
信息海洋------为什么你的"研究"效率如此低下?
想象一下一个世纪前的淘金者。他们最大的挑战是找到那条蕴藏黄金的河流。而今天,身为知识工作者的我们,面临着一个截然不同的困境:我们并非找不到河流,而是深陷一片由信息构成的汪洋大海。这条"河"每天都会创造出海量数据 ,而我们的任务,就是在这片混杂着泥沙的洪流中,精准地找到那几粒闪着智慧光芒的金子。这不仅仅是一个比喻,更是一个被数据量化的严峻现实。
量化之痛:信息过载的隐性税收
根据哥伦比亚商学院的研究,一位普通的知识工作者,每天需要处理的信息量,相当于174份报纸 。这个惊人的数字背后,是我们每个人都在默默承受的"认知税收"。这种无形的税收,正在以惊人的方式侵蚀着我们的生产力、健康和创造力。
时间成本: 研究显示,员工平均每天花费近3小时------也就是将近30%的工作时间------仅仅是为了寻找他们完成本职工作所需的信息。
经济成本: 这种普遍的低效,正转化为巨大的经济损失。仅在美国,信息过载每年导致的生产力损失就高达9000亿美元。
个人成本: 这不仅仅是关于时间和金钱。超过65%的员工表示信息过载对他们的工作产生了负面影响。它导致了与压力相关的健康问题、创造力下降、工作关系紧张,甚至在一项研究中,频繁的信息干扰被发现会导致智商平均下降10个点。
诊断病根:我们手中工具的根本性缺陷
问题的根源,并不仅仅在于信息量的爆炸,更在于我们赖以生存的核心工具---传统搜索引擎---已经无法胜任新时代的需求。
传统搜索引擎,本质上是一个"信息检索者 ",而非"知识合成者"。它的设计初衷是基于关键词匹配,返回一个按某种规则排序的网页列表。它把寻找、筛选、阅读、辨别真伪、连接不同来源的观点、并最终形成结论这一系列最耗费心力的工作,全部留给了用户。这个过程不仅效率低下,还充满了陷阱,比如为了博取流量而进行SEO优化的内容,往往会排在真正有价值的信息之前,让我们在浩瀚的链接中迷失方向。
我们正面临一个根本性的错配:我们试图用20世纪的信息检索工具,去应对21世纪的信息合成挑战。这种错配产生的"合成鸿沟",正是导致我们效率低下、认知疲劳的根本原因。我们花费大量时间手动填补这个鸿沟,付出的正是宝贵的认知资源。
引入解决方案:智能"淘金机器"
如果说传统的手动筛选就像用一个淘金盘在湍急的河水中筛选,那么我们现在需要的,是一台全自动、智能化的"淘金机器"。这台机器不仅能自动从洪流中分离出泥沙,更能直接将高纯度的黄金提炼出来,送到你的面前。
这台机器,就是我们今天将要深入探讨的核心技术------ "Deep Research" 。它被设计用来解决信息时代的根本痛点,将研究工作从"寻找线索"的苦役,转变为"审阅结论"的决策。

揭开面纱------"淘金机器"到底是什么?
