1.AWESOME-DIGITAL-HUMAN是什么
AWESOME-DIGITAL-HUMAN是一款国产开源的数字人框架
2.准备工作
下载源码 git clone github.com/wan-h/aweso... 项目目录如下:
.
├── config.yaml # 全局配置文件
├── agents # agent 配置文件目录
└── engines # 引擎配置文件目录
├── asr # 语音识别引擎配置文件目录
├── llm # 大模型引擎配置文件目录
└── tts # 文字转语音引擎配置目录容器部署:docker-compose up --build -d 创建一个千问智能体,以备后用 开通腾讯tts服务,以备后用
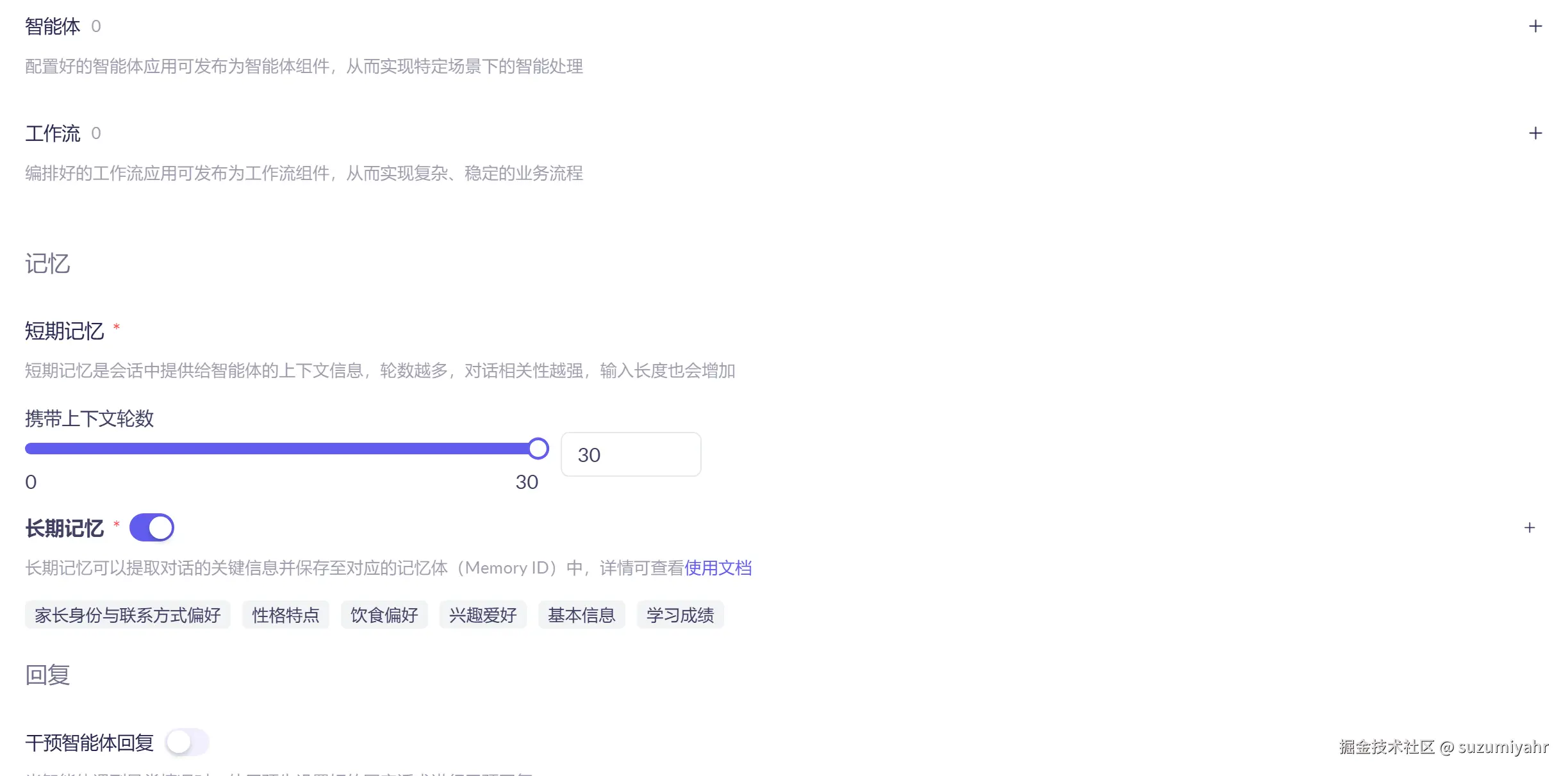
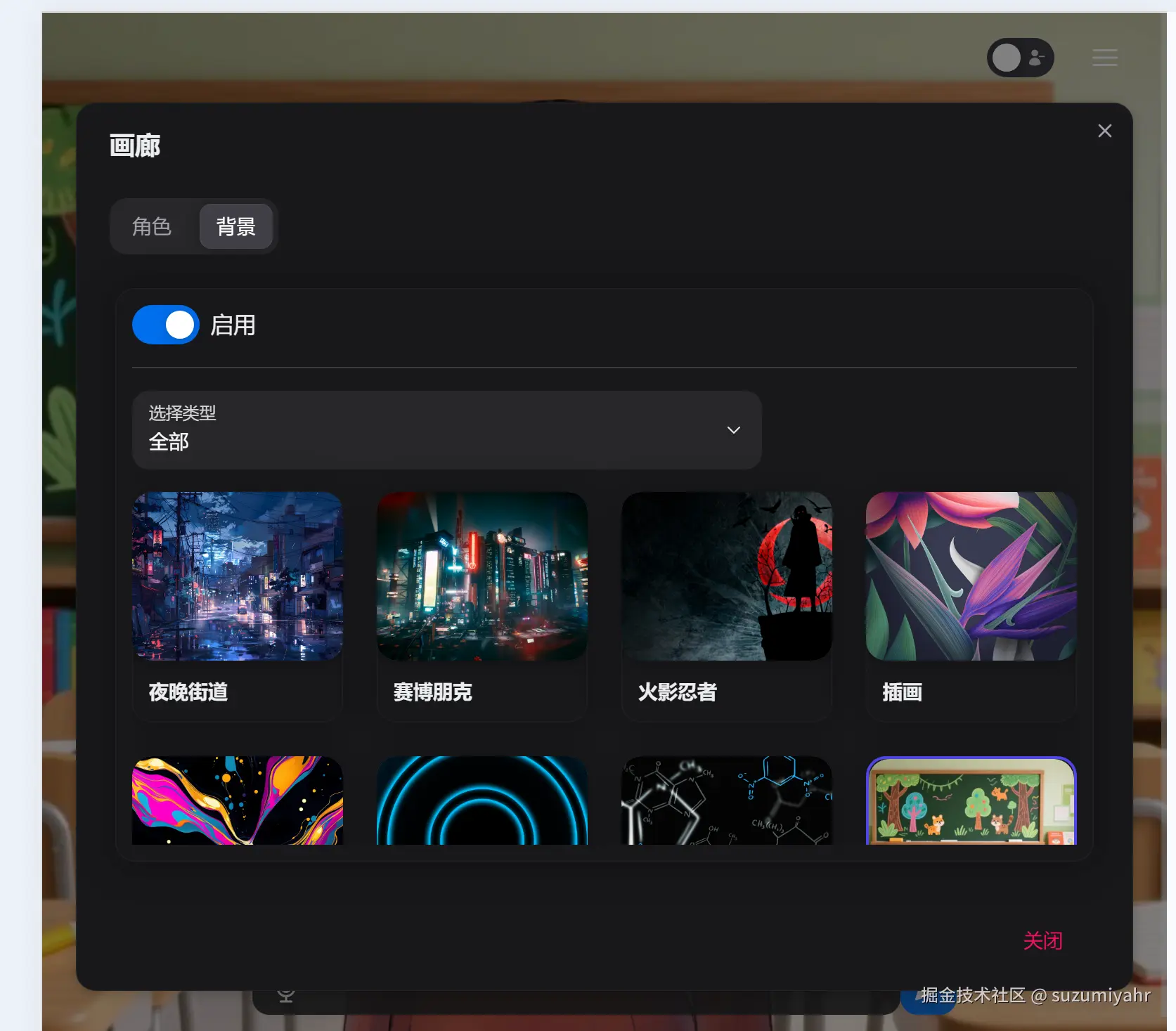
打开8880端口,发现项目已经成功启动了,可以修改很多配置,比如人物的模型,背景,声音,可以使用的agent等等
2.项目修改
修改configs\engines\tts\tencentAPI.yaml文件的相关配置,选择我们喜欢的语音
NAME:
VERSION: "v0.0.1"
DESC: "接入腾讯服务"
META: {
official: "",
configuration: "https://console.cloud.tencent.com/tts",
tips: "",
fee: ""
}
PARAMETERS: [
{
name: "secret_id",
description: "tencent secret_id.",
type: "string",
required: false,
choices: [],
default: "腾讯tts的 secret_id"
},
{
name: "secret_key",
description: "tencent secret_key.",
type: "string",
required: false,
choices: [],
default: "腾讯tts的 secret_key"
},
{
name: "voice",
description: "Voice for TTS.",
type: "string",
required: false,
choices: [],
default: "爱小璟"
},
{
name: "volume",
description: "Set volume, default +0%.",
type: "float",
required: false,
range: [-10, 10],
default: 0.0
},
{
name: "speed",
description: "Set speed, default +0%.",
type: "float",
required: false,
range: [-2, 6],
default: 0.0
}
]打开config_template.yaml文件,可以发现目前是不支持通义千问的,首先增加对千问的支持
COMMON:
NAME: "Awesome-Digital-Human"
VERSION: "v3.0.0"
LOG_LEVEL: "DEBUG"
SERVER:
IP: "0.0.0.0"
PORT: 8880
WORKSPACE_PATH: "./outputs"
ENGINES:
ASR:
SUPPORT_LIST: [ "difyAPI.yaml", "cozeAPI.yaml", "tencentAPI.yaml", "funasrStreamingAPI.yaml"]
DEFAULT: "difyAPI.yaml"
TTS:
SUPPORT_LIST: [ "edgeAPI.yaml", "tencentAPI.yaml", "difyAPI.yaml", "cozeAPI.yaml" ]
DEFAULT: "tencentAPI.yaml"
LLM:
SUPPORT_LIST: []
DEFAULT: ""
AGENTS:
SUPPORT_LIST: [ "repeaterAgent.yaml", "openaiAPI.yaml", "difyAgent.yaml", "fastgptAgent.yaml", "cozeAgent.yaml"]
DEFAULT: "repeaterAgent.yaml"在SUPPORT_LIST里增加qwenAgent.yaml 并设置为默认。 在configs agent目录里增加一个qwenAgent.yaml文件
NAME:
VERSION: "v0.0.1"
DESC: "接入通义千问智能体(DashScope Application)"
META: {
official: "https://bailian.console.aliyun.com/",
configuration: "需在百炼平台创建应用并获取 App ID",
tips: "支持多轮对话、流式输出、自动会话管理。提示词和知识库已在智能体后台配置。",
fee: "按 DashScope 定价计费"
}
# 暴露给前端的参数选项以及默认值
PARAMETERS: [
{
name: "api_key",
description: "DashScope API Key(通义千问密钥)",
type: "string",
required: true,
choices: [],
default: "你的sk"
},
{
name: "app_id",
description: "通义千问智能体 App ID(在百炼平台创建)",
type: "string",
required: true,
choices: [],
default: "你的appId"
}
]在digitalHuman\agent\core下创建qwenAgent.py文件,千问支持保存短期对话和长期对话,短期对话使用session_id或者拼接message列表均可,根据文档,在这两个字段同时存在里阿里会采用message列表的模式,此时session_id字段会失效 我们使用session_id的形式,在用户首次对话时创建session_id并传递给前端,当进行后续对话时再由前端返回,长期记忆根据用户创建memory_id存表,然后在对话中携带参数即可
