
好的,这是一道来自2022年最新的操作系统文件系统综合题。它以一个具体的目录树和i-node结构为例,全面考察了目录结构、硬链接、文件读取流程以及多级索引的寻址范围计算。
我们来详细地解析这道题。
题目原文
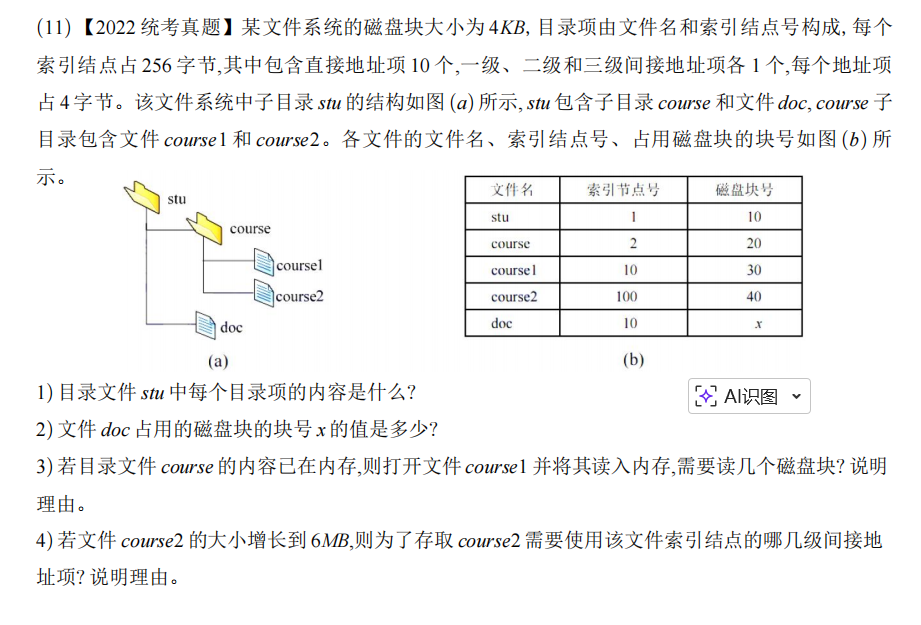
(11)【2022统考真题】某文件系统的磁盘块大小为 4KB, 目录项由文件名和索引结点号构成, 每个索引结点占 256 字节,其中包含直接地址项 10 个,一级、二级和三级间接地址项各 1 个,每个地址项占 4 字节。该文件系统中子目录stu的结构如图 (a) 所示,stu包含子目录course和文件doc, course子目录包含文件course1和course2。各文件的文件名、索引结点号、占用磁盘块的块号如图 (b) 所示。
(注:由于无法直接嵌入图片,此处为图片占位符,请参照您提供的原图)
- 目录文件
stu中每个目录项的内容是什么? - 文件
doc占用的磁盘块的块号 x 的值是多少? - 若目录文件
course的内容已在内存,则打开文件course1并将其读入内存,需要读几个磁盘块? 说明理由。 - 若文件
course2的大小增长到 6MB,则为了存取course2需要使用该文件索引结点的哪几级间接地址项? 说明理由。
一、运用了什么知识点?考了什么?为什么这么考?
-
运用知识点:
- 文件目录 : 理解目录本身是文件,其内容是
<文件名, i-node号>的列表。 - 索引节点 (i-node): 文件系统中描述文件属性和数据块位置的核心数据结构。
- 硬链接 (Hard Link) : 多个不同的文件名(目录项)指向同一个i-node。这意味着它们实际上是同一个文件的不同别名。
- 文件打开与读取流程: 理解操作系统打开一个文件并读取其内容需要经过的磁盘访问步骤:读取目录 -> 读取i-node -> 读取数据块。
- 多级索引的寻址范围: 能够精确计算i-node中直接地址、一级间接、二级间接地址各自能表示的文件大小范围。
- 文件目录 : 理解目录本身是文件,其内容是
-
考了什么?
这道题将文件系统的静态结构和动态访问过程结合起来考察:
- 静态结构还原 (Q1): 能否根据目录树和文件信息,正确地构建出目录文件的内容。
- 核心概念理解 (Q2) : 通过一个巧妙的设计(
doc和course1共享i-node),考察考生是否理解"硬链接"的本质。 - 动态过程模拟 (Q3): 考察考生能否模拟一次完整的文件读取流程,并准确计算出磁盘I/O的次数。
- 设计极限计算 (Q4): 考察考生能否根据文件大小,判断出它需要用到哪一级别的间接索引,这是对多级索引寻址能力计算的直接应用。
-
为什么这么考?
因为这道题非常贴近真实文件系统的工作原理。它通过具体的文件名和i-node号,让考生不再停留在抽象的概念上,而是去解决实际的"寻址"问题。特别是Q2的硬链接和Q3的文件读取流程,都是操作系统课程中的重点和难点,能够很好地检验考生的综合分析能力。
三、解题思路与详细分析 (怎么样?)
