
文章目录
- [Ⅰ. `HttpContext`上下文模块设计](#Ⅰ.
HttpContext上下文模块设计) - [Ⅱ. 接口实现](#Ⅱ. 接口实现)
- [Ⅲ. `HttpServer`服务器模块设计](#Ⅲ.
HttpServer服务器模块设计) - [Ⅳ. 接口实现](#Ⅳ. 接口实现)
-
- 1、核心接口实现
- 2、连接建立完成后的回调处理
- 3、收到消息后的回调处理
- 4、辅助函数
-
- [① 路由查找函数](#① 路由查找函数)
- [② 静态资源处理函数](#② 静态资源处理函数)
- [③ 功能性请求函数处理](#③ 功能性请求函数处理)
- [④ 组织和响应处理函数](#④ 组织和响应处理函数)
- [⑤ 错误信息处理](#⑤ 错误信息处理)
- 5、简单首页登录页面
- 6、简单的错误页面
- [Ⅴ. 服务器主函数](#Ⅴ. 服务器主函数)
- [Ⅵ. 测试代码](#Ⅵ. 测试代码)
Ⅰ. HttpContext上下文模块设计
这个模块用于记录 HTTP 请求的接收和处理进度,因为有可能出现一种情况,就是接收的数据并不是一条完整的 HTTP 请求数据,也就是请求的处理需要在多次收到数据后才能处理完成,所以在每次处理的时候,就需要将处理进度记录起来,以便于下次从当前进度继续向下处理,最终得到一个完整 HttpRequest 请求信息对象,因此 在请求数据的接收以及解析部分需要一个上下文来进行控制接收和处理的节奏。
这个模块要关心的要素如下所示:
- 已经接收并处理的请求信息
- 接收状态:(即当前处于何种接收阶段,方便根据不同的阶段调用不同的函数)
- 接收请求行(当前处于接收并处理请求行的阶段)
- 接收请求头部(表示请求头部的接收还没有完毕)
- 接收正文(表示还有正文没有接收完毕)
- 接收数据完毕(这是一个接收完毕,可以对请求进行处理的阶段)
- 接收处理请求出错
- 响应状态码:
- 在请求的接收并处理中,有可能会出现各种不同的问题,比如解析出错、访问的资源不对、没有权限等等,而这些错误的响应状态码都是不一样的。
所以需要提供以下接口:
- 接收并处理请求数据:
- 接收请求行
- 解析请求行
- 接收头部
- 解析头部
- 接收正文
- 获取解析完毕的请求信息
- 获取响应状态码
- 获取接收解析状态
cpp
// RECV_LINE:接收请求行(当前处于接收并处理请求行的阶段)
// RECV_HEADER:接收请求头部(表示请求头部的接收还没有完毕)
// RECV_BODY:接收正文(表示还有正文没有接收完毕)
// RECV_DONED:接收数据完毕(这是一个接收完毕,可以对请求进行处理的阶段)
// RECV_ERROR:接收处理请求出错
typedef enum {
RECV_LINE,
RECV_HEADER,
RECV_BODY,
RECV_DONED,
RECV_ERROR
} HTTP_RECV_STATUS;
const int MAX_LINE_SIZE = 8192;
class HttpContext
{
private:
int _response_status; // 响应状态码
HTTP_RECV_STATUS _recv_status; // 当前接收的阶段
HttpRequest _request; // 存放已经接收并处理的请求信息
public:
HttpContext();
// 获取响应状态码
int get_response_status();
// 获取接收解析状态
HTTP_RECV_STATUS get_recv_status();
// 获取解析完毕的请求信息
HttpRequest& get_request();
// 接收并处理请求数据
void recv_and_handle_request(Buffer* buffer);
void reset();
private:
// 接收请求行
bool recv_line(Buffer* buffer);
// 解析请求行(内部会解析完将各字段放到请求模块对象中)
bool parse_line(const std::string& line);
// 接收头部(大部分和上面的接收请求行是重合的,注意不同的地方即可)
bool recv_header(Buffer* buffer);
// 解析头部
bool parse_header(std::string& line);
// 接收正文
bool recv_body(Buffer* buffer);
};Ⅱ. 接口实现
1、几个核心接口
几个提供给服务器模块使用接口实现起来并不难,如下所示:
cpp
// RECV_LINE:接收请求行(当前处于接收并处理请求行的阶段)
// RECV_HEADER:接收请求头部(表示请求头部的接收还没有完毕)
// RECV_BODY:接收正文(表示还有正文没有接收完毕)
// RECV_DONED:接收数据完毕(这是一个接收完毕,可以对请求进行处理的阶段)
// RECV_ERROR:接收处理请求出错
typedef enum {
RECV_LINE,
RECV_HEADER,
RECV_BODY,
RECV_DONED,
RECV_ERROR
} HTTP_RECV_STATUS;
const int MAX_LINE_SIZE = 8192;
class HttpContext
{
private:
int _response_status; // 响应状态码
HTTP_RECV_STATUS _recv_status; // 当前接收的阶段
HttpRequest _request; // 存放已经接收并处理的请求信息
public:
HttpContext()
: _response_status(200)
, _recv_status(RECV_LINE)
{}
// 获取响应状态码
int get_response_status() { return _response_status; }
// 获取接收解析状态
HTTP_RECV_STATUS get_recv_status() { return _recv_status; }
// 获取解析完毕的请求信息
HttpRequest& get_request() { return _request; }
// 接收并处理请求数据
void recv_and_handle_request(Buffer* buffer)
{
// 不同的状态,做不同的事情,但是这里不能break,因为处理完请求行后,应该立即处理头部,而不是退出等新数据
switch(_recv_status)
{
case RECV_LINE: recv_line(buffer);
case RECV_HEADER: recv_header(buffer);
case RECV_BODY: recv_body(buffer);
}
}
void reset()
{
_response_status = 200;
_recv_status = RECV_LINE;
_request.reset();
}
};2、接收 && 解析请求行
下面几个接口都是私有的,就是内部的处理函数,其实就是分三个阶段进行处理:请求行阶段、头部阶段、正文阶段。这里我们先来介绍请求行阶段的两个处理函数:接收以及解析请求行!
