为什么"原生全模态"必须被严肃对待?
过去两年,大模型领域,我们见到无数号称"多模态"的模型,但绝大多数都停留在"能力堆叠",而不是真正的"感知一致"。
通常的处理方式就是图像模型输出 embedding → 文本模型继续推理,本质上就是给 LLM 接了外设,信息流经过两轮投影,多半在过程中蒸发掉了 30%--50%。
因此你会看到行业里常见的问题:视觉描述像隔着一层薄雾,或者视频理解只有事件,没有动机;甚至图文结合时容易"跳戏"、情绪识别偏浅层,多模态推理断链。
换句话说,国产大模型一直缺少一个真正统一的"感知"大模型。 而就在昨天(11月13日)百度在2025百度世界大会,正式对外发布文心新一代模型------文心5.0,这件事有了新的转机!

文心这次再把"多模态"这件事又拉到了前台,我似乎看到了:文心 5.0 正把"原生统一建模"做成生产级能力的系统。 这,应该就是国产大模型的技术分水岭。

技术路线先于发布会:为什么文心 5.0 的选型会改变行业节奏?
文心 5.0 与行业主流最大的差异只有一句话:它从训练伊始就让语言、图像、视频、音频共存于同一架构。 这件事极难!
文本、图像、视频、音频被转换成统一 token,将所有模态放进同一个语言空间中进行推理。这意味着:视觉信息的"压缩 → 反投影"链条被取消、跨模态的因果关系能自然流动,并且生成端与理解端用的是同一套参数体系,叙事一致性不再靠"后对齐"兜底了。
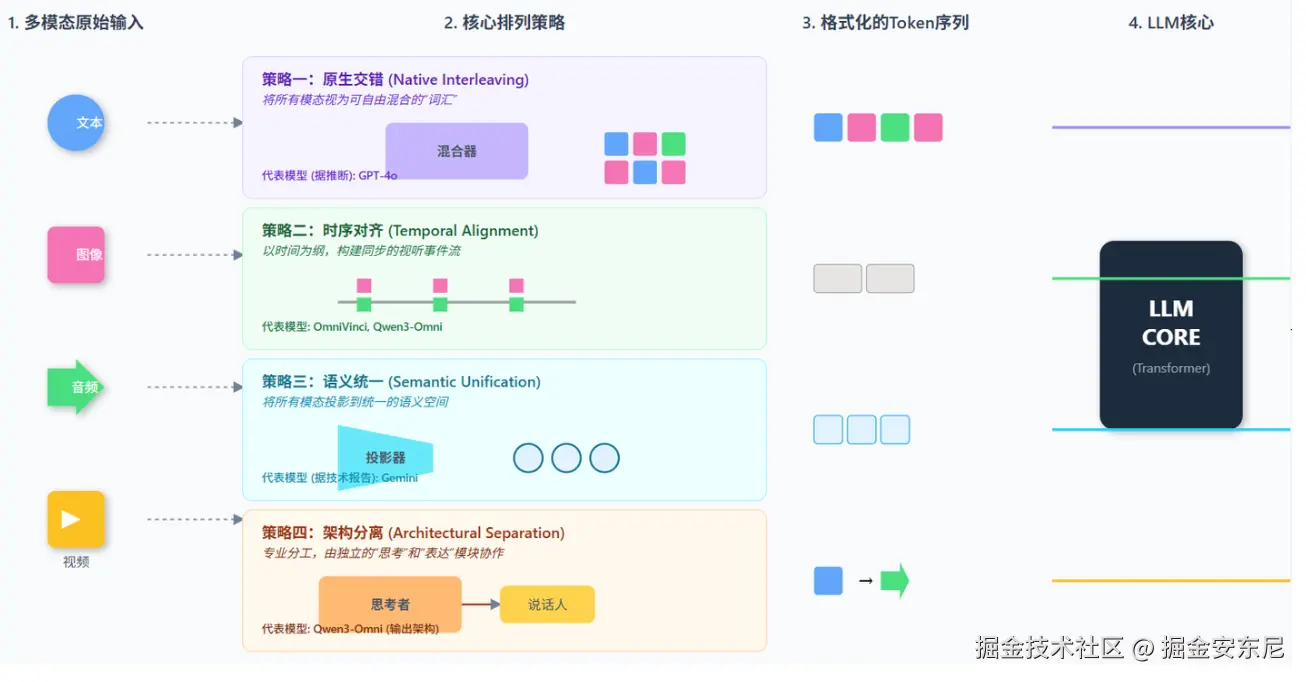
以往模型是视觉理解 → 文本生成,这种两段式很容易断链。而心 5.0 的思路是:理解即生成,生成即理解,是同一个推理过程。 技术上,这是比"加一个视觉头"难一个数量级的事情。
