本文我们来学习一下多线程,多线程实际是用的最多的多任务爬虫,优势是:好控制,且速度不像协程一样过于快,我们直接通过小demo来了解多线程
函数多线程
依旧请出豆瓣Top250:
python
import requests
from lxml import etree
# 线程库
import threading
url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0'
}
def get_data(page):
res = requests.get(url.format(page * 25), headers=headers)
tree = etree.HTML(res.text)
result = tree.xpath('//div[@class="hd"]/a/span[1]/text()')
print(result)
if __name__ == '__main__':
# 创建十个线程对象,target是目标函数,arg是按元组传入目标函数的参数
thread_list = [threading.Thread(target=get_data, args=(page,)) for page in range(10)]
# 启动线程
for t in thread_list:
t.start()这里就是创建十个线程来运行get_data这个函数,然后线程列表循环取出线程对象,然后启动对象
基于线程池的函数多线程
依旧豆瓣:
python
import requests
from lxml import etree
# 线程库
import threading
# 线程池库
from concurrent.futures import ThreadPoolExecutor, as_completed
# 线程池
url = 'https://movie.douban.com/top250?start={}&filter='
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0'
}
def get_data_(page):
res = requests.get(url.format(page * 25), headers=headers)
tree = etree.HTML(res.text)
result = tree.xpath('//div[@class="hd"]/a/span[1]/text()')
print(result)
if __name__ == '__main__':
with ThreadPoolExecutor(max_workers=10) as pool:
