一、项目概述
本项目是基于 Vue 3.5 + Node.js + Express 构建的现代化 AI 多模态应用,实现 智能对话、AI 写作、图像生成、语音识别与合成 等核心功能。采用 前后端分离架构,聚焦工程化实践与用户体验优化,在安全性、性能、可维护性等维度形成完整解决方案,达到生产级应用标准。
二、技术栈架构
前端技术栈
- 框架:Vue 3.5(Composition API)
- UI 组件:Element Plus 2.7
- 状态管理:Pinia 2.1
- 路由:Vue Router 4.2
- 构建工具:Vite 5.0
- 富文本:WangEditor 5.1
- 网络请求:Axios 1.11
- 性能优化:@tanstack/vue-virtual 3.13(虚拟滚动)
- 内容渲染:markdown-it 14.1(Markdown 解析)
后端技术栈
- 运行时:Node.js
- Web 框架:Express 5.1
- 数据层:Prisma 6.16 + MySQL 3.14(ORM 与数据库)
- 认证:JWT(jsonwebtoken 9.0)
- 安全:Helmet 8.1(安全头)、CORS 2.8(跨域)
- 加密:bcryptjs 3.0(密码哈希)
- 文件处理:Multer 2.0(上传)
- 实时通信:ws 8.18(WebSocket)
- 日志:Morgan 1.10
核心 AI 服务集成
- 对话:豆包 Seed 1.6(支持快速 / 深度思考模式)
- 语音合成:豆包 TTS(WebSocket 流式传输)
- 语音识别:豆包 ASR(实时转写)
- 图像生成:豆包 Seedream 4.0
三、核心技术与功能亮点
企业级身份认证与权限管理
业务挑战
需平衡登录注册流程的安全性与开发效率,解决 XSS / CSRF 防护、凭证安全传输、自动鉴权及多角色扩展 问题。
技术实现
- 三层鉴权架构:前端响应式表单验证(用户名 / 密码规则校验)→ 后端 Prisma 查询 + bcrypt 加密(salt rounds=10)→ JWT 生成(含 user_id/role,有效期 24h)。
