
🌍 什么是FIBO?
多数文生图模型擅长想象------而非控制。FIBO 专为专业工作流打造,非日常使用。通过长达1000+单词的结构化JSON标注 训练,FIBO能精准可复现地控制光照、构图、色彩及相机参数。结构化标注促进原生解耦能力,支持针对性迭代优化而无需担心提示偏移。仅凭80亿参数 ,FIBO即实现高画质、强提示遵循与专业级控制------完全基于授权数据训练。
最新动态
🔑 核心特性
- 视觉语言模型引导的JSON原生提示:整合任意VLM将简短提示转化为含1000+单词的结构化方案(光照、相机、构图、景深)。
- 迭代可控生成:从简短提示生成图像,或基于详细JSON与输入图像持续优化获取灵感
- 解耦控制:单独调整某属性(如镜头角度)而不破坏场景。
- 企业级:100%授权数据;具备治理、可复现性及法律明晰性。
- 强提示遵循:在PRISM式评估中展现高对齐度。
- 为生产环境打造:支持API端点(Bria平台、Fal.ai、Replicate)、ComfyUI节点及本地推理。
🎨 三种简易模式玩转FIBO
- 生成: 从快速构思开始。FIBO的语言模型会将简短提示扩展为丰富的结构化JSON提示,随后生成图像。 您将同时获得图像与扩展后的提示。
- 优化: 基于详细结构化提示继续创作,添加简短指令------例如"逆光"、"85毫米镜头"或"更暖肤色"。 FIBO将仅更新指定属性,重新生成图像并返回优化后的提示。
- 启发: 提供图像而非文本。FIBO的视觉-语言模型会提取详细结构化提示,融合您的创作意图,生成关联图像------是获取灵感又不过度依赖原图的理想选择。
⚡ 快速开始
FIBO 可应用于您构建的任何地方,无论是作为源代码和权重、ComfyUI 节点还是 API 端点。
API 端点:
ComfyUI:
源代码与权重
快速入门指南
安装Diffusers及附加依赖
通过源代码安装Diffusers:
bash
pip install git+https://github.com/huggingface/diffusers torch torchvision google-genai boltons ujson sentencepiece accelerate transformers生成
FIBO采用视觉语言模型(VLM),能将简短提示转化为详细的结构化提示词用于生成图像。您可通过以下代码调用Google API使用Gemini生成图像------**需提供GOOGLE_API_KEY**,或取消注释相关代码段切换至本地运行的视觉语言模型(FIBO-VLM)。
python
import json
import os
import torch
from diffusers import BriaFiboPipeline
from diffusers.modular_pipelines import ModularPipeline
# -------------------------------
# Load the VLM pipeline
# -------------------------------
torch.set_grad_enabled(False)
# Using Gemini API, requires GOOGLE_API_KEY environment variable
assert os.getenv("GOOGLE_API_KEY") is not None, "GOOGLE_API_KEY environment variable is not set"
vlm_pipe = ModularPipeline.from_pretrained("briaai/FIBO-gemini-prompt-to-JSON", trust_remote_code=True)
# Using local VLM, uncomment to run
# vlm_pipe = ModularPipeline.from_pretrained("briaai/FIBO-VLM-prompt-to-JSON", trust_remote_code=True)
# Load the FIBO pipeline
pipe = BriaFiboPipeline.from_pretrained(
"briaai/FIBO",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
# pipe.enable_model_cpu_offload() # uncomment if you're getting CUDA OOM errors
# -------------------------------
# Run Prompt to JSON
# -------------------------------
# Create a prompt to generate an initial image
output = vlm_pipe(
prompt="A hyper-detailed, ultra-fluffy owl sitting in the trees at night, looking directly at the camera with wide, adorable, expressive eyes. Its feathers are soft and voluminous, catching the cool moonlight with subtle silver highlights. The owl's gaze is curious and full of charm, giving it a whimsical, storybook-like personality."