"Deep Research"代表着一种根本性的范式转移。它的核心定义非常清晰:从一个给你"链接"的工具,进化为一个给你"答案"的智能助理。它交付的不再是零散的线索,而是经过深度处理、结构化、且有据可查的结论。
它并非简单地找到信息源,而是真正地去阅读、理解、分析并综合这些信息源。 这种能力的飞跃,源于其与传统搜索引擎在底层逻辑上的根本不同。
对比分析:旧工具 vs. 新范式
**
**
为了更直观地理解这种变革,我们可以通过一个简单的表格来对比两者:
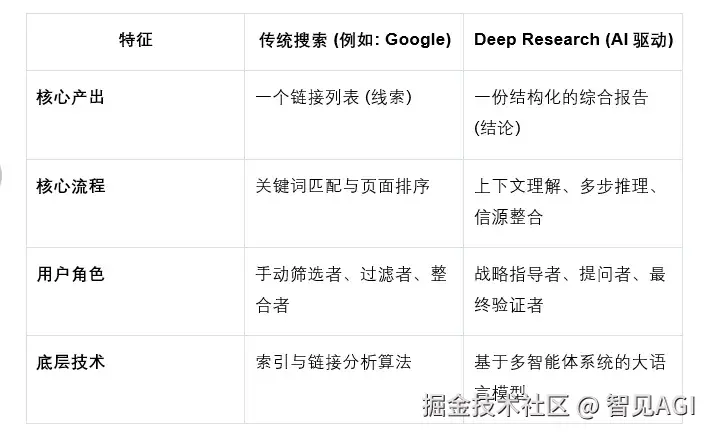
这个表格清晰地揭示了价值核心的转移:Deep Research将信息处理的负担从人类身上转移到了机器上。 传统搜索交付的是无序的混乱,而Deep Research交付的是有序的知识。人类大脑处理结构化信息的效率远高于处理非结构化信息,因此,效率的提升不仅来自于节省搜索时间,更来自于节省了将混乱信息结构化所需的巨大认知负荷。
解构能力:Deep Research的五大支柱
**
**
这种强大的能力,建立在几个关键的技术特性之上:
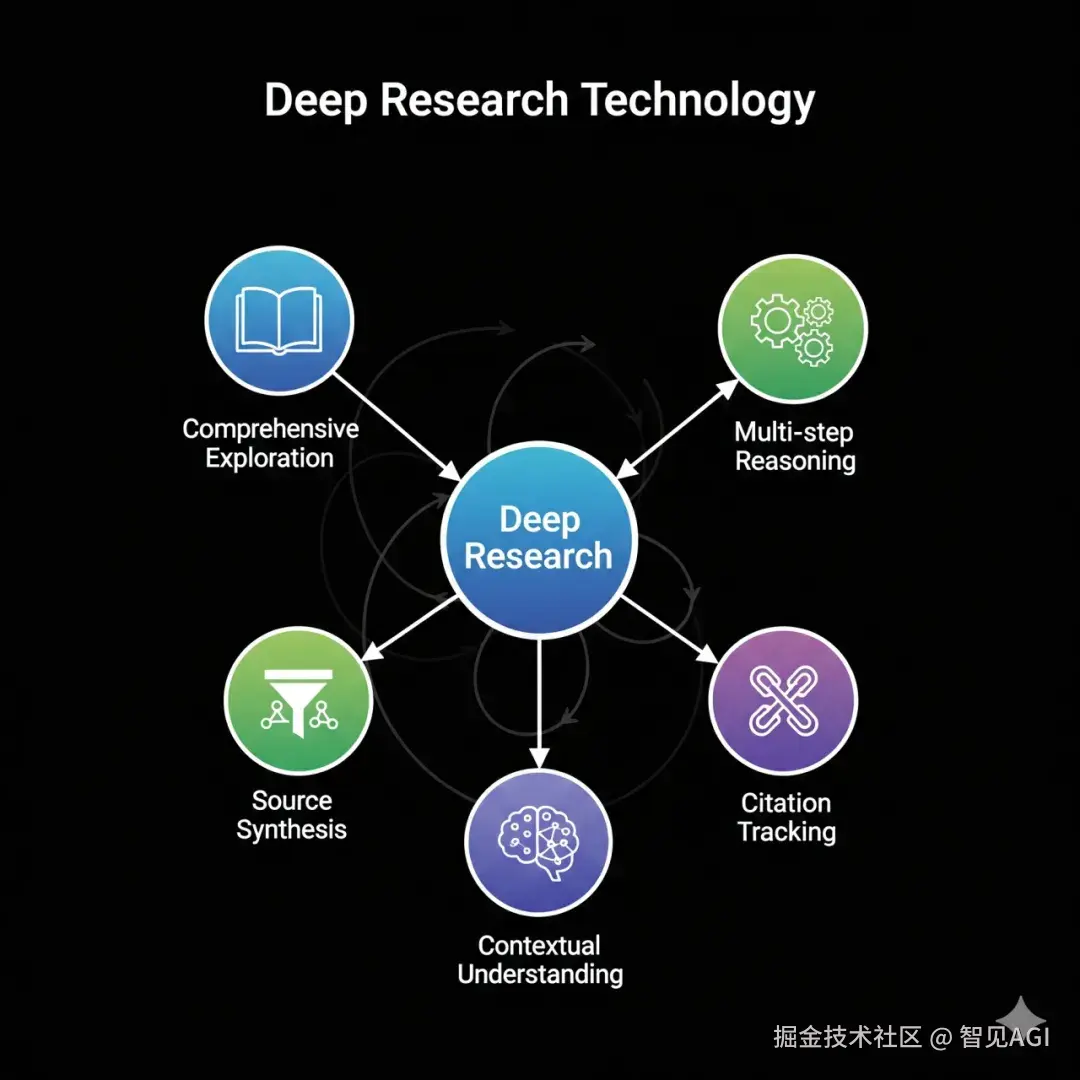
全面探索 (Comprehensive Exploration): 它会完整阅读文章、报告和网页,而不是像传统搜索引擎那样只抓取摘要或片段,从而确保信息的完整性。
多步推理 (Multi-step Reasoning): 它能将一个复杂的研究问题,拆解成一系列逻辑清晰的子任务,并按顺序执行,模拟人类专家的研究思路。
信源整合 (Source Synthesis): 它能智能地结合来自多个、甚至观点相左的信息源,去伪存真,形成一个更全面、更平衡的图景。
