
文章目录
- 一、定义&特点&使用场景
- 二、协议报文
-
- [1. 报文结构](#1. 报文结构)
-
- [1. HTTP请求报文结构](#1. HTTP请求报文结构)
- [2. HTTP响应报文结构](#2. HTTP响应报文结构)
- [2. HTTP请求](#2. HTTP请求)
-
- [1. URL](#1. URL)
-
- [1. 端口号](#1. 端口号)
- [2. 带有层次的文件路径](#2. 带有层次的文件路径)
- [3. 查询字符串](#3. 查询字符串)
- [4. 片段标识符](#4. 片段标识符)
- [2. 方法](#2. 方法)
- [3. 报头](#3. 报头)
-
- [1. host](#1. host)
- [2. Content-Length&Content-Type](#2. Content-Length&Content-Type)
- [3. User-Agent](#3. User-Agent)
- [4. Referer](#4. Referer)
- [5. Cokie](#5. Cokie)
- [3. HTTP响应](#3. HTTP响应)
-
- [1. 状态码](#1. 状态码)
- [2. 使用Java代码构造最原始的请求](#2. 使用Java代码构造最原始的请求)
- 三、HTTPS
-
- [1. 加密](#1. 加密)
- [2. 加密工作原理](#2. 加密工作原理)
-
- [1. 对称加密](#1. 对称加密)
- [2. 非对称加密](#2. 非对称加密)
- [3. 证书](#3. 证书)
一、定义&特点&使用场景
它本质上是一个在应用层方面的超文本的传输协议,可以传输视频、音频、图片等等内容,我们现在普遍使用的都是http1.1版本
http早期依赖于TCP进行传输,但是自从http3.0之后就改用UDP传输了
http主要是用于网页端前端和后端之间的通信,或者是移动端APP与服务器的通信,或者是分布式系统之间的调用
http是一个典型的一问一答的模型,即客户端发送一个请求,服务器就返回一个请求
二、协议报文
我们先来说说什么是代理?
代理分为正向代理和反向代理
正向代理指的是代替客户端干活,反向代理指的就是代替服务器去干活
我们要想看清楚协议报文的内部结构是什么,我们可以借助抓包工具,可以使用浏览器F12自带的解析,也可以使用诸如Fiddler等等抓包软件
1. 报文结构
1. HTTP请求报文结构

- 请求报头:我们看到里面有很多键值对,这些都是HTTP协议定义好的不能自行去修改
- 空行:用来区分请求报头和正文
- 请求正文:这个是可以忽略的
2. HTTP响应报文结构

2. HTTP请求
1. URL
我们通常叫做"网址",全称为唯一资源定位符,标识一个网络资源在网络中的位置
我们以一个理想情况下的标准URL做解析
http://User:pass@www.example.jp:80/dir/index.htm?uid=1#ch1http://指的是协议的域名User:pass指的是登录认证信息,现已弃用,原因是很容易写错www.example.com.jp指的是域名,即服务器地址80指的是服务器的端口号dir/index.htm指的是带有层次的文件路径uid=1指的是查询字符串ch1指的是片段标识符
下面我们就来解析下各个部分
1. 端口号
http如果我们不写服务器端口号,默认就是80,而对于https来说默认就是443
2. 带有层次的文件路径
服务器就像我们的硬盘一样,可能资源是存在不同的地方的,就像我们电脑上的文件路径一样,服务器也有自己的文件路径
当然这个文件路径可以是通过代码逻辑来编写一个虚拟的路径
3. 查询字符串
英文名叫Query String,也是使用一个键值的数据结构
对于不同键值对之间,我们使用&分割,而对于键和值之间我们使用=分割,当然里面的键值是我们程序员自己定的
如果我们在查询字符串中定义一个特殊符号,则会触发转码操作,即把每个字节内容转成16你只,每个字节前面加上%用于区分,比如我们搜索C++
https://cn.bing.com/search?q=C%2B%2B
可以很明显的看到+被转码成十六进制的2B了
4. 片段标识符