#
from ..builder import AGENTS
from ..agentBase import BaseAgent
import os
import json
from urllib.parse import urlencode
from digitalHuman.protocol import *
from digitalHuman.utils import httpxAsyncClient, logger
__all__ = ["QwenAgent"]
@AGENTS.register("Qwen")
class QwenAgent(BaseAgent):
async def run(
self,
input: TextMessage,
streaming: bool,
**kwargs
):
try:
if not streaming:
raise KeyError("Tongyi Agent only supports streaming mode")
# 获取 API 参数
api_key = kwargs.get("api_key") or os.getenv("DASHSCOPE_API_KEY")
app_id = kwargs.get("app_id") or os.getenv("DASHSCOPE_APP_ID")
session_id = (kwargs.get("conversation_id") or kwargs.get("session_id") or "").strip()
memory_id = kwargs.get("mid") or ""
messages = kwargs.get("messages", [])
if not api_key:
raise ValueError(
"Missing 'api_key': please provide it in parameters "
"or set DASHSCOPE_API_KEY environment variable."
)
if not app_id:
raise ValueError(
"Missing 'app_id': please provide it in parameters "
"or set DASHSCOPE_APP_ID environment variable."
)
prompt = input.data.strip()
#模式判断:messages 优先级高于 session_id
use_custom_messages = bool(messages)
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"X-DashScope-SSE": "enable"
}
payload = {
"input": {},
"parameters": {
"incremental_output": True
},
"stream": True
}
url = f"https://dashscope.aliyuncs.com/api/v1/apps/{app_id}/completion"
if memory_id :
payload["input"]["memory_id"] = memory_id
if use_custom_messages:
#自定义上下文模式
logger.info("[QwenAgent] Using custom 'messages' mode. session_id will be ignored.")
for msg in messages:
if not isinstance(msg, dict) or "role" not in msg or "content" not in msg:
raise ValueError("Each message must be a dict with 'role' and 'content'")
final_messages = messages.copy()
if prompt:
final_messages.append({"role": "user", "content": prompt})
payload["input"]["messages"] = final_messages
else:
#标准多轮对话模式
if not prompt:
raise ValueError("Prompt is required when not using 'messages'.")
logger.info(f"[QwenAgent] Using standard mode with session_id: '{session_id or '(new)'}'")
payload["input"]["prompt"] = prompt
if session_id:
url += "?" + urlencode({"session_id": session_id})
payload["input"]["session_id"] = session_id
logger.info(f"[QwenAgent] Request URL: {url}")
logger.info(f"[QwenAgent] Payload: {payload}")
# 发起请求
async with httpxAsyncClient.stream("POST", url, headers=headers, json=payload) as response:
logger.info(f"[QwenAgent] Response status: {response.status_code}")
if response.status_code != 200:
error_text = await response.aread()
try:
err_json = json.loads(error_text)
msg = err_json.get("message", error_text.decode())
except Exception:
msg = error_text.decode()
