Title
题目
Category-specific unlabeled data risk minimization for ultrasoundsemi-supervised segmentation
面向超声半监督分割的类别特异性无标记数据风险最小化
01
文献速递介绍
超声图像分割的核心挑战与CSUDRM方法设计 #### 一、超声图像分割的重要性与核心痛点 1. 核心价值:作为医学影像分析的关键步骤,超声图像分割可勾勒不同类别组织边界,为器官发育分析、体积/形态相关临床参数计算提供支撑。 2. 技术现状:卷积神经网络(CNN)是主流分割方法,在各类超声分割任务中表现优异,但依赖大规模高质量标注数据。 3. 核心痛点: - 标注瓶颈:临床场景中,超声数据标注需专业知识且耗时,大规模标注数据难以获取。 - 图像特性难题:超声图像分辨率低、对比度差,导致组织边界模糊,存在"类间相似性高"和"类内差异性大"的问题,增加分割难度。 #### 二、现有半监督分割方法的局限 半监督学习(SSL)通过结合少量标注数据和大量无标注数据提升性能,现有方法主要分为三类,均存在明显不足: 1. 伪标签学习:为无标注数据生成伪标签,但错误标签无法在训练中修正,且忽视不同类别的分割难度差异,小目标、边界模糊类别易产生更多错误标签。 2. 一致性学习:采用双网络策略,对输入图像施加扰动后学习预测一致性,但依赖特定任务的扰动方法,鲁棒性不足,复杂超声场景下可能生成无效图像。 3. 其他训练策略:包括深度对抗网络(DAN)和无标记风险最小化方法(如MERU),前者依赖对抗学习机制,后者虽提出最小化全训练集风险,但未充分利用类别特异性信息。 #### 三、CSUDRM框架核心设计 针对上述问题,提出"类别特异性无标记数据风险最小化(CSUDRM)"半监督分割框架,包含两大核心模块: 1. 类别特异性分布对齐(CSDA) - 核心机制:通过类别特异性归一化(CSN),对齐标注与无标注数据中同一类别的语义特征分布。 - 关键作用:增强类内特征紧凑性和类间区分度,为难分割类别提供专属惩罚机制,解决不同类别语义收敛不一致的问题。 2. 无标记数据风险最小化(UDRM) - 核心机制:利用CSDA学习到的类别特异性分布信息,估计无标记数据的类别先验概率,进而最小化全训练集的风险。 - 关键优势:避免仅优化标签的局限,提升预测鲁棒性,降低估计方差,防止过拟合。 3. 骨干网络设计:采用单网络多尺度金字塔监督结构,结合多尺度输出监督无标记数据的一致性,引入不确定性正则化,鼓励模型更自信地从无标记数据中学习。 #### 四、方法核心贡献 1. 创新CSDA模块:构建可学习的类别特异性分布空间,增强标注与无标注数据的语义一致性。 2. 提出UDRM模块:融合类别特异性分布提示,实现更精准稳定的无标记数据风险估计与最小化。 3. 优异性能表现:在四个超声数据集上超越现有最先进半监督分割方法,计算成本相当,且通过定量对比、特征空间可视化、鲁棒性分析等消融实验验证了设计有效性。
Aastract
摘要
Achieving accurate computer-aided analysis of ultrasound images is challenging, since not only its imageartifacts but also the difficulties in collecting large-scale pixel-wise annotations from experts for training. Semisupervised segmentation is a solution for learning from labeled and unlabeled data, which mainly focuseson generating pseudo annotations for unlabeled data or learning consistent features in enhanced views ofimages to enhance model generalization. However, anatomically, diverse learning difficulties across tissuesare overlooked, and, technically, the estimation and minimization of empirical risk for unlabeled training dataare largely ignored. Motivated by them, this work proposes a semi-supervised segmentation model, namedCSUDRM, with two modules. The former is called category-specific distribution alignment (CSDA), whichlearns more consistent feature representations of the same class across labeled and unlabeled data. Moreover,it enhances feature space intra-class compactness and inter-class discrepancy and provides category-specificpenalties for more robust learning. The latter one is Unlabeled Data Risk Minimization (UDRM). It minimizesthe risk on the entire training data, which distinguishes it from most existing works that merely optimizelabels. The risk of unlabeled data is estimated by a novel learnable class prior estimator, with the help ofdistributional hints from CSDA. This design could reinforce the robustness of the model and achieve stablesegmentation. CSUDRM achieves state-of-the-art performances on four ultrasound datasets. Extensive ablationstudies, including quantitative comparisons, feature space visualization, and robustness analysis, demonstratethe superiority of our designs.
类别特异性无标记数据风险最小化方法(CSUDRM)的核心应用场景 1. 超声影像计算机辅助分析场景:针对超声图像伪影多、专家逐像素标注成本高、大规模标注数据难获取的问题,替代传统依赖全标注数据的分割方法。 2. 多组织超声分割场景:适用于解剖结构中不同组织学习难度差异大的情况(如肝脏、肾脏、甲状腺等器官的超声分割),能优化不同组织类别的特征学习。 3. 高鲁棒性超声分割需求场景:需要提升模型泛化能力和稳定性的场景,例如跨中心超声数据分割、不同设备采集的超声影像统一分析。 4. 有限标注资源的临床场景:医疗资源有限、难以获取大量专家标注的机构,可通过少量标注数据结合大规模无标注数据训练高精度分割模型。 ### 方法核心适配优势 - 解决超声影像的固有缺陷(伪影、噪声)和标注瓶颈,降低对大规模标注数据的依赖。 - 通过类别特异性分布对齐(CSDA)适配不同组织的学习差异,提升多类别分割准确性。 - 无标记数据风险最小化(UDRM)模块强化模型鲁棒性,适配不同临床环境下的超声数据波动。 要不要我帮你整理一份场景-方法适配要点清单,明确不同应用场景下该方法的核心技术优势与落地重点,方便快速对接实际需求?