# 通过线程池对象完成任务提交, 提交的括号内不能写args=(1,),语法为pool.submit(函数, 函数的参数1, 函数的参数2, ...)
[pool.submit(get_data_, page) for page in range(10)]这里还需要将一个东西,当我们拿到数据想要交给另一个函数处理时,要return出来,但是返回到列表中得到的是future对象:
我们通过遍历来得到结果,但你会发现,这里得到的结果都是按顺序的,说明我们并发的目的并没有达到:
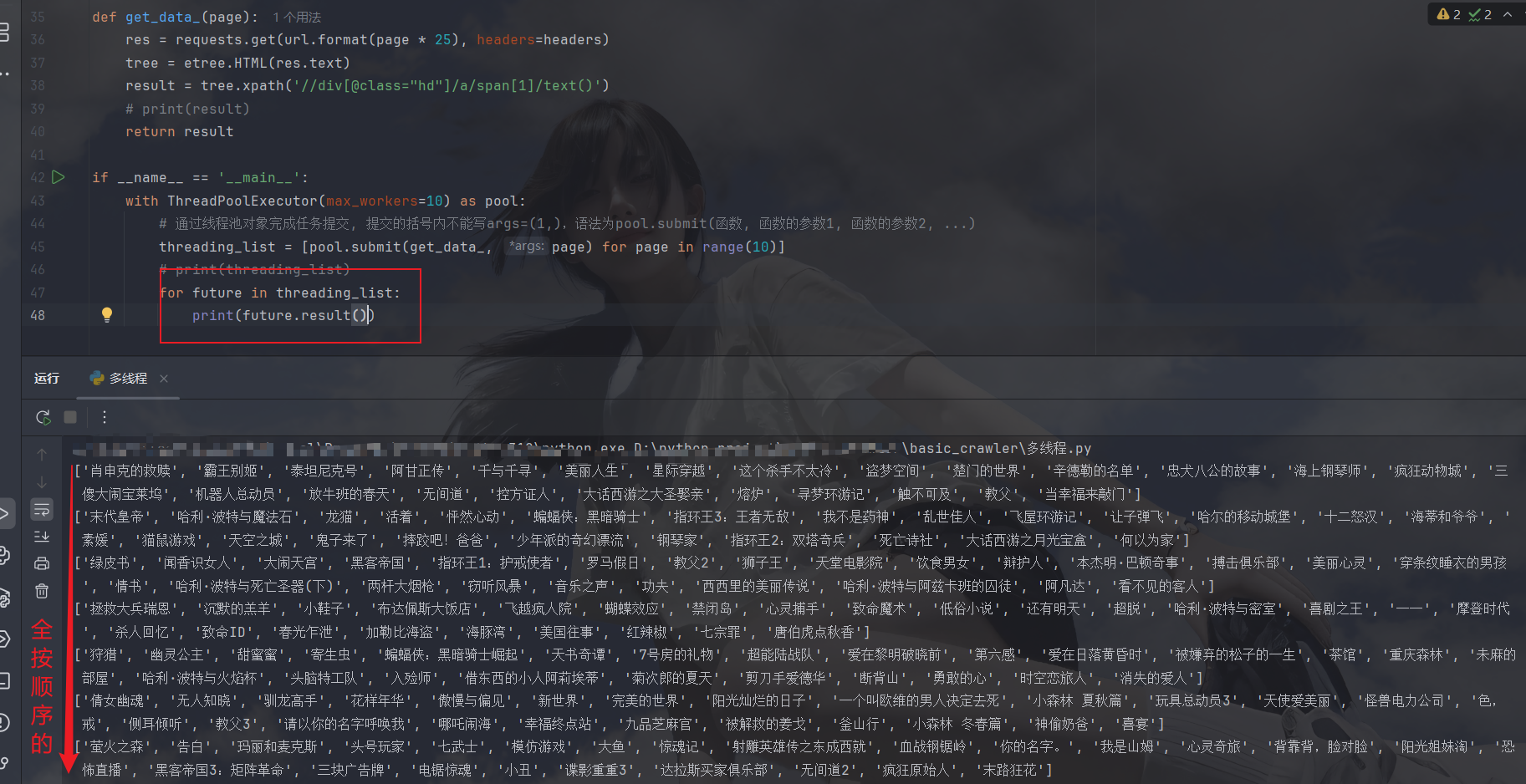
其实这都是result()的锅,他会阻塞线程保证输出是按顺序的,某一页解析完他不返回,而是按创建线程的顺序得到结果,这样会拖慢我们的进度,所以这时候就要用到引入线程池时引入的另一个方法了------as_completed:
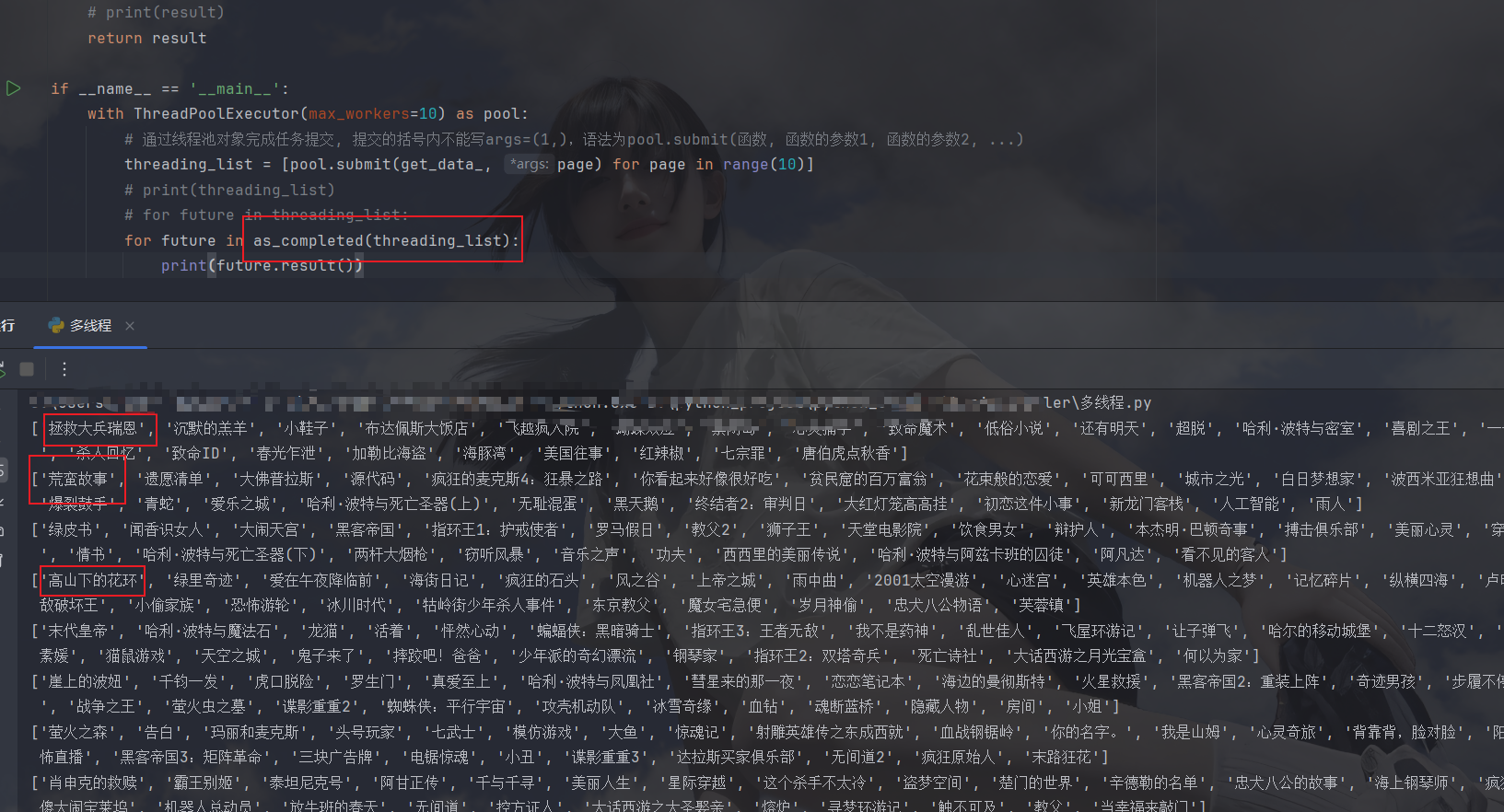
什么原理呢,as_completed方法会将列表转化为生成器,生成器里的数据是按照完成顺序来返回的,这时候得到的结果就是随机的了
守护线程
咱们先来看这样一段代码和他的运行结果:
python
def thread_n(page):
for _ in range(page):
time.sleep(0.1) # 模拟解析提取数据过程
print('得到第', _, '页数据')
if __name__ == '__main__':
threading_lst = [threading.Thread(target=thread_n, args=(66,)) for i in range(3)]
for t in threading_lst:
t.start()
time.sleep(2)
print('数据存储成功!!')运行结果:
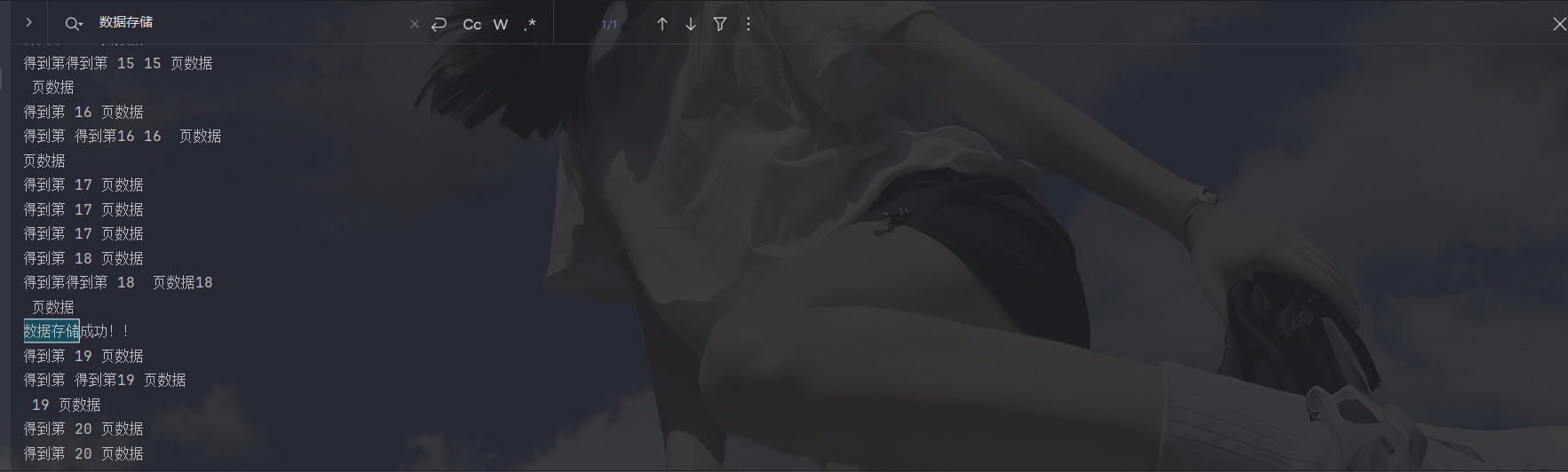
可以看到这里我们数据还没完全爬取完就已经存储完成了,存储完成不说,下面还一直在继续爬取和解析提取数据,这种怎么办,我们可以试试守护线程,开启守护线程后,当主线程停止工作后,子线程就立刻停止:
再看一下结果:
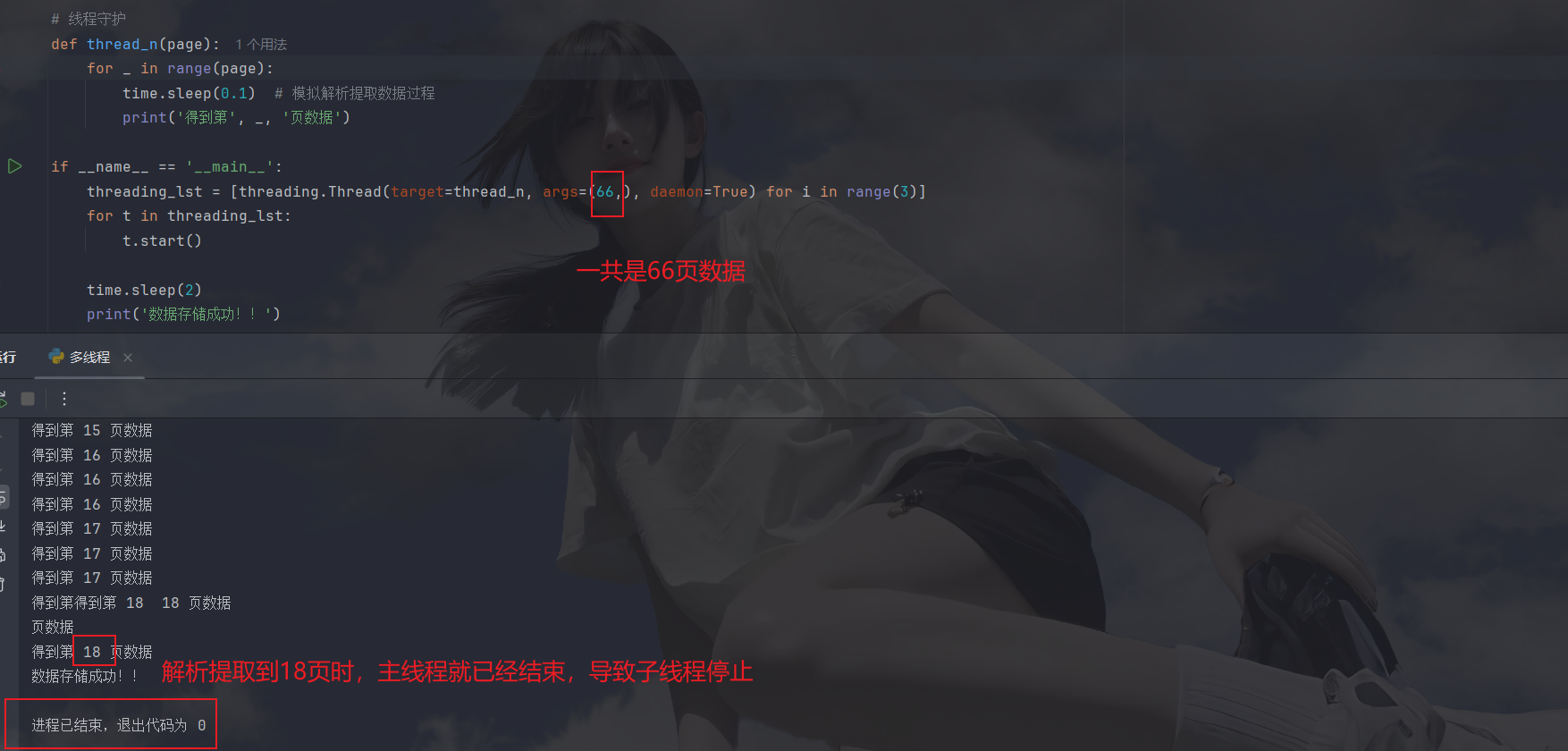
子线程是停止了,但是并没有保证数据完整性,还需要借助其他的东西,那就是join方法阻塞主线程
join阻塞主线程
先看代码:
python
# 线程守护
def thread_n(page):
for _ in range(page):
time.sleep(0.1) # 模拟解析提取数据过程
print('得到第', _, '页数据')
if __name__ == '__main__':