不仅如此,文心 5.0 的 MoE 总参数超过 2 万亿,训练通过飞桨的多级分离架构与 FP8 混合精度实现 230% 的性能提升。这套体系的价值在于:不是靠堆算力,而是靠"调度能力"、不是靠暴力扩容,而是靠"高效稀疏",它能把原生全模态成本压得足够低,能产线化,还能保持训练效率,让统一架构真正落地。
在 2025 年这个行业昂贵到"每算力都要反复计较"的时间点,这套技术选型具有非常强的现实意义。
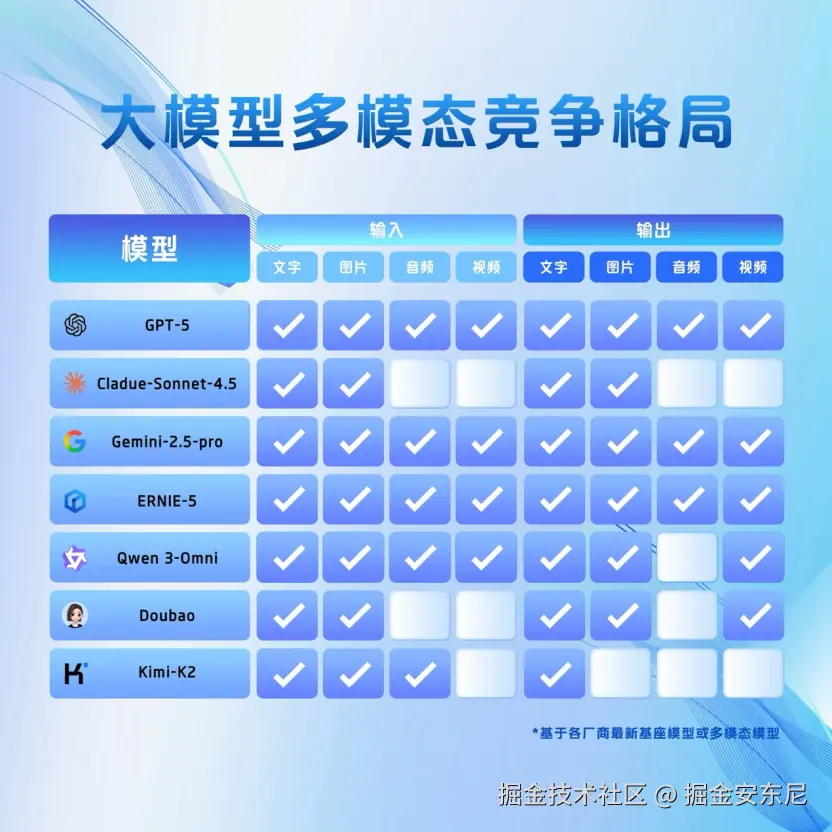
百度押的不是模型规模,而是架构未来, 这也是为什么我说它是分水岭。
在技术路径已经铺好之后,我们再去看 11 月 13 日的发布会
所以,再看11 月 13 日发布会的意义,不是"某个模型上线了",而是:百度第一次把完整的原生全模态体系,对开发者公开透明。 preview 当天上线千帆平台,支持:图像 + 文本输入、视频 + 文本输入、音频输入、多模态输出(文本 + 图片)、即将开放视频生成链路。
对开发者而言,这意味着你可以第一时间感受统一架构的推理特征,而不是从讲稿中间接理解。发布会里讲到的亮点,其实都可以回到刚才说的底层路线:
- 统一建模 → 多模态推理丝滑
- 稀疏化 MoE → 推理成本下降
- 多级分离推理架构 → 长任务更稳
- 强化学习引入"行动链" → 智能体能力增强
其实,早在发布会的前一周,ernie-5.0-preview-1022的"预览版本"已经登上了LMArena文本排行榜全球并列第二、国内第一。
能力差异藏在细节里:三类关键测试场景

4.1 文心 5.0 理解动态世界,从一颗"旋转的地球"开始
为了验证文心 5.0 的原生全模态推理能力,我找了一个极简单、但极具区分度的输入------一个 3D 自转地球的 GIF(地球自转周期 24 小时、卫星公转周期约 90 分钟)。乍一看,这不过是个普通的 3D 演示:光照、纹理、旋转、星空背景,中间还有一段遮挡贴图。
