实时语音转文字,比如会议记录、课堂笔记,这类功能现在很常见,也是很多人感兴趣的热门方向。
那么想不想动手部署一个开源、好玩的实时转录项目 ------ WhisperLiveKit 。 它能让你在自己的电脑上轻松搭建一套语音实时识别系统!
💡 先说结论:它适合谁?
WhisperLiveKit 非常适合学习和体验 AI 实时语音识别的原理与流程。 不过要提醒一句:它还不能完全替代专业商业产品,但已经非常有趣、够强大。
优点:
- 🚀 部署超级简单
- 💻 自带网页界面,可直接体验前沿技术
需要注意的地方:
-
延迟问题 中文识别准确率高的模型(比如
large-v2/v3)相对较慢,语音转文字的延迟可能大于10秒,甚至更久。 如果你的电脑有一张 NVIDIA 显卡(建议 12G 显存以上),速度会快很多。 小模型虽然快,但中文识别不够准确。 -
网络环境 程序需要下载一个非常大的核心模型,这个文件在墙外。 👉 所以你需要提前准备好"科学上网"工具。
🧰 第一步:准备工作(磨刀不误砍柴工)
开始前,请确认你的电脑准备好了以下几样:
-
安装
uv这是一个现代化的 Python 包管理工具,可以用"一条命令"安装所有依赖,极其省心。如果你还没装,查看官网安装方式 docs.astral.sh/uv/getting-...
-
安装
ffmpeg它是音视频处理界的"瑞士军刀",我们的程序要靠它来读取麦克风声音。同样,如果还没安装,查看官网安装 ffmpeg.org/download.ht...
-
开启网络代理 ⚠️ 这一点非常重要! 因为模型文件要从墙外服务器下载,请务必开启"科学上网", 并设置为"全局代理"或"系统代理"模式。
⚙️ 第二步:安装核心程序
-
新建一个文件夹,比如:
D:/python/livekit -
打开这个文件夹,在地址栏输入
cmd,然后按回车。 你会看到一个黑色命令行窗口👇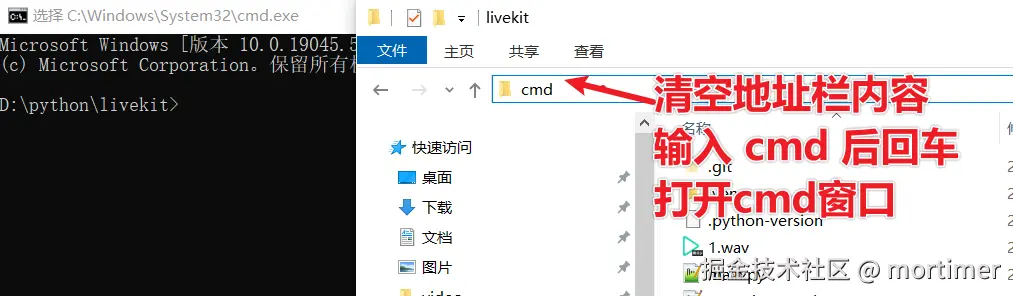
-
把下面命令复制进去,然后按回车执行:
csharp
uv init && uv add whisperlivekit faster-whisper --index https://pypi.tuna.tsinghua.edu.cn/simple💡 这条命令会:
- 使用
uv自动安装 WhisperLiveKit 和加速依赖faster-whisper- 并通过清华镜像源加速下载

等待安装中...... ⏳ 
看到如下界面,就表示安装成功啦!🎉 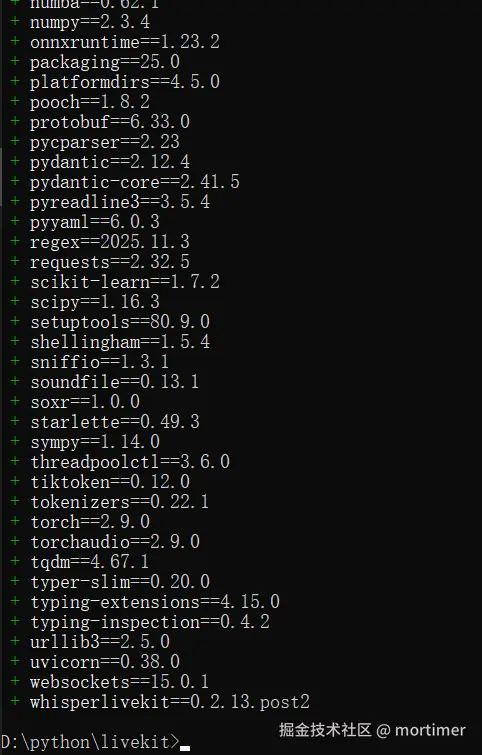
🚀 第三步:启动实时转录服务
继续在命令行窗口中执行以下命令:
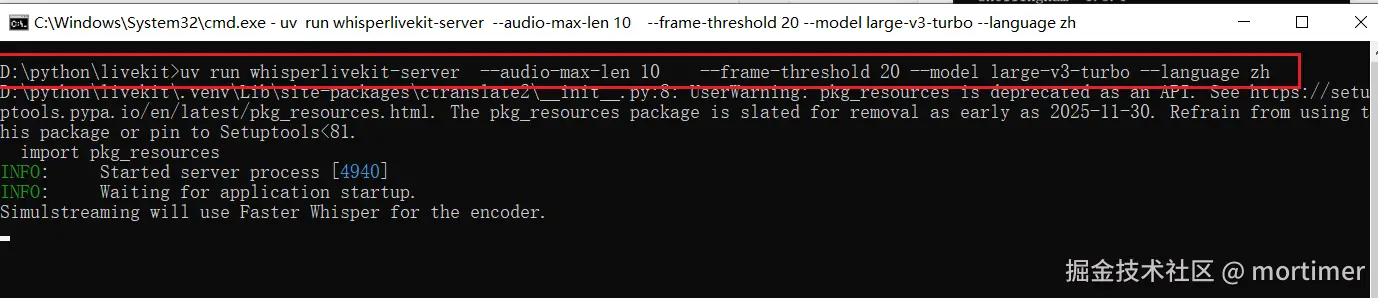
css
uv run whisperlivekit-server --audio-max-len 10 --frame-threshold 20 --model large-v3-turbo --language zh参数说明:
--model large-v3-turbo:使用更快的large-v3-turbo模型(比 large-v2/v3 快很多,准确率略有下降)--language zh:指定识别中文
⚠️ 第一次运行会自动下载模型文件,体积较大,请保持网络畅通并耐心等待。
当窗口出现下图中的网址时,恭喜!🎉 服务启动成功! 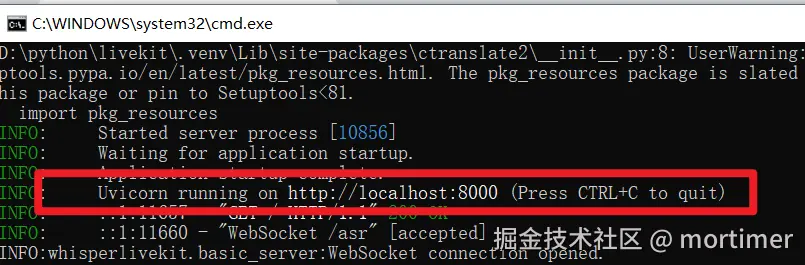
🌐 第四步:开始使用!