首先就是接收请求行的操作,无非就是利用 Buffer 模块中的获取一行的接口 get_line() 获取请求行,然后判断两种特殊情况:一行没有读取完毕、一行数据超过服务器规定大小(一般是8K),做这个判断主要是防止恶意的传入过长请求而导致消耗过多服务器资源!
获取成功的话则调用解析请求行函数 parse_line() 开始解析请求行,在其内部解析完请求行后将各字段存放到请求模块对象中进行保存!
最后别忘了要移动 buffer 的读指针,还要将所处状态改为接收头部状态!
cpp
// 接收请求行
bool recv_line(Buffer* buffer)
{
// 1. 接收请求行之前,判断当前是否处于接收请求行的阶段
if(_recv_status != RECV_LINE)
return false;
// 2. 获取缓冲区中的一行
std::string line = buffer->get_line_andMove();
// 3. 判断两种特殊情况:请求行没有读取完毕、请求行超过服务器规定(一般是8K)
if(line.size() == 0)
{
/* 如果此时请求行没有读取完毕,而且缓冲区中的数据是超过MAX_LINE_SIZE的,
说明数据很长都不足一行,这已经是有问题的了,那么请求行肯定是超过MAX_LINE_SIZE了 */
if(buffer->get_sizeof_read() > MAX_LINE_SIZE)
{
_recv_status = RECV_ERROR;
_response_status = 414; // 414表示URI太长了
return false;
}
return true; // 返回true表示没有读取完毕,不算错误
}
if(line.size() > MAX_LINE_SIZE)
{
_recv_status = RECV_ERROR;
_response_status = 414; // 414表示URI太长了
return false;
}
// 4. 获取成功的话则调用parse_line()开始解析请求行(其内部会解析完将各字段放到请求模块对象中)
bool ret = parse_line(line);
if(ret == false)
return false;
// 5. 将所处状态改为接收头部状态
_recv_status = RECV_HEADER;
return true;
} 而对于解析请求行函数 parse_line() ,它是由 recv_line() 调用的,此时拿到的是请求行的字符串,该函数的功能就是将该字符串中的各个字段解析出来,存放到请求模块对象中去,这里就用到了我们之前讲过的正则表达式来进行解析字段!
通过正则表达式解析完后结果放到了 std::smatch 类型的结果集中去,我们可以通过 [] 操作来获取它的结果,然后将它们各自放到请求模块中的对应字段去!
cpp
// 解析请求行(内部会解析完将各字段放到请求模块对象中)
bool parse_line(const std::string& line)
{
// (GET|POST|HEAD|PUT|DELETE) 表示匹配并提取其中任意一个字符串
// [^?]* [^?] 匹配非问号字符,后边的*表示 0次或多次
// \\?(.*) \\? 表示原始的 ? 字符,(.*)表示提取 ? 之后的任意字符 0 次或多次,直到遇到空格
// (?:\\?(.*))? (?: ...) 表示匹配某个格式字符串,但是不提取,所以就是表示匹配了上一行注释 0 次或 1 次,并且不获取该内容
// HTTP/1\\.[01] 表示匹配以 HTTP/1. 开始,后边有个 0 或 1 的字符串
// (?:\n|\r\n)? (?: ...) 表示匹配某个格式字符串,但是不提取,而最后的 ? 表示的是匹配前边的表达式 0 次或 1 次
// 注意要使用icase表示忽略请求方法的大小写
std::regex rule("(GET|POST|HEAD|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?", std::regex::icase);
std::smatch matches; // 结果集
bool ret = std::regex_match(line, matches, rule); // 进行表达式匹配,将匹配结果放到结果集中
if (ret == false)
{
_recv_status = RECV_ERROR;
_response_status = 400; // BAD REQUEST
return false;
}
// 举个例子,此时"GET /liren/login?user=xiaoming&pass=123123 HTTP/1.1\r\n" 的结果如下所示:
// 0 : GET /liren/login?user=xiaoming&pass=123123 HTTP/1.1
// 1 : GET
// 2 : /liren/login
// 3 : user=xiaoming&pass=123123
// 4 : HTTP/1.1
// 1. 请求方法的获取
_request._method = matches[1];
std::transform(_request._method.begin(), _request._method.end(), _request._method.begin(), ::toupper); // 注意要将方法转化为大写
// 2. 资源路径的获取,需要对其进行url解码,但是不需要将+转化为空格
_request._path = Util::url_decode(matches[2], false);
// 3. 协议版本的获取
_request._version = matches[4];
// 4.1 查询字符串的获取,先获取每个key=val的结构也就是键值对组合
std::vector<std::string> strs;
int size = Util::split(matches[3], "&", &strs);
// 4.2 然后再分解获取每个key和val
for(int i = 0; i < size; ++i)
{
std::vector<std::string> key_val;
int n = Util::split(strs[i], "=", &key_val);
// 此时如果只有key没有val的话则是错误的
if(n == 1)
{
_recv_status = RECV_ERROR;
_response_status = 400;
return false;
}
// 正确获取的话则对key和val先进行url解析,此时就需要将+转化为空格,然后将它们设置进请求对象中保存
std::string key = Util::url_decode(key_val[0], true);
std::string val = Util::url_decode(key_val[1], true);
_request.set_queryString(key, val);
}
return true;
}3、接收 && 解析请求头部
其实这里请求部分的接收和请求行的处理是大体相同的,不同之处在于 头部有多行,所以要用死循环 ,直到当前头部读到的字符串是 \r\n 或者 \n 的时候才退出循环,其它的操作都是类似的!