大多数多模态模型看到这种 GIF,给出的答案往往是模板化的:"这是地球在转""这是太空""这是星空背景"。但文心 5.0 的反馈明显不同,它的理解几乎是"跨模态同步"的:它综合判断:大陆板块的形变是否符合球体 UV 纹理的真实旋转、光照移动速度与纹理移动速度是否同步、亮暗交界线是否呈现昼夜交替的物理特征,这是一种典型的"跨模态物理推理"。
很多模型会把星空误识为贴图噪声,文心 5.0 却能判断:星空元素不随相机视角移动、不是摄像机晃动,而是主体旋转,说明它在进行视觉稳定性判断。
文心5.0还能理解中心遮挡物不是地球特征,而是演示贴图缺损,绝大多数模型会认为那块白色矩形是"冰盖""建筑""亮斑""高光",这是典型的:跨模态物理一致性推理。
4.2 文心 5.0 能"读懂动作风格",不是单纯比对像素
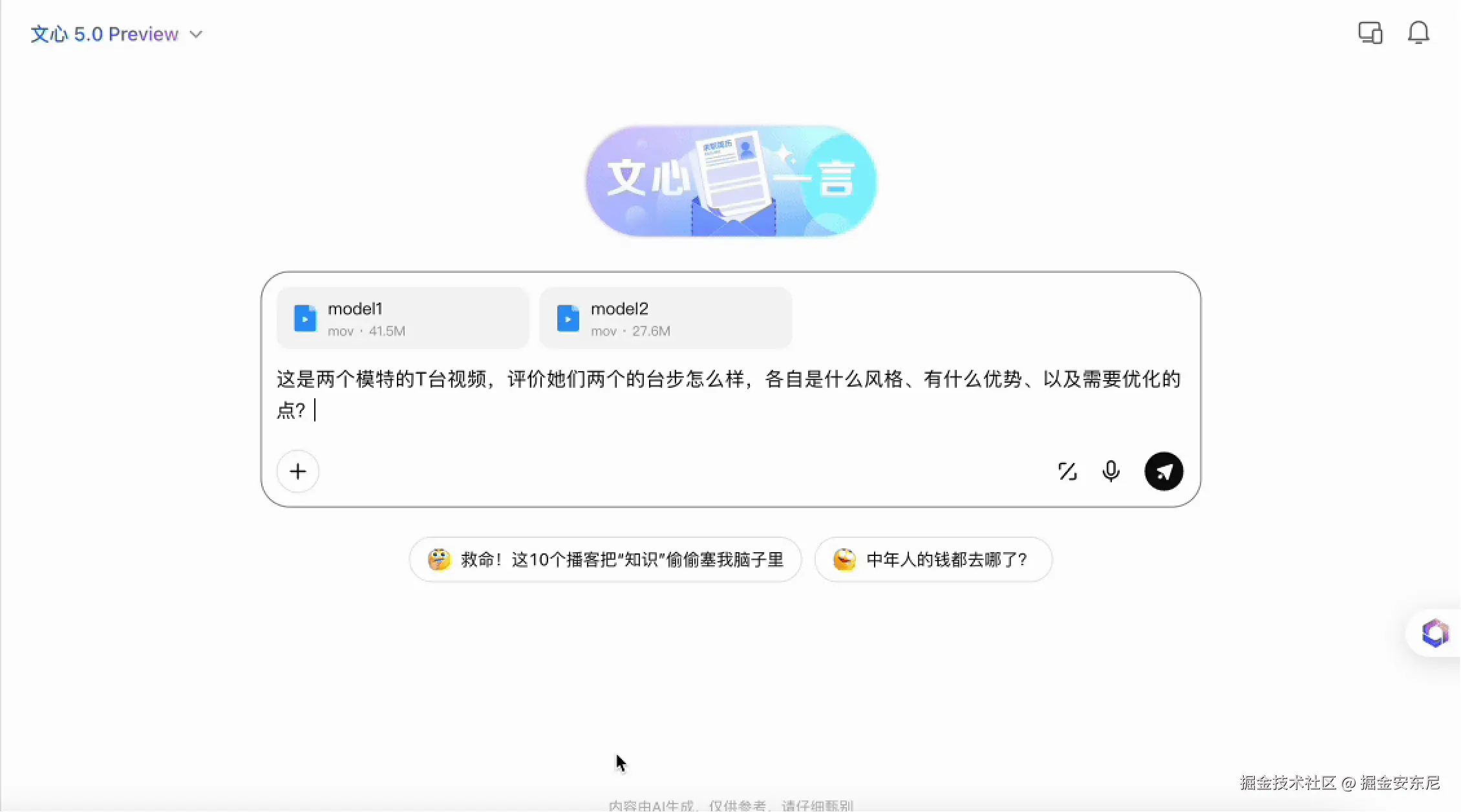
第二个案例我用了一个更偏"动作理解"的输入:两段模特台步视频放在一起,让模型进行对比。别看这个任务听起来简单,实际上它是传统视觉-语言拼接模型的"死亡三连":动作节奏识别(步频、摆臂幅度)、镜头运动与人物运动区分、跨视频同步理解并做差异化分析
传统模型分析这种内容时,结果往往是模板式的:"A 走得快""B 走得慢"。但文心 5.0 会自动做四件事:
1、自动建立"节奏对齐"维度,而不是逐帧比较
例如它会指出:"左侧模特的步频更稳定、步幅更小,节奏感偏向常规走秀","右侧模特的步伐更大、摆臂更明显,更偏向视觉冲击型展示。"这是典型的动作韵律理解,不是画面级别的"识别"。
2、识别镜头运动 vs. 人体运动
传统模型容易被"推镜头"或"轻微抖动"误导,判断成人物动作不稳。文心 5.0 会先判断:镜头是否移动、背景几何是否发生透视变化、主体移动是否相对稳定然后给出类似的结论:"第一段视频存在轻微镜头前推,不属于模特动作差异。"
