采集数据的几种方式
1.request:简单,没有约束 request.get/post,难点在于逆向
2.playwright:通过代码操纵浏览器,实际上发送请求的是浏览器,难点在于怎么控制
如果没有特殊要求,哪个方便那个能拿到数据就用哪个
找工作必须要会的:逆向,自动化 ,scrapy
3.scrapy:框架半成品的爬虫项目,本身以异步的方式来实现的
什么是框架?
框架是一套可复用的、半成品的软件架构,它为开发者提供了一套基础结构、设计模式、工具集合和开发规范,目的是让开发者能更高效、更规范地构建应用程序。
使用框架的优缺点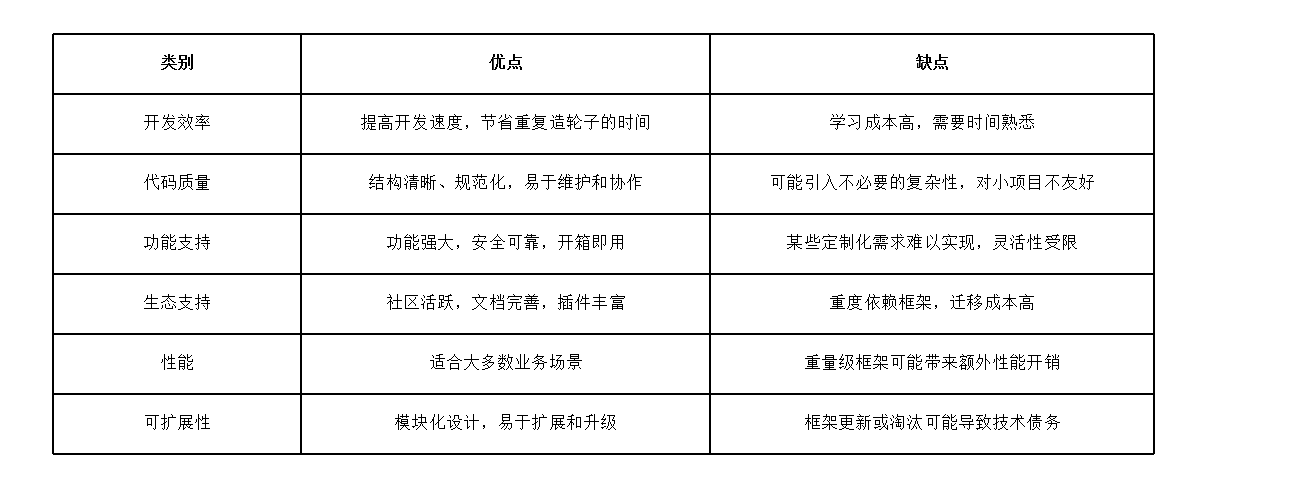
比较框架和库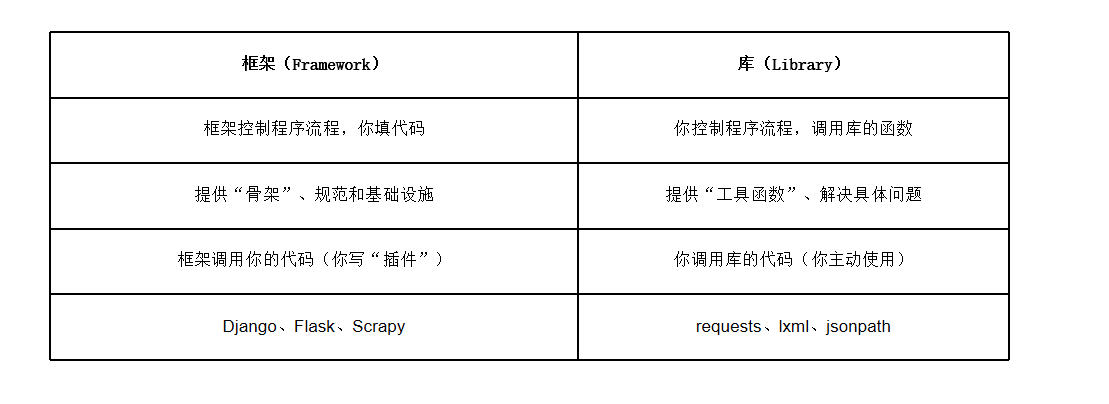
scrapy的简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。
安装:pip install scrapy
使用步骤:
一个基本的scrapy爬虫
1.创建一个新的Scrapy项目:(用命令来创建)
scrapy startproject projectname(名称可以自己改)
2.创建一个爬虫:
scrapy genspider spidername domainname(给一个域名)
3.编写爬虫逻辑:在爬虫的目录中,可以编辑parse()函数,在其中编写爬取网页的代码
4.运行爬虫:(命令行运行)
scrapy crawl spidername
注意事项:上面的命令,必须在对应的文件夹之下执行
且爬虫名称不要和项目名称相同
举例代码
import scrapy
# 创建了一个爬虫类【继承scrapy.Spider父类】
class Baidu01Spider(scrapy.Spider):
# 爬虫名称
name = "baidu01"
# allowed_domains 允许访问的域名
allowed_domains = ["www.baidu.com"]
# start_urls 开始的网站
start_urls = ["https://www.baidu.com/"]
# response 形参【只需要管好看】,真正起到作用的是实参,实参是框架传递的
# 这个方法必须是这个名称【因为他是重写父类的方法】
# 参数随意 response 代表响应对象 =》下载器给的
def parse(self, response): (方法必须是parse这个名称)