如果不是结束行的话,则会在获取到结果后调用解析头部函数 parse_header() 进行处理!
cpp
// 接收头部(大部分和上面的接收请求行是重合的,注意不同的地方即可)
bool recv_header(Buffer* buffer)
{
// 1. 接收头部之前,判断当前是否处于接收头部的阶段
if(_recv_status != RECV_HEADER)
return false;
// 因为头部有多行,所以要用死循环
while(true)
{
// 2. 获取缓冲区中的一行
std::string line = buffer->get_line_andMove();
// 3. 判断两种特殊情况:一行没有读取完毕、请求行超过服务器规定(一般是8K)
if(line.size() == 0)
{
/* 如果此时请求行没有读取完毕,而且缓冲区中的数据是超过MAX_LINE_SIZE的,
说明数据很长都不足一行,这已经是有问题的了,那么请求行肯定是超过MAX_LINE_SIZE了 */
if(buffer->get_sizeof_read() > MAX_LINE_SIZE)
{
_recv_status = RECV_ERROR;
_response_status = 414; // 表示一行数据太多
return false;
}
return true; // 返回true表示没有读取完毕,不算错误
}
if(line.size() > MAX_LINE_SIZE)
{
_recv_status = RECV_ERROR;
_response_status = 414; // 表示一行数据太多
return false;
}
// 4. 如果读的头部是\n或者\r\n的话,表示头部接收结束了,则将所处状态改为接收正文状态,然后退出循环,
if(line == "\r\n" || line == "\n")
break;
// 5. 获取成功的话则调用parse_line()开始解析请求行(其内部会解析完将各字段放到请求模块对象中)
bool ret = parse_header(line);
if(ret == false)
return false;
}
_recv_status = RECV_BODY;
return true;
} 而解析头部相比解析请求行要简单,因为头部是一个固定的 key: val 的格式,很好分割获得键值对!要注意的是因为我们接收头部的时候,调用的接收数据接口 get_line() 是将 \r\n 或者 \n 都读取上来了,但是它不应该被包含在键值对中,所以 在解析头部之前,应该先将 \n 和 \r 去掉!
cpp
// 解析头部
bool parse_header(std::string& line)
{
// 1. 末尾是\n或者\r换行则要去掉
if (line.back() == '\n') line.pop_back();
if (line.back() == '\r') line.pop_back();
// 2. 根据key: val的格式,进行分割获取头部的key和val
std::vector<std::string> key_val;
int size = Util::split(line, ": ", &key_val);
if(size <= 1)
{
_recv_status = RECV_ERROR;
_response_status = 400;
return false;
}
// 3. 将key和val设置进请求对象中保存
_request.set_header(key_val[0], key_val[1]);
return true;
}4、接收正文
接收正文并不需要进行解析,只需要拿到正文后设置到请求模块对象中的正文字段中即可!
要注意的是因为当前读取到的正文还不是完整的,所以我们需要先计算还需要接收的正文长度 real_length ,然后判断一下当前缓冲区数据是否大于等于 real_length ,是的话则获取 real_length 部分的数据,就是当前正文的数据!
如果缓冲区数据小于 real_length 的话,那就只能先获取当前缓冲区的数据,然后直接返回 true ,等待服务器模块再次调用该接收正文函数读取剩余的正文,而 服务器判断是否需要再次调用该接收正文函数的依据就是根据当前的接收状态来判断 ,如果是接收完毕了,则状态为 RECV_DONED,如果不是的话则依然还是处于 RECV_BODY 状态!
cpp
// 接收正文
bool recv_body(Buffer* buffer)
{
// 1. 接收正文之前,判断当前是否处于接收正文的阶段
if(_recv_status != RECV_BODY)
return false;
// 2. 从头部中获取正文长度
size_t size = _request.get_body_length();
if(size == 0)
{
// 没有正文,则请求解析完毕
_recv_status = RECV_DONED;
return true;
}
// 3. 计算还需要接收的正文长度(因为可能前面因为数据只接收了部分)
size_t real_length = size - _request._body.size();
if(buffer->get_sizeof_read() >= real_length)
{
// 3.1 若缓冲区中的数据包含了当前请求的所有正文,则取出所需的数据,然后设置状态为接收完毕即可
_request._body.append(buffer->start_of_read(), real_length);
buffer->push_reader_back(real_length);
_recv_status = RECV_DONED;
return true;
}
// 3.2 若缓冲区中的数据无法满足当前正文的需要,也就是数据不足,则取出数据,然后等待新数据到来,不用修改接收状态
_request._body.append(buffer->start_of_read(), buffer->get_sizeof_read());
buffer->push_reader_back(buffer->get_sizeof_read());
return true;
}Ⅲ. HttpServer服务器模块设计
这个模块是最终给组件使用者提供的,用于以简单的接口实现 HTTP 服务器的搭建的模块。
该模块内部包括如下元素:
-
一个
TcpServer对象:- 负责连接的
IO处理。
- 负责连接的
-
静态资源根目录:
- 其实就是一个字符串,表示当前服务器中想被外部访问的目标资源的根目录!
-
几张哈希表存储请求方法与其处理函数的映射表:
-
组件使用者向
HttpServer模块设置哪些请求应该使用哪些函数进行处理,比如说GET、POST、DELETE等方法要如何处理。这样子等TcpServer模块收到对应的请求之后就会使用对应的函数进行处理。 -
不同的方法,所对应的处理函数是不同的。对于
GET、HEAD来说,它们的处理函数就是要获取静态资源,则需要用到上面的静态资源根目录成员;而对于POST、DELETE、PUT等方法来说,它们的处理函数更多的是功能性函数,也就是需要进行具体的业务处理! -
不过 实际上我们用的是数组来存储映射表,因为我们在操作的时候其实需要遍历去比对正则表达式,不用到快速索引,所以用数组来代替!
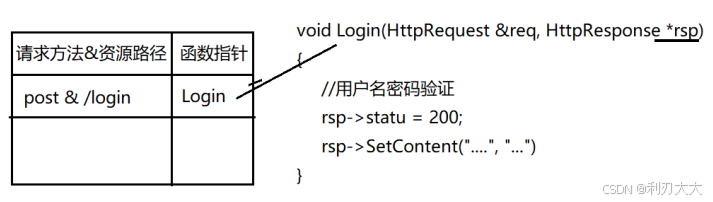
-
先来梳理一下 HTTP 服务器的一个处理流程,方便我们了解后面需要实现什么接口:
- 首先要从
socket中接收数据,放到接收缓冲区中。 - 调用
message_handle()函数也就是消息的回调函数,进行业务处理。 - 对请求进行解析,得到一个
HttpRequest对象,其内部就包含了该请求的所有要素。 - 然后根据将该
HttpRequest对象进行请求的路由查找,即从上面提到的映射表中找到对应的处理函数。此时根据请求方法,分为两种情况:- 静态资源请求 :
- 比如说
GET和HEAD方法,就是单纯为了请求文件的资源,那么直接将静态资源文件的数据读取出来即可,填充到HttpResponse模块中!