用来区分一个页面中的不同部分,比如一些文档网站,跳转不同的文档之间就会触发这个
https://cn.vuejs.org/guide/components/props.html#prop-passing-details
2. 方法
我们有很多常见的方法,以下是一些比较常用的方法,这些方法合在一起我们称之为Restful风格
| 方法 | 说明 | 协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0 1.1 |
| POST | 传输实体主体 | 1.0 1.1 |
| PUT | 传输文件 | 1.0 1.1 |
| HEAD | 获取报文头部 | 1.0 1.1 |
| DELETE | 删除文件 | 1.0 1.1 |
| OPTIONS | 访问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONECT | 使用隧道协议连接代理 | 1.1 |
| LINK | 建立与资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
当然上面这些都是设计者的美好幻想罢了,对于程序员来说遵不遵守就很难说了
我们来看几个最常用到的方法吧
GET:从服务器上去获取资源,通常这个请求报文都是没有正文body的,数据呢一般存在Query String中,并且我们每次得到的结果都是明确的,这个称之为幂等POST:把数据发送到服务器上,可能包含Query String,并且请求报文中一般都是有正文的,并且我们每次得到的结果都是不明确的,这个称之为非幂等PUT:一般用于更新数据,具有幂等建议,数据也存放在body中Delete:通常没有body,但是我们也是不允许随便去删除服务器上的资源的
3. 报头
1. host
顾名思义就是服务器的主机地址和端口号
2. Content-Length&Content-Type
这俩是成对出现的,为了解决TCP传输的粘包问题,Content-Length描述的是body中数据的长度,而Content-Type描述的是body中的数据格式
Content-Type常见的值有text/css,text/html,application/javascript,application/json等等
对于这些变动频率比较低的数据,浏览器会将这些数据保存到硬盘上,这样读取就快很多
3. User-Agent
它主要描述的是操作系统的信息和浏览器的信息,在前端开发中有一个叫响应式编程,会根据浏览器窗口尺寸自动对内容进行排版
4. Referer
跳转网页的时候会有这个内容,主要是告诉服务器这个请求是从哪里发出的
我们举个例子,假如你正在浏览www.example.com,此时你看到一个A网的图片链接www.apicture.com,你点进去此时会发送一个请求给A网的服务器,内容中的Referer就是www.example.com
5. Cokie
每个键值对之间使用;分割,键和值之间使用=分割
类似于Query String,是程序员自己定义的,本质上是把浏览器的数据本地存储,比如登录认证啥的,下次就可以直接访问硬盘,把硬盘中的数据发送给服务器
比如就拿登录举例,当登录成功后服务器会返回一个会话session,同时服务器维护了一个HashMAP中使用sessionId去区分不同用户的请求
3. HTTP响应
1. 状态码
本质上是一个服务器的反馈情况,我们有几个常见的状态码
200表示请求成功404 NOT FOUND表示你所要访问的资源在网络上不存在403 Foridden表示服务器拒绝访问405 Method Not Allowed表示你的方法服务器不支持500 Interal Sewer Errot表示服务器内部错误,说明服务器挂了504 Getway Timeout表示服务器网关繁忙302&301 Move&permanent temporaily表示临时重定向和拥有重定向,重定向有点类似于呼叫转移,即打旧号码自动转接到新号码
那么多状态码,简要概括就是
| 状态码 | 类别 | 说明 |
|---|---|---|
| 1xx | 信息性状态码 | 接受的请求正在处理 |
| 2xx | 成功状态码 | 请求处理完毕 |
| 3xx | 重定向状态码 | 需要进行附加操作完成请求 |