# response 就是响应对象
# print(response.url)
print(response.text)
# print("HELLO WORLD")
常用配置文件
BOT_NAME: 项目的名字,用于区分不同的 Scrapy 项目
LOG_LEVEL: 日志级别,控制日志的输出程度
CRITICAL:仅输出最高级别的严重错误消息
ERROR:输出错误和更严重级别的消息
WARNING:输出警告和更严重级别的消息
INFO(默认值):输出常规信息、警告和错误消息
DEBUG:输出详细的调试信息,包括请求和响应数据
USER_AGENT: 请求中的 User-Agent,用于伪装浏览器身份
ROBOTSTXT_OBEY: 是否遵守 robots.txt 规则,控制是否爬取被禁止的页面
CONCURRENT_REQUESTS: 并发请求数的最大值,用于控制同时发出的请求数量
DOWNLOAD_DELAY:请求之间的延迟(防封)
ITEM_PIPELINES: 定义数据处理管道的优先级,指定对数据进行处理的模块
DEFAULT_REQUEST_HEADERS:请求头设置
SPIDER_MIDDLEWARES/DOWNLOADER_MIDDLEWARES:爬虫/下载中间件
COOKIES_ENABLED: 是否启用 Cookie 功能,用于处理和发送请求中的 Cookie
实操过程中没有响应,因为自动遵守robots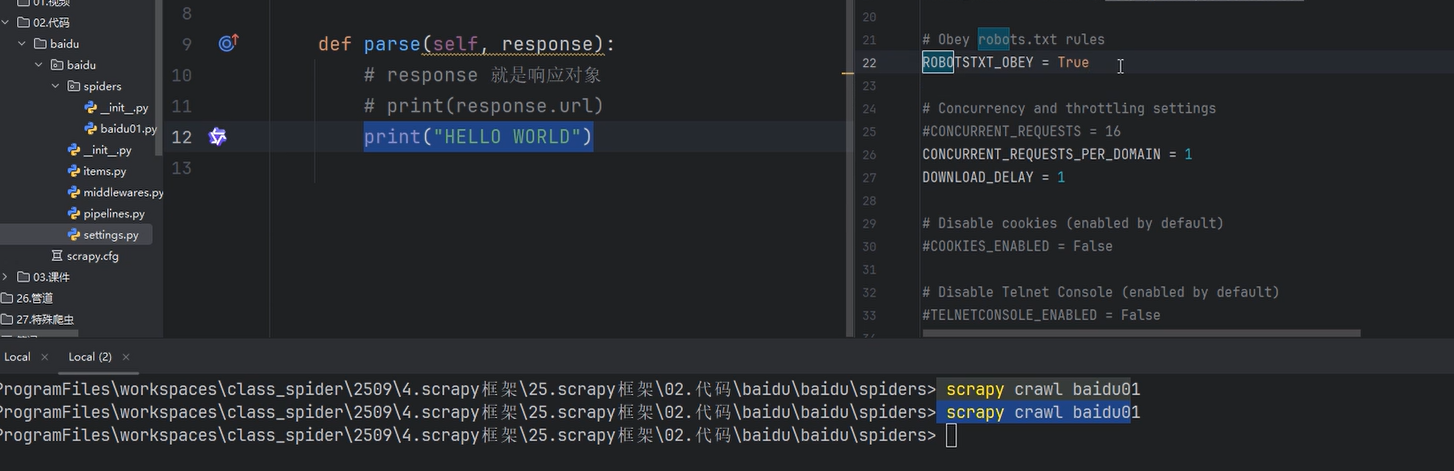
找到robots将true改为false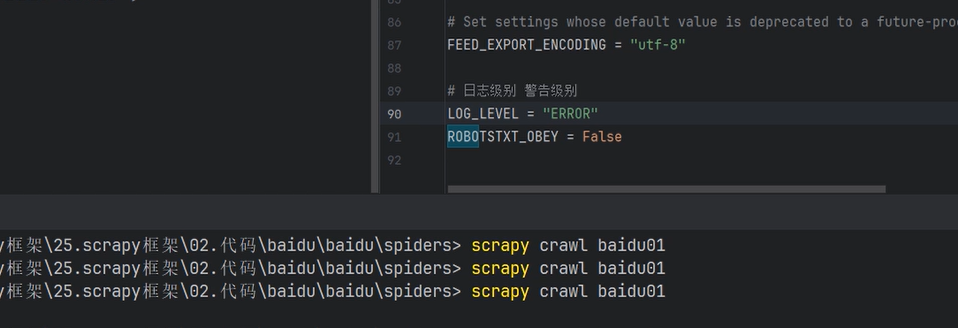
scrapy的特点
scrapy 特点
1,异步处理:Scrapy 使用异步网络库(如 Twisted)来实现高效的并发请求处理,可以同时发送多个请求并处理响应。
2,基于选择器的数据提取:Scrapy 提供了强大的数据提取机制,使用类似于 XPath 的选择器语法,可以方便地从网页中提取所需的数据。
3,中间件支持:Scrapy 提供了中间件机制,可以在请求和响应的处理过程中进行自定义的操作,例如修改请求头部、处理异常、设置代理等。
4,自动的请求调度和去重:Scrapy 负责自动管理请求的调度和去重,确保每个链接只被访问一次。