)
json_prompt_generate = output.values["json_prompt"]
def get_default_negative_prompt(existing_json: dict) -> str:
negative_prompt = ""
style_medium = existing_json.get("style_medium", "").lower()
if style_medium in ["photograph", "photography", "photo"]:
negative_prompt = """{'style_medium':'digital illustration','artistic_style':'non-realistic'}"""
return negative_prompt
negative_prompt = get_default_negative_prompt(json.loads(json_prompt_generate))
# -------------------------------
# Run Image Generation
# -------------------------------
# Generate the image from the structured json prompt
results_generate = pipe(
prompt=json_prompt_generate, num_inference_steps=50, guidance_scale=5, negative_prompt=negative_prompt
)
results_generate.images[0].save("image_generate.png")
with open("image_generate_json_prompt.json", "w") as f:
f.write(json_prompt_generate)
精炼
FIBO支持迭代生成。给定结构化提示和指令后,FIBO会对输出进行优化改进。
python
output = vlm_pipe(
json_prompt=json_prompt_generate, prompt="make the owl brown"
)
json_prompt_refine_from_image = output.values["json_prompt"]
negative_prompt = get_default_negative_prompt(json.loads(json_prompt_refine_from_image))
results_refine_from_image = pipe(
prompt=json_prompt_refine_from_image, num_inference_steps=50, guidance_scale=5, negative_prompt=negative_prompt
)
results_refine_from_image.images[0].save("image_refine_from_image.png")
with open("image_refine_from_image_json_prompt.json", "w") as f:
f.write(json_prompt_refine_from_image) --> Make the owl brown(把猫头鹰变成棕色)
--> Make the owl brown(把猫头鹰变成棕色)  --> Turn the owl into a lemur(把猫头鹰变成狐猴)
