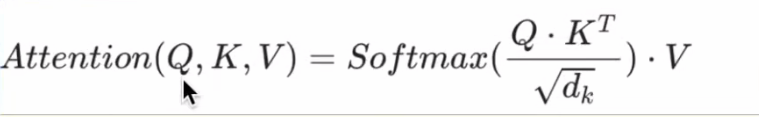(三)自然语言处理笔记------Transformer
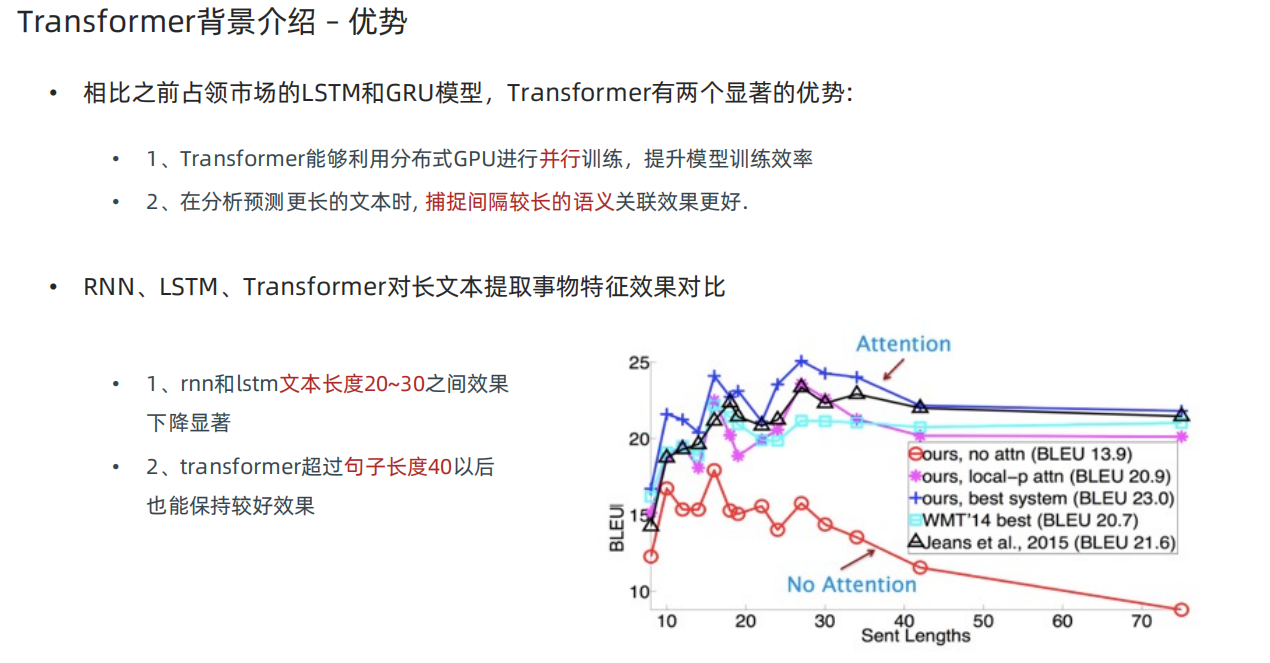
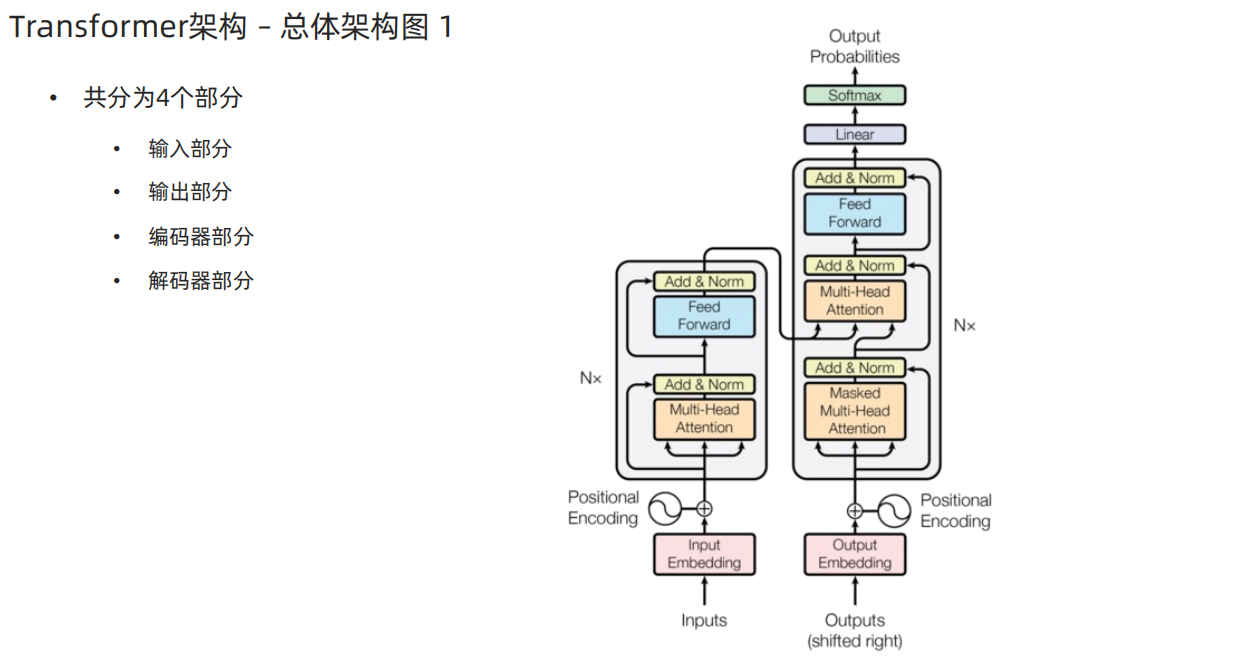
1、Transformer结构

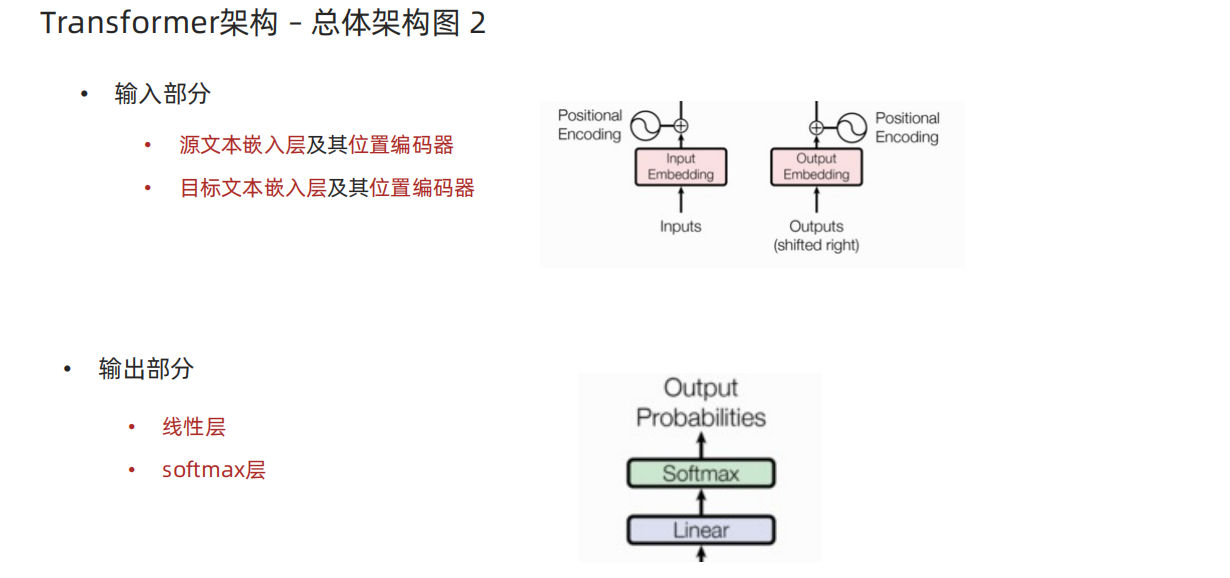

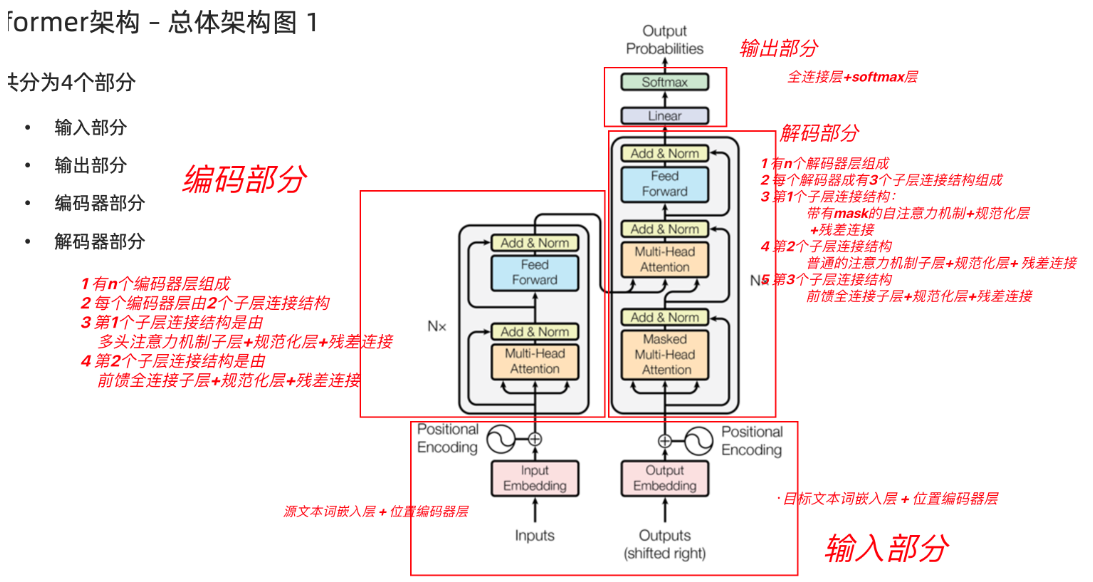
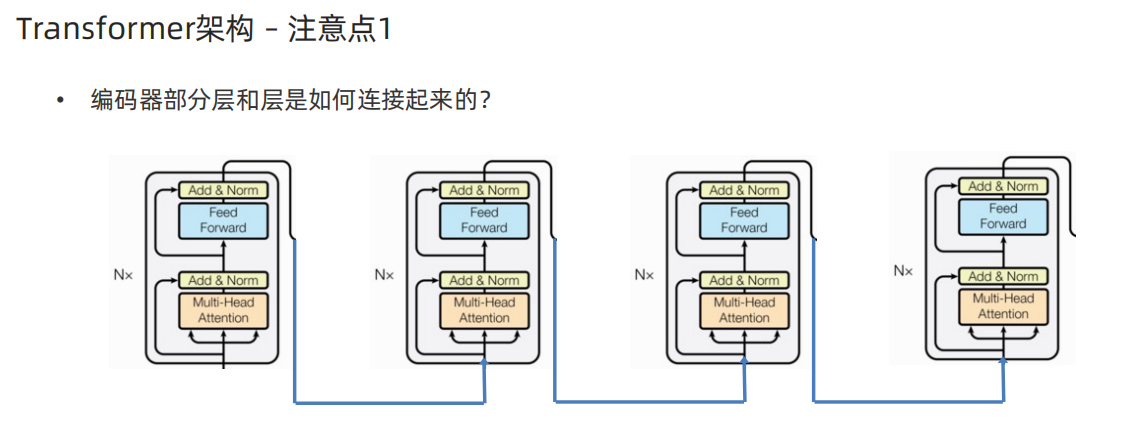
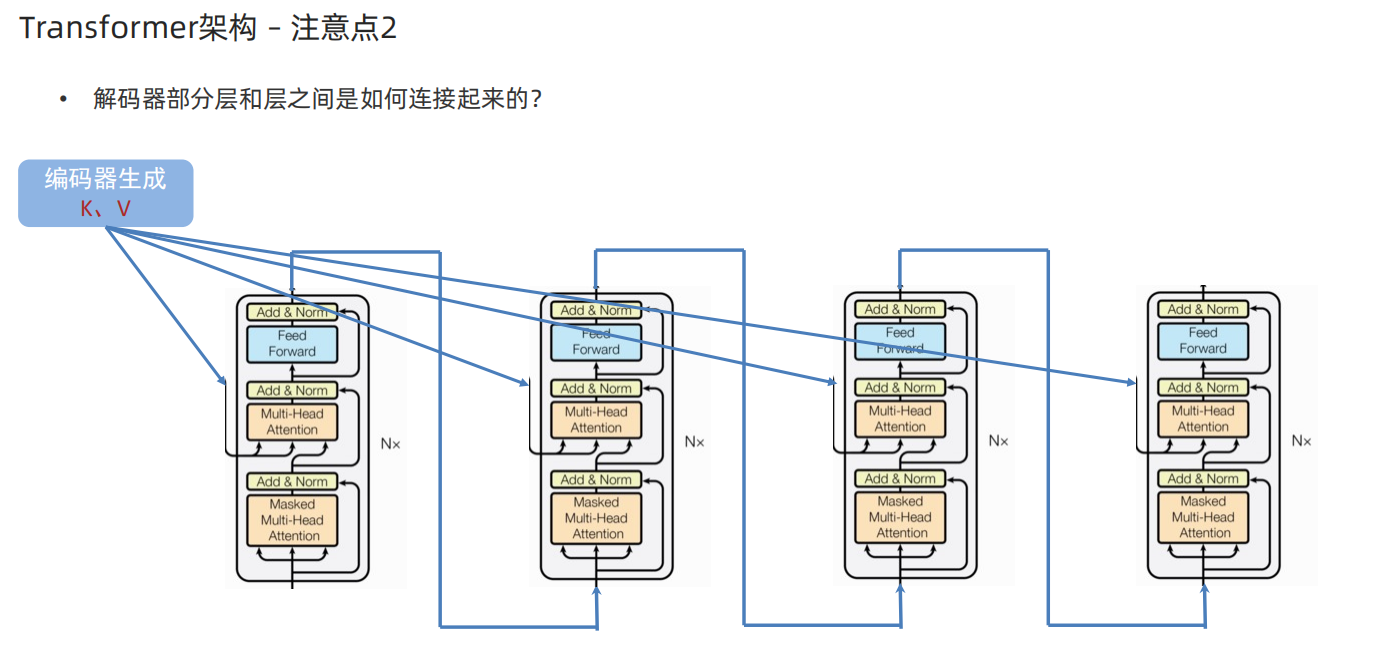

2、Transformer输入部分代码实现

python
import torch
import torch.nn as nn
import math
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
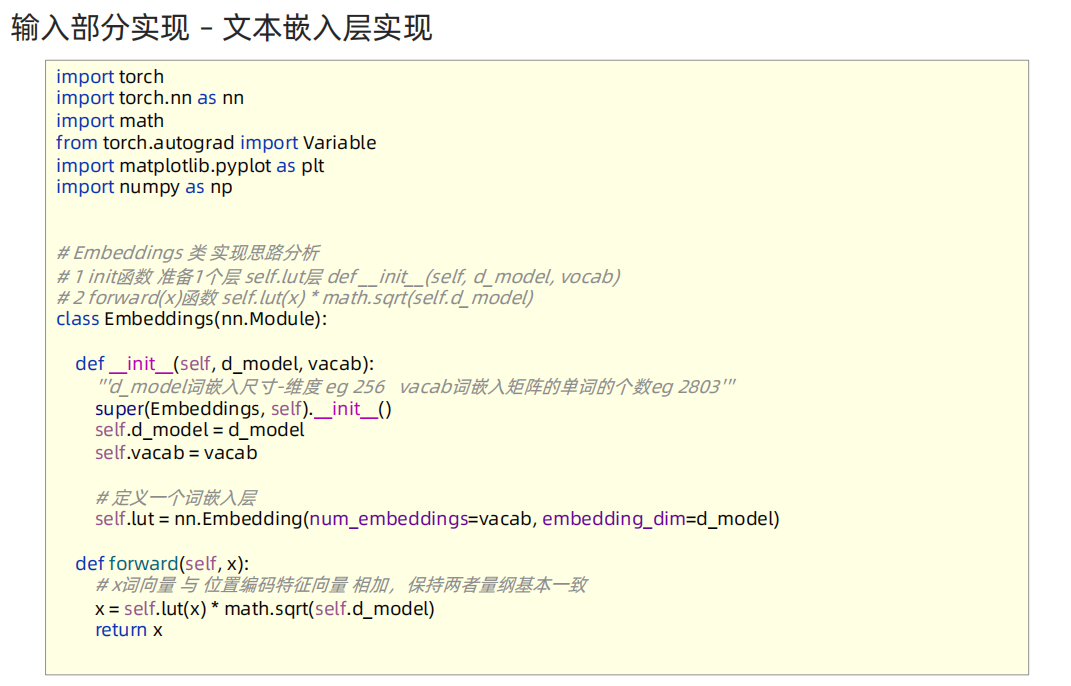
# Embeddings 类 实现思路分析
# 1 init函数 准备1个层 self.lut层 def __init__(self, d_model, vocab)
# 2 forward(x)函数 self.lut(x) * math.sqrt(self.d_model)
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.d_model = d_model
self.vocab = vocab
# self.lut层
self.lut = nn.Embedding(vocab, d_model)
def forward(self, x):
