前言
我是[提前退休的java猿](https://juejin.cn/user/465848660928872 "https://juejin.cn/user/465848660928872"),一名7年java开发经验的开发组长,分享工作中的各种问题!(抖音、公众号同号)
昨天在看【java深度调试技术】的时候看到数据库死锁这一章节.然后我就在思考平时写的代码 死锁的场景太多了,为什么工作了七八年从来没遇到因为死锁导致的业务阻塞问题,也从来没有解决过数据库的死锁问题。
今天这篇文章的主题就讲一下为什么我们很少去解决数据死锁问题,围绕这个话题我们会带出一个新的知识点:数据库在某些情况下只会回滚部分SQL 以及 我们通过在什么情况下应该去看日志,什么情况下去查询当前事务的情况。
为什么很少遇到数据库死锁
业务并发低并发低这个是很少发生死锁的主要原因. 除了这个问题之外和数据库本身的死锁机制也有很大的关系. 主流的SQL数据都是有死锁检测机制大同小异罢了。所以当我们的数据库检测到死锁之后,就会回滚部分死锁事务,从不会一直阻塞我们的业务。
MySQL数据库的死锁检测机制
今天就来说一下主流的SQL数据库它的死锁检测机制,当然主要还是讨论一下MySQL就行了。 mysql 的死锁检测机制或者说死锁兜底机制主要有个关键的配置:
- 第一个是否开启死锁检测配置(默认开启):
innodb_deadlock_detect = ON - 第二配置等待锁超时时间(默认50s):
innodb_lock_wait_timeout = 50
第一步:innodb_deadlock_detect
MySQL的InnoDB引擎通过 等待图(Wait-for Graph)算法来检测死锁。系统会周期性地检查是否存在事务间的循环等待链,一旦发现,就会立即触发死锁处理机制。会回滚一个或者多个死锁事务,选择回滚代价小的事务(插入、更新、删除行数小的)。
当然这个死锁检测机制是可以通过配置关闭的,这个机制也会存在一定的性能开销,所以在极高的并发下可以考虑关闭死锁检测.
🔈 死锁检测配置(默认开启):
innodb_deadlock_detect = ON📒SQL官方文档:dev.mysql.com/doc/refman/...
测试(mysql8.0)
js
-----------------------事务1------------------------------
// 第一步:会话 01 ,关闭自动提交事务,更新 navigation
set autocommit = 0;
UPDATE navigation SET name = 'txt01';
//第三步:更新 navigation_relation_station,一直等待锁
UPDATE navigation_relation_station SET navigation_id = 101;
---------------------事务2--------------------------------
//第二步:会话 02,关闭自动提交事务,更新 navigation_relation_station
set autocommit = 0;
UPDATE navigation_relation_station SET navigation_id = 2;
// 第四步: 更新 navigation ,形成死锁
UPDATE navigation SET name = 'txt02';当执行第四步时就会形成死锁,事务1报错回滚,错误信息如下:
text
UPDATE navigation_relation_station SET navigation_id = 101
1213 - Deadlock found when trying to get lock; try restarting transaction
查询时间: 5.445s第二步:innodb_lock_wait_timeout
这个配置算是一个等待锁的一个兜底机制,不管是发生死锁(死锁探测机制关闭) ,还是因为锁被其他事务长时间占用 导致的锁等待超时,这个配置就显得非常重要了。默认50s,根据实际场景调整。 如果超过这个这个配置的设置时间了会发生么?