--> Turn the owl into a lemur(把猫头鹰变成狐猴)  --> Add jungle vegetation(添加丛林植被)
--> Add jungle vegetation(添加丛林植被)  --> Add sunlight(添加阳光)
--> Add sunlight(添加阳光)
启迪
从一张图片开始汲取灵感,让Fibo重新生成它的变体,或将您的创意意图融入下一代作品中
python
from PIL import Image
original_astronaut_image = Image.open("<path to original astronaut image>")
output = vlm_pipe(
image=original_astronaut_image, prompt="")
json_prompt_inspire = output.values["json_prompt"]
negative_prompt = get_default_negative_prompt(json.loads(json_prompt_inspire))
results_inspire = pipe(
prompt=json_prompt_inspire, num_inference_steps=50, guidance_scale=5, negative_prompt=negative_prompt
)
results_inspire.images[0].save("image_inspire_no_prompt.png")
with open("image_inspire_json_prompt_no_prompt.json", "w") as f:
f.write(json_prompt_inspire)
output = vlm_pipe(
image=original_astronaut_image, prompt="Make futuristic")
json_prompt_inspire = output.values["json_prompt"]
negative_prompt = get_default_negative_prompt(json.loads(json_prompt_inspire))
results_inspire = pipe(
prompt=json_prompt_inspire, num_inference_steps=50, guidance_scale=5, negative_prompt=negative_prompt
)
results_inspire.images[0].save("image_inspire_with_prompt.png")
with open("image_inspire_json_prompt_with_prompt.json", "w") as f:
f.write(json_prompt_inspire) original image
original image  Inspire #1: No prompt
Inspire #1: No prompt  Inspire #2: Make futuristic
Inspire #2: Make futuristic
高级用法
Gemini配置 可选
FIBO支持将任何视觉语言模型(VLM)作为流程组成部分。如需使用Gemini作为FIBO的VLM主干,请按以下步骤操作:
-
获取Gemini API密钥
注册Google AI Studio (Gemini)并创建API密钥。