5,分布式爬取:Scrapy 可以与分布式任务调度系统结合使用,实现分布式爬取和部署。
组件介绍

spiders可以存在多个爬虫文件的,
核心组件
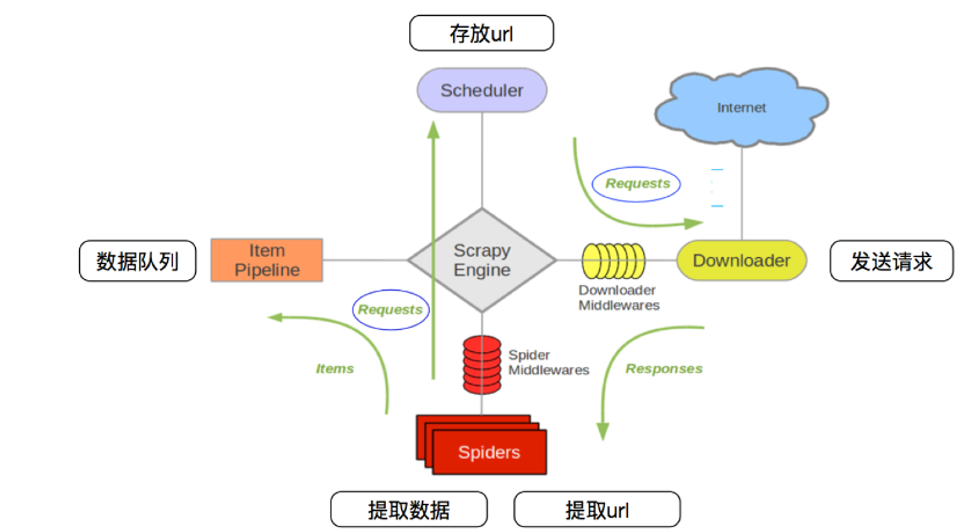
1.引擎 (Engine):Scrapy引擎负责控制数据流在所有组件之间的流动,并在相应动作发生时触发事件。
2.调度器 (Scheduler):调度器负责获取请求并将其排队,以便引擎后续处理。
3.下载器 (Downloader):下载器负责获取网页内容。当调度器传递一个请求给下载器时,下载器会下载该请求对应的URL内容。
4.爬虫 (Spiders):爬虫是用户自定义的类,用于解析网页内容并提取数据。爬虫通常从一个或多个起始URL开始,然后跟踪网页中的链接以发现更多内容。(必须我们自己写的)
5.项目管道 (Item Pipelines):管道负责处理爬虫提取的数据。用户可以自定义管道来实现数据的清洗、验证、持久化等操作。(保存)
scrapy执行流程
1.引擎启动:Scrapy 的执行从启动引擎开始。
2.发送初始请求:引擎根据配置的初始 URL,发送第一个请求
3.调度器分发请求:请求被发送到调度器,调度器负责管理待处理的请求队列,并根据调度算法选择下一个要处理的请求
4.下载器下载网页:调度器将请求传递给下载器,下载器负责下载网页,然后返回响应给引擎
5.Spider处理响应:引擎将响应传递给对应的 Spider 进行处理。Spider 是编写的爬虫程序,通过编写 Spider 类来定义如何解析响应、提取数据和生成新的请求
6.生成新请求:在 Spider 中,可以通过 yield 关键字生成更多的请求,这些请求会被添加到调度器中等待处理
7.数据处理与持久化(管道):当 Spider 解析响应并提取数据后,将数据传递给管道进行处理和持久化操作
8.继续处理新请求:重复执行步骤 3-7,直到调度器中没有待处理的请求
9.爬虫关闭:当所有请求处理完成后,引擎会发出信号通知爬虫关闭,并执行一些必要的清理操作
响应对象
数据解析
Scrapy 框架提供了数据解析 API,主要用于从网页内容中提取结构化数据。
response.xpath('xpath表达式'):使用 XPath 提取数据。
element.get():提取第一个结果的字符串。
element.getall():提取所有结果的列表。