- 比如说
- 功能性请求 :
- 比如说
PUT和POST方法,对于这类方法我们要在请求映射表中查找对应的处理函数,进行业务处理,然后再进行填充HttpResponse模块!
- 比如说
- 静态资源请求 :
- 将上一步得到的
HttpResponse模块组织成HTTP格式响应,进行发送即可!
所以根据上面的流程可以知道,我们需要实现以下给使用者使用的核心接口:
- 添加请求-处理函数的映射信息接口 :
- 这里要特别注意的是,因为资源路径是有多种的,但是对应的处理函数可能只有一种,因为存在多对一的关系,所以对于 传入的资源路径则要求必须是一个正则表达式,这样子我们在解析资源路径的时候,可以把这个对应的处理函数与的多个资源路径进行统一,就不用说搞很多重复功能但不同名的处理函数了。
- 举个例子,如果资源路径是
/hello的话,此时我们需要调用一个Hello()执行函数,而有种情况就是资源路径为/hello/123,此时我们还是需要调用Hello(),但是可能该路径下还有别的文件比如资源路径/hello/456,此时我们不可能说再搞个Hello456()专门给它执行,所以我们要求传入的资源路径是一个正则表达式,则上面两个资源路径就变成/hello/\d+,则统一调用的都是Hello()函数,并且只需要在映射表种记录该正则表达式与该执行函数的关系即可,而不会出现多对一关系的情况!
- 设置静态资源根目录接口
- 设置是否启动非活跃连接超时关闭接口
- 设置线程池中线程数量接口
- 启动服务器接口
然后还需要一些内部私有成员函数,来完成 http 服务器的处理流程:
- 两个提供给
TcpServer对象的接口:- 连接建立完成后的回调处理 :
- 该回调处理很简单,就是给
TcpServer设置协议的上下文即可。(即设置通用类型Any的成员变量,用于记录请求数据的处理过程,才能在线程被切走然后又重新切回来之后知道之前处理到了哪里)
- 该回调处理很简单,就是给
- 收到消息后的回调处理 :
- 收到消息之后就要从缓冲区中获取上下文,然后进行解析处理,判断请求方法是静态资源请求还是功能性请求类型的,根据两种类型的不同进行不同的处理(这个过程我们叫做请求的路由查找,下面也会专门搞个函数来负责处理),最后就是组织
http响应格式进行返回!
- 收到消息之后就要从缓冲区中获取上下文,然后进行解析处理,判断请求方法是静态资源请求还是功能性请求类型的,根据两种类型的不同进行不同的处理(这个过程我们叫做请求的路由查找,下面也会专门搞个函数来负责处理),最后就是组织
- 连接建立完成后的回调处理 :
- 辅助消息回调处理的函数:
-
路由查找函数
- 该函数其实就是为下面两个函数进行选择,根据请求方法的不同选择下面不同的处理函数!
-
静态资源请求处理函数
-
功能性请求处理函数
-
组织协议格式进行返回的函数
-
cpp
using handle_t = std::function<void(const HttpRequest&, HttpResponse*)>;
class HttpServer
{
private:
TcpServer _server; // 高性能服务器对象
std::string _static_directory; // 静态资源根目录
std::vector<std::pair<std::regex, handle_t>> get_route; // get方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> post_route; // post方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> put_route; // put方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> delete_route; // delete方法的执行函数路由表
public:
/* 对外提供的核心接口 */
HttpServer();
// 添加请求-处理函数的映射信息接口(注意这里key不是字符串,而是一个正则表达式)
void add_get(const std::string& pattern, const handle_t& handler);
void add_post(const std::string& pattern, const handle_t& handler);
void add_put(const std::string& pattern, const handle_t& handler);
void add_delete(const std::string& pattern, const handle_t& handler);
// 设置静态资源根目录接口
void set_static_directory(const std::string& path);
// 设置是否启动非活跃连接超时关闭接口
void enable_inactive_release(int timeout);
// 设置线程池中线程数量接口
void set_nums_of_thread(int count);
// 启动服务器接口
void start_httpserver();
private:
/* 服务器内部的两个回调处理函数,以及其所需的一些辅助函数 */
// 连接建立完成后的回调处理
void connected_handle(const ConnectionPtr& cptr);
// 收到消息后的回调处理
void message_handle(const ConnectionPtr& cptr, Buffer* buffer);
// 路由查找函数
void route(HttpRequest& request, HttpResponse* response);
// 判断是否为正确的静态资源请求
bool is_static_resource_request(const HttpRequest& request);
// 静态资源请求处理函数
void static_resource_request(const HttpRequest& request, HttpResponse* response);
// 功能性请求函数的分类处理
void functional_request(HttpRequest& request, HttpResponse* response,
std::vector<std::pair<std::regex, handle_t>>& route);
// 组织协议格式进行返回的函数
void organize_and_response(const ConnectionPtr& cptr, const HttpRequest& request, HttpResponse* response);
// 响应错误信息
void error_response(const ConnectionPtr& cptr, const HttpRequest& request, HttpResponse* response);
};Ⅳ. 接口实现
1、核心接口实现
cpp
using handle_t = std::function<void(const HttpRequest&, HttpResponse*)>;
class HttpServer
{
private:
TcpServer _server; // 高性能服务器对象
std::string _static_directory; // 静态资源根目录
std::vector<std::pair<std::regex, handle_t>> get_route; // get方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> post_route; // post方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> put_route; // put方法的执行函数路由表
std::vector<std::pair<std::regex, handle_t>> delete_route; // delete方法的执行函数路由表
public:
HttpServer(uint16_t port, int timeout = DEFAULT_TIMEOUT)
: _server(port)
{
// 这里只设置两个回调处理
_server.set_connected_callback(std::bind(&HttpServer::connected_handle, this, std::placeholders::_1));
_server.set_message_callback(std::bind(&HttpServer::message_handle, this, std::placeholders::_1,
std::placeholders::_2));
_server.enable_inactive_release(timeout);
}
// 添加请求-处理函数的映射信息接口(注意这里key不是字符串,而是一个正则表达式)
void add_get(const std::string& pattern, const handle_t& handler)
{
get_route.push_back(std::make_pair(std::regex(pattern), handler));
}
void add_post(const std::string& pattern, const handle_t& handler)
{
post_route.push_back(std::make_pair(std::regex(pattern), handler));
}
void add_put(const std::string& pattern, const handle_t& handler)
{
put_route.push_back(std::make_pair(std::regex(pattern), handler));
}
void add_delete(const std::string& pattern, const handle_t& handler)
{
delete_route.push_back(std::make_pair(std::regex(pattern), handler));
}
// 设置静态资源根目录接口
void set_static_directory(const std::string& path)
{
assert(Util::is_directory(path) == true);
_static_directory = path;
}
// 设置是否启动非活跃连接超时关闭接口
void enable_inactive_release(int timeout) { _server.enable_inactive_release(timeout); }
// 设置线程池中线程数量接口
void set_nums_of_thread(int count) { _server.set_nums_of_subthread(count); }
// 启动服务器接口
void start_httpserver() { _server.start_server(); }
};2、连接建立完成后的回调处理
这个我们简单处理,就是设置一下该连接的上下文,然后进行日志打印即可!