这说明它的时序理解能力 覆盖了视频语言之外的摄影语法。
3、识别"风格"这种高度抽象的属性(关键)
动作风格属于极高抽象层次,需要在统一空间中实现:姿态、重心变化、步频节奏、手臂协调、视觉气场

文心 5.0 总结:"左侧风格偏自然、中性,右侧风格更表现型,带有刻意的节奏强调。"
4、能跨视频做"差异化叙述",而不是分别单讲
拼接式模型常犯一个错误:它只能独立描述两个视频,无法构建"对比空间"。文心 5.0 则能一次生成完整对比结论:
"相比左侧模特的稳定步态与自然摆臂,右侧模特在身体前倾角度、摆臂幅度与步幅节奏上更夸张,形成明显的舞台表现张力。"
这是因为所有视觉 token 都进了同一个语言空间,模型能在同一链路中完成:特征提取、时序编码、风格判断、跨视频差异化推理,这是典型的 跨模态统一推理能力。
多模态综合推理就是:视觉证据 + 场景线索 + 常识推理 → 不容易被骗
4.3 文心 5.0 的音视频混合推理能力
第三个案例换成了一个非常典型的开发者任务:给模型一段音频,再给一段视频,让它判断视频是否使用了这段音乐,以及出现在哪个时间点。
对大多数多模态模型来说并不好做,因为拼接式模型往往把视频当视觉任务处理,把音轨当独立语音任务处理,最后再用语言模型"猜"答案,大多只能给出非常模糊的匹配结果。
文心 5.0 会同时读取视频帧的动作节奏、背景音轨的波形特征、音乐的节拍与旋律变化,再把这些特征放在同一空间做比对。于是当音乐真正被用在视频中时,模型能够捕捉到音轨与画面节奏之间的对应关系;它也能指出具体是从哪个时间点开始, 这个能力本质上不依赖"语言描述",而是依赖原生全模态模型对音频与视频在同一链路上的比对能力。
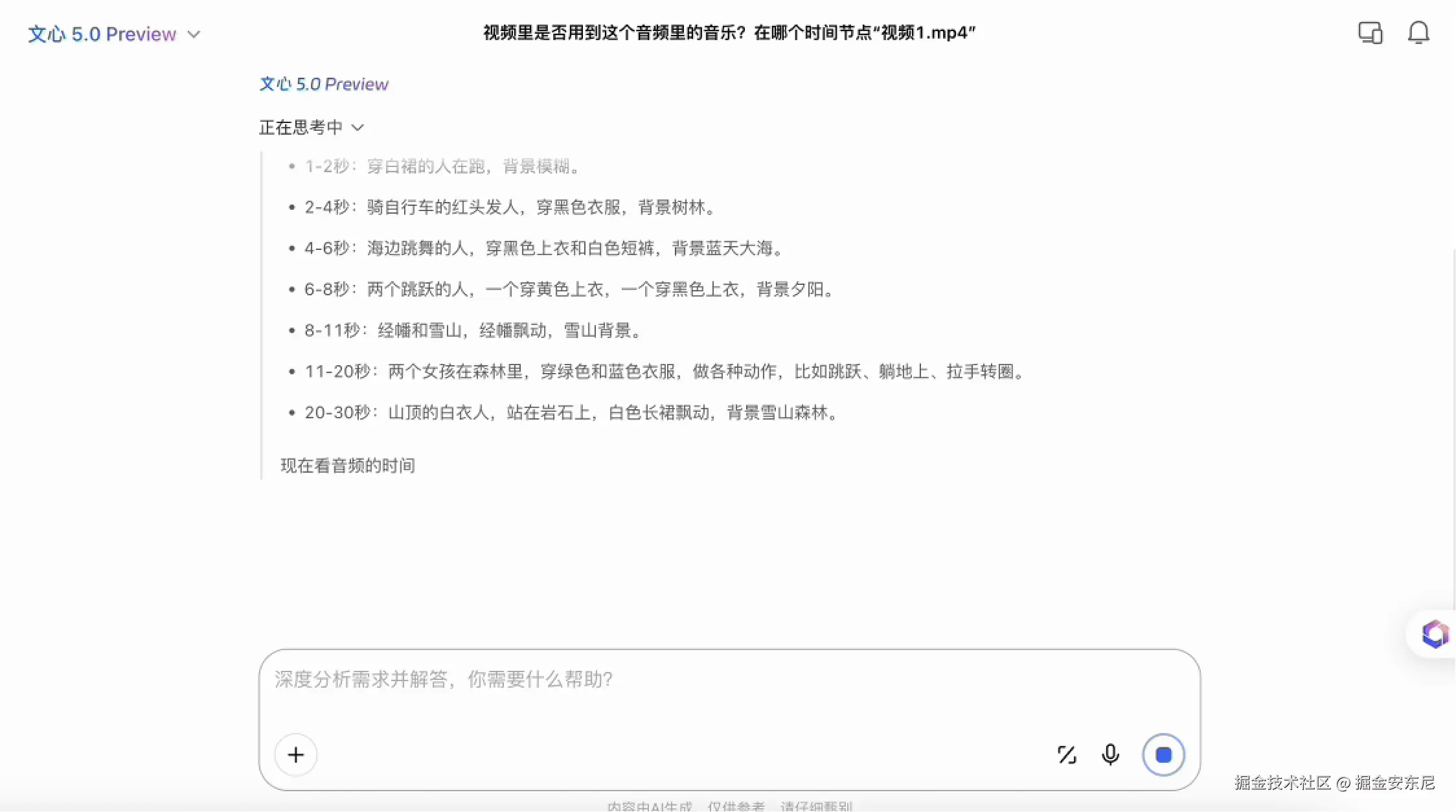