| 4xx | 客户端错误状态码 | 服务器无法处理请求 |
| 5xx | 服务器错误状态码 | 服务器处理请求出错 |
2. 使用Java代码构造最原始的请求
java
public class Test {
public static void main(String[] args) throws IOException, InterruptedException {
HttpClient httpClient = HttpClient.newHttpClient();
HttpRequest httpRequest = HttpRequest.newBuilder()
.uri(URI.create("https://www.baidu.com"))
.GET()
.header("User-Agent","aaaa")
.build();
HttpResponse<String> httpResponse = httpClient.send(httpRequest,HttpResponse.BodyHandlers.ofString());
System.out.println(httpResponse.statusCode());
System.out.println(httpResponse.headers());
System.out.println(httpResponse.body());
}
}当然我们也可用可视化工具诸如apifox,postman等等都可以
三、HTTPS
1. 加密
因为https本质上是在http基础上进行了加密操作,加密和解密的过程都会用到特殊的密钥
所谓对称加密就是一把钥匙加锁和解锁,非对称加密就是一把钥匙加锁一把钥匙解锁
2. 加密工作原理
1. 对称加密
客户端或者是服务器生成一个密钥,同时让对方也持有这个密钥
在客户端发给服务器的数据中使用这个密钥进行加密,服务器就会使用这个密钥解密
但是由于你数据发出去的同时也把密钥发出去了,如果中间路由器被人劫持了你的数据也就暴露无遗了
就像你给对方发了一份上了锁的数据,你把钥匙也挂上面了,那你这还不如不上锁,掩耳盗铃
2. 非对称加密
针对以上情况,我们就需要使用非对称加密,把钥匙分成两份,一份是公钥,一份是私钥,两个密钥之间有一定的数学联系
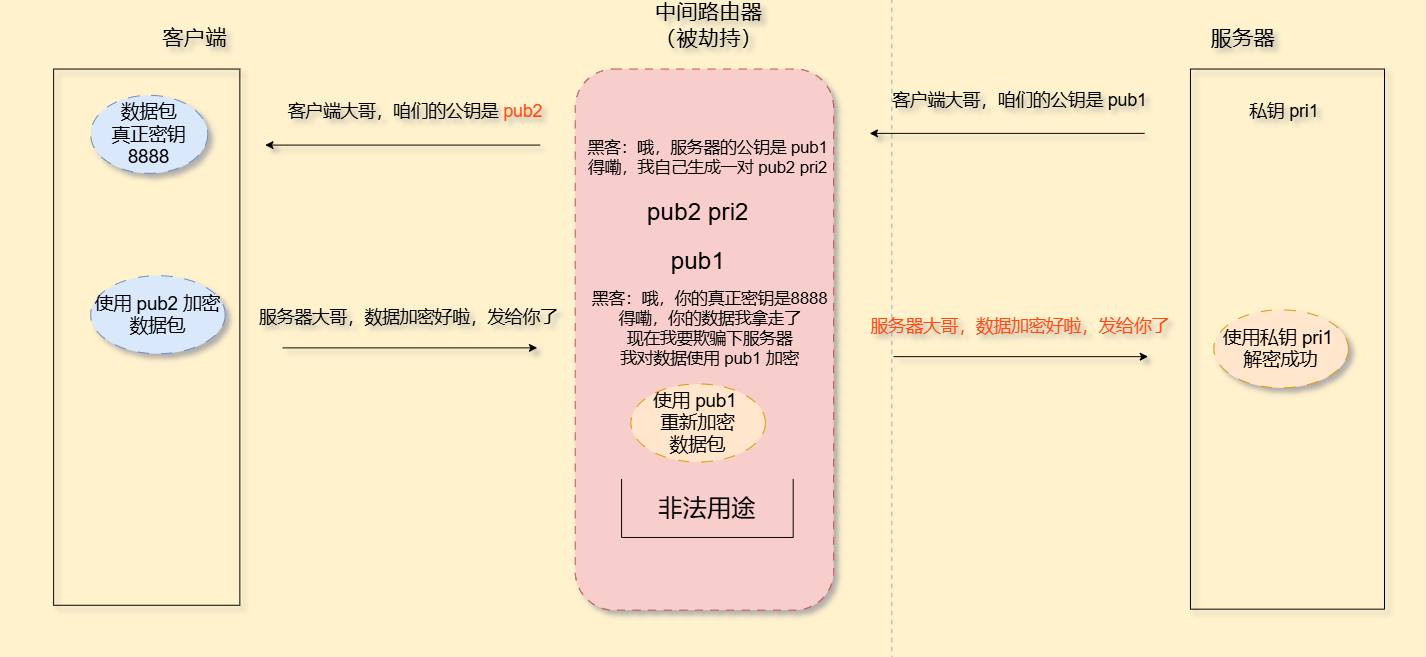
服务器先生成公钥和私钥,服务器自己持有私钥,把公钥发给客户端,客户端拿到这个公钥对这个数据进行加密,服务器拿到后再用私钥进行解密,但是还是有风险,还是中间路由器被人劫持这种情况(中间人攻击)
服务器生成了一对密钥pri1/pub1,服务器自己持有pri1,向客户端发送pub1
但是经过中间路由的时候,由于被劫持,中间路由未造成服务器,自己生成了另一对密钥pri2/pub2
此时中间路由保存了服务器的公钥pub1,但是给客户端返回的却是自己生成的pub2,此时客户端不知道中间路由被劫持了,就拿这个pub2密钥加密数据,然后发给中间路由
此时被劫持的中间路由用自己的私钥pri2进行解密得到真正密钥假如是8888,此时中间路由再伪装成客户端对这个数据使用服务器的公钥pub1进行加密发送给服务器
此时服务器同样也不知道中间路由被劫持,因此照常按照自己的私钥pri1进行解密得到真正密钥8888,在使用这个真正密钥进行解密得到数据
此时这份从客户端发来的数据除了被服务器持有,被劫持的中间路由也同样持有
我们简要画个图来说明这个过程
3. 证书
- 服务器出示"身份证":服务器将它的数字证书发送给客户端。
- 客户端联网"查户口":客户端操作系统/浏览器用内置的"公安系统信息"(CA根证书)去验证这张"身份证"(服务器证书)的真伪。
- 验证签名:用CA的公钥去解密证书签名,看是否能匹配证书内容。如果匹配,说明证书确实由该CA签发,且内容未被篡改。
- 验证信息:检查证书上的域名是否与正在访问的网站一致,证书是否在有效期内。
- 验证成功,建立信任:如果所有检查都通过,客户端就信任证书中包含的那个服务器的公钥是真的。随后,就可以用这个公钥安全地协商出对称加密的会话密钥。
文章内容在面试都是高频考点,属于是典型的八股文了哈
但重点在于理解,理解后再进行记忆
END♪٩(´ω`)و♪`