上下文理解 (Contextual Understanding): 在整个研究过程中,它始终保持对原始问题的认知,确保所有收集和分析的信息都与核心目标高度相关,不会偏离主题。
引用追踪 (Citation Tracking): 与普通AI聊天生成的"黑箱"答案不同,Deep Research为其报告中的每一个关键论点提供清晰、可验证的来源引用,这不仅建立了信任,也允许用户在需要时进行更深入的核查。
这项技术标志着我们与信息交互方式的根本性变革。我们正在从一个"拉取"模式(我们手动从网络上拉取一个个独立的文档),转向一个"委托"模式(我们向一个AI代理"委托"一份综合研究报告)。 "搜索框"正在被"研究任务简报"所取代,这将深刻地改变知识工作的流程、项目管理的方式,乃至对从业者技能的要求。
"淘金机器"的动力核心:多智能体系统从提示词到上下文的思维跃迁
讲解完"Deep Research"的理念后,一个自然而然的问题是:这种强大的能力在技术上是如何实现的呢?答案已经从依赖"一个无所不能的超级大脑",进化到了构建一个"各司其职的AI专家团队"------也就是多智能体系统 (Multi-Agent Systems, MAS)。
**
**
从"一个大脑"到"团队协作"
早期的AI尝试使用一个单一、庞大的模型来处理所有任务。然而,这种"独行侠"模式在面对复杂、长链条的真实世界问题时,常常会暴露出缺陷,比如容易忘记最初的指令、在多步骤中逻辑混乱或偏离主题。
真正的技术突破,是转向了多智能体协作的架构。这个架构的核心思想是"分而治之",就像组建一个高效的人类项目团队。它将一个庞大的任务分解,分配给多个拥有特定技能的AI智能体,它们各自负责一部分,并通过协作共同完成最终目标。 这种模式通过任务分解、专业化和并行处理,极大地提升了系统的鲁棒性、效率和解决复杂问题的能力。
技术范例:拆解"天工"智能体(Skywork Agent)框架