error_msg = f"HTTP {response.status_code}: {msg}"
logger.error(f"[QwenAgent] Request failed: {error_msg}")
yield eventStreamError(error_msg)
return
got_conversation_id = False
async for chunk in response.aiter_lines():
line = chunk.strip()
if not line or line == ":":
continue
if line.startswith("data:"):
data_str = line[5:].strip()
if data_str == "[DONE]":
break
try:
data = json.loads(data_str)
except json.JSONDecodeError as e:
logger.warning(f"[QwenAgent] JSON decode error: {e}, raw: {data_str}")
continue
logger.debug(f"[QwenAgent] SSE data received: {data}")
# 提取 conversation_id(仅在标准模式下)
if not got_conversation_id and not use_custom_messages:
cid = data.get("output", {}).get("session_id")
if cid:
if not session_id or cid != session_id:
logger.info(f"[QwenAgent] New conversation_id received: {cid}")
yield eventStreamConversationId(cid)
got_conversation_id = True
# 提取文本
text = data.get("output", {}).get("text", "")
if text:
yield eventStreamText(text)
yield eventStreamDone()
except Exception as e:
logger.error(f"[QwenAgent] Exception: {e}", exc_info=True)
yield eventStreamError(str(e))阿里创建长期记忆体sdk:
@staticmethod
def create_client() -> bailian20231229Client:
"""
使用凭据初始化账号Client
@return: Client
@throws Exception
"""
# 工程代码建议使用更安全的无AK方式,凭据配置方式请参见:https://help.aliyun.com/document_detail/378659.html。
credential = CredentialClient()
config = open_api_models.Config(
credential=credential
)
# Endpoint 请参考 https://api.aliyun.com/product/bailian
config.endpoint = f'bailian.cn-beijing.aliyuncs.com'
return bailian20231229Client(config)
@staticmethod
async def main_async(
args: List[str],
) -> None:
client = Sample.create_client()
create_memory_node_request = bailian_20231229_models.CreateMemoryNodeRequest()
runtime = util_models.RuntimeOptions()
headers = {}
try:
# 复制代码运行请自行打印 API 的返回值
await client.create_memory_node_with_options_async('', '', create_memory_node_request, headers, runtime)
except Exception as error:
# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。需要注意incremental_output需要修改为True,否则流式输出的情况下数据会有重复。 在流式输出的情况下,如果每次返回都请求tts,会导致断句不自然甚至一字一顿的情况,比如 我 喜欢 吃这样,调整前端相关的逻辑代码,着重修改web\app(products)\sentio\hooks\chat.ts文件,主要修改逻辑就是把每次流式输出推送tts改为拼接完成后,根据标点断句分批推送tts,同时控制文字和语音的分段同时显示,使嘴型,声音和文字更加自然同步。
import
import {
useChatRecordStore,
useSentioAgentStore,
useSentioTtsStore,
useSentioBasicStore,
} from "@/lib/store/sentio";
import { useTranslations } from 'next-intl';
import { CHAT_ROLE, EventResponse, STREAMING_EVENT_TYPE } from "@/lib/protocol";
import { Live2dManager } from '@/lib/live2d/live2dManager';
import { base64ToArrayBuffer, ttsTextPreprocess } from '@/lib/func';
import { convertMp3ArrayBufferToWavArrayBuffer } from "@/lib/utils/audio";
import {
api_tts_infer,
api_agent_stream,