x = self.lut(x) * math.sqrt(self.d_model)
return x
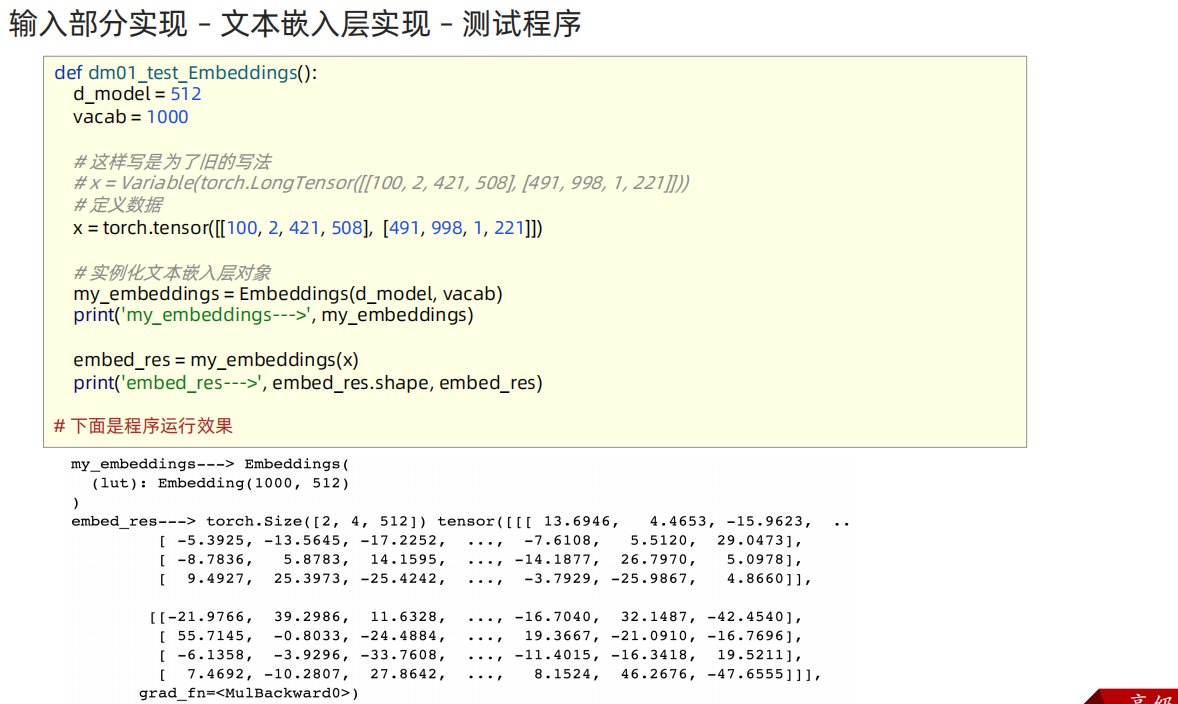
def dm01_test_Embeddings():
# 1 准备数据
x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])
# 2 实例化文本词嵌入层
myembeddings = Embeddings(512, 1000) # 传入的是嵌入的维度,单词数量
print('myembeddings-->', myembeddings)
# 3 给模型喂数据 [2,4] ---> [2,4,512]
embed_res = myembeddings(x)
print('embed_res-->', embed_res.shape, embed_res)
pass
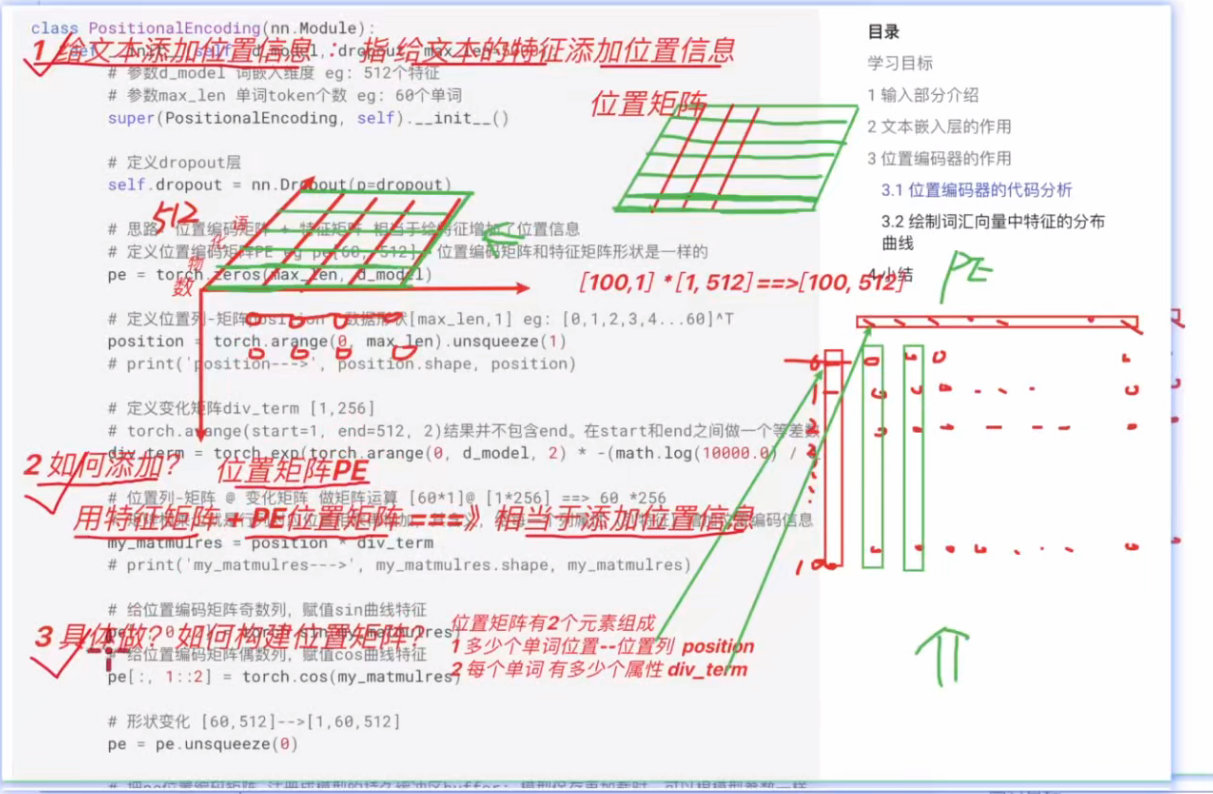
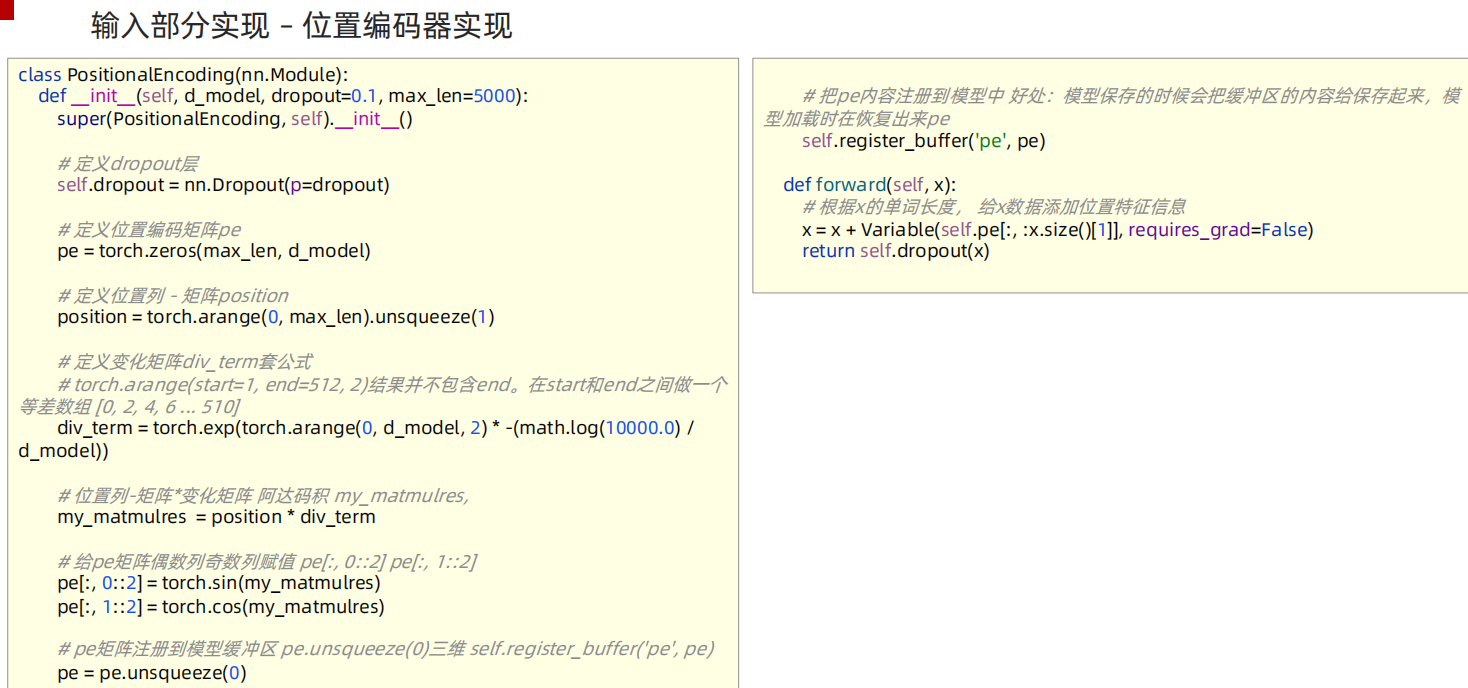
# 位置编码器类 PositionalEncoding 实现思路分析
# 1 init函数 (self, d_model, dropout, max_len=5000)
# super()函数 定义层self.dropout
# 定义位置编码矩阵pe 定义位置列-矩阵position 定义变化矩阵div_term 套公式
# position = torch.arange(0, max_len).unsqueeze(1)
# div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0)/d_model))
# 位置列-矩阵*变化矩阵 阿达码积 my_matmulres, 