Method
方法
3.1. Problem setting and overall framework
Different from fully-supervised setting, the training dataset ={ 𝑙 , 𝑢 } of semi-supervised problem consists of a labeled subset 𝑙 andan unlabeled subset 𝑢 . Labeled subset 𝑙 = (𝐗*𝑖* , 𝐘*𝑖* ) 𝑚**𝑙𝑖*=1 has 𝑚**𝑙 image--label pairs (𝐗*𝑖* , 𝐘*𝑖* ), where, in this work, 𝐗*𝑖* ∈ R𝐻×𝑊 is a grayscaleultrasound image with size 𝐻 × 𝑊 and 𝐘*𝑖* is its corresponding pixel wise label. In semi-supervised setting, the number of labeled samples𝑚𝑙* is much smaller than that of the unlabeled subset *𝑚𝑢* . The aim ofsemi-supervised learning is to learn from both labeled and unlabeleddata for better image segmentation.The overview of our semi-supervised framework CSUDRM is illustrated in Fig. 2. Our proposed framework comprises three majormodules: a multi-scale pyramid network, CSDA, and UDRM. As illustrated in Fig. 2, we utilize U-Net (Ronneberger et al., 2015) as thenetwork backbone. In the following of this section, we elaborate on themulti-scale pyramid network architecture in Section 3.2. And we introduce Category-specific Distribution alignment (CSDA) and UnlabeledData Risk Minimization(UDRM), in Sections 3.3 and 3.4, respectively.Finally, we describe the total loss configuration in Section 3.5.
3.1 问题设定与整体框架 与全监督学习不同,半监督学习的训练数据集 = {ₗ, ᵤ} 包含标注子集ₗ 和无标注子集ᵤ。标注子集ₗ = {(𝐗ᵢ, 𝐘ᵢ)}₍ᵢ₌₁⁾ᵐˡ 包含𝑚ₗ 个图像-标签对 (𝐗ᵢ, 𝐘ᵢ),其中本研究中𝐗ᵢ ∈ ℝ^𝐻×𝑊 表示尺寸为𝐻×𝑊 的灰度超声图像,𝐘ᵢ 为其对应的逐像素标签。在半监督学习场景中,标注样本数量𝑚ₗ 远少于无标注样本数量𝑚ᵤ。半监督学习的目标是结合标注数据和无标注数据进行学习,以实现更优的图像分割效果。 所提半监督框架CSUDRM的整体结构如图2所示,包含三个核心模块:多尺度金字塔网络、类别特异性分布对齐(CSDA)和无标记数据风险最小化(UDRM)。如图2所示,我们采用U-Net(Ronneberger等人,2015)作为网络骨干。本节后续内容中,3.2节将详细阐述多尺度金字塔网络架构,3.3节和3.4节分别介绍类别特异性分布对齐(CSDA)与无标记数据风险最小化(UDRM),最后在3.5节说明总损失函数的配置。 要不要我帮你整理一份框架核心模块与对应功能清单,明确各模块的核心作用、输入输出及与其他模块的关联,方便快速梳理技术逻辑?
Conclusion
结论
In this paper, we propose a novel CSUDRM framework to tacklethe two main challenges of semi-supervised segmentation methods:(1) the semantic convergence consistency across different categories isoverlooked, (2) risk optimization on unlabeled training data is largelyignored. CSDA aligns the feature distribution of the same categoryamong the whole dataset by establishing learnable category-specificfeature distribution spaces to achieve inter-class separability and intraclass compactness. The proposed UDRM estimates and minimizes therisk expectation on unlabeled images, which distinguishes it from mostexisting works that merely optimize labels. It utilizes labeled data,unlabeled data, and class priors to derive the expected decision boundary. Extensive experiments on F-A4C dataset, HC-18 dataset, BUS-BRAdataset, and OKUS dataset demonstrate the superiority of the proposedmethod. Moreover, ablation studies prove the effectiveness of eachcomponent, which can be flexibly applied to a wide range of ultrasound image segmentation tasks, and have significant clinical value inreducing the labor of ultrasound image analysis data annotation.
本文提出一种新颖的CSUDRM框架,旨在解决半监督分割方法面临的两大核心挑战:(1)忽视不同类别间的语义收敛一致性;(2)在很大程度上忽略对未标记训练数据的风险优化。 ### 核心组件设计 - CSDA(类别特异性分布对齐):通过构建可学习的类别专属特征分布空间,对齐整个数据集中同一类别的特征分布,实现类间可分性与类内紧凑性。 - UDRM(未标记数据风险最小化模块):估算并最小化未标记图像的风险期望,区别于多数现有方法仅优化标签的思路。该模块融合标记数据、未标记数据及类别先验,推导期望决策边界。 ### 实验验证与价值 - 基于F-A4C、HC-18、BUS-BRA和OKUS四个数据集的大量实验,验证了所提方法的优越性。 - 消融实验证实了各组件的有效性,该框架可灵活应用于多种超声图像分割任务。 - 在减少超声图像分析数据标注工作量方面,具备重要的临床价值。 要不要我帮你整理一份CSUDRM框架核心要点总结表,清晰呈现其解决的问题、核心组件、创新点及应用价值?