打开浏览器(推荐 Chrome 或 Edge),访问地址:
👉 http://localhost:8000/
你会看到一个简洁的网页界面👇 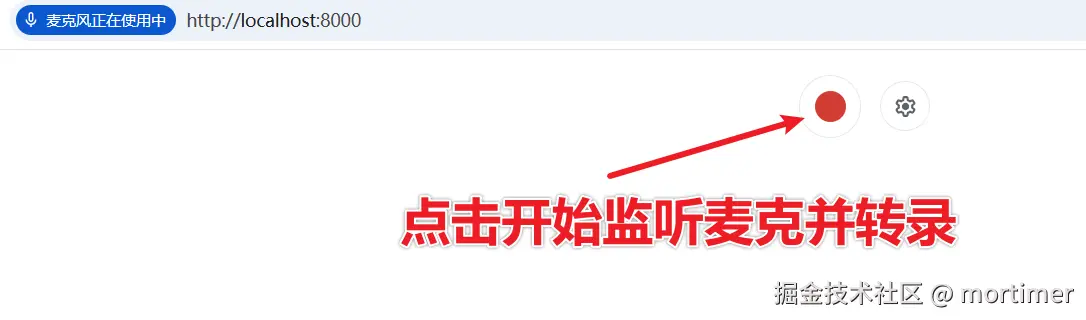
点击大大的红色按钮,允许浏览器访问麦克风。 然后开始说话,稍等几秒,识别文字就会出现在屏幕上! 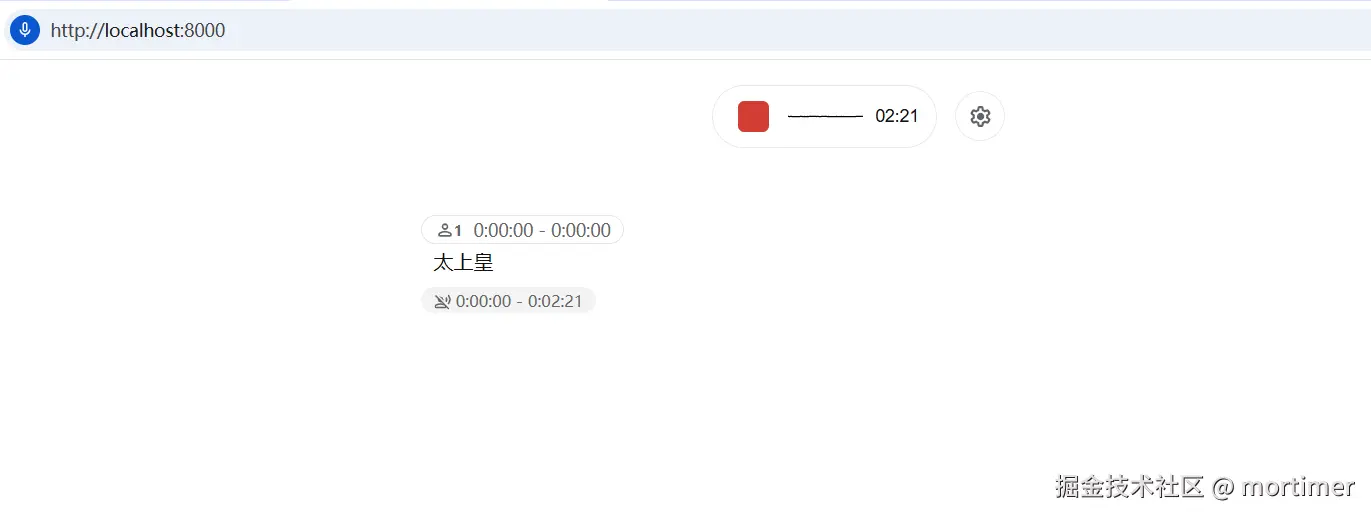
🧩 常见"翻车"现场与解决办法
别担心,以下是最常见的几种错误:
-
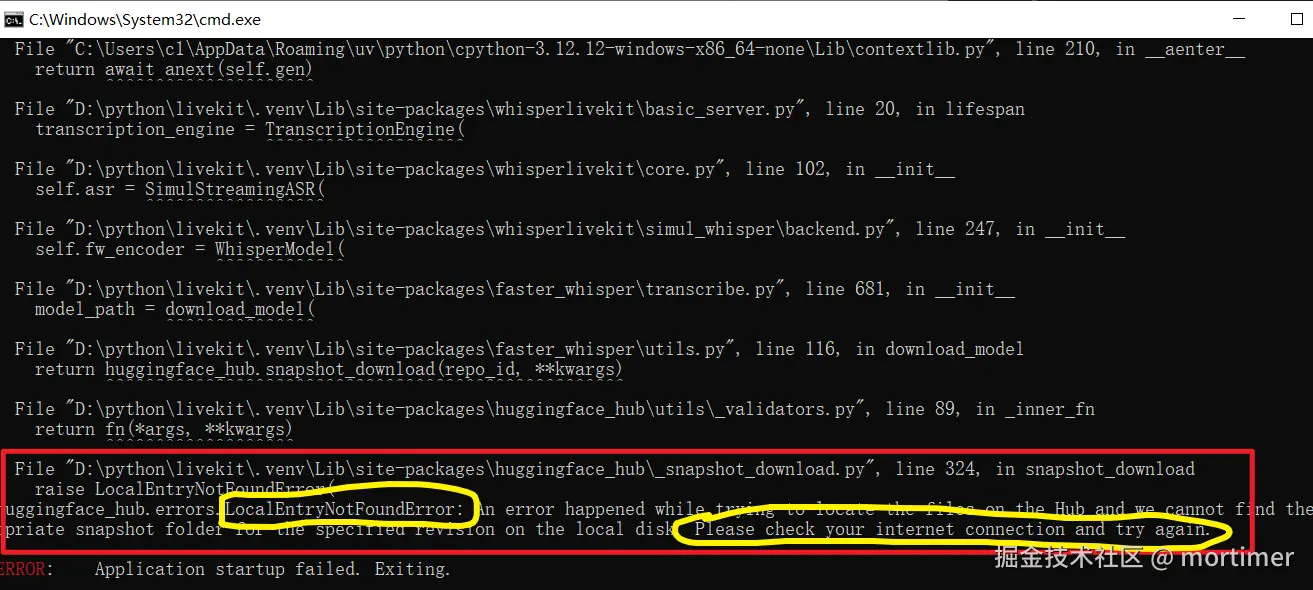
❌ 模型下载失败 错误提示里如果有 "huggingface"、"download"、"timeout"等字样, 几乎都是代理没开或没设置成全局模式 。
-
❌ 找不到
uv表示uv没安装好,或未加入系统环境变量。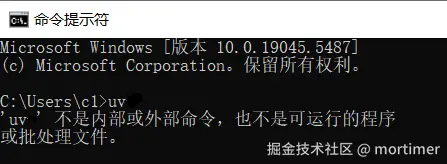
-
❌ 找不到
ffmpeg同理,检查是否安装正确并配置了环境变量。
💤 懒人福利:一键启动脚本!