cpp
// 连接建立完成后的回调处理
void connected_handle(const ConnectionPtr& cptr)
{
cptr->set_context(HttpContext());
DLOG("new connection: %p", cptr.get());
}3、收到消息后的回调处理
这个函数是进行业务处理的核心函数,因为当该连接对应的文件描述符有可读事件触发了,或者当连接要关闭的时候,我们先进行业务处理!
因为这个函数是在 socket 接收数据之后放到缓冲区后调用的,所以我们要先读取缓冲区中的数据,通过我们前面封装的上下文 HttpContext 进行读取,这样子能保证处理时候上下文一致!
接收完之后就将接收到的上下文放到请求中,即放到 HttpRequest 对象中去,然后再创建一个空的响应对象即 HttpResponse 一起进行路由查找,路由查找函数就是帮我们根据传入的请求结构,与用户设置的执行函数映射表进行匹配,如果找到对应请求的执行函数,则进行处理,找不到的话其内部会进行错误码的设置!
路由查找结束之后就是根据 HttpResponse 对象的结构进行组织成响应报文,返回给客户端!
发送结束之后还需要进行上下文的重置,因为我们这个回调函数是一个循环体,如果缓冲区有数据的话就会进行持续的处理,为了防止下一条请求被影响(比如说状态码不正确的情况),我们就得重置上下文!
最后判断是否为短连接,是的话直接关闭连接即可,如果不是的话则不需要关心!
cpp
// 收到消息后的回调处理
void message_handle(const ConnectionPtr& cptr, Buffer* buffer)
{
// 如果缓冲区有数据的话就进行持续的处理
while(buffer->get_sizeof_read() > 0)
{
// 1. 获取上下文
HttpContext* context = cptr->get_context()->get<HttpContext>();
// 2. 通过上下文对缓冲区数据进行解析,得到HttpRequest对象(如果缓冲区数据解析成功,且请求已经获取完毕了,才开始去路由查找和处理)
context->recv_and_handle_request(buffer);
// 2.1 如果缓冲区数据解析失败,则直接响应错误信息然后关闭连接即可
HttpRequest& request = context->get_request();
HttpResponse response(context->get_response_status());
if(context->get_response_status() >= 400)
{
// 即填充错误信息页面数据到响应中,然后返回该错误页面响应
error_response(cptr, request, &response);
// 出错了就把当前连接的缓冲区数据清空,不然会和下面的shutdown函数形成死循环。最后顺便把状态也清空一下
request.reset();
buffer->clear_buffer();
cptr->shutdown();
return;
}
// 2.2 如果缓冲区数据解析成功,但是请求还没获取完整,则退出该函数,等待新数据的到来后再继续处理
if(context->get_recv_status() != RECV_DONED)
return;
// 3. 进行路由查找(在其内部进行对应请求的处理)
route(request, &response);
// 4. 组织HttpResponse进行返回
organize_and_response(cptr, request, &response);
// 5. 重置上下文,防止下一条请求被影响(比如状态码什么的)
context->reset();
// 6. 判断是否为短连接,是的话直接关闭连接
if(request.is_short_connection())
cptr->shutdown();
}
}4、辅助函数
① 路由查找函数
这个函数不难,就是判断请求的是什么资源,如果是静态资源请求的话,则进行静态资源请求处理;如果是功能性请求的话,则根据请求方法来将不同功能性请求派发到不同作用的函数中去!
如果既不是静态资源请求,也不是功能性请求的话,则设置状态码为 405 表示请求方法未找到即可!
cpp
// 路由查找函数
void route(HttpRequest& request, HttpResponse* response)
{
// 1. 如果是静态资源请求的话,则进行静态资源请求处理
if(is_static_resource_request(request) == true)
return static_resource_request(request, response);
// 2. 如果是功能性请求的话,则根据请求方法来将不同功能性请求派发到不同作用的函数中去
if(request._method == "GET" || request._method == "HEAD")
return functional_request(request, response, get_route);
else if(request._method == "POST")
return functional_request(request, response, post_route);
else if(request._method == "PUT")
return functional_request(request, response, put_route);
else if(request._method == "DELETE")
return functional_request(request, response, delete_route);
// 3. 如果既不是静态资源请求,也不是功能性请求的话,则设置状态码为405表示请求方法未找到
response->_status = 405;
}② 静态资源处理函数
首先得先判断当前请求的是否为静态资源,如果是的话再进行静态资源请求处理!具体判断步骤和处理过程在下面代码中有注释:
cpp
// 判断是否为正确的静态资源请求
bool is_static_resource_request(const HttpRequest& request)
{
// 1. 要求必须设置了静态资源根目录
if(_static_directory.empty())
return false;
// 2. 要求请求方法GET或者HEAD
if(request._method != "GET" && request._method != "HEAD")
return false;
// 3. 判断请求路径是否合法
if(Util::is_path_valid(request._path) == false)
return false;
// 4. 请求的资源必须存在,并且是一个普通文件
// 如果是请求资源是目录的话,那么就在其后面加上默认页面文件index.html即可
std::string path = _static_directory + request._path; // 为了避免直接修改请求的资源路径,因此定义一个临时对象
if(path.back() == '/')
path += "index.html";
if(Util::is_regular_file(path) == false)
return false;
return true;
}
// 静态资源请求处理函数
void static_resource_request(const HttpRequest& request, HttpResponse* response)
{
// 就是将要请求的静态资源读取出来后,放到response的正文中,然后设置资源的类型Content-Type即可
std::string path = _static_directory + request._path;
if(path.back() == '/')
path += "index.html";
bool ret = Util::read_file(path, &response->_body);
if(ret == false)
return;
response->set_header("Content-Type", Util::get_mime_from_suffix(path));
}③ 功能性请求函数处理
这个函数也不难,就是在对应请求方法的路由表中,查找是否存在该请求的处理方法,如果有的话则调用,没有的话则设置 404 状态码返回即可!不过要注意的就是因为 std::regex_match 中要求正则表达式是一个 const 对象,所以我们要单独搞一个变量出来进行传递,不然的话会报错!