Results
结果
In this section, the proposed method is compared with other stateof-the-art SSL methods on four ultrasound segmentation tasks in Section 5.1. Then, to analyze the effectiveness of our proposed framework,we provide a series of ablation studies in Section 5.2. Finally, Section 5.3 reveals the performance of CSUDRM with different proportionsof labeled images on four ultrasound datasets.
5.1. Comparison with state-of-the-art methods
To validate the effectiveness of the proposed model, it is compared with supervised learning with different percentages of labeled data(SL) and state-of-the-art semi-supervised methods on four ultrasounddatasets from the perspectives of quantitative performances and computational consumption. Following previous works (Luo et al., 2022), twoconditions that only 10% and 20% of training samples are labeled areused for evaluation. For the fair comparison, all methods are comparedunder the same backbone and are implemented using their officiallyreleased codes. In addition, a fully supervised segmentation basedon U-Net (Ronneberger et al., 2015) is leveraged as the supervisedbaseline.
本节中,5.1 节将所提方法与其他最先进的半监督学习(SSL)方法在四个超声分割任务上进行对比;5.2 节通过一系列消融实验分析所提框架的有效性;最后 5.3 节展示 CSUDRM 在四个超声数据集上,不同标注图像比例下的性能表现。
5.1 与最先进方法的对比
为验证所提模型的有效性,从定量性能和计算开销两个角度,在四个超声数据集上,将其与不同标注数据比例的监督学习(SL)方法及最先进的半监督方法进行对比。参考现有研究(Luo 等人,2022),采用仅 10% 和 20% 训练样本标注的两种实验设置进行评估。为保证对比公平性,所有方法均基于相同的骨干网络,并使用其官方发布的代码实现。此外,以基于 U-Net(Ronneberger 等人,2015)的全监督分割作为监督学习基准模型。
Figure
图
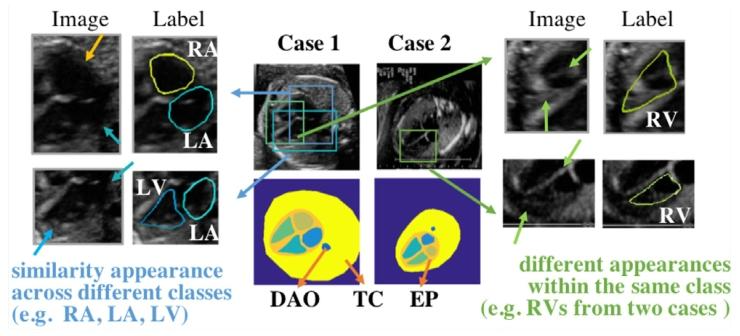
Fig. 1. Two examples of ultrasound obstetric fetal apical four-chamber viewsand their ground truth. Seven segmentation targets: left atrium (LA), rightatrium (RA), left ventricle (LV), right ventricle (RV), epicardium (EP), thoraciccontour (TC), and descending aorta (DAO)
要不要我帮你整理一份CSUDRM方法核心设计与优势对照表,清晰呈现模块功能、解决的问题及相较于传统方法的提升点,方便快速梳理方法亮点?
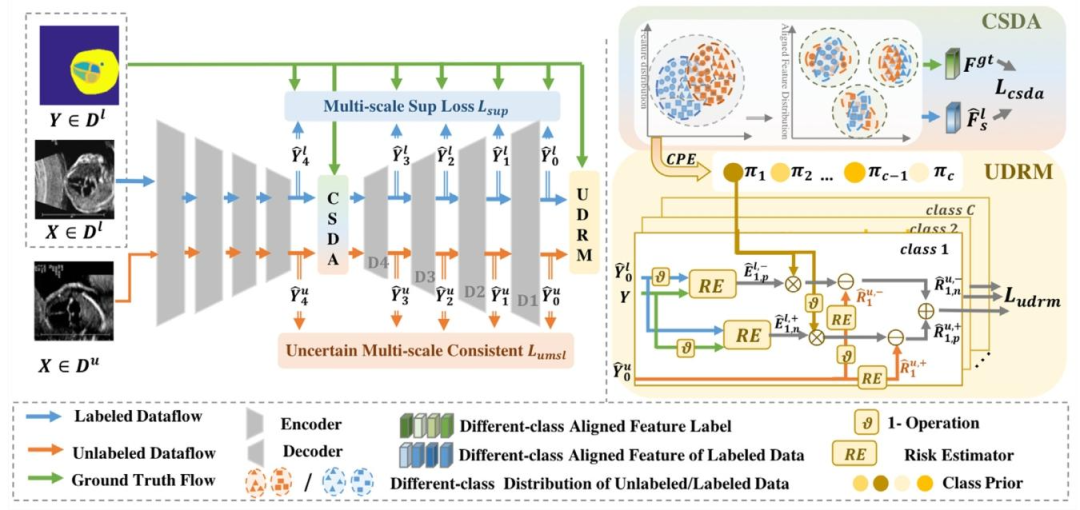
Fig. 2. Overview of the proposed semi-supervised architecture that consists of three parts: (1) a pyramid segmentation network; (2) Category-specific Distribution
alignment (CSDA) and (3) Unlabeled Data Risk Minimization(UDRM)
图2. 所提半监督架构总览,包含三部分:(1)金字塔分割网络;(2)类别特异性分布对齐(CSDA);(3)无标记数据风险最小化(UDRM)
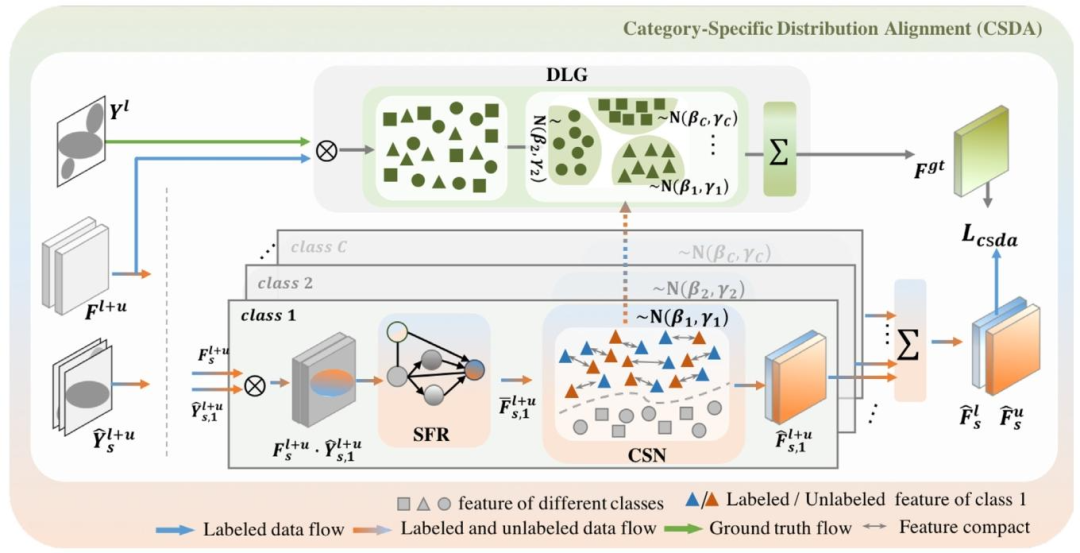