每次敲命令太麻烦?那就来个"一键启动"!
- 在项目文件夹(
D:/python/livekit)中新建一个文本文档 - 把以下内容复制进去:
python
@echo off
call uv run whisperlivekit-server --audio-max-len 10 --backend faster-whisper --frame-threshold 20 --model large-v3-turbo --language zh
pause- 点击"文件"→"另存为", 保存类型选为 所有文件 ,命名为
start.bat,然后保存。 4. ⚠️ 确认文件名结尾是.bat(不是.bat.txt)!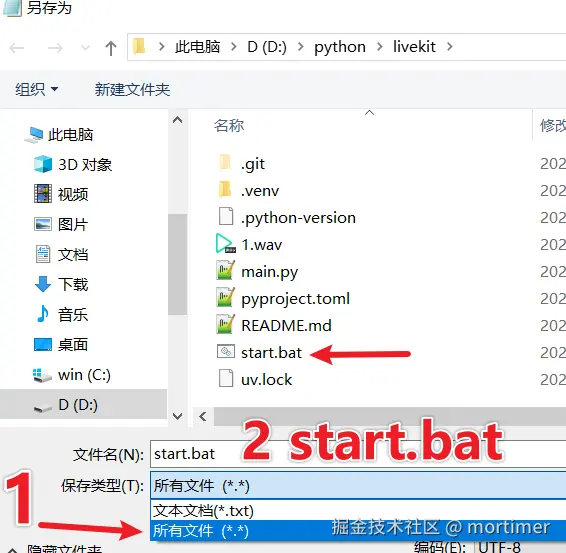
以后你只需双击 start.bat 文件,就能一键启动服务啦~ 再也不用每次输入长命令,轻松又高效!
🎉 恭喜你完成部署! 从现在起,你已经能在自己的电脑上实现实时语音识别。 WhisperLiveKit 是一个非常适合学习和演示的项目, 不妨多尝试不同模型、参数,探索它的更多玩法吧!