给pe矩阵偶数列奇数列赋值 pe[:, 0::2] pe[:, 1::2]
# pe矩阵注册到模型缓冲区 pe.unsqueeze(0)三维 self.register_buffer('pe', pe)
# 2 forward(self, x) 返回self.dropout(x)
# 给x数据添加位置特征信息 x = x + Variable( self.pe[:,:x.size()[1]], requires_grad=False)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 定义位置编码矩阵pe
pe = torch.zeros(max_len, d_model)
# 定义位置列-矩阵position [60,1]
position = torch.arange(0, max_len).unsqueeze(1)
# 定义变化矩阵div_term 套公式 [1,256]
div_term = torch.exp( torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) )
# 位置列-矩阵*变化矩阵 阿达码积 my_matmulres, 给pe矩阵偶数列奇数列赋值 pe[:, 0::2] pe[:, 1::2]
my_matmulres = position * div_term # [60,1] * [1,256]==> [60, 256]
pe[:, 0::2] = torch.sin(my_matmulres)
pe[:, 1::2] = torch.cos(my_matmulres)
# pe矩阵注册到模型缓冲区 pe.unsqueeze(0)三维 self.register_buffer('pe', pe)
pe = pe.unsqueeze(0) #[60, 256]--> [1,60,256]
self.register_buffer('pe', pe)
def forward(self, x):
tmp = x.size()[1]
x = x + Variable( self.pe[:, :x.size()[1]], requires_grad=False )
return x
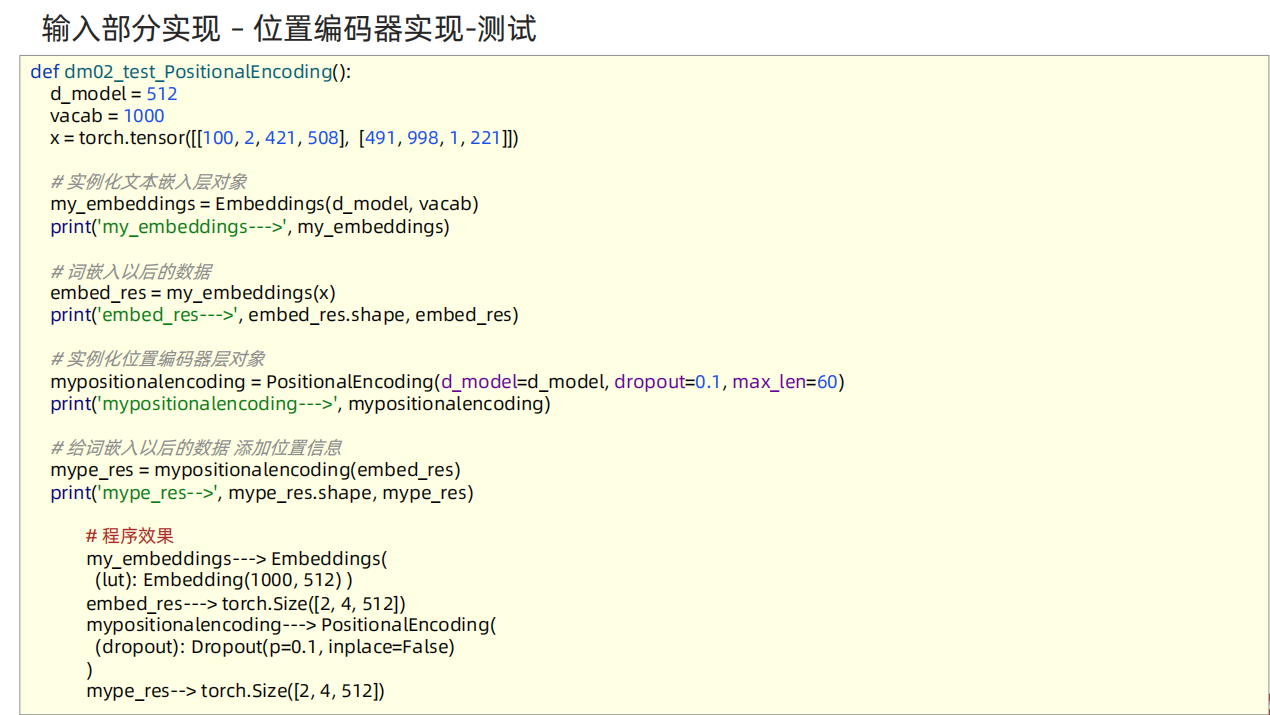
def dm02_test_PositionalEncoding():
# 1 准备数据
x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])
# 2 实例化文本词嵌入层
myembeddings = Embeddings(512, 1000)
print('myembeddings-->', myembeddings)
# 3 给模型喂数据 [2,4] ---> [2,4,512]
embed_res = myembeddings(x)
print('embed_res-->', embed_res.shape, embed_res)
# 4 添加位置信息
mypositionalencoding = PositionalEncoding(d_model=512, dropout=0.1, max_len=60)
print('mypositionalencoding-->', mypositionalencoding)
pe_res = mypositionalencoding(embed_res)
print('添加位置特征以后的x-->', pe_res.shape)
if __name__ == '__main__':
dm01_test_Embeddings()