cpp
// 功能性请求函数的分类处理
void functional_request(HttpRequest& request, HttpResponse* response, std::vector<std::pair<std::regex, handle_t>>& route)
{
// 在对应请求方法的路由表中,查找是否存在该请求的处理方法,如果有的话则调用,没有的话则设置404状态码
// 思路:使用路由表中的每个正则表达式与请求路径进行匹配,匹配成功则使用对应函数进行处理
// 所以路由表中的key最好存放的是正则表达式,如果是字符串的话则需要去编译成正则表达式,比较费时间
for(auto& handler : route)
{
const std::regex& regex = handler.first;
bool ret = std::regex_match(request._path, request._matches, regex);
if(ret == false)
continue;
return handler.second(request, response); // 传入请求信息和空的response,执行对应的处理函数
}
// 如果走到这里的话,说明上面的功能性请求没找到对应的处理方法,则设置404状态码即可
response->_status = 404;
}④ 组织和响应处理函数
在组织响应内容之前,要先完善一些响应的头部字段,比如长短连接、正文长度、请求资源类型、重定向等等,如下所示:
cpp
// 组织协议格式进行返回的函数
void organize_and_response(const ConnectionPtr& cptr, const HttpRequest& request, HttpResponse* response)
{
// 1. 完善一些头部字段(比如长短连接、正文长度、请求资源类型、重定向等等)
if(request.is_short_connection() == true)
response->set_header("Connection", "close");
else
response->set_header("Connection", "keep-alive");
if(!response->_body.empty() && response->has_header("Content-Length") == false)
response->set_header("Content-Length", std::to_string(response->_body.size()));
if(!response->_body.empty() && response->has_header("Content-Type") == false)
response->set_header("Content-Type", "application/octet-stream");
if(response->_is_redirect == true)
response->set_header("Location", response->_redirect_path);
// 2. 根据response组织响应内容(状态行、响应报头、空行、响应正文)
std::stringstream sstr;
sstr << request._version << " " << std::to_string(response->_status)
<< " " << Util::get_information_from_status(response->_status) << "\r\n";
for(auto& e : response->_header)
sstr << e.first << ": " << e.second << "\r\n";
sstr << "\r\n" << response->_body;
// 3. 发送数据
cptr->send_data(sstr.str().c_str(), sstr.str().size());
}⑤ 错误信息处理
因为有可能接收到的内容是错误的,或者服务器处理错误,此时返回一个错误页面即可!
cpp
// 响应错误信息
void error_response(const ConnectionPtr& cptr, const HttpRequest& request, HttpResponse* response)
{
// 1. 读取错误页面文件
std::string buffer;
bool ret = Util::read_file("./wwwroot/error.html", &buffer);
if(ret == false)
{
ELOG("响应错误信息操作失败!");
return;
}
// 2. 将数据设置为响应正文,然后进行组织发送
response->set_content(buffer, "text/html");
organize_and_response(cptr, request, response);
}5、简单首页登录页面
html
<!DOCTYPE html>
<html>
<head>
<title>登录页面</title>
<style>
body {
background: #f1f1f1;
font-family: Arial, sans-serif;
}
.container {
width: 300px;
margin: 0 auto;
padding: 20px;
background: #fff;
border-radius: 5px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}
h2 {
text-align: center;
color: #333;
}
input[type="text"],
input[type="password"] {
width: 100%;
padding: 10px;
margin-bottom: 15px;
border-radius: 3px;
border: 1px solid #ccc;
}
input[type="submit"] {
width: 100%;
padding: 10px;
background: #4CAF50;
color: #fff;
border: none;
border-radius: 3px;
cursor: pointer;
}
input[type="submit"]:hover {
background: #45a049;
}
.error {
color: red;
margin-bottom: 10px;
}
</style>
</head>
<body>
<div class="container">
<h2>用户登录</h2>
<form action="/login" method="post">
<input type="text" name="username" placeholder="用户名">
<input type="password" name="password" placeholder="密码">
<div class="error">错误消息显示在这里(如果有)</div>
<input type="submit" value="登录">
</form>
</div>
</body>
</html>6、简单的错误页面
html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>出错了</title>
<style>
body {
font-family: Arial, sans-serif;
background-color: #f1f1f1;
}
.error-container {
margin: 10% auto;
text-align: center;
}
h1 {
font-size: 3rem;
color: #333;
}
p {
font-size: 1.2rem;
color: #777;
margin-bottom: 2rem;
}
a {
display: inline-block;
padding: 0.5rem 1rem;
margin-top: 2rem;
background-color: #007bff;
color: #fff;
border-radius: 4px;
text-decoration: none;
transition: background-color 0.2s ease;
}
a:hover {
background-color: #0062cc;
}
</style>
</head>
<body>
<div class="error-container">
<h1>出错了</h1>
