嘿,我想和大家分享一些有趣的事情。我用 Claude Code 来处理编程任务,但最近我想尝试用它来整理我的笔记------这是我一直在努力解决的问题。
Claude Code 为我做了这些事:
- 研究了笔记组织的最佳实践
- 建议了最适合我的结构的高效方法
- 为我所有笔记添加标签,创建模板,用两种语言添加缺失标签,甚至构建了 MOCs(内容地图)
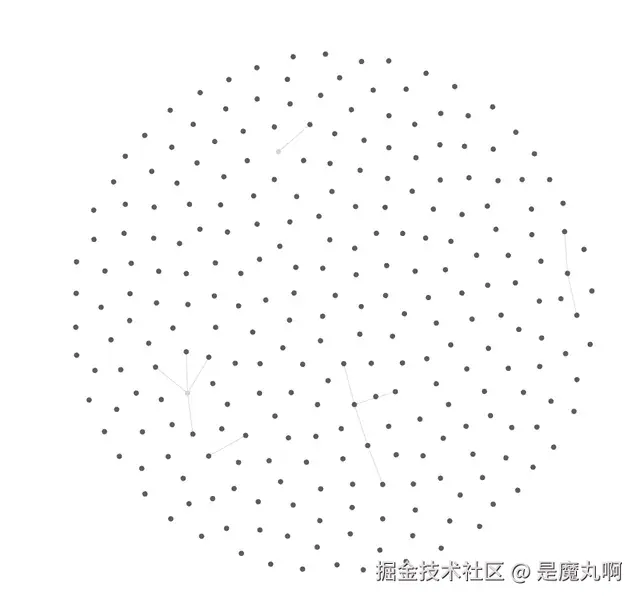
使用 Claude Code 之前
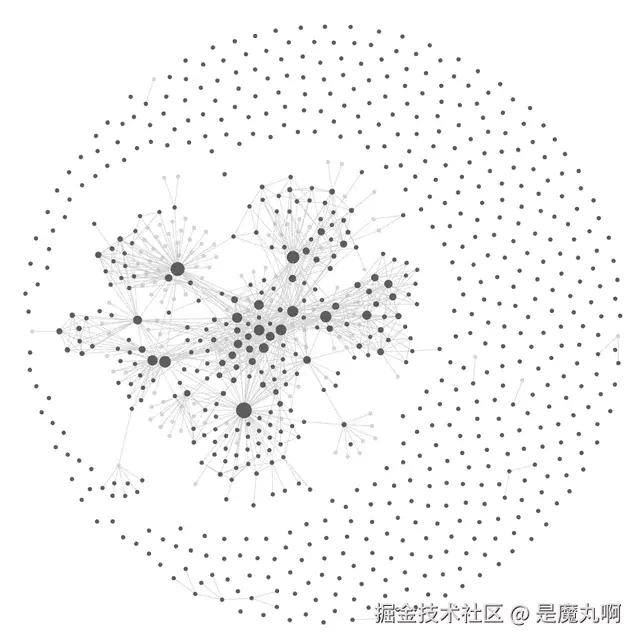
使用 Claude Code 之后
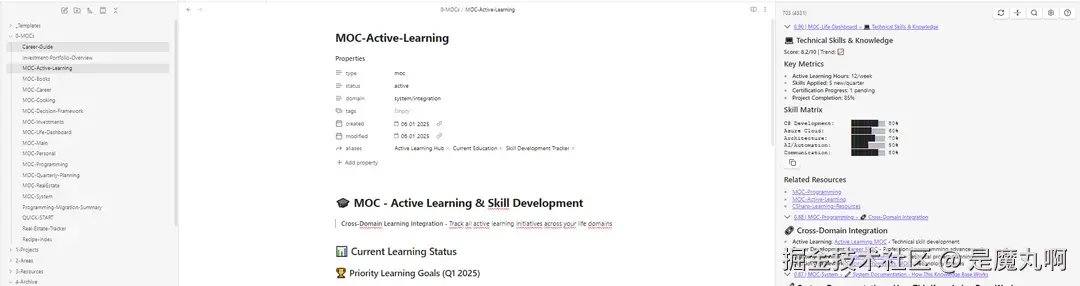
迁移完成
我使用的启动prompt
markdown
## 指令
您将分析提供的知识库结构和笔记,以创建改进的组织系统。请遵循以下步骤:
### 第1阶段:分析
首先,在 `<analysis>` 标签内检查当前结构:
**当前组织评估**
- 识别组织方法(文件夹、标签、链接或组合)
- 注意命名约定中的任何模式
- 评估文件夹层次结构的深度
- 识别潜在的信息孤岛或重复内容
- 检查孤立笔记或断开的连接
**内容类型分类**
- 对存在的笔记类型进行分类(参考、项目、个人等)
- 识别反复出现的主题或话题
- 注意笔记的平均长度和复杂性
- 确定笔记遵循原子原则还是包含多个概念
**使用模式识别**
- 识别笔记如何相互连接
- 评估当前的链接策略
- 确定主要使用场景(研究、项目、学习等)
### 第2阶段:建议
基于您的分析,在 `<recommendations>` 标签内提供详细建议:
**组织结构**
- 选择最合适的主要方法:
- **带有 MOCs 的扁平结构**(内容地图)以获得最大灵活性
- **PARA 方法**(项目、区域、资源、档案)用于面向行动的系统
- **混合方法**结合最少的文件夹和广泛的链接
- 根据用户的内容和模式证明您的选择合理性
2. **笔记架构**
- 推荐笔记类型:
- **原子笔记**用于单个概念
- **MOC 笔记**用于主题组织
- **索引笔记**用于导航
- **每日笔记**用于捕捉稍纵即逝的想法
- 为每个推荐的笔记类型提供模板
3. **元数据和标签系统**