- 自动化鉴权 :JWT 存储于 HttpOnly Cookie (防 XSS ) ,后端统一中间件提取验证令牌,注入用户信息至 req.user,支持 角色权限(USER/ADMIN)细粒度控制。
- 安全增强:配置 secure(生产环境 HTTPS)、sameSite=lax(防 CSRF);密码加密采用单向哈希,登出时主动清除 Cookie 与本地状态。
核心价值
实现 无感知鉴权流程,防护常见网络攻击,支持多角色扩展,安全性与用户体验兼顾。
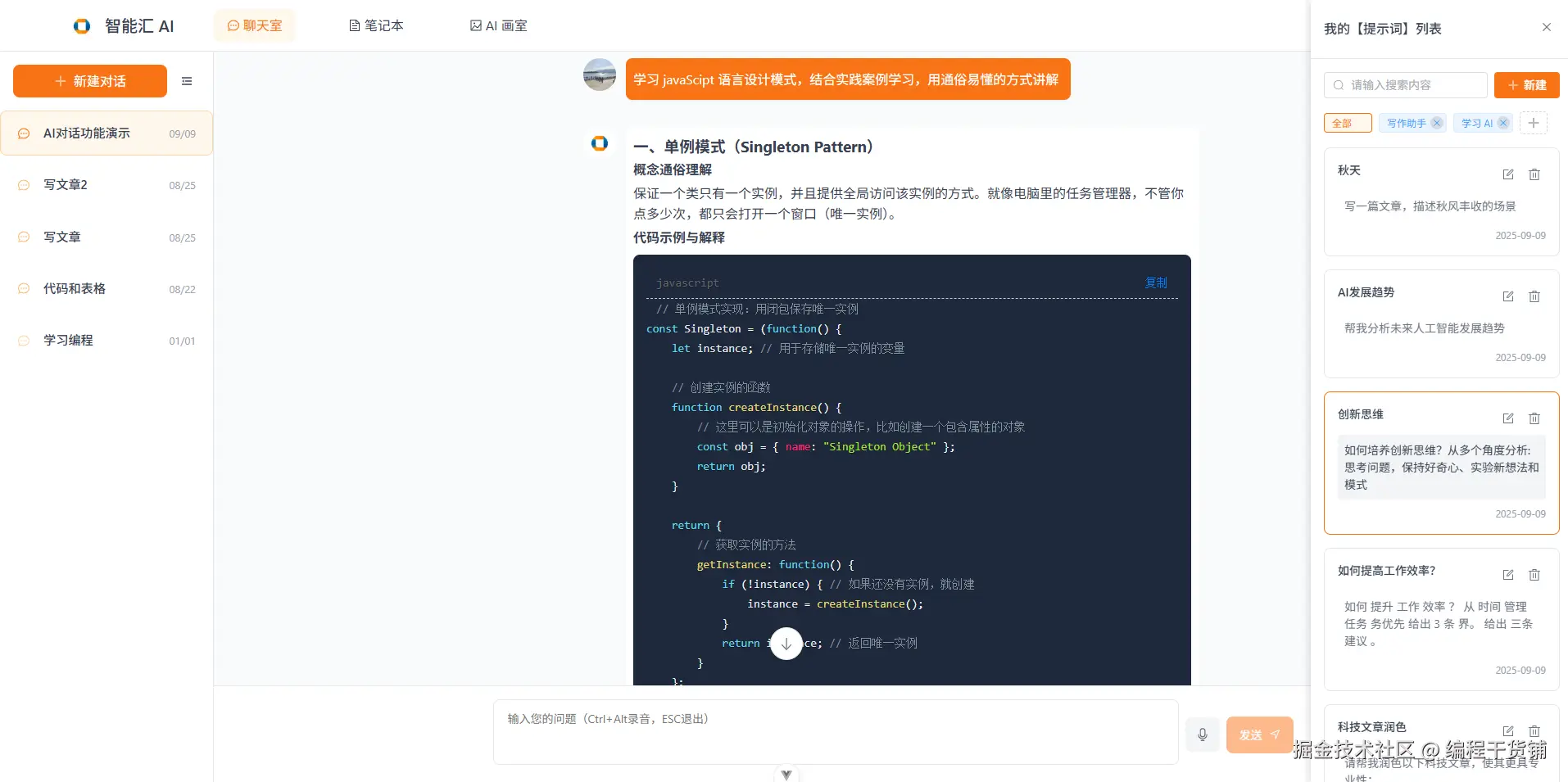
AI 对话快速和深度思考无缝切换
业务挑战
豆包快速 / 深度模型参数格式存在差异,都需处理 SSE 流式数据实现逐字显示,降低前端调用复杂度。
技术实现
- 后端接口统一封装:通过 modelApi.js 适配不同模型参数(深度思考模型会返回思考文本),统一 messages 数组输入格式,按 modelType 自动转换。
- 流式数据处理:缓冲区解决数据分割问题,解析 SSE 格式提取增量内容,区分深度模型的 "思考过程" 与 "最终答案",返回统一格式({status, data: {content, type}})。
- 前端 实时渲染 :自定义 POST-based SSE 客户端(原生 EventSource 仅支持 GET),利用 Vue 响应式系统拼接增量内容,实现自然的 逐字显示效果。
核心价值
前端无需关注模型差异,切换零成本;流式渲染优化对话体验,前后端解耦提升可维护性。
 编辑
编辑
长列表性能优化方案
业务挑战
聊天记录增长导致 首屏加载慢、 DOM 节点冗余(2000+)、滚动卡顿(30-40 fps ) 。
技术实现
- 后端分页策略:默认加载最新 20 条,滚动触顶时加载上一页;按 created_at 倒序查询(利用索引),返回 hasNext/hasPrev 元数据,并行查询列表与总数提升响应速度。