问题1分析:构建stu目录文件
- 思路 : 目录文件
stu的内容,就是它下面包含的所有文件/子目录的"<文件名, i-node号>"列表。 - 分析 :
- 从图(a)的目录树可知,
stu目录下有两项:子目录course和文件doc。 - 从图(b)的表格中,我们可以查到这两项对应的i-node号。
course-> 索引节点号 2doc-> 索引节点号 10
- 从图(a)的目录树可知,
- 结论 : 目录文件
stu的内容如下表所示:
| 文件名 | 索引结点号 |
| :--- | :--- |
| course | 2 |
| doc | 10 |
问题2分析:硬链接的本质
- 思路 : 我们需要找到文件
doc的数据块位置。i-node是连接文件名和数据块的桥梁。 - 关键发现 :
- 从图(b)的表格中,我们发现文件
doc和文件course1的索引结点号都是10。 - 核心概念 : 在Unix-like文件系统中,多个目录项指向同一个i-node,这就是硬链接 。这意味着
doc和course1实际上是同一个文件的两个不同名字。它们共享同一个i-node,因此也共享同一份物理数据。
- 从图(b)的表格中,我们发现文件
- 查找数据 :
- 既然它们是同一个文件,那么
doc占用的磁盘块就和course1占用的磁盘块是完全一样的。 - 从图(b)表格中查到,
course1占用的磁盘块号是30。
- 既然它们是同一个文件,那么
- 结论 : 文件
doc占用的磁盘块的块号 x 的值是 30。
问题3分析:文件读取流程
- 目标 : 打开并读取
course1。 - 初始状态 : 目录文件
course的内容已在内存。 - 模拟步骤 :
- 查找i-node号 : 由于
course目录已在内存,操作系统可以直接在内存中查找course1的目录项,得到其索引结点号为10 。(此步无需访问磁盘) - 读取i-node : i-node 10的内容不在内存中。i-node本身也存放在磁盘上。因此,操作系统需要第一次磁盘访问 ,去读取i-node 10所在的磁盘块。
- 获取数据块地址 : 从读入内存的i-node 10中,解析出文件
course1的数据块地址。从图(b)可知,这个地址是块号30。 - 读取数据块 : 文件的数据(
course1的内容)在磁盘的30号块中。操作系统需要进行第二次磁盘访问 ,去读取磁盘块30的内容。
- 查找i-node号 : 由于
- 结论 : 需要读 2 个磁盘块。理由是:首先需要读取
course1的索引结点(i-node 10)所在的磁盘块 ,以获取文件的地址信息;然后根据i-node中的地址信息,再去读取存放文件内容的数据块(磁盘块30)。
问题4分析:多级索引的寻址范围
- 目标: 判断一个6MB的文件需要用到哪几级间接地址。
- 思路: 我们需要计算每一级索引所能支持的最大文件大小,然后看6MB落在了哪个区间。
第一步:计算一个索引块能存放多少地址
- 磁盘块大小 = 4KB = 4096 B
- 地址项大小 = 4 B
每个索引块的地址项数 = 4096 / 4 = 1024项。
第二步:计算各级索引的寻址能力
- 直接地址 (10个) :
- 能索引
10个数据块。 - 覆盖文件大小:
10 × 4KB = 40 KB。
- 能索引
- 一级间接地址 (1个) :
- 指向1个一级索引块,该块能索引
1024个数据块。 - 覆盖文件大小:
1024 × 4KB = 4 MB。 - 累计覆盖 : 加上直接地址,可表示
40KB + 4MB大小的文件。
- 指向1个一级索引块,该块能索引
- 二级间接地址 (1个) :
- 指向1个二级索引块,该块指向
1024个一级索引块。 - 能索引
1024 × 1024 = 2²⁰个数据块。 - 覆盖文件大小:
2²⁰ × 4KB = 1M × 4KB = 4 GB。
- 指向1个二级索引块,该块指向
第三步:定位6MB文件
- 文件大小 = 6MB。
- 比较 :
6MB > 40KB(仅直接地址不够)。6MB > 40KB + 4MB(直接地址 + 一级间接地址也不够)。- 因为
4MB + 40KB = 4.039 MB(约等于)。6MB已经超出了这个范围。
- 结论 : 文件的末尾部分数据必须通过二级间接地址项来索引。
- 完整理由 :
- 10个直接地址项最多能表示
10 * 4KB = 40KB的文件。 - 1个一级间接地址项最多能额外表示
(4KB/4B) * 4KB = 1024 * 4KB = 4MB的文件。 - 两者相加,总共能表示
4MB + 40KB的文件。 - 因为文件大小
6MB大于4MB + 40KB,所以仅靠直接地址和一级间接地址不足以存下整个文件。 - 因此,必须使用二级间接地址项 来索引超出
4MB + 40KB的那部分数据。 - 所以,存取整个6MB的文件,需要用到直接地址项、一级间接地址项和二级间接地址项 。但题目问的是哪几级"间接" ,所以是一级和二级间接地址项。
- 10个直接地址项最多能表示