前言
直言的说
笔者对数据不感兴趣,所以是什么网址不重要,里面的内容也不重要。
笔者只是想进行这个爬虫这个爬的过程。
网址如下
gnAtLt84GJxI1YuZnOWEI+WOiG1VR9ip0NZek1C8tpVnP246hSGiP14R66kcvnle
加密网址的函数
javascript
const CryptoJS = require('crypto-js');
let key='1234567890123456'
let iv='abcdef9876543210';
function encryptUrl(url, key, iv) {
return CryptoJS.AES.encrypt(url, CryptoJS.enc.Utf8.parse(key), {
iv: CryptoJS.enc.Utf8.parse(iv),
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
}).toString();
}哈哈哈哈哈哈,哈哈哈哈哈(0.0)(0.0)(0.0)
正文
分析
进去之后,发现请求里面有这些参数
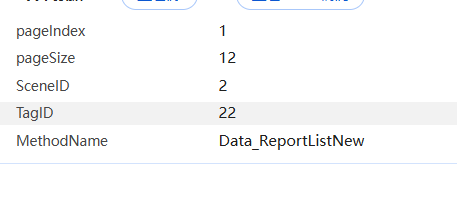
都没有进行加密,请求头里面也没有什么加密
但是发现响应是加密的
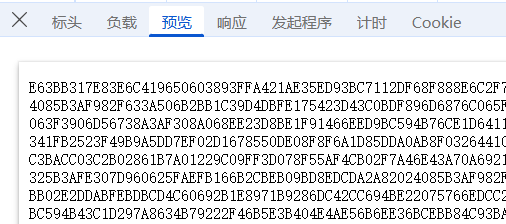
直接看堆栈的调用
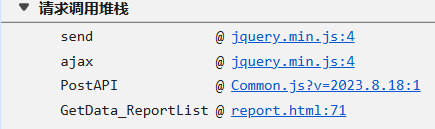
可以发现是html 到Common.js 到jquery
直接点击Common.js,进去看看
发现了关键

这个success,就jquery发送请求,成功后的处理
里面可以看到有一个webInstace.shell(e)
打个断点,看看
刚开始是加密的
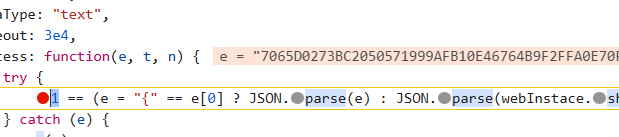
经过之后

可以发现e被解密出来了,那**webInstace.shell(e)**就是解密函数
进去看看
发现是经过混淆的代码,但是,笔者发现是在一个js文件里面

而且关键的一点

笔者发现了webInstace,那就简单了,直接把整个文件都复制下来
前置准备
- 新建一个文件夹
- 新建一个index.js文件
- 把webDES.min.js复制到index.js
- 新建一个index.html
- 导入index.js
其中index.html的内容如下
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="index.js"></script>
<script>
console.log(webInstace)
</script>
</head>
<body>
</body>
</html>笔者先打印看看情况,看有没有这个对象,结果如下
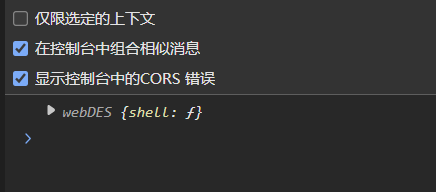
哈哈哈哈哈哈,可以
那问题已经解决了,没报错。
去掉打印语句
编写爬虫
先使用爬虫来试试,很简单,代码如下
python
import requests
from DrissionPage import ChromiumPage
page= ChromiumPage()
url = '*****'
data = {
'pageIndex': '4',
'pageSize': '12',
'SceneID': '2',
'TagID': '',
'MethodName': 'Data_ReportListNew'
}
resp = requests.post(url, data=data)
page.get('http://localhost:63342/..../index.html')
decrypted_data = page.run_js("return JSON.parse(webInstace.shell(arguments[0]))", resp.text)
print(decrypted_data)笔者发现不需要请求头,结果如下
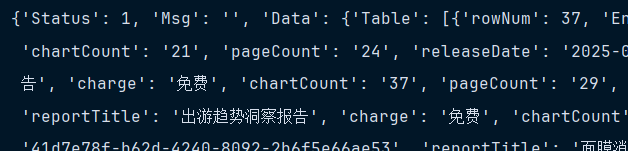
说实话,没什么意思,虽然解密的函数是混淆的,但是可以绕过去,不需要解密
使用mitmproxy试试
页面是通过jquery发送的请求,然后在jquery的success里面解密的,那么笔者也使用jquery
编写爬虫,不需要请求头,那更简单了
代理文件都不需要写,直接启动mitmproxy就可以
那么,index.html文件的内容如下
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="index.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script>
</head>
<body>
<script>
const params = {
pageIndex: '4',
pageSize: '12',
SceneID: '2',
TagID: '',
MethodName: 'Data_ReportListNew'
};
$.post('http://localhost:8082/API/GetData.ashx',params, function (data) {
console.log(JSON.parse(webInstace.shell(data)));
});
</script>
</body>
</html>使用8082端口,这看个人的选择,无所谓
启动
mitmweb --mode reverse:xxxxx -p 8082
结果如下
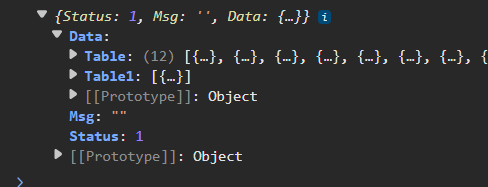
没问题。
总结
mitmproxy是真好玩。