✅默认会回滚等待超时事务中获取锁的那条SQL,没错不是回滚整个事务. 当然这只是MySQL的默认策略,这个回滚策略也是可以通过配置控制的。可通过配置(默认关闭,回滚等待锁的SQL)让其回滚整个事务:innodb_rollback_on_timeout = OFF
测试(MySQL8.0)
💦本次测试当事务在等待锁超时的情况的下,数据库是只回滚部分SQL。并且会话保持,出错之后继续commit,看看能否执行成功,成功的部分是否为事务中未回滚的前半部分语句。
mysql 数据如下,ID为主键索引(避免锁范围扩大)
| id | realname |
|---|---|
| 1 | 零零一 |
| 2 | 零零二 |
做一下测试,模拟等待锁超时的情况:
js
//第一步,事务1,抢占 ID 为1的行锁,不提交事务
set autocommit = 0;
update t_user set realname = "事务1" WHERE id = "1";
// 第二步,事务2,先更新ID为2的数据,再更新ID= 1的数据(等待锁)
set autocommit = 0;
update t_user set realname = "事务2-2" WHERE id = "2";
update t_user set realname = "事务2-1" WHERE id = "1";
commit;第二步的事务等待锁超时,输出结果如下:
js
update t_user set realname = "事务2-2" WHERE id = "2"
> Affected rows: 1
> 查询时间: 0s
update t_user set realname = "事务2-1" WHERE id = "1"
> 1205 - Lock wait timeout exceeded; try restarting transaction
> 查询时间: 51.353s再次commit第二的事务,发现能提交成功,刷新列表,发现只有事务中的第一条SQL执行成功了
 ✅测试结论:当事务因为等待锁超时(没有开启回滚整个事务),数据会报错,并且事务会回滚等待锁的SQL语句。此时会话依然保持,可以继续commit,事务等待锁之前的SQL将会被重新提交。
✅测试结论:当事务因为等待锁超时(没有开启回滚整个事务),数据会报错,并且事务会回滚等待锁的SQL语句。此时会话依然保持,可以继续commit,事务等待锁之前的SQL将会被重新提交。
如何解决死锁问题
官网和博客好多说使用SHOW ENGINE INNODB STATUS,这个命令能执行成功,但是我从来没有看到过任何信息(不知道怎么回事儿,模拟发生过死锁)。
看死锁日志
日志准备:MySQL8.0 windows 环境中,配置文件需要指定error日志输出文件,以及开启死锁日志记录。
js
# my.ini 文件配置
[mysqld]
innodb_print_all_deadlocks = 1
log_error = /var/log/mysql/error.log📟同时还要确保我们的死锁检测配置时开启的,不然也看不到死锁日志
模拟死锁SQL:
js
------------------- 事务49421-----------------------
第一步
set autocommit = 0 ;
UPDATE t_user SET realname = 'tx01-1' WHERE id = '101';
第三步
UPDATE t_user SET realname = 'tx02-1' WHERE id = '102';
COMMIT
-----------------事务49422--------------------------
第二步
set autocommit = 0 ;
UPDATE t_user SET realname = 'tx122222-1' WHERE id = '102';
第四步
UPDATE t_user SET realname = 'tx1111-1' WHERE id = '101';
COMMIT;死锁日志如下:
js
TRANSACTION 49421, ACTIVE 12 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 8, OS thread handle 31912, query id 130 localhost ::1 root updating
UPDATE t_user SET realname = 'tx02-1' WHERE id = '102'
RECORD LOCKS space id 10 page no 17899 n bits 216 index PRIMARY of table `test`.`t_user` trx id 49421 lock_mode X locks rec but not gap waiting (等待锁 102)
Record lock, heap no 150 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 3; hex 313032; asc 102;;
1: len 6; hex 00000000c10e; asc ;;
2: len 7; hex 02000001540b3b; asc T ;;;
3: len 13; hex 31303231323334333238623363; asc 1021234328b3c;;
4: len 10; hex 74783132323232322d31; asc tx122222-1;;
5: len 3; hex 386266; asc 8bf;;
TRANSACTION 49422, ACTIVE 8 sec starting index read, thread declared inside InnoDB 5000
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 9, OS thread handle 28276, query id 134 localhost ::1 root updating
UPDATE t_user SET realname = 'tx1111-1' WHERE id = '101'
RECORD LOCKS space id 10 page no 17899 n bits 216 index PRIMARY of table `test`.`t_user` trx id