dm02_test_PositionalEncoding()
print('输入部分 End')


python
import torch
import torch.nn as nn
import math
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
# Embeddings 类 实现思路分析
# 1 init函数 准备1个层 self.lut层 def __init__(self, d_model, vocab)
# 2 forward(x)函数 self.lut(x) * math.sqrt(self.d_model)
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.d_model = d_model
self.vocab = vocab
# self.lut层
self.lut = nn.Embedding(vocab, d_model)
def forward(self, x):
x = self.lut(x) * math.sqrt(self.d_model)
return x
def dm01_test_Embeddings():
# 1 准备数据
x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])
# 2 实例化文本词嵌入层
myembeddings = Embeddings(512, 1000) # 传入的是嵌入的维度,单词数量
print('myembeddings-->', myembeddings)
# 3 给模型喂数据 [2,4] ---> [2,4,512]
embed_res = myembeddings(x)
print('embed_res-->', embed_res.shape, embed_res)
pass
# 位置编码器类 PositionalEncoding 实现思路分析
# 1 init函数 (self, d_model, dropout, max_len=5000)
# super()函数 定义层self.dropout
# 定义位置编码矩阵pe 定义位置列-矩阵position 定义变化矩阵div_term 套公式
# position = torch.arange(0, max_len).unsqueeze(1)
# div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0)/d_model))
# 位置列-矩阵*变化矩阵 阿达码积 my_matmulres, 给pe矩阵偶数列奇数列赋值 pe[:, 0::2] pe[:, 1::2]
# pe矩阵注册到模型缓冲区 pe.unsqueeze(0)三维 self.register_buffer('pe', pe)
# 2 forward(self, x) 返回self.dropout(x)
# 给x数据添加位置特征信息 x = x + Variable( self.pe[:,:x.size()[1]], requires_grad=False)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 定义位置编码矩阵pe
pe = torch.zeros(max_len, d_model)
# 定义位置列-矩阵position [60,1]
position = torch.arange(0, max_len).unsqueeze(1)
# 定义变化矩阵div_term 套公式 [1,256]
div_term = torch.exp( torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) )