} from '@/lib/api/server';
import { addToast } from "@heroui/react";
import { SENTIO_RECODER_MIN_TIME, SENTIO_RECODER_MAX_TIME } from "@/lib/constants";
export function useAudioTimer() {
const t = useTranslations('Products.sentio');
const startTime = useRef(new Date());
const toast = (message: string) => {
addToast({
title: message,
color: "warning",
});
};
const startAudioTimer = () => {
startTime.current = new Date();
};
const stopAudioTimer = (): boolean => {
const duration = new Date().getTime() - startTime.current.getTime();
if (duration < SENTIO_RECODER_MIN_TIME) {
toast(`${t('recordingTime')} < ${SENTIO_RECODER_MIN_TIME}`);
} else if (duration > SENTIO_RECODER_MAX_TIME) {
toast(`${t('recordingTime')} > ${SENTIO_RECODER_MAX_TIME}`);
} else {
return true;
}
return false;
};
return { startAudioTimer, stopAudioTimer };
}
//获取 mid
function getMidFromUrl(): string | null {
if (typeof window === 'undefined') return null;
const params = new URLSearchParams(window.location.search);
return params.get('mid');
}
export function useChatWithAgent() {
const [chatting, setChatting] = useState(false);
const { engine: agentEngine, settings: agentSettings } = useSentioAgentStore();
const { engine: ttsEngine, settings: ttsSettings } = useSentioTtsStore();
const { sound } = useSentioBasicStore();
const { addChatRecord, updateLastRecord } = useChatRecordStore();
const controller = useRef<AbortController | null>(null);
const conversationId = useRef<string>("");
const messageId = useRef<string>("");
// 原始流式文本缓存(用于断句)
const fullRawText = useRef<string>("");
const pendingText = useRef<string>("");
const lastTextUpdateTime = useRef<number>(0);
// 已显示的文本(仅包含已 TTS 的内容)
const displayedContent = useRef<string>("");
const agentThinkRef = useRef<string>("");
//TTS 串行队列,保证顺序
const ttsQueue = useRef<Array<{ text: string }>>([]);
const isProcessingTts = useRef<boolean>(false);
//从 URL 获取 mid(只在初始化时读一次)
const mid = useRef<string | null>(getMidFromUrl());
const abort = () => {
setChatting(false);
Live2dManager.getInstance().stopAudio();
if (controller.current) {
controller.current.abort("abort");
controller.current = null;
}
fullRawText.current = "";
pendingText.current = "";
displayedContent.current = "";
lastTextUpdateTime.current = 0;
agentThinkRef.current = "";
ttsQueue.current = []; // 清空队列
isProcessingTts.current = false;
};
const updateDisplayedContent = (newSentence: string) => {
displayedContent.current += newSentence;
updateLastRecord({
role: CHAT_ROLE.AI,
think: agentThinkRef.current,
content: displayedContent.current
});
};
//串行处理 TTS 队列
const processNextTtsInQueue = () => {
if (isProcessingTts.current || ttsQueue.current.length === 0 || !controller.current) {
return;
}