threading_lst = [threading.Thread(target=thread_n, args=(66,), daemon=True) for i in range(3)]
for t in threading_lst:
t.start()
for join_t in threading_lst:
join_t.join()
time.sleep(2)
print('数据存储成功!!')新加那两行的意思是给线程列表中的每一个线程都加一个命令:你们没完成任务不要回来,当他们都完成了任务时才继续往下运行主线程,看一下结果是不是如此:

这个倒是解决了,但是还有一个隐藏的问题------解析数据是多线程,但存储却是单线程,解析速度肯定是比存储快的,那解析的数据多的放在哪儿,可能有的朋友会觉得那不直接return 回线程列表吗,但是当通过threading.Thread启动线程时,thread_n的return值会被直接丢弃,不会被任何对象(包括线程实例)主动保存,因此无法自动进入threading_lst
除此之外我们还发现这三个线程是每一个线程执行一遍0~65页这66页,不仅速度没提高还得到了两遍重复数据,这事儿整的,不过没关系,我们还有招,引出我们的queue队列
queue队列
queue是一个第三方库名字,直接pip安装即可,它可以让每一个线程来队列里取数据,每取一次就会在队列中剔除也个数据,这样就保证不会重复了,然后它还是一个暂存信息的地方,理论上来说可以存无限的数据,但是受限于系统内存(我们也不可能让系统内存全占满,所以会设置maxsize来设置最大容量形成有界列表),当系统内存占满时此时会直接抛出`MemoryError`(程序崩溃),下面来说一下最常用的用法:
python
1.queue.get() # 取数据
2.queue.put() # 放入数据
3.queue.task_done() # 每取出一个数据就会标记一次任务完成
4.queue.empty() # 当队列为空时返回True下面需要对原来代码进行大改造了,先来解决重复问题 ↓↓↓
首先就是将任务全部放进一个队列中:
python
queue1 = Queue()
for page in range(1, 100):
queue1.put(page)然后写一个函数取出队列中的内容:
python
def get_data():
while True:
if not queue1.empty():
data = queue1.get()
queue1.task_done() # 每次取完就会标记一次任务成功
print('得到数据', data)
else:
break创建主函数入口开始多线程处理:
python
if __name__ == '__main__':