49422 lock_mode X locks rec but not gap (持有锁102)
Record lock, heap no 150 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 3; hex 313032; asc 102;;
1: len 6; hex 00000000c10e; asc ;;
2: len 7; hex 02000001540b3b; asc T ;;;
3: len 13; hex 31303231323334333238623363; asc 1021234328b3c;;
4: len 10; hex 74783132323232322d31; asc tx122222-1;;
5: len 3; hex 386266; asc 8bf;;
RECORD LOCKS space id 10 page no 17899 n bits 216 index PRIMARY
of table `test`.`t_user` trx id 49422 lock_mode X locks rec but not gap waiting(等待锁101)
Record lock, heap no 149 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 3; hex 313031; asc 101;;
1: len 6; hex 00000000c10d; asc ;;
2: len 7; hex 01000001010c84; asc ;;
3: len 13; hex 31303131323334333238623363; asc 1011234328b3c;;
4: len 6; hex 747830312d31; asc tx01-1;;
5: len 3; hex 386266; asc 8bf;;🔱不会分析丢给AI就行了。 从上面的信息能看到具体的代码阻塞到的是哪行,这样自己再去定位代码其实也比较简单了。
查询事务表信息
因为我们mysql 自带的死锁检测机制会自动回滚 其中代价小的事务,所以因为死锁导致阻塞的事务就很难通过 查询运行中事务的状态来定位了。
当然如果是系统并发非常高,并且死锁检测机制被关闭,或者说用来查询长事务,可以去通过查看下面的信息来定位问题。
下面这些操作需要数据开启性能模式,默认开启:performance_schema = ON
- MySQL 8.0 及以上版本:使用
performance_schema.data_locks和performance_schema.data_lock_waits查看锁信息,配合INNODB_TRX查看事务详情。 - MySQL 5.7 及以下版本:仍可使用
INNODB_LOCKS、INNODB_LOCK_WAITS、INNODB_TRX这三个表。
✅推荐使用:performance_schema.INNODB_TRX 和 performance_schema.data_locks 表就行了;
data_locks :表关键信息事务ID,事务获取锁数据(比如主键值)、等待锁数据,所以这个是很方便定位到死锁的,定位到死锁的事务ID,然后再去INNODB_TRX回查,就能定位到指定的SQL
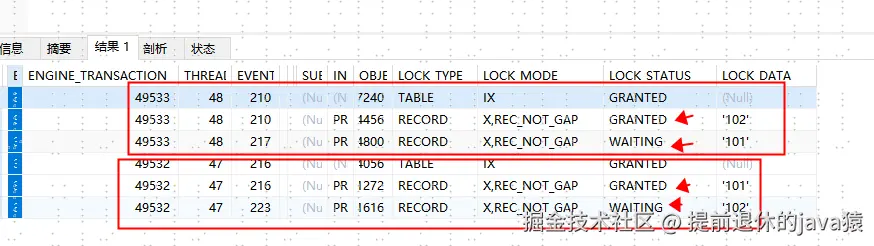
INNODB_TRX :表关键信息有事务ID,事务状态,等待执行的SQL。
事务状态字段: trx_state (事务状态,如果在等待锁就会显示:LOCK_WAIT); 事务ID:trx_id;事务等待执行SQL:trx_query ,事务的开始时间等(💢用来定位挂起的事务就非常方便了)。

死锁的预防
🔊这个就很简单了,首先就是保持更新表的顺序,比如各业务操作更新多表的时候,可以按照先更新主表再更新副表的顺序,或者直接按照 表名的 字符串排序更新。第二就是减少事务占用的时间 减少锁占用的时间,合理使用索引减少锁的范围,
监控死锁的第三方工具
上面都是基于MySQL 自带日志和事务表来分析的。下面介绍一下一些三方工具吧。 当然现在很多企业都使用大厂的云服务器,基本都自带数据库监控工具。
1. Percona Toolkit(PT 工具集)
- 作用 :
pt-deadlock-logger专门用于监控和记录 MySQL 死锁信息,可实时抓取死锁日志并输出到文件或数据库,支持定时运行和历史分析。 - 用法示例 :
pt-deadlock-logger --user=root --password=xxx localhost会持续监控并打印新发生的死锁,也可指定输出到文件:--dest file:/var/log/mysql/deadlocks.log
2. MySQL Workbench
- 作用:MySQL 官方图形化工具,内置 "Performance" 模块,可直观查看当前事务、锁等待、死锁历史等信息(需连接数据库后在 "Data Export" 或 "Performance Schema" 面板中操作)。
- 优势:可视化展示锁等待关系,适合新手快速定位问题。
3. Orchestrator
- 作用:一款开源的 MySQL 高可用管理工具,除了主从切换,还能监控数据库锁状态、死锁事件,并提供告警功能。
- 适用场景:分布式 MySQL 集群环境,需结合监控平台使用。
4. 监控平台集成(Prometheus + Grafana)
- 原理 :通过
mysqld_exporter采集 MySQL 锁相关指标(如innodb_deadlocks计数器),在 Grafana 中配置仪表盘,实时监控死锁发生频率,并设置告警(如死锁数突增时触发邮件 / 短信告警)。 - 关键指标 :
innodb_deadlocks(累计死锁次数)、innodb_lock_waits(锁等待次数)等。
MySQL什么场景下数据库会回滚部分SQL
上文说了等待锁超时,默认情况下会回滚等待锁的SQL。除了这种情况还存在其他情况也有这个问题。比如:
📃官方文档:dev.mysql.com/doc/refman/...
📢 博主测试过 锁等待超时,和 重复键插入,报错之后,继续commit ,报错行之后的SQL不会再被执行,只会提交回滚行之前的SQL。
总结
从为什么很少遇到死锁的原因,到死锁相关的配置,到死锁的解决思路,再到哪些场景数据库在回滚的时候会回滚当前阻塞的SQL。写这篇文章确实比较耗费心力,因为博主也做了很多测试。希望各位兄弟姐妹点个赞 收藏吧。