Fig. 3. The detailed architecture of our Category-specific Distribution alignment (CSDA). It consists of Semantic Feature Reinforcement (SFR), Category-specificNormalization (CSN), and Distribution Label Generation (DLG). The bidirectional gray arrows in the CSN represent compacting feature of the same categorybetween labeled and unlabeled data.
图3. 类别特异性分布对齐(CSDA)的详细架构。该架构包含语义特征强化(SFR)、类别特异性归一化(CSN)和分布标签生成(DLG)三部分。CSN中的双向灰色箭头表示压缩标注数据与无标注数据中同一类别的特征。
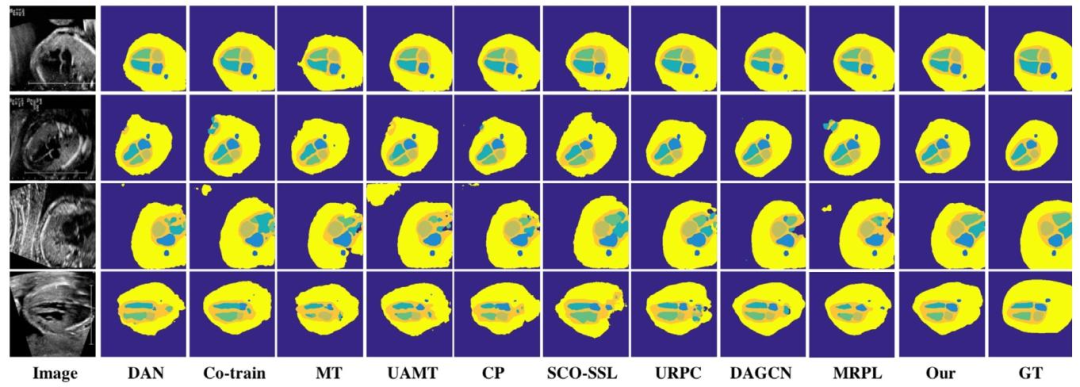
Fig. 4. Visual comparison of different semi-supervised methods for F-A4C dataset segmentation with 20% training labeled data. GT means ground truth
图4. 20%训练样本标注情况下,不同半监督方法在F-A4C数据集分割任务上的可视化对比结果。GT表示真实标签。
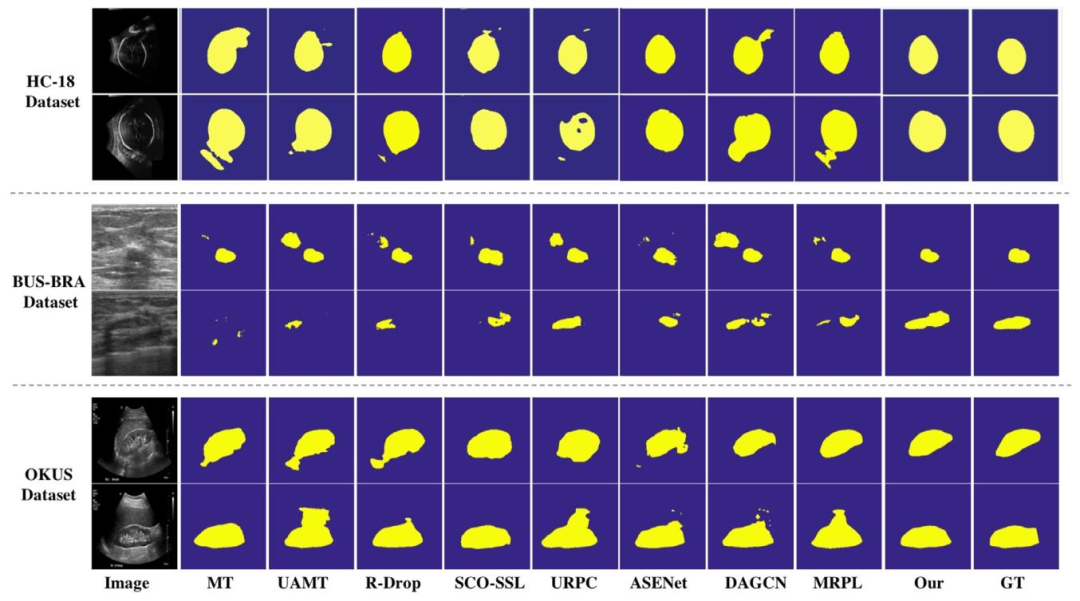
Fig. 5. Visual segmentation comparison of different semi-supervised methods for HC-18 dataset, BUS-BRA dataset, and OKUS dataset with 20% training labeleddata. GT means ground truth.
图5. 20%训练样本标注情况下,不同半监督方法在HC-18数据集、BUS-BRA数据集及OKUS数据集上的分割可视化对比结果。GT表示真实标签。
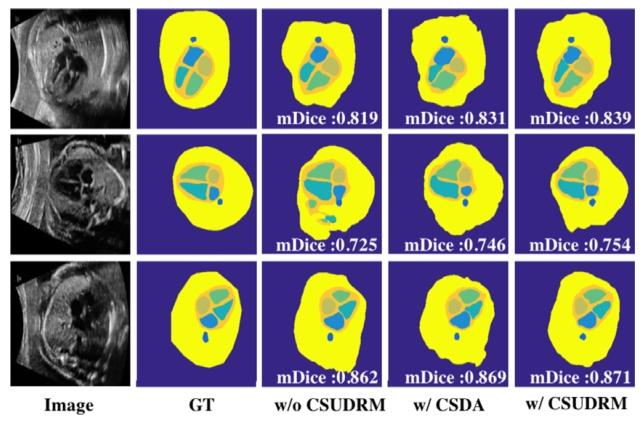
Fig. 6. Visualization of the ablation studies on F-A4C dataset
图6. F-A4C数据集上的消融实验可视化结果
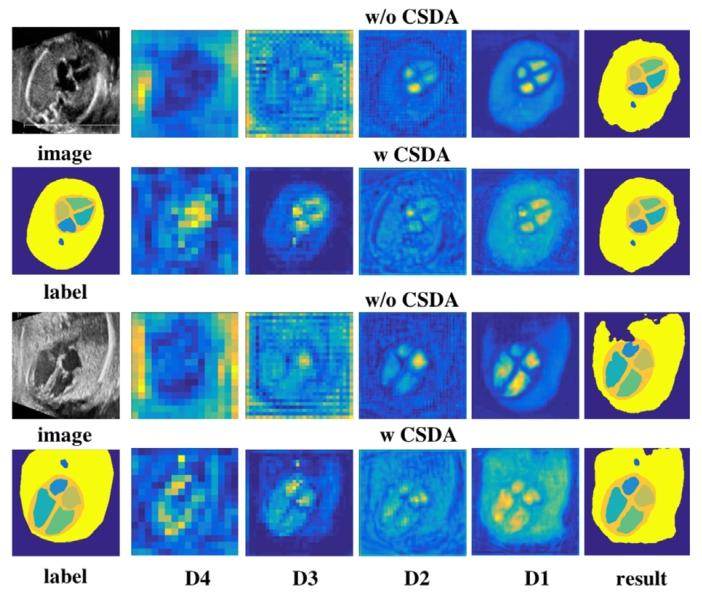
Fig. 7. Visualization of feature at different stages. w/o denotes without; w/denotes with. D1--D4 denote different stages of decoder in Fig. 2.