# 创建线程
thread = [threading.Thread(target=get_data) for _ in range(3)]
for t in thread:
# 启动线程
t.start()建立阻塞,下面是完整代码:
python
queue1 = Queue()
for page in range(1, 100):
queue1.put(page)
def get_data():
while True:
if not queue1.empty():
data = queue1.get()
print('得到数据', data)
else:
break
if __name__ == '__main__':
# 创建线程
thread = [threading.Thread(target=get_data) for _ in range(3)]
for t in thread:
# 启动线程
t.start()
for main_t in thread:
main_t.join()
print('-----------开始存储-------------')
time.sleep(2)
print('存储完成...')再来解决存储问题 ↓↓↓
再次创建一个队列,然后将得到的数据data填进队列中,然后在外部依次取出:
python
# 上面代码大改造:
queue1 = Queue()
for page in range(1, 100):
queue1.put(page)
queue2 = Queue() # 存储所需队列
def get_data():
while True:
if not queue1.empty():
data = queue1.get()
# queue1.task_done() # 每次取完就会标记一次任务成功
print('得到数据', data)
# 开始放入存储队列
queue2.put(data)
else:
break
if __name__ == '__main__':
# 创建线程
thread = [threading.Thread(target=get_data) for _ in range(3)]
for t in thread:
# 启动线程
t.start()
for main_t in thread:
main_t.join()
print('-----------开始存储-------------')
num = 1
while True:
if not queue2.empty():
queue2.get() # 存一个取出来一个
num += 1
print('存储', num)
queue2.task_done()
else:
break
queue2.join() # 当都标记完成时
time.sleep(2)