为了让大家更直观地理解,我们不妨以近期由昆仑万维发布的知名开源框架"天工"为例,看看一个现代化的智能体框架是如何像一个精英研究团队一样运作的。
这个"AI研究团队"主要由三个核心角色构成:
1.决策者 (Planner) - "项目经理"
**
**
角色定位: Planner是团队的大脑和指挥官。当它接收到用户下达的复杂研究任务(比如"分析新能源汽车市场的竞争格局与未来趋势")时,它的首要职责不是立即执行,而是进行深度思考和规划。它会将这个宏大的目标,拆解成一份详尽、有序、可执行的行动计划,明确需要完成哪些子任务,以及它们的先后顺序。
"天工"实践: 这个角色在"天工"的设计中得到了完美的体现。其首创的**"澄清卡 (Clarification Card)"**功能,正是一个优秀的"项目经理"在项目启动前的标准动作。在开始工作前,它会主动向用户提问,确认研究的目标、背景和具体要求,形成一份"待办清单"让用户确认。这一步确保了后续所有工作都精准地对齐用户的真实意图,从源头上避免了方向性错误。
2.执行者 (Executor) - 多个"初级研究员"
**
**
角色定位: Executors是团队中负责具体执行的"研究员"。它们从"项目经理"那里领取被拆分好的具体子任务。每个Executor都可能拥有不同的"专业技能"。例如,研究员A可能擅长从上市公司的财报中提取财务数据,研究员B精通社交媒体的情感分析,而研究员C则专注于检索和解读政府的政策文件。它们可以并行工作,极大地缩短了信息收集和初步处理的时间。
"天工"实践: "天工"的架构中,"5大专家智能体"(分别专精于文档、PPT、表格、播客和网页的生成)和连接了众多工具的"通用智能体",就扮演了这些专业化的"研究员"角色。当需要生成一份包含数据分析的PPT报告时,"项目经理"会将数据分析任务分配给"表格智能体",将内容撰写任务分配给"文档智能体",最后由"PPT智能体"将所有成果整合成最终的演示文稿。