图7. 不同阶段的特征可视化结果。w/o表示"无";w/表示"有"。D1--D4对应图2中解码器的不同阶段。
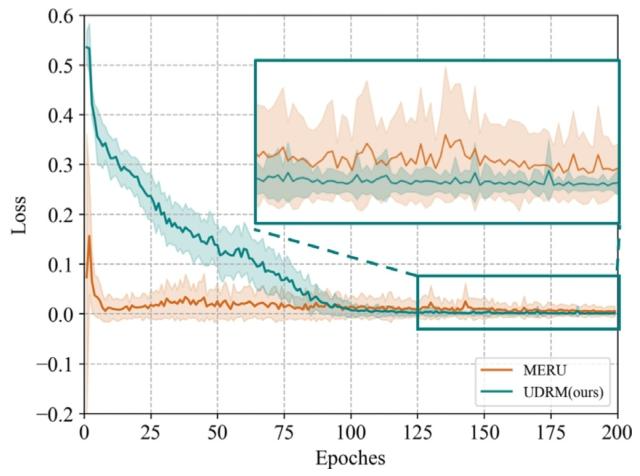
Fig. 8. Means and variances of the loss term 𝑛𝑛 ̂𝑅*𝑢, 𝑝 + in our method and MERUduring training
图8. 训练过程中,所提方法与MERU方法中损失项𝑛𝑛̂𝑅𝑢,𝑝+的均值和方差对比图。

Fig. 9. T-SNE visualization of multi-class distribution on F-A4C dataset. w/odenotes without; w/ denotes with. In the same category, dark color indicatesthe distribution of unlabeled data, while light color represents the distributionof labeled data
图9. F-A4C数据集上多类别分布的T-SNE可视化结果。w/o表示"无";w/表示"有"。同一类别中,深色代表无标注数据的分布,浅色代表标注数据的分布。
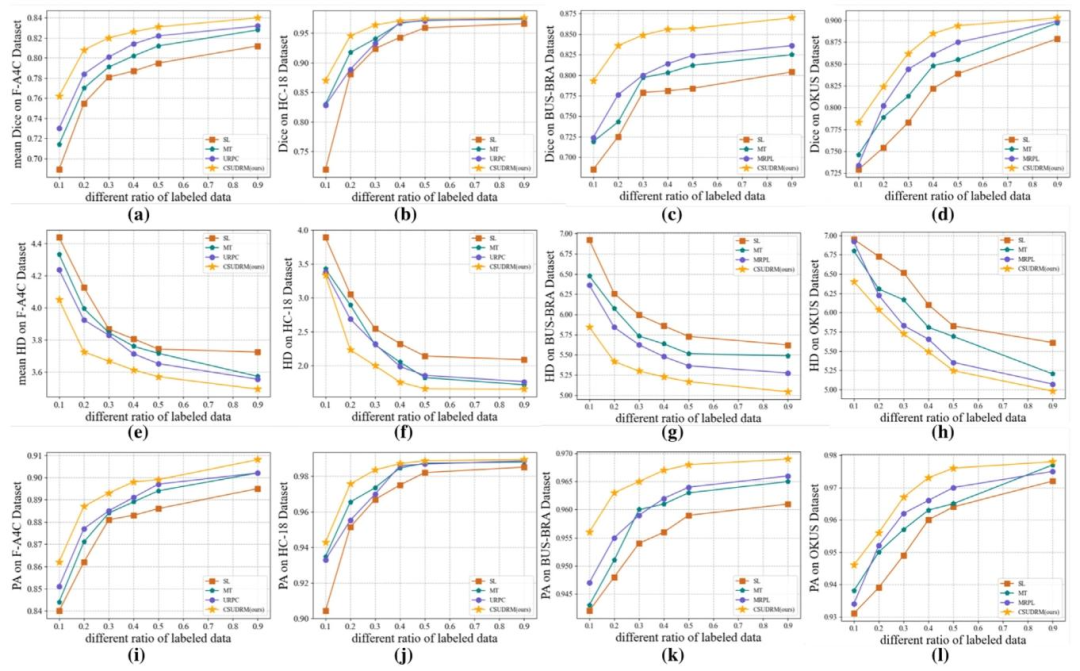
Fig. 10. Results of four different methods with different ratios of labeled images. (a)--(d) depict Dice results on the four datasets, (e)--(h) show HD results on thefour datasets, and (i)--(l) show PA results on the four datasets. The higher Dice and PA indicate the better performance, while the smaller HC indicate the betterperformance.
图10. 四种不同方法在不同标注图像比例下的实验结果。(a)--(d) 分别为四个数据集上的Dice系数结果,(e)--(h) 为四个数据集上的HD(豪斯多夫距离)结果,(i)--(l) 为四个数据集上的PA(像素准确率)结果。Dice系数和PA值越高表示性能越好,而HD值越小表示性能越好。
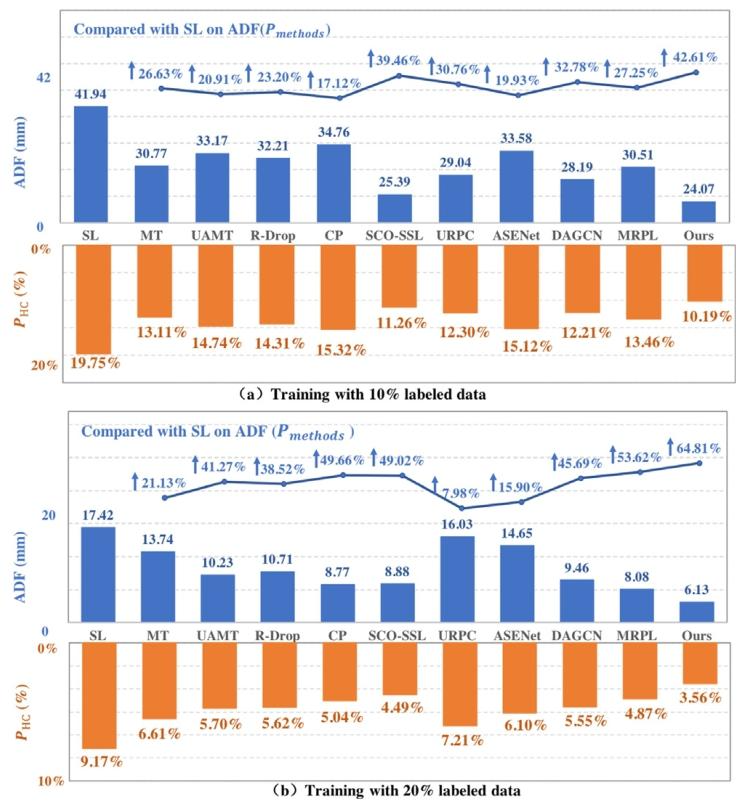
Fig. 11. Results of head circumference on HC-18 dataset. The smaller 𝐴𝐷𝐹and 𝑃**𝐻𝐶 indicate the better performance (represented by column charts), whilethe larger 𝑃𝑚𝑒𝑡ℎ𝑜𝑑𝑠 indicates the better performance (represented by line charts).