print('存储完成...')但是这样并不是极限,因为当产生的数据全部存储到队列中后才能开始存储操作,那我们能不能一边生产一边消费呢,下面来讲一下生产者-消费者模式
生产者-消费者模式
建立两个函数,一个是producer,另一个是consumer,一个解析提取,一个存储(顺便将存储也变成多线程):
python
def producer():
while True:
if not pro_queue.empty():
# print('开始处理数据...')
"""
取队列里的数据的操作只能使用一次,
因为每取一次就会少一个数据,
在同一个循环多次使用相等于一次性取出好几个
"""
pro_data = pro_queue.get()
print('数据', pro_data)
pro_queue.task_done()
con_queue.put(f'数据{pro_data}')
else:
print('生产者队列已无数据...')
break
def consumer():
while True:
if not con_queue.empty():
data = con_queue.get()
print(f'存入数据{data}')
con_queue.task_done()
else:
print('消费者队列已无数据...')
break
if __name__ == '__main__':
pro_queue = Queue()
for page in range(1, 88):
pro_queue.put(page)
con_queue = Queue()
producer_thread = [threading.Thread(target=producer) for _ in range(5)]
for pt in producer_thread:
pt.start()
consumer_thread = [threading.Thread(target=consumer) for _ in range(2)]
for ct in consumer_thread:
ct.start()
# 先取消线程对象
for pt_join in producer_thread:
pt_join.join()
# 在保证put进pro_queue内的数据全部被标记为完成
pro_queue.join() # 相当于二次检测
for ct_join in consumer_thread:
ct_join.join()
con_queue.join()
print('主线程结束...')OK这个基本就是终极版了,再往后就是给他封装成两个类,一个class Producer 一个class Consumer
小结
本文到此就结束了,如果喜欢请持续关注,如有问题也请提出共同进步,加油加油