Claude SKILL ------ 制定特定的工作流,使得AI + 可复用技能(Claude SKILL)完成提词目标。 Claude Code SKILL 官方文档:code.claude.com/docs/en/ski...
从「看文档学 Jetpack」到「围绕真实项目 + 招聘要求的系统化学习」
一、制定 SKILL 目标
作为一名Flutter 经验老鸟,但 Android 原生体系偏弱的开发者,在补充 Android Jetpack 能力时遇到了一个老生常谈的问题:
知识点零散、学习路径割裂、学完不知道"够不够面试"
传统学习方式通常是:
- 看官方文档
- 跟着博客写 Demo
- 记住几个关键词(ViewModel、LiveData、Room...)
但一到真实项目或面试,很容易暴露问题:
- 不清楚 模块在真实的设计思路
- 不知道 一个技术点在面试中的延展深度
- 学完就忘,没有持续演进能力
这也是我尝试 Claude Skill 工作流 的直接动机:
👉 尝试把「项目结构 + 学习路径 + 面试要求」统一成一套可复用的 AI 学习工具
二、从真实工程出发
我选择了一个典型的 Jetpack + MVVM 架构项目,先不学任何技术细节,只做一件事:
梳理项目骨架,制定模块分析工作流
项目整体骨架分析
通过提词生成项目骨架图生成如下
bash
├── app/
│ ├── src/main/java/com/yechaoa/wanandroid_jetpack/
│ │ ├── base/ # MVVM 基类封装
│ │ ├── common/ # 全局配置常量
│ │ ├── data/ # 数据层(网络、数据库、实体)
│ │ ├── ui/ # 界面层(功能模块)
│ │ └── util/ # 工具方法
│ ├── src/main/res/ # 资源文件
│ ├── src/test/ # 单元测试
│ └── src/androidTest/ # 仪器测试
├── build.gradle.kts
├── app/build.gradle.kts
├── buildSrc/
└── gradle/用「人类语言」生成文档
在 Skill 的第一步,我并不让 AI 直接分析代码,而是先输出一份:
- 📄 项目整体介绍文档
- 📌 模块职责说明
- 🔗 模块之间的关联关系
- 🧭 推荐学习顺序(为什么先学这个)
这一步的价值在于:
先建立工程认知并人为纠正,再进入技术细节
三、学习顺序设计 ------ "项目驱动"
基于项目结构,我制定了一个符合三年 Android 社招预期的学习顺序:
-
构建系统与模块结构
- Gradle / buildSrc
- 模块拆分思路
-
MVVM Base 层
- BaseActivity / BaseViewModel
- ViewModel 生命周期
-
UI 模块
- Fragment 管理
- Navigation / 状态恢复
-
数据链路
- Retrofit / Room
- Repository 设计
-
功能模块拆分
- 首页 / 业务模块如何解耦
-
测试与质量
- 单元测试
- UI 测试与稳定性
👉 每一步都能映射到真实代码位置 + 面试问题
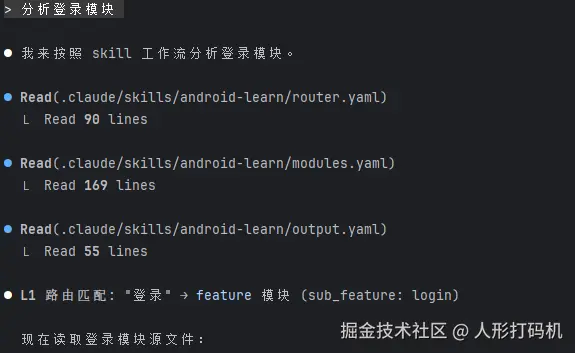
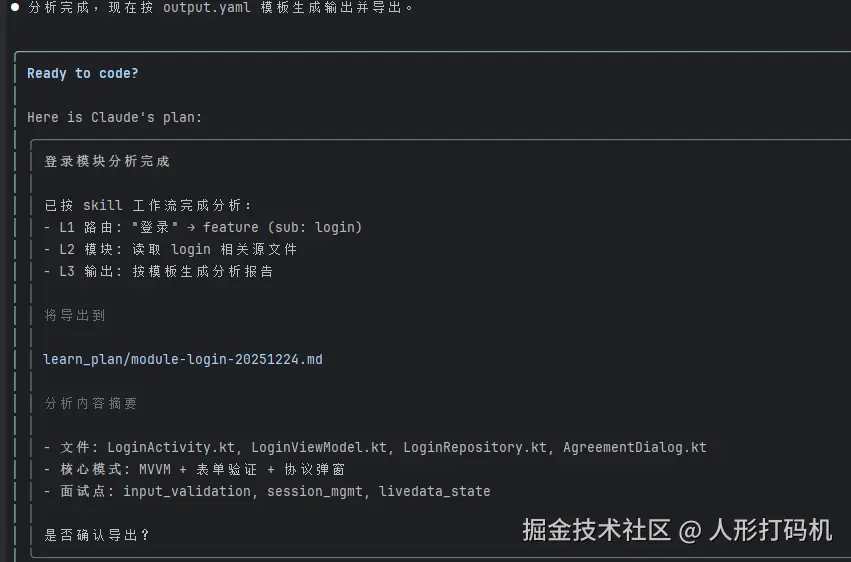
四、Skill 工作流设计
在完成骨架与学习计划后,我开始设计 Claude Skill 的工作包结构。
调优过程略过,主要是围绕项目及 Skill 特性进行垂直展开,最终 Skill 工作包内容如下
bash
.claude/skills/android-learn/
├── SKILL.md # 入口 (37行) - 触发词 + 一级路由 + 执行流程
├── router.yaml # L1 完整关键词路由表
├── modules.yaml # L2 模块路径与分析点
└── output.yaml # L3 输出模板与导出规则设计思路
lua
用户输入: "分析登录模块"
↓
L1 router.yaml: 匹配关键词 "登录" → module_id: "feature"
↓
L2 modules.yaml: 获取 feature 配置 → paths + analyze + interview
↓
L3 output.yaml: 填充模板 → 生成报告
↓
导出: learn_plan/module-feature-20251224.md
Token 节省
| 项目 | 优化前 | 优化后 | 节省 |
|---------|-------|------|------|
| 配置文件数 | 10 | 4 | 60% |
| 总 token | ~3000 | ~500 | 83% |
| 自然语言 | 大量 | 极少 | 90%+ |尽可能达成一个 Module = 一次完整的「学习 + 面试发散」闭环
五、SKILL.md 实现
在 Skill 首版中,我刻意做了一个选择:
Rule 使用自然语言完成,而不是机器语言
原因很简单:
- 我要 能读、能改、能演进
- 规则本身也是学习路径的一部分
SKILL.md 的职责是:
- 模块路由规则(如何进入某个 module)
- 每次分析的输出目标
- 与招聘要求的联动方式
总结
结合实际使用,我认为这套 Skill 工作流有三个明显特点:
1️⃣ 项目优先,而不是技术点优先
不再是"学 ViewModel",而是:
"在这个项目里,ViewModel 是怎么被设计和约束的?"
2️⃣ 学习路径天然对齐面试
通过招聘信息检索 + 模块映射:
- 知道 学到什么程度够用
- 知道 哪些是加分项
3️⃣ 可持续演进,而不是一次性 Prompt
- 项目变 → Skill 跟着变
- 目标变(学习 / 面试)→ Rule 可调整
使用方式
bash
/analyze login # 分析登录模块
/analyze 网络 # 分析数据层
/analyze mvvm # 分析 MVVM 基类
/analyze 首页 # 分析主页导航
或自然语言:分析登录模块、学习网络层