3.反思者 (Reflector) - "资深分析师"或"质检员"
**
**
角色定位: 这可能是整个团队中确保最终成果质量最关键的一环。Reflector不直接参与一线的研究工作,它的核心职责是审查和验证。它会检查每一位"研究员"提交的工作成果,评估其信息的准确性、逻辑的连贯性以及与原始计划的匹配度。如果发现问题、矛盾或不足之处,它会提出修改建议,将任务"打回"给相应的Executor进行返工或优化。这个持续的"审查-反馈-修正"循环,是保证最终报告深度和准确性的关键。
"天工"实践: Reflector的理念,在"天工"的**"可追溯 (Tracing)"**功能中得到了体现。系统之所以能确保生成内容中的每一个事实和数据都有清晰的来源,正是因为在其内部流程中,有一个类似Reflector的机制在不断地进行验证和核对,确保结论与原始证据链的强关联。
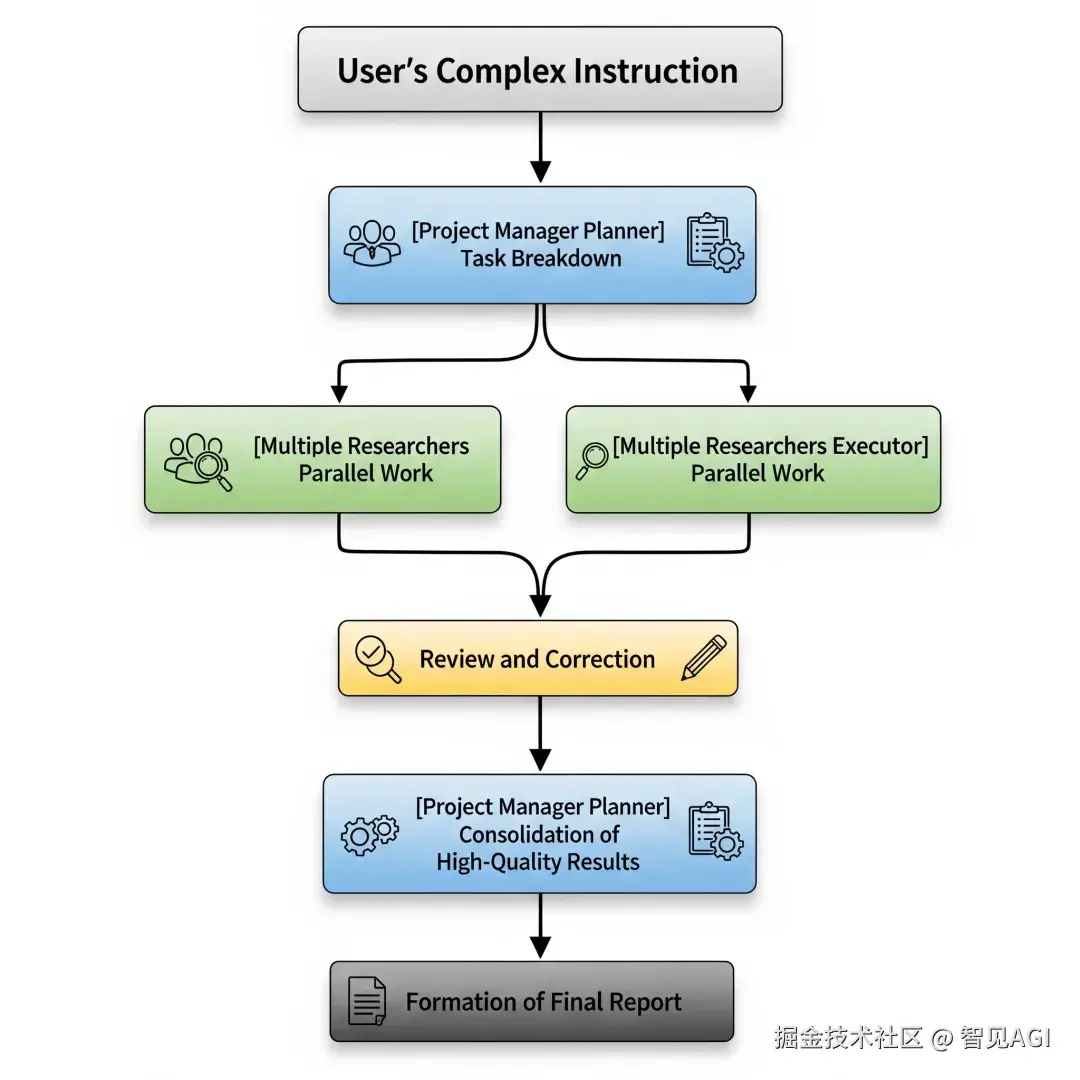
工作流程解析
**
**
整个团队的协作流程可以简化为下图:
为什么这种框架是关键?
**
**
这种多智能体协作的模式,完美地模拟并优化了人类专家团队解决复杂问题的最佳实践。它通过分工(专业化)、协作(并行化)和反思验证(质量控制),实现了1+1>2的效果,从根本上解决了单个大模型在处理复杂任务时容易"想不周全"、"干着干着就忘了"或者"一本正经地胡说八道"的核心难题。
可以说,Planner-Executor-Reflector这种架构,不仅仅是一种技术实现,它更是一种将人类严谨的研究方法论(提出假设、分工执行、同行评审)代码化的哲学。正是这种哲学,构成了实现真正"深度研究"的坚实基石,也是AI从一个创意工具,迈向一个可信赖的专业工具的关键一步。
实战演练------看"淘金机器"如何大显神通?
