✅ 一、什么是学习率衰减?
学习率衰减(Learning Rate Decay) 是一种在训练过程中逐步降低学习率的技术。其核心思想是:
🔍 "先快后慢":
- 初期用较大的学习率快速逼近最优解;
- 后期用较小的学习率精细调整,避免震荡或跳过最小值。
✅ 二、为什么需要学习率衰减?
2.1 学习率过大 → 震荡
- 在接近最优解时,大步长会导致模型"来回跳动",无法收敛;
- 类比:爬山时最后几步太大,会从山顶滑下去。
2.2 学习率过小 → 收敛慢
- 初期更新太慢,浪费训练时间;
- 类比:刚开始走得太小心,效率低下。
✅ 因此,动态调整学习率是提升训练效果的关键策略。
✅ 三、常见学习率衰减方法
3.1 分段常数衰减(Piecewise Constant Decay)
-
将训练过程分为多个阶段,每个阶段使用不同的固定学习率;
-
常用于实验中手动调参。
示例:每 10 epochs 降一次
lr = [0.1, 0.05, 0.01, 0.001] # 每个阶段的 learning rate
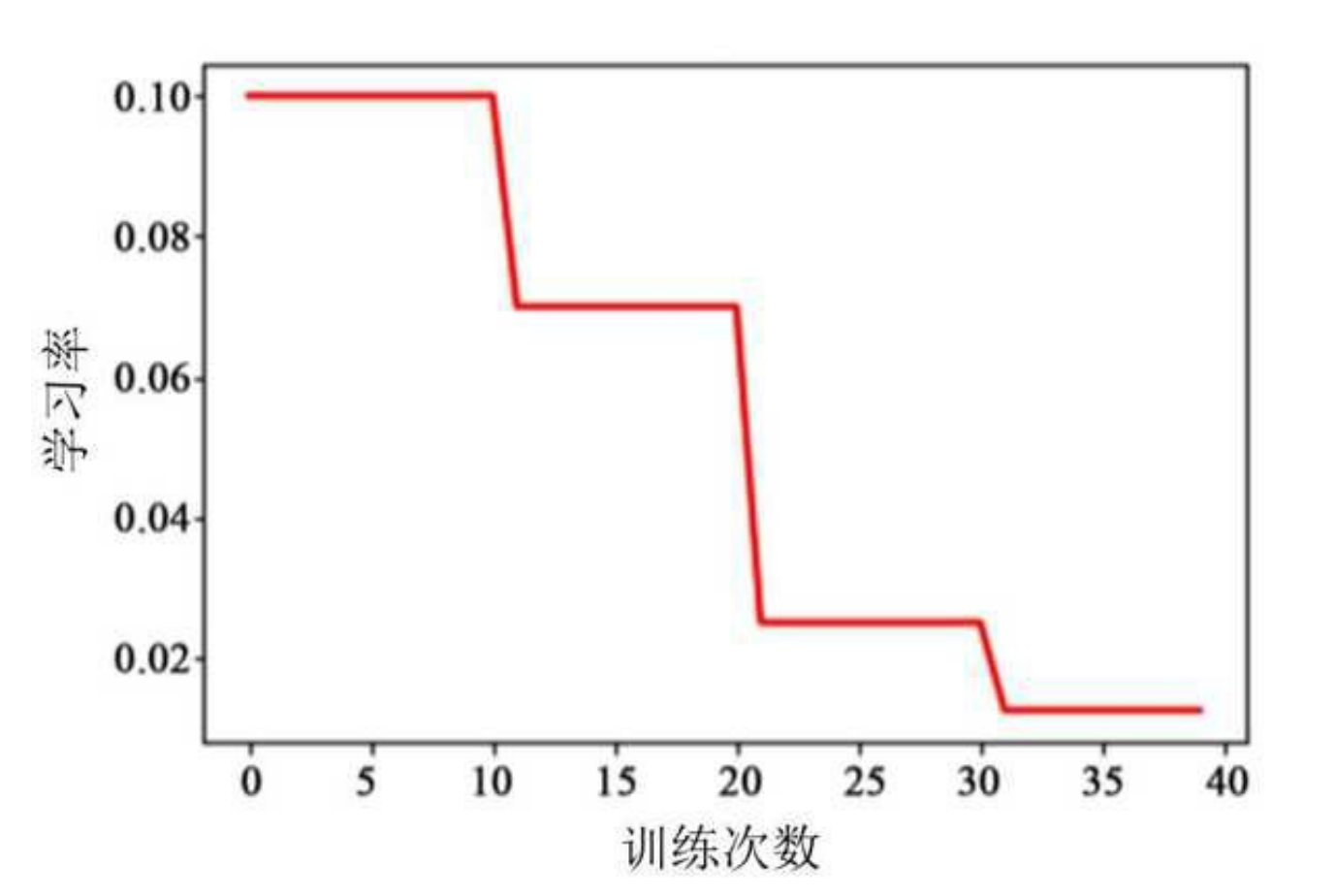
✅ 优点:简单直观;
❌ 缺点:不够灵活,需人工设定。
3.2 指数衰减(Exponential Decay)
- 学习率按指数函数下降:
或
其中:
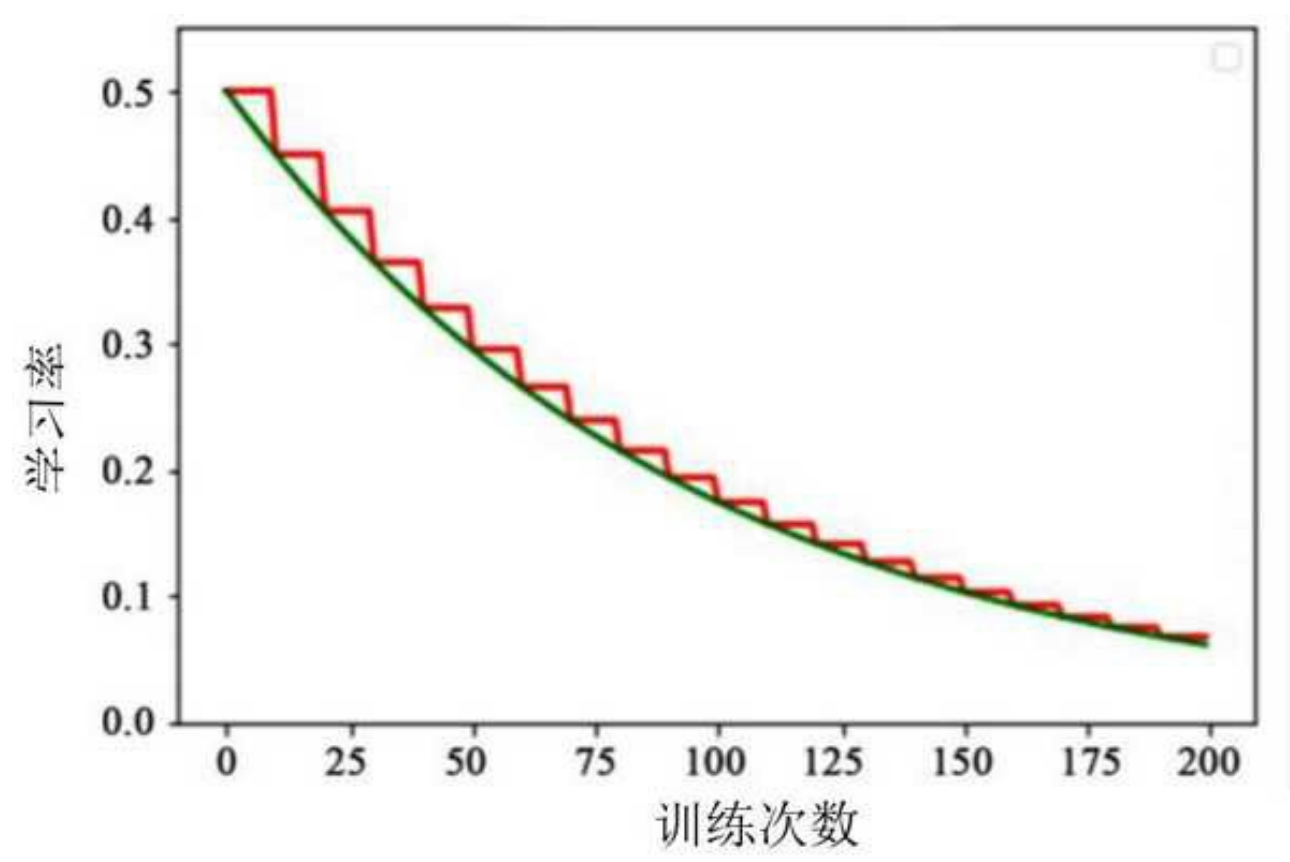