isProcessingTts.current = true;
const { text } = ttsQueue.current.shift()!;
const processedText = ttsTextPreprocess(text);
if (!processedText) {
updateDisplayedContent(text);
isProcessingTts.current = false;
processNextTtsInQueue();
return;
}
api_tts_infer(
ttsEngine,
ttsSettings,
processedText,
controller.current.signal
).then((ttsResult) => {
if (ttsResult && controller.current) {
const audioData = base64ToArrayBuffer(ttsResult);
convertMp3ArrayBufferToWavArrayBuffer(audioData)
.then((buffer) => {
if (controller.current) {
updateDisplayedContent(text);
Live2dManager.getInstance().pushAudioQueue(buffer);
}
})
.catch((err) => {
console.warn("Audio conversion failed:", err);
updateDisplayedContent(text);
})
.finally(() => {
isProcessingTts.current = false;
processNextTtsInQueue();
});
} else {
updateDisplayedContent(text);
isProcessingTts.current = false;
processNextTtsInQueue();
}
}).catch((err) => {
console.warn("TTS failed for text:", text, err);
updateDisplayedContent(text);
isProcessingTts.current = false;
processNextTtsInQueue();
});
};
//入队函数(替代原来的 processTextForTTS)
const enqueueTts = (text: string) => {
if (!controller.current) return;
const processedText = ttsTextPreprocess(text);
if (!processedText) {
// 无效文本立即显示
updateDisplayedContent(text);
return;
}
if (!sound) {
// 无声模式直接显示
updateDisplayedContent(text);
return;
}
// 有声模式:入队等待串行处理
ttsQueue.current.push({ text });
processNextTtsInQueue();
};
//按标点断句并及时入队
const tryProcessPendingText = () => {
if (!pendingText.current.trim()) return;
const now = Date.now();
const timeSinceLastUpdate = now - lastTextUpdateTime.current;
const charCount = pendingText.current.length;
// 定义句子结束符(注意:必须包含中文和英文标点)
const sentenceEndingsRegex = /[。!?!?.;;\n,,、...~]/g;
const endings = pendingText.current.match(sentenceEndingsRegex) || [];
const parts = pendingText.current.split(sentenceEndingsRegex);
const completeSentences: string[] = [];
let remaining = "";
// 重组:除最后一个 part 外,其余都可组成完整句子
for (let i = 0; i < parts.length - 1; i++) {
let sentence = parts[i];
if (i < endings.length) {
sentence += endings[i]; // 把标点加回去
}
if (sentence.trim()) {
completeSentences.push(sentence);
}
}
// 最后一个 part 是未完成的片段(除非原文本以标点结尾)
const lastPart = parts[parts.length - 1] || "";
const endsWithPunctuation = sentenceEndingsRegex.test(pendingText.current.slice(-1));
if (endsWithPunctuation) {
// 如果原文本以标点结尾,则最后一部分也完整
if (lastPart.trim()) {
completeSentences.push(lastPart + (endings[endings.length - 1] || ''));
}
remaining = "";
} else {
// 否则保留为 pending
remaining = lastPart;
}
// 是否强制 flush 剩余内容?
const shouldFlushRemaining =
charCount >= 60 ||
timeSinceLastUpdate > 1500;
if (shouldFlushRemaining && remaining.trim()) {
completeSentences.push(remaining);
remaining = "";
}
