一、摘要
YOLOv5 作为当前主流的目标检测框架,凭借其高效的检测速度与出色的精度表现,成为植物识别任务的优选方案。本项目将围绕 "仙人掌、松树" 等植物类别展开目标检测模型的开发,整体流程可分为模型准备、数据处理、模型训练、推理验证四大核心环节,通过分工协作与技术拆解,实现从基础框架到定制化植物识别的全流程落地。



二、模型准备:从官方资源到定制化开发
首先需从 YOLOv5 官方仓库 下载基础模型(如 yolov5s.pt),该模型是在 COCO 数据集上预训练的通用目标检测模型,具备识别 80 类常见物体的能力。但为适配植物识别任务,需在其基础上进行数据替换与网络微调:
1.下载后将模型文件置于项目根目录(如 yolov5_new),后续通过 train.py 脚本加载该模型,并利用自定义植物数据集重新训练分类与回归头,使模型专注于识别 "仙人掌、松树" 等目标;
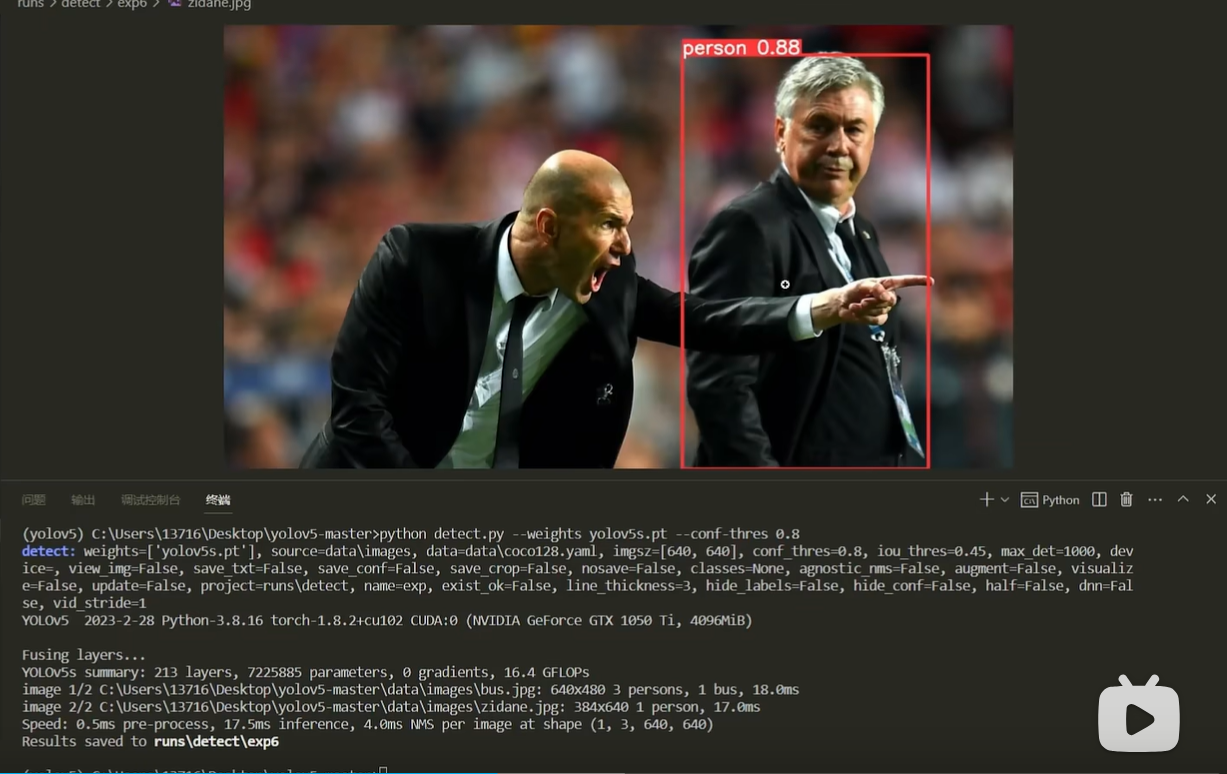
2.若需快速验证流程,可先通过 detect.py 运行官方模型,测试如上图中 "人物检测" 的默认功能,再逐步替换为植物数据。
三、数据处理:标注与划分的关键步骤
数据是模型效果的核心支撑,植物识别任务需重点关注以下环节:
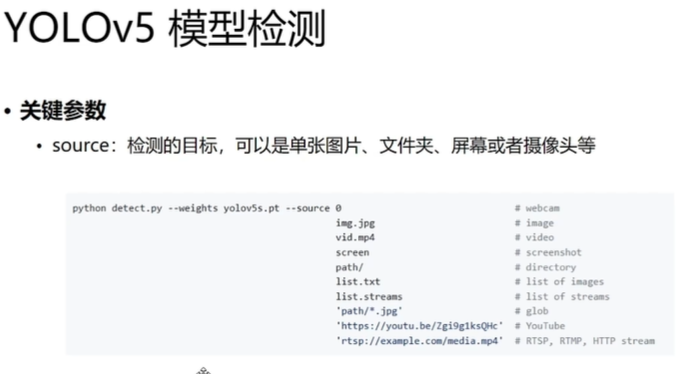
1.数据采集与分类:收集 "仙人掌、松树" 等目标的图像,覆盖不同生长阶段、光照条件、拍摄角度(如上图中仙人掌的密集场景、松树的山地场景),确保数据多样性;
2.标注分工协作:采用 LabelMe 等工具对图像进行边界框标注,明确每株植物的类别与位置。由于标注工作量大,需两人分工完成,分别负责不同类别的图像标注,保证标注精度与效率,通过以下代码将 LabelMe标注后的json文件转换为txt文件;
import json
import os
from PIL import Image
json_dir = "D:\labelme\song.txt"
txt_dir = "D:\labelme"
# 类别:0=song
class_names = ["song"]