- 前端虚拟滚动:仅渲染可视区 + 缓冲区内容(约 15 条),通过 padding 模拟未渲染区域高度,DOM 数量降至 40 个;动态测量每条消息高度并缓存,加载新数据时自动调整滚动位置保持体验连贯。
优化效果
- 首屏加载时间:1.8 秒→0.3 秒(提升 83%)
- DOM 节点:2000+→40 个(减少 95%)
- 滚动帧率:30-40fps→55-60fps
实时流式语音合成
业务挑战
传统方案需等待完整音频生成(3-5 秒),用户体验差,需实现 低延迟 流式播放。
技术实现
- 后端实时 中继:WebSocket 连接豆包 TTS 服务,解析自定义二进制协议(提取 PCM/MP3 数据块),通过 HTTP 分块传输(Transfer-Encoding: chunked)实时推送音频数据。
- 前端流式播放:利用 HTML5 Audio 元素直接绑定 API URL,收到首块数据后触发 canplay 事件立即播放;全局单例管理播放器,新消息播放时自动停止当前音频,支持自动重试(最多 3 次)。
- 文本预处理:自动去除 Markdown 格式,截断过长内容(>1000 字)避免生成超时。
核心价值
延迟从 3-5 秒降至 0.5-1 秒,边传边播提升用户体验,跨域配置与自动播放策略保障兼容性。
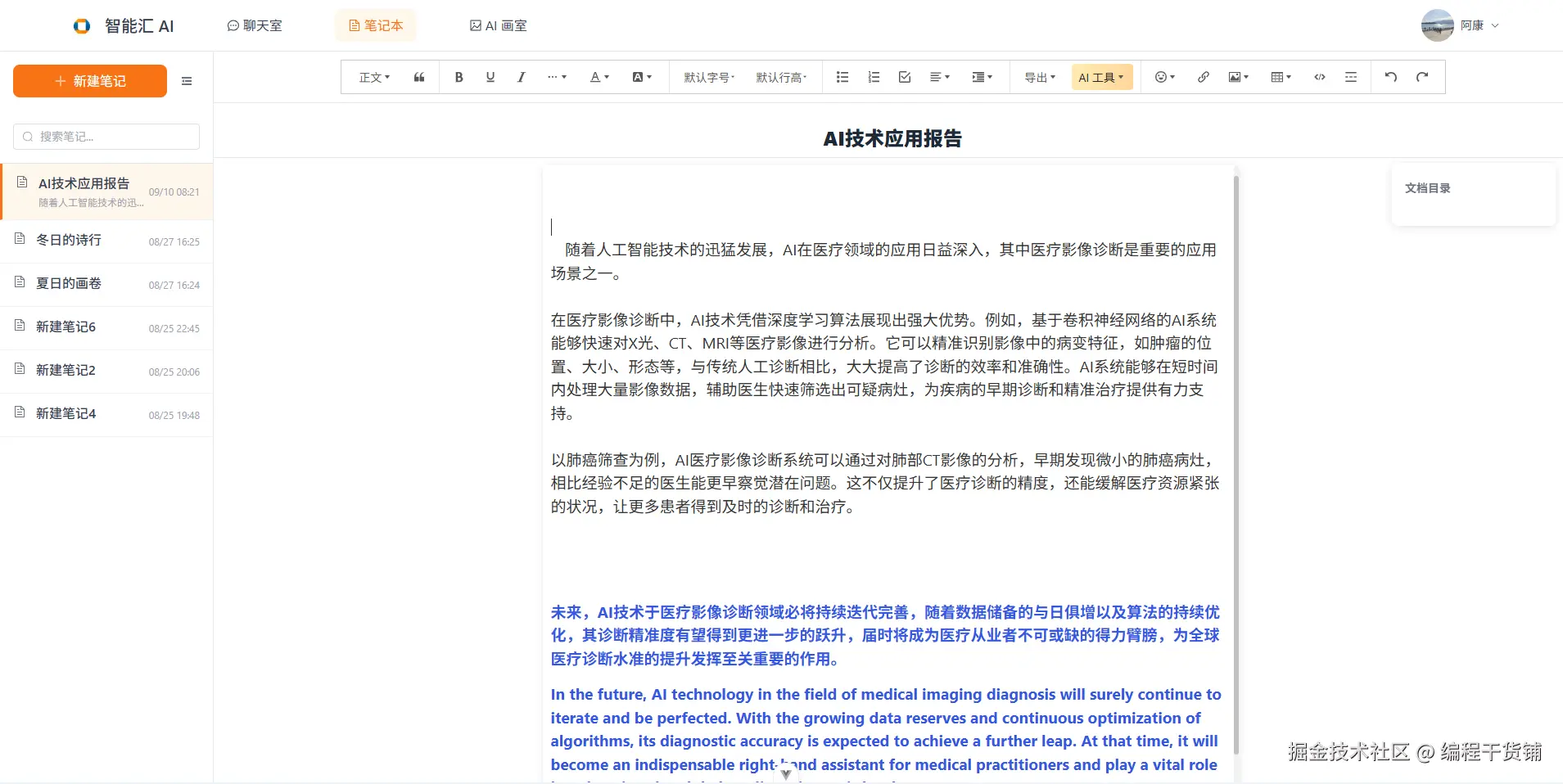
富文本编辑器 AI 写作助手
业务挑战
需在编辑器中无缝集成语音功能,支持多种触发方式,不打断写作节奏。
技术实现
- 多触发方式:工具栏 "AI 工具" 下拉菜单(续写 / 总结 / 润色等)、Ctrl+Alt 快捷键唤醒弹窗(跟随光标定位)、选中文本自动识别(高亮提示)。
- 实时反馈 :AI 生成内容 逐字显示(打字机效果) ,完成后一键插入光标位置,支持替换 / 追加选中文本。
- 解耦 设计:AI 功能与编辑器通过全局事件通信,新增功能无需修改编辑器核心代码。
核心价值
操作流畅不打断写作节奏,多触发方式适配不同使用场景,动态定位与状态提示提升交互体验。