-
设置环境变量
将Gemini API密钥存入
GEMINI_API_KEY环境变量:bashexport GEMINI_API_KEY=您的_gemini_api密钥可将该命令添加至
.bashrc、.zshrc等shell配置文件实现永久生效。
详见示例目录中的案例演示。
🧠 训练与架构
FIBO 是基于DiT架构的80亿参数流匹配文生图模型,其训练数据全部采用授权素材 及超长结构化JSON标注 (每条约1000词),从而具备卓越的提示跟随能力和专业级控制精度。该模型采用SmolLM3-3B 作为文本编码器,创新性地引入DimFusion 调节架构以高效处理长文本训练,并选用Wan 2.2 作为变分自编码器。结构化监督机制实现了原生解耦特性,支持精准的迭代优化而不产生提示偏移,同时通过我们基于Qwen-2.5 微调的VLM或Gemini 2.5 Flash进行视觉语言辅助:可扩展简短用户意图、补全缺失细节,并能从图像中提取/编辑结构化提示。为保障可复现性,我们完整公开了"生成"、"优化"、"启发"三种模式下的辅助系统提示词及结构化提示JSON模板。
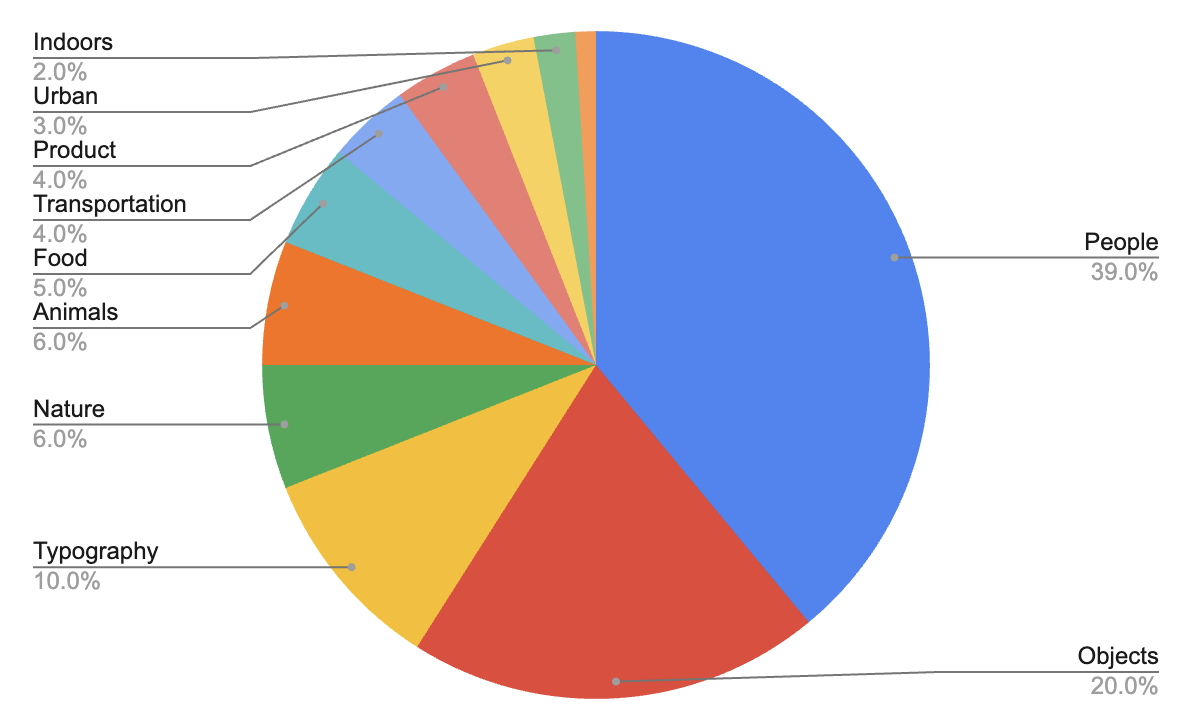
数据分布
FIBO的训练数据来自约10亿规模图像库的精选图文对,其分布情况如图所示。所有素材均通过商业用途审核,具备完整的溯源归属信息,并符合GDPR及欧盟AI法案的区域合规要求。这种广泛而均衡的数据分布确保FIBO能泛化处理从真人影像到平面设计、产品可视化等多元视觉领域,同时保持全流程的授权合规性。
评估
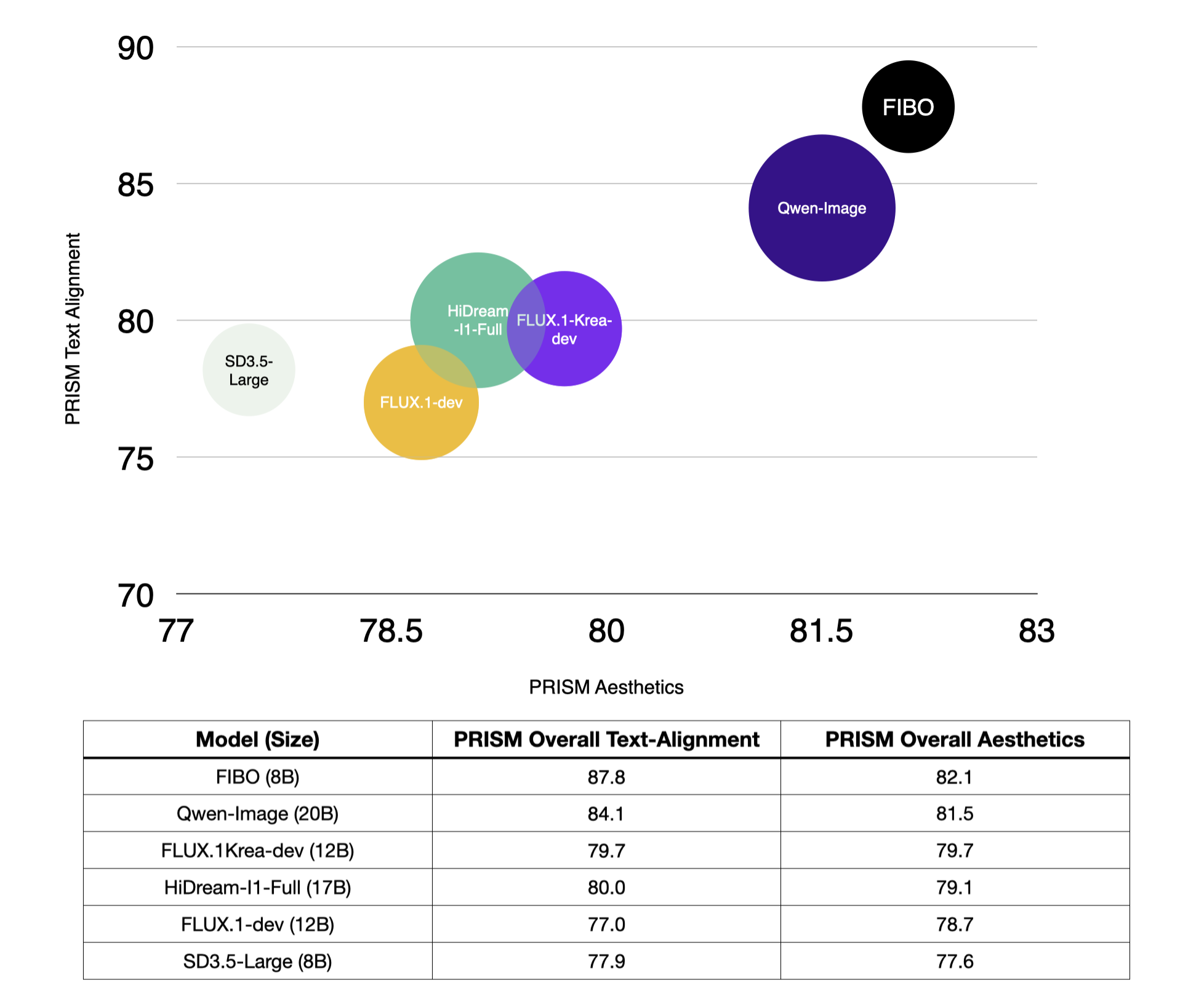
PRISM基准测试模型对比
使用PRISM-Bench的授权数据子集,我们评估了图文对齐性和美学表现。FIBO超越了同类开源基线模型,表明通过结构化描述训练实现了优秀的提示遵循性、可控性和美学表现。
更多示例
生成

启发与优化

FIBO的灵感来自斐波那契数列,数学通过黄金比例遇见美学------这是自然与设计永恒的和谐密钥。
如果您对本代码库有疑问、想分享反馈或希望直接贡献,我们欢迎您在GitHub上提交问题和拉取请求。您的贡献将帮助FIBO变得更好。
如果您对基础研究充满热情,我们正在招聘全职员工(FTE)和研究实习生。不要犹豫------请联系hr@bria.ai
引用
如果您觉得我们的工作有所帮助,我们诚挚地鼓励您引用。
bibtex
@misc{gutflaish2025generating,
title = {Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions},
author = {Gutflaish, Eyal and Kachlon, Eliran and Zisman, Hezi and Hacham, Tal and Sarid, Nimrod and Visheratin, Alexander and Huberman, Saar and Davidi, Gal and Bukchin, Guy and Goldberg, Kfir and Mokady, Ron},
year = {2025},
eprint = {2511.06876},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2511.06876},
url = {https://arxiv.org/abs/2511.06876}
}❤️ FIBO 模型卡 和 ⭐ 在 GitHub 上给 FIBO 点赞,加入负责任生成式 AI 的运动!