- 使用嵌套标签(例如,#type/article, #status/draft)设计分层标签结构
- 推荐 YAML 前置属性以增强组织
- 建议标签类别:内容类型、状态、主题、来源
4. **链接策略**
- 建立链接约定
- 建议何时使用链接 vs 标签
- 建议 MOC 创建触发器(例如,当主题有 5+ 相关笔记时)
5. **搜索和检索优化**
- 推荐更好的搜索命名约定
- 建议用于动态组织的 Dataview 查询
- 提供高效检索的搜索操作符
### 第3阶段:实施计划
在 `<implementation>` 标签内提供逐步迁移计划:
**准备阶段**(第1周)
- 备份当前库
- 安装推荐插件
- 创建文件夹结构和初始 MOCs
**迁移阶段**(第2-3周)
- 确定迁移笔记的优先级
- 更新笔记格式并添加元数据
- 创建连接和 MOCs
**优化阶段**(第4周)
- 审查和完善系统
- 创建供将来参考的文档
- 建立维护例程
### 第4阶段:实用示例
在 `<examples>` 标签内提供:
**整理前后的**笔记组织示例
**示例 MOC 结构**与 Dataview 查询
**模板示例**用于不同笔记类型
**示例标签层次结构**特定于其内容
### 要应用的重要原则:
- **面向未来的设计**:创建一个随增长扩展的系统
- **低摩擦捕获**:确保快速笔记创建而无需复杂分类
- **渐进式组织**:从简单开始,根据需要增加复杂性
- **交叉引用**:最大化相关概念之间的连接
- **定期维护**:包括定期审查流程
记住:
- 优先考虑可发现性而非完美分类
- 为用户的"最糟糕的日子"设计,当他们疲惫或匆忙时
- 平衡结构与灵活性
- 结合显式(文件夹/标签)和隐式(链接)组织
- 考虑现代工具中AI辅助的搜索能力
您的最终输出应该是实用的、可操作的,并根据在用户当前系统中识别的特定内容和使用模式量身定制。一些回帖反馈
- 备份至关重要:在尝试 AI 整理前要完整备份
- 版本控制:建议使用 Git 管理文本文件,配合 DVC 处理图片等资源
- cc自动化工作流:使用 Claude Desktop 和 mcp-obsidian 插件,在保存库的目录中打开 Claude Code 终端。创建了多个自定义斜杠命令,定期运行;每天用 Claude Code 总结任务和未完成事项。