// 处理所有完整句子
completeSentences.forEach(sentence => {
if (sentence.trim()) {
enqueueTts(sentence);
}
});
// 更新 pendingText
pendingText.current = remaining;
};
const chatWithAgent = (
message: string,
postProcess?: (conversation_id: string, message_id: string, think: string, content: string) => void
) => {
addChatRecord({ role: CHAT_ROLE.HUMAN, think: "", content: message });
addChatRecord({ role: CHAT_ROLE.AI, think: "", content: "" });
controller.current = new AbortController();
setChatting(true);
fullRawText.current = "";
pendingText.current = "";
displayedContent.current = "";
lastTextUpdateTime.current = 0;
agentThinkRef.current = "";
ttsQueue.current = [];
isProcessingTts.current = false;
const agentCallback = (response: EventResponse) => {
const { event, data } = response;
switch (event) {
case STREAMING_EVENT_TYPE.CONVERSATION_ID:
conversationId.current = data;
break;
case STREAMING_EVENT_TYPE.MESSAGE_ID:
messageId.current = data;
break;
case STREAMING_EVENT_TYPE.THINK:
agentThinkRef.current += data;
updateLastRecord({
role: CHAT_ROLE.AI,
think: agentThinkRef.current,
content: displayedContent.current
});
break;
case STREAMING_EVENT_TYPE.TEXT:
fullRawText.current += data;
pendingText.current += data;
lastTextUpdateTime.current = Date.now();
if (sound) {
tryProcessPendingText();
} else {
displayedContent.current += data;
updateLastRecord({
role: CHAT_ROLE.AI,
think: agentThinkRef.current,
content: displayedContent.current
});
}
break;
case STREAMING_EVENT_TYPE.ERROR:
addToast({ title: data, color: "danger" });
break;
case STREAMING_EVENT_TYPE.TASK:
case STREAMING_EVENT_TYPE.DONE:
if (postProcess) {
postProcess(conversationId.current, messageId.current, agentThinkRef.current, fullRawText.current);
}
// 流结束,处理剩余文本
if (sound && pendingText.current.trim()) {
enqueueTts(pendingText.current);
pendingText.current = "";
}
setChatting(false);
break;
default:
break;
}
};
const agentErrorCallback = (error: Error) => {
setChatting(false);
};
//调用 api_agent_stream 时传入 mid
api_agent_stream(
agentEngine,
agentSettings,
message,
conversationId.current,
controller.current.signal,
agentCallback,
agentErrorCallback,
mid.current
);
};
const chat = (
message: string,
postProcess?: (conversation_id: string, message_id: string, think: string, content: string) => void
) => {
abort();
chatWithAgent(message, postProcess);
};
useEffect(() => {
conversationId.current = "";
return () => {
abort();
};
}, [agentEngine, agentSettings]);
return { chat, abort, chatting, conversationId, mid: mid.current };
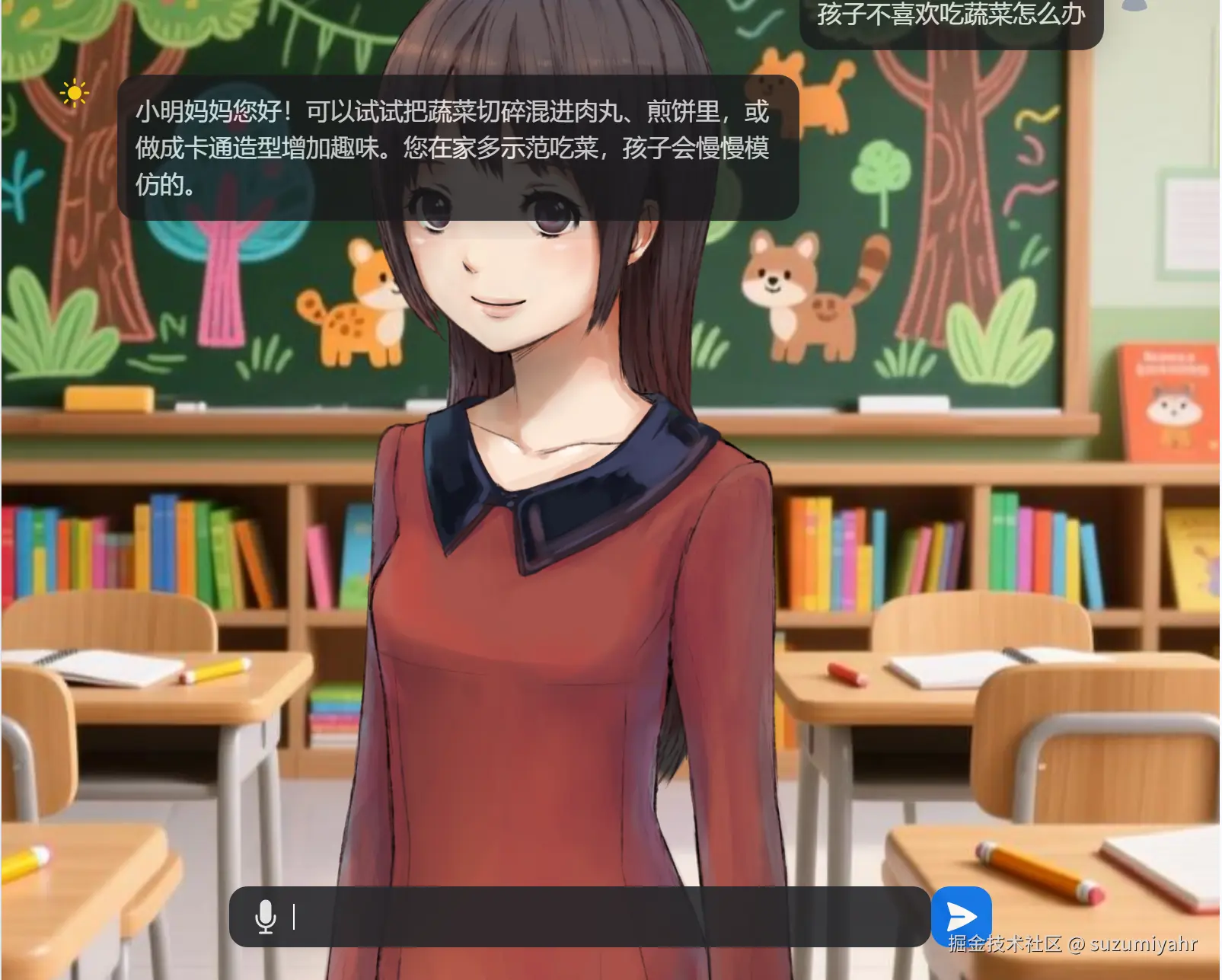
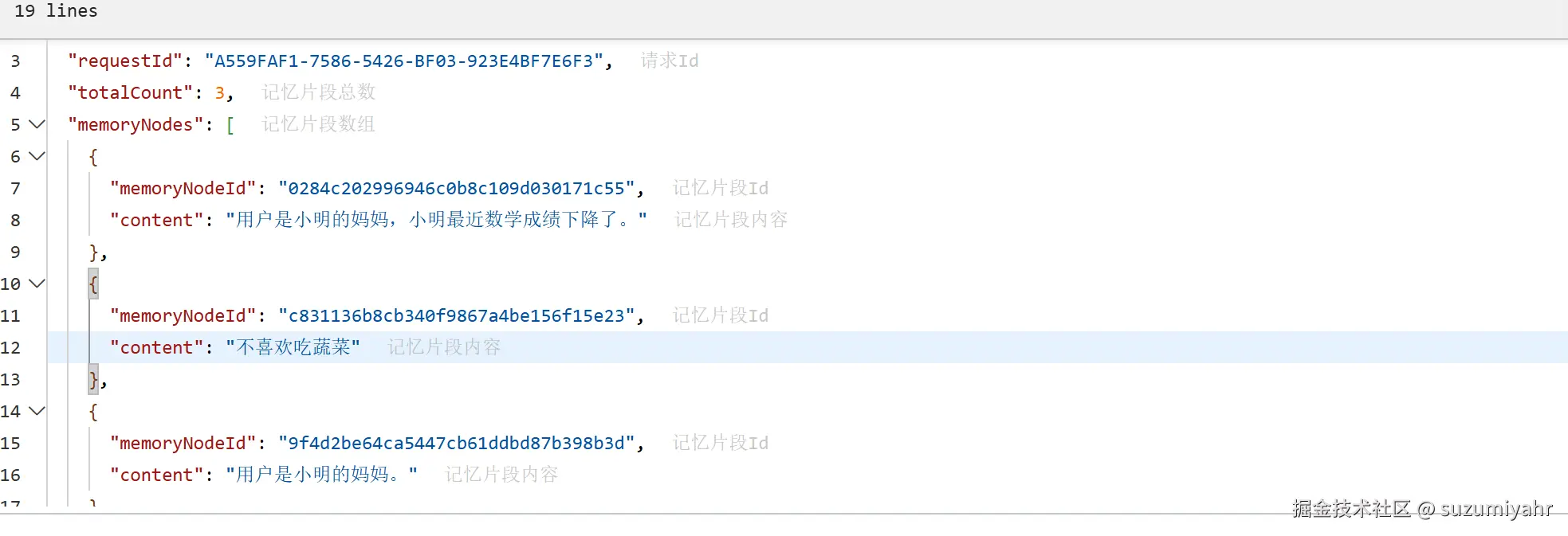
}到这里感觉完事大吉了,但是查看长期记忆列表居然没有数据,这是什么情况?经过多次实现发现自动写入记忆片段只有推理模式才能成功,但是开启推理模式等待时间过长,不适合数字人这种需要及时交互的场景,那么有没有解决的方法呢?