这种能力意味着模型在媒体分析、内容审核、音乐版权检测、视频语义检索等任务上都有更高的可用性。
从推理到智能体:原生全模态带来了更强的"行动能力"

以高说服力数字人的底座能力为例,文心 5.0 同时依托文心 4.5 Turbo、语音合成和视频生成模型,通过统一的推理链串起脚本、表演、动作与情绪,使数字人不再只是"播放动画",而是真正具备思考、决策和执行能力。
在实际直播间中,这种能力进一步被扩展为多智能体协同。数字人的"AI 大脑"会根据直播热度、观众行为、评论节奏不断做出判断,并调度不同智能体执行任务:直播冷场时调度助播智能体活跃气氛,用户进入犹豫期时调度运营智能体发券,出现专业提问时调度互动智能体回答。
所有决策都会根据直播后的数据回流进行迭代,让智能体体系形成闭环。
类似的能力已经在汽车行业落地:数字人会根据实时信号自动判断观众地域特征,一旦识别出"北方用户较多",便即时切换介绍空调、座椅加热等更相关的卖点。结果是线索转化率提升 44%,获客成本下降 64%。所以,从这个案例可以看到,原生全模态的价值不只在"看懂世界",而是在"基于理解做出正确行动"。
结语:原生全模态不是概念,是国产模型真正站上世界级舞台的那一步
全球大模型竞速像是重量级拳击赛,一个个模型靠"堆能力、堆模态、堆技巧"硬撑上场。国产模型在这条赛道上追得很辛苦:算力差距摆在那、生态差距摆在那、海外模型封闭得更是寸步难行。
但文心 5.0 这次做的不只是"追上"------将文本、图像、视频、音频放进同一个统一架构,以原生全模态做底座,在 LMArena 上,它已经与全球头部模型并肩;在多模态、智能体、训练体系、推理效率这些真正体现底功的指标上,它展现出的成熟度,让人第一次清晰地看到:
国产模型不再是跟随者,而是正在共同定义下一代模型的基准线。