图11. HC-18数据集上的头围测量结果。ADF(平均绝对偏差)和PHC(预测头围误差)值越小表示性能越好(以柱状图呈现),而Pmethods(方法准确率)值越大表示性能越好(以折线图呈现)。
Table
表
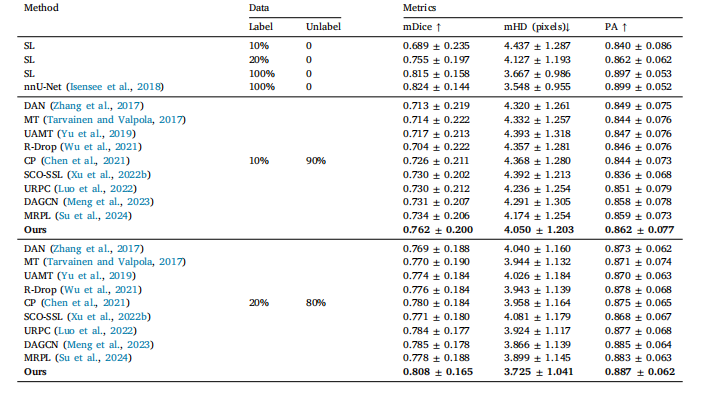
Table 1Comparison results between our method and other semi-supervised methods on F-A4C dataset. Best results are highlighted. SLmeans supervised learning with partial percentages of labeled data.
表1 所提方法与其他半监督方法在F-A4C数据集上的对比结果。最佳结果已高亮标注。SL表示使用部分比例标注数据的监督学习方法。
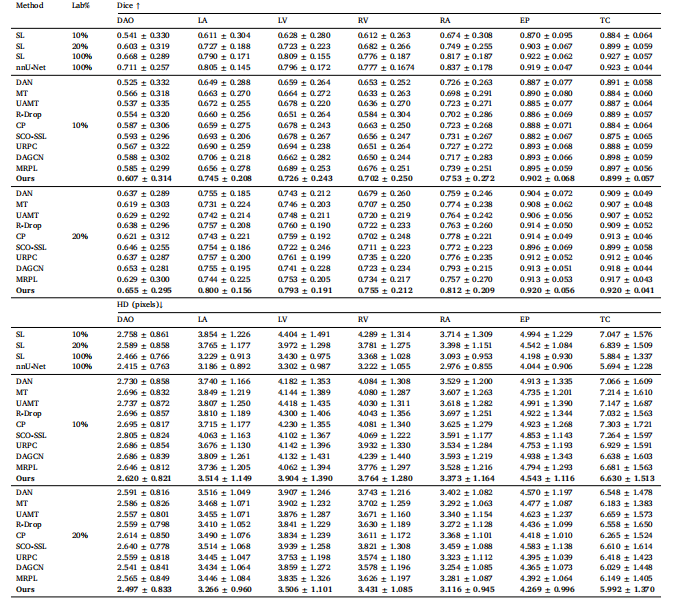
Table 2The results of Dice and HD for seven targets compared our method with other semi-supervised methods on F-A4C dataset. SL means supervised learning withpartial percentages of labeled data. Best results are highlighted.
表2 所提方法与其他半监督方法在F-A4C数据集上针对七个分割目标的Dice系数和HD(豪斯多夫距离)对比结果。SL表示使用部分比例标注数据的监督学习方法。最佳结果已高亮标注。
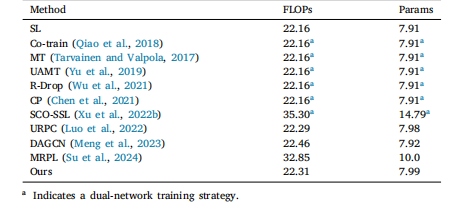
Table 3Comparison complexity between our method and other semi-supervised methods on the F-A4C dataset.