✅ 优点:平滑下降,适合大多数任务。
3.3 自然指数衰减(Natural Exponential Decay)
- 更常用的变体:
✅ 特点:前期下降快,后期趋于平稳。
3ا4 多项式衰减(Polynomial Decay)
- 使用多项式函数控制学习率下降:
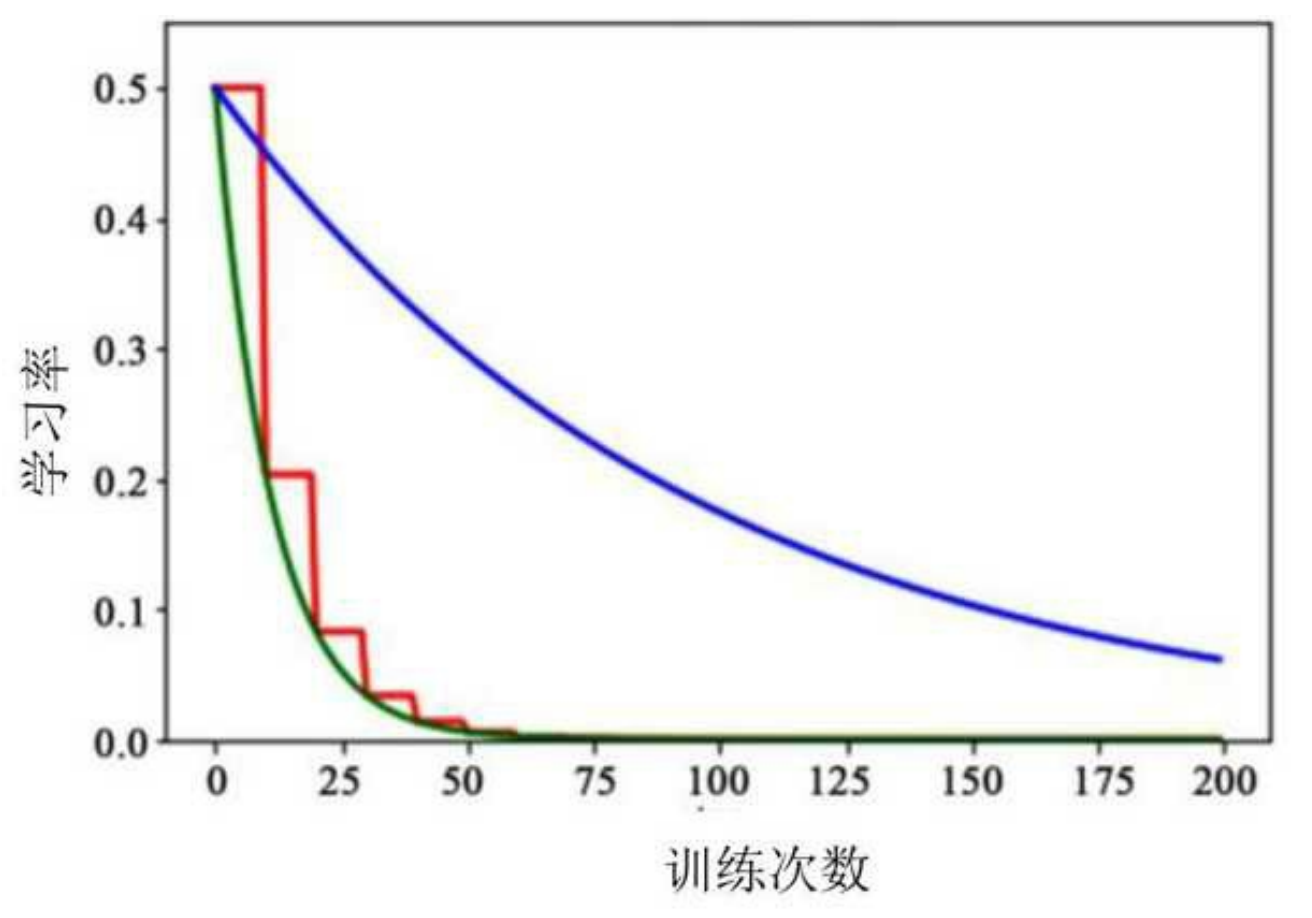
✅ 优点:可定制衰减曲线形状;
❌ 缺点:对超参数敏感。
3.5 余弦退火(Cosine Annealing)
-
使用余弦函数模拟学习率变化:
-
可结合周期性重启(Cyclic LR),实现"热重启"策略。
✅ 优点:能有效逃出局部极小值;
⭐ 常见于现代优化器(如 PyTorch 的
CosineAnnealingLR)。
3.6 余弦衰减(Cosine Decay)
- 类似余弦退火,但不重启:
✅ 优点:平滑过渡到最小学习率。
✅ 四、实际应用建议
| 方法 | 适用场景 | 推荐程度 |
|---|---|---|
| 分段常数 | 手动调参、调试阶段 | ⭐⭐ |
| 指数衰减 | 通用任务 | ⭐⭐⭐ |
| 多项式衰减 | 需要精细控制 | ⭐⭐⭐ |
| 余弦退火 | 复杂模型、大规模训练 | ⭐⭐⭐⭐ |
💡 经验法则:
- 初始学习率:0.001 ~ 0.01;
- 衰减方式:优先尝试余弦退火或指数衰减;
- 结合早停(Early Stopping)防止过拟合。
✅ 五、代码示例(PyTorch)
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR, ExponentialLR, CosineAnnealingLR
model = torch.nn.Linear(10, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 1. 分段衰减
scheduler = StepLR(optimizer, step_size=10, gamma=0.5) # 每10步乘0.5
# 2. 指数衰减
scheduler = ExponentialLR(optimizer, gamma=0.95) # 每步乘0.95
# 3. 余弦退火
scheduler = CosineAnnealingLR(optimizer, T_max=100) # 总步数100
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
scheduler.step() # 更新学习率✅ 六、总结
🌟 学习率衰减是提升模型收敛速度与稳定性的关键技术
它让训练过程像"登山"一样:先大步前进,再小步精调。
- 分段衰减:简单直接;
- 指数/多项式衰减:平滑可控;
- 余弦退火:最先进,推荐使用。
💡 一句话记住 :
"学习率不是越大越好,而是越'聪明'越好。"