for json_file in os.listdir(json_dir):
if json_file.endswith(".json"):
with open(os.path.join(json_dir, json_file), "r", encoding="utf-8") as f:
data = json.load(f)
# 获取图片尺寸
img_path = os.path.join(json_dir, data["imagePath"])
img = Image.open(img_path)
width, height = img.size
# 生成txt标签
txt_name = json_file.replace(".json", ".txt")
with open(os.path.join(txt_dir, txt_name), "w") as f:
for shape in data["shapes"]:
cls = class_names.index(shape["label"]) # 类别编号
points = shape["points"] # 多边形坐标
# 转换坐标为YOLO格式(归一化到0-1)
normalized = []
for (x, y) in points:
normalized.append(x / width)
normalized.append(y / height)
# 写入txt:类别 坐标1 坐标2 ...
f.write(f"{cls} " + " ".join(map(str, normalized)) + "\n")3.数据集划分:将标注好的数据按 "训练集:验证集 = 8:2" 的比例划分,训练集用于模型参数更新,验证集用于监控训练过程中的过拟合情况(如前文所述验证集需包含各类别关键特征且不与训练集重复)。
四、模型训练与推理:从参数配置到效果验证
1.训练流程:
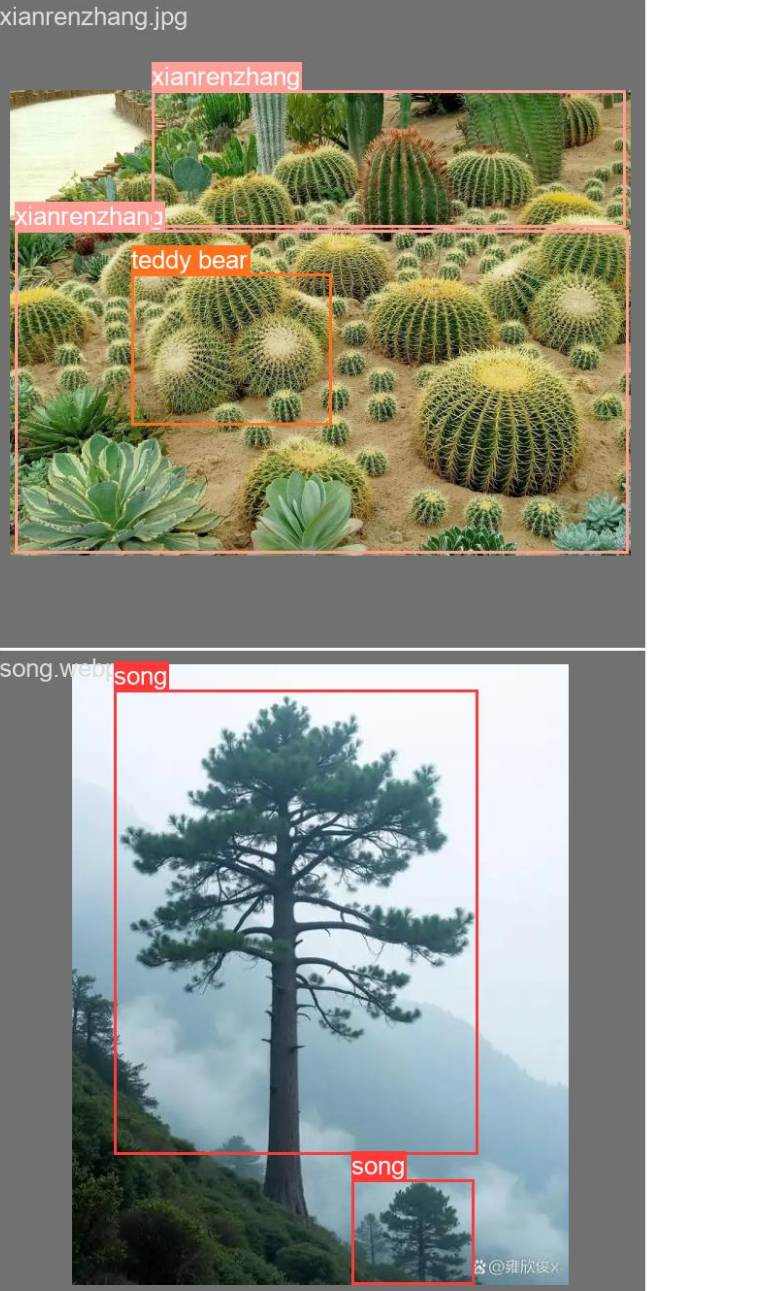
(1)配置 mydata.yaml 文件,指定训练集、验证集路径及类别数(如本项目中 nc=2 代表 "仙人掌、松树" 两类);