 编辑
编辑
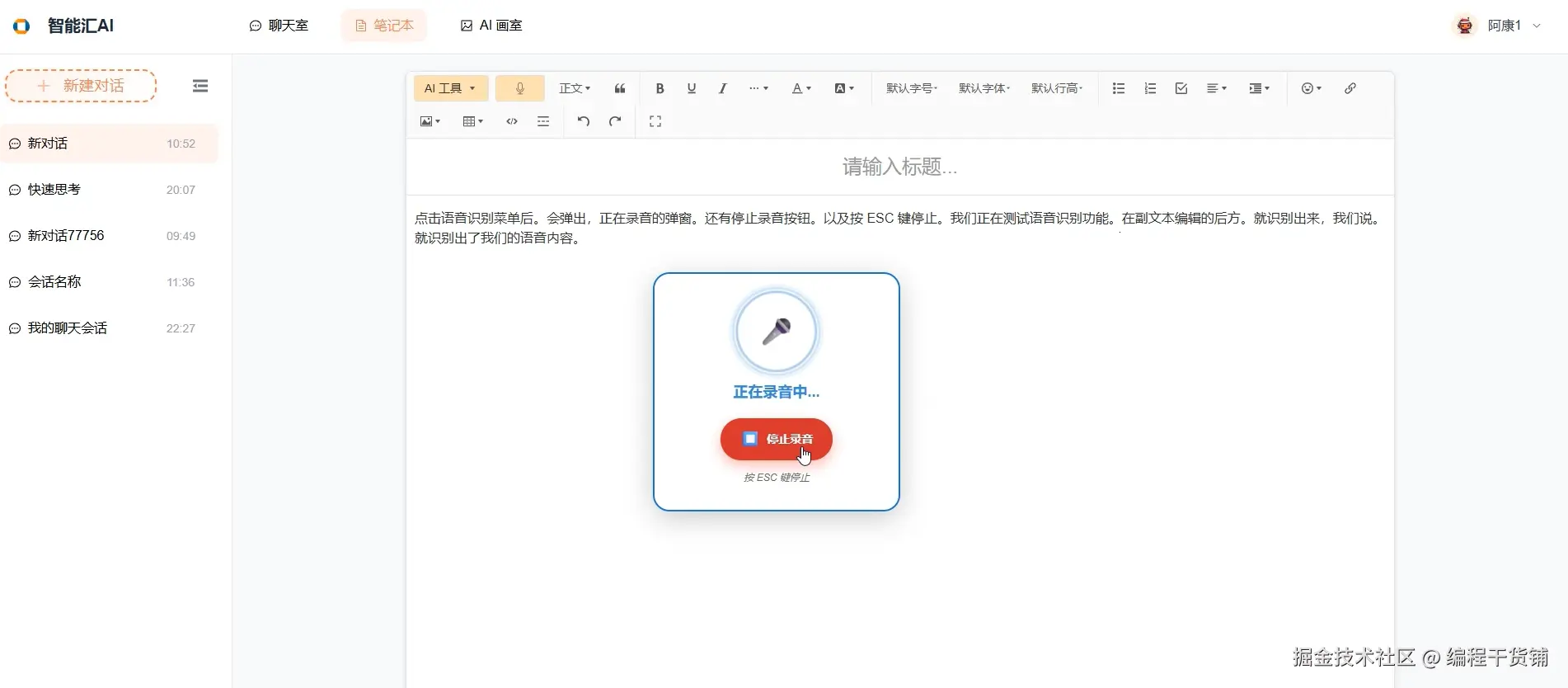
智能语音识别实时转写
业务挑战
实现 "边说边写" 提升输入效率,需解决 音频格式转换、浏览器兼容、实时反馈 问题。
技术实现
- 实时转写流程:WebSocket 流式传输 PCM 音频(16kHz 采样率,16 位深度),后端识别中间结果即时返回,前端插入编辑器;最终结果自动更新中间内容,支持 ESC 停止录音。
- 格式标准化:浏览器采集的 Float32 音频→转换为 Int16 PCM,统一服务端输入格式,提升识别准确率。
- 分层架构:UI 交互层→核心控制层(录音 / WebSocket 管理)→音频处理层→通信层→诊断层,保障稳定性。
核心价值
实时反馈减少等待感,格式统一提升识别准确率,新老浏览器兼容覆盖全场景。
 编辑
编辑
图像生成接口的工程化实践
业务挑战
将豆包 Seedream 4.0 API 封装为生产级服务,核心问题在于:外部 API 返回的图片 URL 可能失效,无法保证长期可用性 。同时需解决 稳定性、安全性、可维护性 等工程化问题,涵盖图片持久化、并发下载、格式识别、数据一致性等多个方面。
技术实现
采用分层架构保障系统稳定运行,具体为:路由层(RESTful 接口)→中间件层(JWT 鉴权 / 参数验证 / 限流)→控制器层(请求处理)→服务层(API 调用 / 图片下载)→数据层(Prisma 存储)。在此基础上,实现以下核心技术:
图片本地化存储:解决外部 URL 失效问题
- 核心策略 :不直接返回外部 URL,而是将生成的图片下载到本地服务器(
uploads/images/目录),返回本地路径 - 文件命名规则 :
{imageId}_{index}.{ext}(如uuid_1.png),确保唯一性与可追溯性 - 长期可用性:图片存储在自有服务器,不受外部服务影响,用户可随时访问历史生成的图片
并发下载优化:提升多图生成效率
- 并发策略 :使用