<p>抱歉,您访问的页面暂时无法显示。</p>
<a href="./index.html">返回首页</a>
</div>
</body>
</html>Ⅴ. 服务器主函数
先展示一下整个工程的路径结构,如下图所示:
接下来我们就编写一下 server.cc 也就是服务器的主函数,简单的给出几个执行函数映射表,然后启动服务器,代码如下所示:
cpp
#include "httpserver.hpp"
const std::string source = "./wwwroot";
std::string RequestStr(const HttpRequest &req)
{
// 将请求报文结构转化为字符串格式
std::stringstream ss;
ss << req._method << " " << req._path << " " << req._version << "\r\n";
for (auto &it : req._queryString)
ss << it.first << ": " << it.second << "\r\n";
for (auto &it : req._header)
ss << it.first << ": " << it.second << "\r\n";
ss << "\r\n" << req._body;
return ss.str();
}
// 进行简单的请求报文的回显(text/plain表示文本内容)
void Hello(const HttpRequest &req, HttpResponse *rsp)
{
rsp->set_content(RequestStr(req), "text/plain");
}
// 进行简单的请求报文的回显
void Login(const HttpRequest &req, HttpResponse *rsp)
{
rsp->set_content(RequestStr(req), "text/plain");
}
// 接收请求的文件内容,然后放到当前资源根目录下
void PutFile(const HttpRequest &req, HttpResponse *rsp)
{
std::string pathname = source + req._path;
Util::write_file(pathname, req._body);
}
// 进行简单的请求报文的回显
void DelFile(const HttpRequest &req, HttpResponse *rsp)
{
rsp->set_content(RequestStr(req), "text/plain");
}
int main()
{
HttpServer server(8080, 10); // 设置端口和超时事件
server.set_nums_of_thread(4);
server.set_static_directory(source);
// 设置执行函数映射表
server.add_get("/hello", Hello);
server.add_post("/login", Login);
server.add_put("/1234.txt", PutFile);
server.add_delete("/1234.txt", DelFile);
// 启动服务器
server.start_httpserver();
return 0;
} makefile 文件如下所示:
makefile
CXX = g++
DEBUG = -g
THREAD = -lpthread
HIGH_VERSION = -std=c++17
CXXFLAGS = -c #-Wall
TARGET = server
OBJ = $(patsubst %.cc, %.o, $(wildcard $(TARGET).cc))
HEADERS = httpserver.hpp ../server.hpp
$(TARGET) : $(OBJ)
$(CXX) -o $@ $^ $(HIGH_VERSION) $(THREAD) $(DEBUG)
%.o : %.cc $(HEADERS)
$(CXX) $(CXXFLAGS) -o $@ $< $(DEBUG)
.PHONY:clean
clean:
rm -rf $(TARGET) *.oⅥ. 测试代码
首先先给出 makefile 文件,我们只需要在该 makefile 文件中改一下目标生成文件即可生成不同的目标文件,如下所示:
makefile
CXX = g++
TARGET = client1
OBJ = $(patsubst %.cc, %.o, $(wildcard $(TARGET).cc))
CXXFLAGS = -c #-Wall
$(TARGET) : $(OBJ)
$(CXX) -o $@ $^ -std=c++11
%.o : %.cc
$(CXX) $(CXXFLAGS) -o $@ $<
.PHONY:clean
clean:
rm -f $(OBJ) $(TARGET)1、超时连接释放测试一
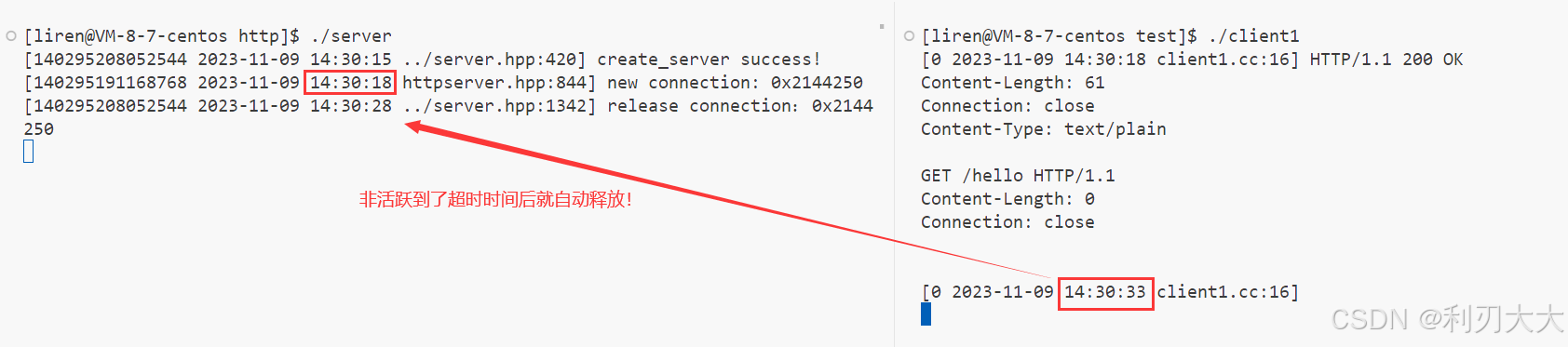
因为前面服务器的超时时间设置为 10 秒,所以我们让当前连接的处理休眠 15 秒进行测试,预期结果:10s 后连接被释放。
cpp
#include "../source/server.hpp"
// 测试长连接的demo
int main()
{
// 创建客户端套接字
Socket client_sock;
client_sock.create_client(8080, "81.71.97.127");
std::string str = "GET /hello HTTP/1.1\r\nConnection: close\r\nContent-Length: 0\r\n\r\n";
while(true)
{
assert(client_sock.Send(str.c_str(), str.size()) != -1);
char buf[1024] = { 0 };
client_sock.Recv(buf, sizeof(buf) - 1);
DLOG("%s", buf);
sleep(15);
}
return 0;
} 可以看到结果确实会超时释放:
2、超时连接释放测试二
给服务器发送一个数据,告诉服务器要发送 1024 字节的数据,但是实际发送的数据不足 1024,查看服务器处理结果,有以下两种情况:
- 如果数据只发送一次,服务器将得不到完整请求,就没有再进行业务处理,客户端也就得不到响应,最终非活跃后超时关闭连接
- 连着给服务器发送了多次小的请求,服务器会将后边的请求当作前边请求的正文进行处理,而后处理的时候有可能就会因为处理错误而关闭连接
预期结果:服务器第一次接收请求不完整,会将后边的请求当作第一次请求的正文进行处理。最终对剩下的数据处理的时候处理出错,关闭连接。
cpp
#include "../source/server.hpp"
/*
给服务器发送一个数据,告诉服务器要发送1024字节的数据,但是实际发送的数据不足1024,查看服务器处理结果,有以下两种情况:
1. 如果数据只发送一次,服务器将得不到完整请求,就没有再进行业务处理,客户端也就得不到响应,最终非活跃后超时关闭连接
2. 连着给服务器发送了多次小的请求,服务器会将后边的请求当作前边请求的正文进行处理,而后处理的时候有可能就会因为处理错误而关闭连接
*/
int main()
{
// 创建客户端套接字
Socket client_sock;
client_sock.create_client(8080, "81.71.97.127");
std::string str = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\n\r\nlirendada";
while(true)
{
assert(client_sock.Send(str.c_str(), str.size()) != -1);
//assert(client_sock.Send(str.c_str(), str.size()) != -1);
//assert(client_sock.Send(str.c_str(), str.size()) != -1);
char buf[1024] = { 0 };
client_sock.Recv(buf, sizeof(buf) - 1);
DLOG("%s", buf);
sleep(1);
}
return 0;
}3、超时连接释放测试三
当业务处理超时,查看服务器的处理情况:因为当服务器达到了一个性能瓶颈,如果在一次业务处理中花费了太长的时间(有可能超过了服务器设置的非活跃超时时间),则有可能导致其他的连接也被连累超时,其他的连接有可能会被拖累超时释放!