理解了这台"淘金机器"的内部构造,现在让我们把它放到真实的商业战场中,看看它如何掀起一场效率革命。
金融分析师: 将过去需要数天完成的季度竞争对手分析报告,压缩到几十分钟。AI智能体自动抓取财报、分析舆情、总结会议要点并生成报告,使分析师从"数据搬运工"转变为高阶的"战略决策者"。
医学研究员: 将以往耗时数月乃至数年的文献综述与药物筛选过程,缩短至几小时。AI能够"阅读"海量论文,发现人类难以察觉的复杂关联,从而极大地加速科学发现,甚至让过去因人力限制而无法进行的全局性分析成为可能。
市场战略师: 将过去需要团队数周完成的竞品分析,变为一个快速、自动化的过程。AI能够系统性地整合市场动态、用户痛点和竞品策略,为团队提供全面、及时的情报,实现真正的数据驱动决策。
这些场景揭示了一个深刻的转变:Deep Research不仅是让现有任务变得更快,更是让过去因为时间、成本和认知带宽限制而不可能完成的任务成为可能。一名分析师永远无法在一个周末手动读完一万篇研究论文,但AI可以。这从根本上改变了我们能够提出的问题的范围和深度,推动我们从基于"样本"的洞察,迈向基于"普查"的智慧。
**
**
理性思考------"淘金机器"并非没有瑕疵
尽管Deep Research技术带来了革命性的潜力,但它并非完美无瑕的魔法。一个聪明的"淘金者",必须清醒地认识到自己手中工具的局限性和潜在风险。
挑战一:AI幻觉
大语言模型最广为人知的缺陷之一是"幻觉"现象,即AI可能会生成一些看似流畅自信、格式完美,但内容却完全错误或凭空捏造的回答。这背后的根源在于,大语言模型的本质是概率性的"文字接龙"大师,而非事实数据库,它通过计算来预测下一个最有可能出现的词语以追求语言上的通顺,有时这会导致它"杜撰"出违背事实的细节。
这种风险在严肃场景下尤为突出,一个著名的真实案例是,美国有律师因使用AI撰写法律文件并引用了其捏造的虚假案例而遭到法庭处罚。这生动地警示我们,人类的最终审核与批判性思维是不可或缺的最后防线,同时,优先选择那些内置了信源追溯和验证功能的工具,也能有效降低此类风险。
**
**
挑战二:算法偏见
AI模型的能力建立在海量的互联网数据之上,然而,这些数据本身就像一面镜子,反映了人类社会现有的偏见,如性别、种族和地域歧视。AI在学习这些数据的过程中,也不可避免地学习并可能放大了这些偏见。这本质上是"垃圾进,垃圾出"的问题:当训练数据本身存在偏见时,AI的输出结果也必然会带有偏见。
因此,作为使用者,我们需对AI的输出,尤其是在涉及人的决策时,保持高度警惕。同时,对于开发者而言,使用更多元化、更具代表性的数据集进行训练,并进行严格的偏见检测与修正,是其不可推卸的责任。
挑战三:认知惰化
**
**
一个更深层次的、关于人机关系的哲学思辨是:当我们越来越依赖这些强大到可以为我们完成思考、研究和总结的工具时,我们自己的核心认知能力是否会因此退化?
对此,存在两种截然不同的观点。一种是"用进废退"的风险论,认为就像过度依赖计算器会降低心算能力一样,若将所有研究和分析工作都外包给AI,我们自身的批判性思维、信息甄别和深度思考等"认知肌肉"可能会逐渐萎缩。另一种是"认知增强"论,认为通过将繁琐、重复的低层次认知任务自动化,AI能解放我们的心智资源,让我们专注于更高层次的创造性、战略性思考,成为我们"延伸的大脑"。最终的结果并非由技术本身决定,而是取决于我们如何选择使用这项技术。
**
**
拥抱新工具,成为聪明的"淘金者"
我们正处在一个信息处理范式发生巨变的黎明。Deep Research技术,作为驾驭信息海洋的强大工具,无疑是我们这个时代知识工作者最值得关注和掌握的"生产力核武器"。它能够放大我们的智慧,为我们节省下数以千计的宝贵小时,并解锁那些在过去仅凭人力无法触及的深度洞察。
然而,我们必须清晰地认识到,这项技术的终极目标不是取代人类的智慧,而是增强它。AI处理的是"是什么"(What)------进行数据收集和综合。而我们,则需要将更多的精力投入到"所以呢"(So What)------洞察其战略意义,以及"下一步呢"(Now What)------做出可行的决策。
一个聪明的"淘金者",不仅仅是拥有一台最先进的机器。他更懂得如何给机器设定正确的航向,如何维护和校准它,以及最关键的------如何解读它提炼出的黄金,并据此做出最明智的投资。
🗣️互动话题:
在你的工作领域,你最希望用"Deep Research"AI解决的第一个复杂研究难题是什么?欢迎在评论区分享你的想法!