path: D:\python learning\pythonProject\yolov5_new\mydata
train: D:\python learning\pythonProject\yolov5_new\mydata\images\train
val: D:\python learning\pythonProject\yolov5_new\mydata\images\train # test images (optional)
test:
# Classes
names:
0: song
1: xianrenzhang
2: teddy bear(2)运行 train.py 脚本,加载预训练模型 yolov5s.pt,设置训练轮数(epochs)、批次大小(batch_size)等参数,启动模型训练;
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "D:\python learning\pythonProject\yolov5_new\data\mydata.yaml", help="dataset.yaml path")


(3)训练过程中,TensorBoard 会实时记录损失曲线与精度指标,可通过 tensorboard --logdir runs/train 查看训练动态。
2.推理验证:
(1)训练完成后,加载最优权重文件(如 runs/train/exp/weights/best.pt),通过 detect.py 对测试图像进行推理;
(2)推理时可调整置信度阈值(conf-thres),平衡检测框数量与精度(如上图中不同阈值下的检测效果差异),最终输出带植物类别与位置的检测结果

五、后续计划与协作分工
现阶段需优先完成 YOLOv5 官方模型的下载与环境配置,确保 train.py、detect.py 等脚本可正常运行。待模型准备就绪后,将启动数据标注工作,分工负责不同类别植物的标注任务,以加速数据积累。后续还需针对模型训练过程中的损失波动、精度瓶颈等问题进行调优,最终实现高精度的植物识别目标检测系统。