假设现在 12345 描述符就绪了且非活跃超时时间为 30s ,在处理 1 的时候花费了 30s 处理后,导致 2345 描述符因为长时间没有刷新活跃度,此时有两种情况:
- 如果接下来的
2345描述符都是通信连接描述符,如果都就绪了,则没有太大的影响,因为接下来就会进行处理并刷新活跃度 - 如果接下来的
2号描述符是定时器事件描述符,此时定时器触发超时,执行定时任务,就会将345描述符给释放掉- 这时候一旦
345描述符对应的连接被释放,接下来在处理345事件的时候就会导致程序崩溃(内存访问错误)
- 这时候一旦
因此在本次事件处理中,并不能直接对连接进行释放,而应该将释放操作压入到任务池中,等到事件处理完了执行任务池中的任务的时候,再去释放。
不过这种测试是比较偶然的,不一定能测出来,下面我们就创建多个子进程客户端,向服务器发送数据,然后服务器在处理 hello 执行函数中进行 15s 的等待,此时就会超过非活跃连接销毁时间!
cpp
#include "../source/server.hpp"
int main()
{
// 创建多进程客户端套接字
signal(SIGCHLD, SIG_IGN);
for(int i = 0; i < 10; ++i)
{
pid_t id = fork();
if(id < 0)
{
ELOG("fork error");
return -1;
}
else if(id == 0)
{
// 子进程进行数据发送
Socket client_sock;
client_sock.create_client(8080, "81.71.97.127");
std::string str = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
while(true)
{
assert(client_sock.Send(str.c_str(), str.size()) != -1);
char buf[1024] = { 0 };
client_sock.Recv(buf, sizeof(buf) - 1);
DLOG("%s", buf);
sleep(1);
}
exit(0);
}
}
while(true); // 父进程进行死循环
return 0;
}4、数据中多条请求处理测试
一次性给服务器发送多条数据,然后查看服务器的处理结果。预期结果:每一条请求都应该得到正常处理。
cpp
#include "../source/server.hpp"
/* 一次性给服务器发送多条数据,然后查看服务器的处理结果 */
/* 每一条请求都应该得到正常处理 */
int main()
{
// 创建客户端套接字
Socket client_sock;
client_sock.create_client(8080, "81.71.97.127");
std::string str = "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
str += "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
str += "GET /hello HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
while(true)
{
assert(client_sock.Send(str.c_str(), str.size()) != -1);
char buf[1024] = { 0 };
client_sock.Recv(buf, sizeof(buf) - 1);
DLOG("%s", buf);
sleep(1);
}
return 0;
}5、put请求大文件上传测试
首先我们先用命令行创建一个大文件,如下所示:
shell
[liren@VM-8-7-centos test]$ dd if=/dev/zero of=./test.txt bs=300M count=1
1+0 records in
1+0 records out
314572800 bytes (315 MB) copied, 0.495342 s, 635 MB/s 然后客户端进行发送:
cpp
#include "../source/http/httpserver.hpp"
/* 大文件传输测试,给服务器上传一个大文件,服务器将文件保存下来,观察处理结果(上传的文件,应该和服务器保存的文件一致才对) */
int main()
{
// 创建客户端套接字
Socket client_sock;
client_sock.create_client(8080, "127.0.0.1");
std::string str = "put /1234.txt HTTP/1.1\r\nConnection: keep-alive\r\n";
std::string body;
Util::read_file("./test.txt", &body);
str += "Content-Length: " + std::to_string(body.size()) + "\r\n\r\n";
assert(client_sock.Send(str.c_str(), str.size()) != -1);
assert(client_sock.Send(body.c_str(), body.size()) != -1);
char buf[4096] = { 0 };
client_sock.Recv(buf, sizeof(buf) - 1);
DLOG("%s", buf);
sleep(3);
return 0;
} 可以看到它们的 md5 值都是相同的,说明是同一个文件!

6、性能测试
这里采用 webbench 进行服务器性能测试。webbench 是知名的网站压力测试工具,它是由 Lionbridge 公司(http://www.lionbridge.com)开发的。webbench 的标准测试可以向我们展示服务器的两项内容: 每秒钟相应请求数 和 每秒钟传输数据量。
webbench 测试原理是:创建指定数量的进程,在每个进程中不断创建套接字向服务器发送请求,并通过管道最终将每个进程的结果返回给主进程进行数据统计。所以性能测试的两个重点衡量标准:吞吐量 && QPS(即每秒钟处理的包的数量)。
测试环境:
任何不说明测试环境的测试都是无知的,这里服务器环境:2 核 2G 云服务器,服务器程序采用 1 主 3 从的 reactor 模式。
而 webbench 客户端环境:在同一台云服务器上。(测试的意义不大,因为同主机会造成互相的 cpu 争抢,但是这里目前没办法,毕竟服务器的带宽和资源太低了)
cpp
[liren@VM-8-7-centos WebBench]$ ./webbench -c 5000 http://127.0.0.1:8080/
Webbench - Simple Web Benchmark 1.5
Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software.
Benchmarking: GET http://127.0.0.1:8080/
5000 clients, running 30 sec.
Speed=19040 pages/min, 718584 bytes/sec.
Requests: 9519 susceed, 1 failed.