Promise.all并发下载多张图片(最多 4 张),而非串行下载 - 性能提升:4 张图片并发下载时间从串行的 8-12 秒降至 2-3 秒,提升 75%
- 超时控制:单张图片下载超时 60 秒,避免长时间阻塞
智能格式识别:确保文件格式正确
- 多级判断机制:
- 优先根据 HTTP 响应头
Content-Type判断(image/png、image/jpeg、image/webp) - 无法判断时,根据 URL 后缀猜测
- 兜底使用
.png格式
- 容错处理:即使外部服务返回格式信息不完整,也能正确保存图片
完整的数据持久化体系
- 本地存储 + 数据库记录:
- 本地存储:图片文件保存到
uploads/images/目录 - 数据库记录:使用 Prisma ORM 存储生成参数(提示词、尺寸、模型、数量)、图片路径数组、生成时间、用户 ID、会话 ID 等
- 历史查询支持:
- 支持按会话分页查询历史生成记录
- 支持按用户查询收藏的图片
- 返回
hasNext、hasPrev等分页元数据
安全防护
JWT 鉴权、输入校验(提示词长度 / 尺寸白名单)、API 密钥环境变量管理、可扩展限流机制。
核心价值
通过上述技术实现,接口支持多用户并发访问,确保图片长期可用;依托统一规范的分层架构设计,系统具备强可观测性(日志 / 监控),极大提升维护与扩展的便捷性。
 编辑
编辑
四、项目总结
核心技术亮点
- 安全性:JWT+HttpOnly Cookie 防护,bcrypt 加密,CORS/CSRF 防护,输入校验与限流。
- 性能优化:虚拟滚动减少 95% DOM,分页加载提升 83% 首屏速度,流式传输降低 80% 语音延迟。
- 用户体验:实时流式反馈(对话 / 语音),智能交互(快捷键 / 自动定位),流畅操作(滚动 / 位置保持)。
- 工程化:分层架构清晰,统一错误处理,完善日志,可观测性强。
- 可维护性:模块解耦,规范统一(API / 响应格式),类型安全(Prisma)。
多模态 AI项目开发技术学习 :coding.imooc.com/class/954.h...