# 位置列-矩阵*变化矩阵 阿达码积 my_matmulres, 给pe矩阵偶数列奇数列赋值 pe[:, 0::2] pe[:, 1::2]
my_matmulres = position * div_term # [60,1] * [1,256]==> [60, 256]
pe[:, 0::2] = torch.sin(my_matmulres)
pe[:, 1::2] = torch.cos(my_matmulres)
# pe矩阵注册到模型缓冲区 pe.unsqueeze(0)三维 self.register_buffer('pe', pe)
pe = pe.unsqueeze(0) #[60, 256]--> [1,60,256]
self.register_buffer('pe', pe)
def forward(self, x):
tmp = x.size()[1]
x = x + Variable( self.pe[:, :x.size()[1]], requires_grad=False )
return x
def dm02_test_PositionalEncoding():
# 1 准备数据
x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])
# 2 实例化文本词嵌入层
myembeddings = Embeddings(512, 1000)
print('myembeddings-->', myembeddings)
# 3 给模型喂数据 [2,4] ---> [2,4,512]
embed_res = myembeddings(x)
print('embed_res-->', embed_res.shape, embed_res)
# 4 添加位置信息
mypositionalencoding = PositionalEncoding(d_model=512, dropout=0.1, max_len=60)
print('mypositionalencoding-->', mypositionalencoding)
pe_res = mypositionalencoding(embed_res)
print('添加位置特征以后的x-->', pe_res.shape)
if __name__ == '__main__':
dm01_test_Embeddings()
dm02_test_PositionalEncoding()
print('输入部分 End')3、Transformer编码器部分
掩码张量


python
def dm01_test_nptriu():
# m:表示一个矩阵
# K:表示对角线的起始位置(k取值默认为0)
# return: 返回函数的上三角矩阵
# 测试产生上三角矩阵
print('k=1\n', np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=1))
print('k=0\n', np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=0))
print('k=-1\n', np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=-1))
pass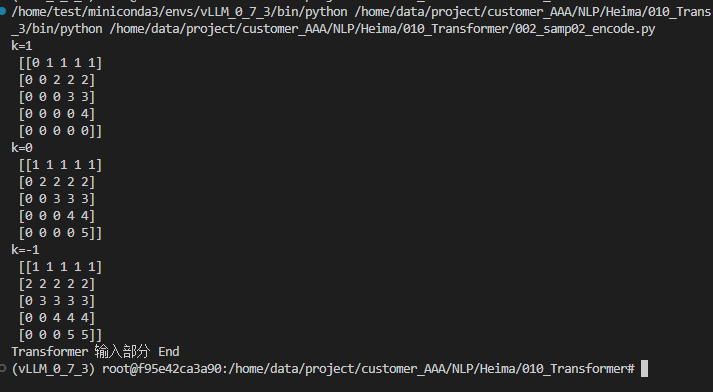
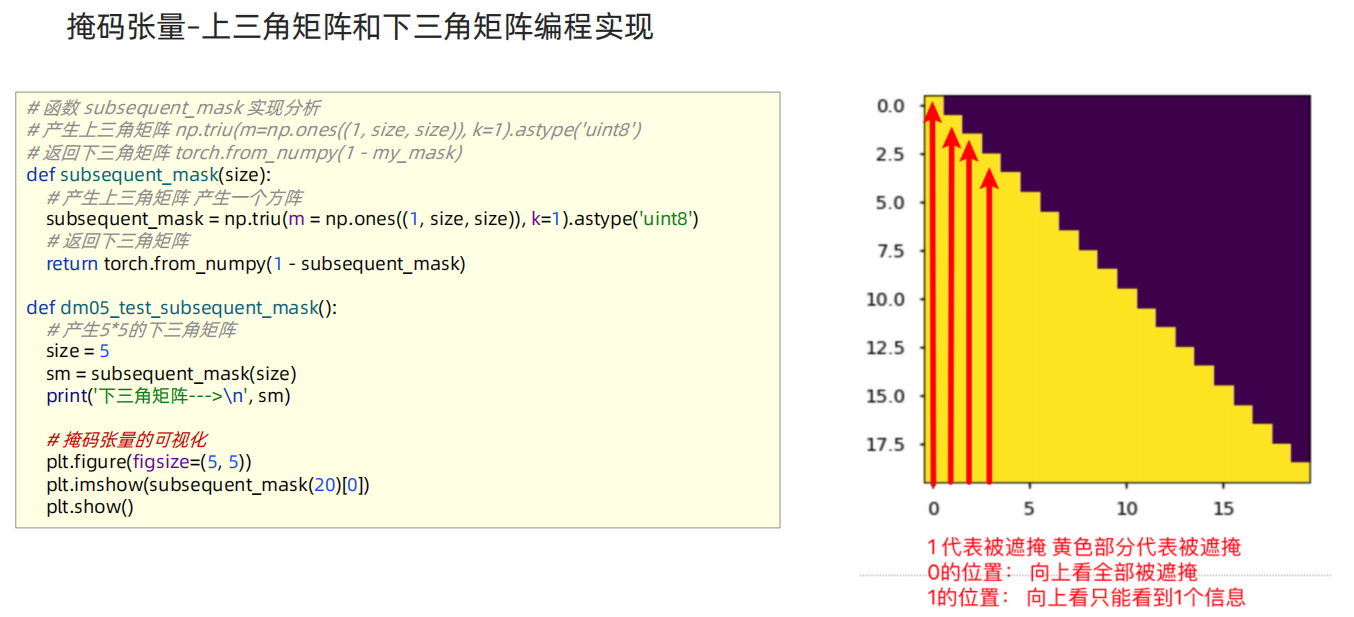
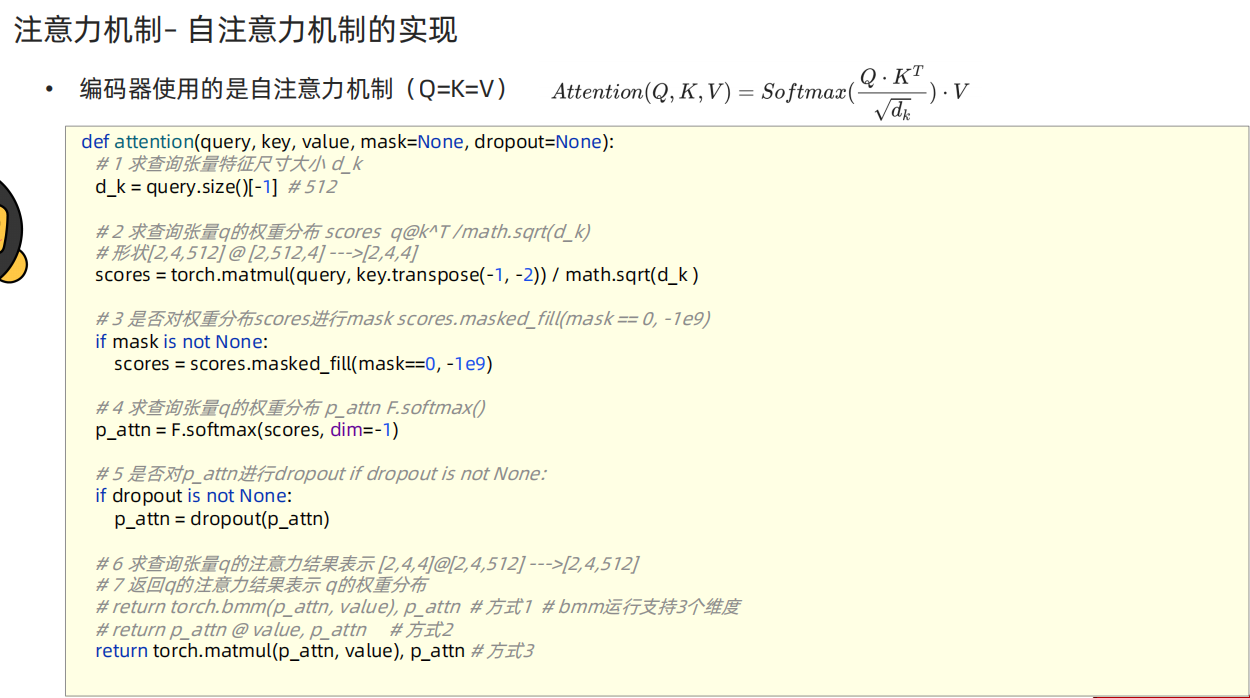
自注意力机制模块