 我们可以使用阿里提供的另一个接口,主动创建记忆片段。 修改qwenAgent.py文件,具体逻辑就是在千问返回信息后,异步通过接口判断当前返回的内容是否需要抽取保存到记忆中,如果需要的话通过相关sdk进行保存
我们可以使用阿里提供的另一个接口,主动创建记忆片段。 修改qwenAgent.py文件,具体逻辑就是在千问返回信息后,异步通过接口判断当前返回的内容是否需要抽取保存到记忆中,如果需要的话通过相关sdk进行保存
#
from ..builder import AGENTS
from ..agentBase import BaseAgent
import os
import json
import asyncio
import re
from urllib.parse import urlencode
from digitalHuman.protocol import *
from digitalHuman.utils import httpxAsyncClient, logger
# DashScope SDK 导入
try:
from alibabacloud_bailian20231229.client import Client as bailian20231229Client
from alibabacloud_credentials.client import Client as CredentialClient
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_bailian20231229 import models as bailian_20231229_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_credentials.models import Config as CredentialConfig
SDK_AVAILABLE = True
except ImportError:
logger.warning("DashScope SDK not available, memory writing disabled")
SDK_AVAILABLE = False
__all__ = ["QwenAgent"]
@AGENTS.register("Qwen")
class QwenAgent(BaseAgent):
def __init__(self, config=None, engine_type=None):
"""初始化 QwenAgent,兼容父类构造函数"""
super().__init__(config, engine_type)
self._sdk_client = None
if SDK_AVAILABLE:
self._init_sdk_client()
def _init_sdk_client(self):
"""初始化 DashScope SDK 客户端 - 从环境变量读取 AK/SK"""
try:
access_key_id = os.getenv("DASHSCOPE_ACCESS_KEY_ID")
access_key_secret = os.getenv("DASHSCOPE_ACCESS_KEY_SECRET")
if not access_key_id or not access_key_secret:
logger.error("DASHSCOPE_ACCESS_KEY_ID or DASHSCOPE_ACCESS_KEY_SECRET not set in environment variables")
return
credential_config = CredentialConfig(
type='access_key',
access_key_id=access_key_id,
access_key_secret=access_key_secret
)
credential = CredentialClient(credential_config)
config = open_api_models.Config(credential=credential)
config.endpoint = 'bailian.cn-beijing.aliyuncs.com'
self._sdk_client = bailian20231229Client(config)
logger.info("DashScope SDK client initialized successfully")
except Exception as e:
logger.error(f"Failed to initialize SDK client: {e}")
self._sdk_client = None
#判断是否需要抽取记忆
def _should_extract_memory(self, text: str) -> bool:
"""轻量判断:是否可能包含可记忆信息"""
if not text.strip():
return False
triggers = [
"叫", "名字", "姓名", # 基本信息
"喜欢", "爱吃", "爱喝", "讨厌", "不吃", "过敏", # 饮食
"兴趣", "爱好", "擅长", "迷上", "喜欢玩", # 兴趣
"性格", "活泼", "内向", "安静", "调皮", # 性格
"年级", "学校", "班级", # 基本信息
"进步", "退步", "成绩", "考得", "学习", "作业" # 学习(趋势)
]
return any(trigger in text for trigger in triggers)
# qwen-max 抽取结构化记忆
async def _extract_memory_with_qwen_max(self, text: str, api_key: str, child_name: str = "") -> dict:
prompt = f"""
# 角色
你是一个严格的信息抽取系统,不是对话助手。你的唯一任务是从家长原话中提取结构化信息。
# 规则
1. 禁止任何解释、问候、反问、建议
2. 禁止输出 JSON 以外的任何字符(包括换行、空格、Markdown)
3. 如果没有可提取信息,必须输出:{{}}
4. 字段值必须是简洁的中文短语,不要完整句子
# 字段定义
- basic_info: "姓名,性别,年级"(如"李明,男,三年级")
- diet_preference: "饮食偏好"(如"喜欢吃西瓜")
- interests: "兴趣爱好"(如"喜欢画画")
- personality: "性格特点"(如"性格活泼")
- academic_trend: "学习趋势"(如"数学有进步")
# 家长原话
{text}
# 你的输出(纯 JSON,无任何其他内容):
"""
try:
resp = await httpxAsyncClient.post(
"https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation",
headers={"Authorization": f"Bearer {api_key}"},
json={
"model": "qwen-max",
"input": {"prompt": prompt.strip()},
"parameters": {
"max_tokens": 200,
"temperature": 0.01,
"stop": ["\n", "。", "!", "?", ":"]
}
},
timeout=10.0
)
if resp.status_code == 200:
data = resp.json()
raw_text = data.get("output", {}).get("text", "").strip()
logger.debug(f"[MemoryExtract] Raw output: '{raw_text}'")
# 尝试解析 JSON
try:
return json.loads(raw_text)
except:
# 尝试提取 {...}
match = re.search(r'\{[^{}]*\}', raw_text)
if match:
try:
return json.loads(match.group())
except:
pass
if raw_text == "{}":
return {}
logger.warning(f"[MemoryExtract] Failed to parse: {raw_text[:100]}")
except Exception as e:
logger.error(f"[MemoryExtract] Error: {e}", exc_info=True)
return {}
#使用 SDK 写入 DashScope Memory
async def _write_memory_node_with_sdk(self, app_id: str, memory_id: str, content: str):
if not SDK_AVAILABLE or self._sdk_client is None:
logger.warning("[MemoryWrite] SDK not available, skipping write")
return
if not app_id or not memory_id or not content.strip():
logger.warning("[MemoryWrite] Skip empty app_id, memory_id or content")
return
try:
logger.info(f"[MemoryWrite] Attempting to write via SDK - app_id: '{app_id}', memory_id: '{memory_id}', content: '{content}'")
create_memory_node_request = bailian_20231229_models.CreateMemoryNodeRequest(
content=content
)
runtime = util_models.RuntimeOptions()
headers = {}