表3 所提方法与其他半监督方法在F-A4C数据集上的复杂度对比结果。
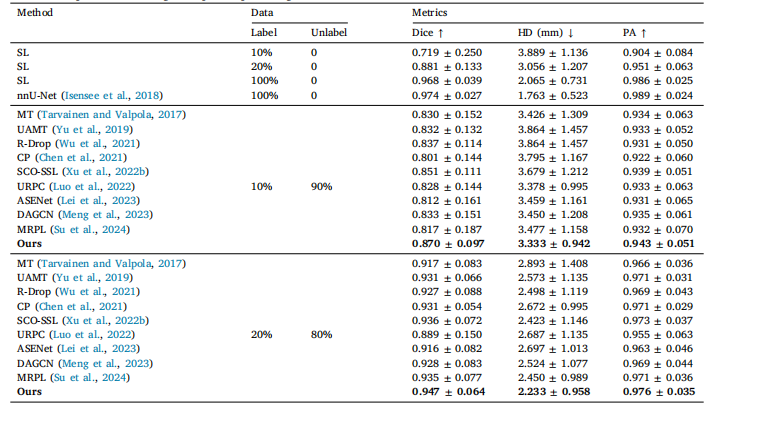
Table 4Comparison results between our method and other semi-supervised methods on HC-18 dataset. The best results are highlighted.SL means supervised learning with partial percentages of labeled data
表4 所提方法与其他半监督方法在HC-18数据集上的对比结果。最佳结果已高亮标注。SL表示使用部分比例标注数据的监督学习方法。
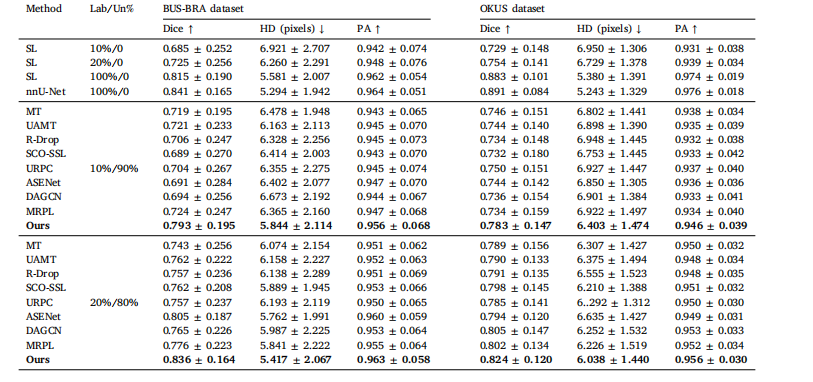
Table 5Comparison results between our method and other semi-supervised methods on BUS-BRA dataset and OKUS dataset. Best results arehighlighted. SL means supervised learning with partial percentages of labeled data
表5 所提方法与其他半监督方法在BUS-BRA数据集和OKUS数据集上的对比结果。最佳结果已高亮标注。SL表示使用部分比例标注数据的监督学习方法。
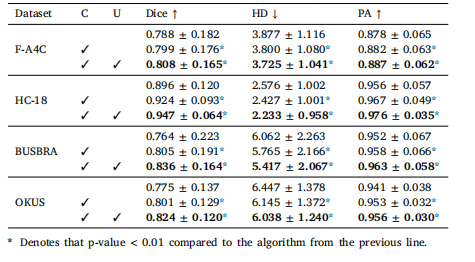
Table 6Ablation results on the four datasets. C denotes CSDA, U denotes UDRM
表6 四个数据集上的消融实验结果。C表示类别特异性分布对齐(CSDA),U表示无标记数据风险最小化(UDRM)。
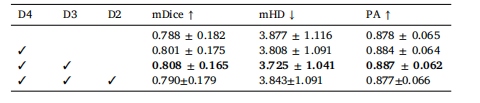
Table 7Ablation studies of the impact of the different position to add CSDA and UDRMon F-A4C dataset with a labeled ratio of 20%.
表7 20%标注比例下,在F-A4C数据集上添加CSDA和UDRM的不同位置对模型影响的消融实验结果。
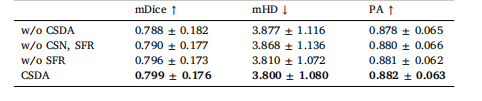
Table 8Ablation studies of CSDA on F-A4C dataset with a labeled ratio of 20%. Thefirst line means training without CSDA.
表8 20%标注比例下,CSDA模块在F-A4C数据集上的消融实验结果。第一行表示不使用CSDA模块进行训练的结果。
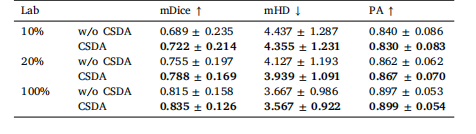
Table 9The experiments of CSDA in fully-supervised segmentation on F-A4C dataset.
表9 类别特异性分布对齐(CSDA)模块在F-A4C数据集全监督分割任务中的实验结果。
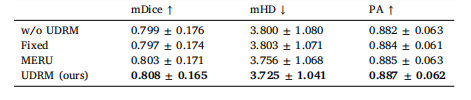
Table 10Different class prior estimators of UDRM on F-A4C dataset with a labeled ratioof 20%
表10 20%标注比例下,UDRM模块的不同类别先验估计器在F-A4C数据集上的实验结果。

Table 11Ablation analysis of UMSL without CSUDRM on F-A4C dataset with a labeledratio of 20%
表11 20%标注比例下,未结合CSUDRM的多尺度一致性监督(UMSL)在F-A4C数据集上的消融分析结果。