space_id = os.getenv("DASHSCOPE_SPACE_ID")
response = await self._sdk_client.create_memory_node_with_options_async(
space_id,
memory_id,
create_memory_node_request,
headers,
runtime
)
logger.info(f"[MemoryWrite] SDK SUCCESS - MemoryNode ID: {response.body.memory_node_id}")
except Exception as e:
logger.error(f"[MemoryWrite] SDK EXCEPTION: {e}")
#后台记忆更新任务
async def _background_memory_update(self, user_input: str, app_id: str, memory_id: str, api_key: str):
await asyncio.sleep(0.5)
child_name = ""
extracted = await self._extract_memory_with_qwen_max(user_input, api_key, child_name)
logger.info(f"[Memory] Extracted result: {extracted}")
for key, value in extracted.items():
if value:
pure_content = value
logger.info(f"[Memory] Writing pure content: {pure_content}")
await self._write_memory_node_with_sdk(app_id, memory_id, pure_content)
async def run(
self,
input: TextMessage,
streaming: bool,
**kwargs
):
try:
if not streaming:
raise KeyError("Tongyi Agent only supports streaming mode")
# 获取 API 参数(从环境变量或参数)
api_key = kwargs.get("api_key") or os.getenv("DASHSCOPE_API_KEY")
app_id = kwargs.get("app_id") or os.getenv("DASHSCOPE_APP_ID")
session_id = (kwargs.get("conversation_id") or kwargs.get("session_id") or "").strip()
memory_id = kwargs.get("mid") or ""
messages = kwargs.get("messages", [])
if not api_key:
raise ValueError(
"Missing 'api_key': please provide it in parameters "
"or set DASHSCOPE_API_KEY environment variable."
)
if not app_id:
raise ValueError(
"Missing 'app_id': please provide it in parameters "
"or set DASHSCOPE_APP_ID environment variable."
)
prompt = input.data.strip()
#模式判断:messages 优先级高于 session_id
use_custom_messages = bool(messages)
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"X-DashScope-SSE": "enable"
}
payload = {
"input": {},
"parameters": {
"incremental_output": True
},
"stream": True
}
url = f"https://dashscope.aliyuncs.com/api/v1/apps/{app_id}/completion"
if memory_id:
payload["input"]["memory_id"] = memory_id
if use_custom_messages:
logger.info("[QwenAgent] Using custom 'messages' mode. session_id will be ignored.")
for msg in messages:
if not isinstance(msg, dict) or "role" not in msg or "content" not in msg:
raise ValueError("Each message must be a dict with 'role' and 'content'")
final_messages = messages.copy()
if prompt:
final_messages.append({"role": "user", "content": prompt})
payload["input"]["messages"] = final_messages
else:
if not prompt:
raise ValueError("Prompt is required when not using 'messages'.")
logger.info(f"[QwenAgent] Using standard mode with session_id: '{session_id or '(new)'}'")
payload["input"]["prompt"] = prompt
if session_id:
url += "?" + urlencode({"session_id": session_id})
payload["input"]["session_id"] = session_id
logger.info(f"[QwenAgent] Request URL: {url}")
logger.info(f"[QwenAgent] Payload: {payload}")
#异步触发记忆抽取
if memory_id and self._should_extract_memory(prompt):
logger.info("[Memory] Triggering async memory extraction...")
asyncio.create_task(
self._background_memory_update(prompt, app_id, memory_id, api_key)
)
#发起主请求(保持原有逻辑不变)
async with httpxAsyncClient.stream("POST", url, headers=headers, json=payload) as response:
logger.info(f"[QwenAgent] Response status: {response.status_code}")
if response.status_code != 200:
error_text = await response.aread()
try:
err_json = json.loads(error_text)
msg = err_json.get("message", error_text.decode())
except Exception:
msg = error_text.decode()
error_msg = f"HTTP {response.status_code}: {msg}"
logger.error(f"[QwenAgent] Request failed: {error_msg}")
yield eventStreamError(error_msg)
return
got_conversation_id = False
async for chunk in response.aiter_lines():
line = chunk.strip()
if not line or line == ":":
continue
if line.startswith("data:"):
data_str = line[5:].strip()
if data_str == "[DONE]":
break
try:
data = json.loads(data_str)
except json.JSONDecodeError as e:
logger.warning(f"[QwenAgent] JSON decode error: {e}, raw: {data_str}")
continue
logger.debug(f"[QwenAgent] SSE data received: {data}")
if not got_conversation_id and not use_custom_messages:
cid = data.get("output", {}).get("session_id")
if cid:
if not session_id or cid != session_id:
logger.info(f"[QwenAgent] New conversation_id received: {cid}")
yield eventStreamConversationId(cid)
got_conversation_id = True
text = data.get("output", {}).get("text", "")
if text:
yield eventStreamText(text)
yield eventStreamDone()
except Exception as e:
logger.error(f"[QwenAgent] Exception: {e}", exc_info=True)
yield eventStreamError(str(e))这样一个支持语音输出输入,长短期记忆的live2d数字人就完成了