为了计算生态系统服务的重要性,一般来说会使用累计值来进行计算。比如说累计的前50%值的像元为极重要区,而50-75是一般重要。
| 重要性 | 说明 |
|---|---|
| 极重要 | 从大到小排序,累计50的值 |
| 重要 | 从大到小排序,累计50-75的值 |
| 中等重要 | 从 90%到 75%该段的栅格值,占总量 15%的值归类为中等重要区域 |
| 一般 | 比 90%小的值,即占总量 10%的值全部归类为一般区域。 |
一、主要部分
下面的代码放在代码框中。
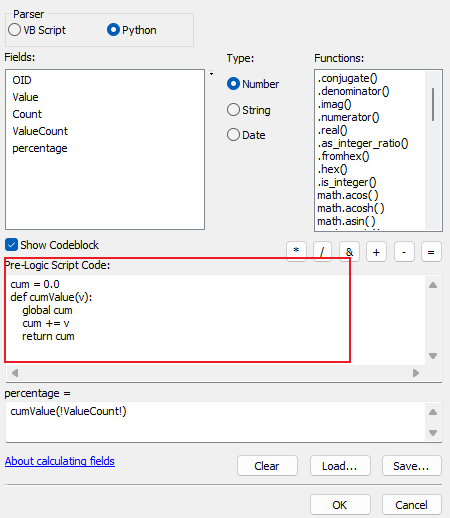
bash
# 全局累加器
cum = 0.0
total = 0.0
# 在计算前先一次性求 total(第一次执行时 total 仍然为 0,因此需要初始化)
import arcpy
# 获取当前图层(使用 !SHAPE! 触发,则自动是当前表)
tbl = arcpy.Describe(arcpy.GetParameterAsText(0)).catalogPath if arcpy.GetParameterAsText(0) else None
# 兼容 ArcMap,强制使用当前表名
if tbl is None:
tbl = r"%s" % arcpy.Describe("RWEQ_xh_ly.tif").catalogPath # 这块需要将 RWEQ_xh_ly.tif
# 只在 total 还没算的时候执行一次
if total == 0:
rows = arcpy.SearchCursor(tbl)
for r in rows:
total += r.ValueCount # ValueCount是要算的字段
def getCumProp(value):
global cum
cum += value
return cum / total在想算比例的字段中计算这个值。
bash
getCumProp(!ValueCount!)二、探究部分
这里面其实有个问题,就是这个是基于什么排序的?我探索了一下,它并没有指定,在goble环境下,它自动依据value进行降序排序,不管你后面在属性表中进行再排序其结果都是一样的。
具体可以用一个简单的例子来说明。可以用下面的一个例子来进行说明。
bash
cum = 0.0
def cumValue(v):
global cum
cum += v
return cum
bash
cumValue(!ValueCount!)此外,我还探索了下面两行代码,为什么需要这么写。其实下面就是获得文件的路径。(下面的第一行代码本来就是想获取它当前的路径的,但是在arcmap里面是不成功的。)
bash
# 获取当前图层(使用 !SHAPE! 触发,则自动是当前表)
tbl = arcpy.Describe(arcpy.GetParameterAsText(0)).catalogPath if arcpy.GetParameterAsText(0) else None
# 兼容 ArcMap,强制使用当前表名
if tbl is None:
tbl = r"%s" % arcpy.Describe("RWEQ_xh_ly.tif").catalogPath # 这块需要将 RWEQ_xh_ly.tif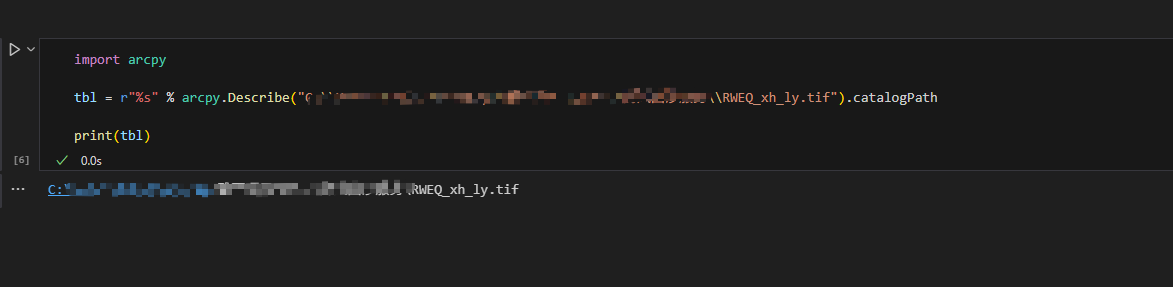
进一步探索:SearchCursor
这个功能感觉没有啥具体的用处,能算xy和对应的面积。
python
import arcpy
fc = 'c:/data/base.gdb/well'
# For each row, print the Object ID field, and use the SHAPE@AREA
# token to access geometry properties
with arcpy.da.SearchCursor(fc, ['OID@', 'SHAPE@AREA']) as cursor:
for row in cursor:
print(f'Feature {row[0]} has an area of {row[1]}')进一步探索:和Describe的相关属性
python
# 1.使用键值访问特定属性。
import arcpy
path = "C:\\Data\\Venice.gdb\\VeniceStructures"
desc = arcpy.da.Describe(path)
field_names = [field.name for field in desc["fields"]]
if "YEAR_BUILT" not in field_names:
arcpy.management.AddField(path, "YEAR_BUILT", "SHORT")
# 2.显示返回的 Describe 字典以查看所有可用属性。
import arcpy
from pprint import pprint
path = "C:\\Data\\Venice.gdb\\VeniceStructures"
desc = arcpy.da.Describe(path)
pprint(desc)需要进一步探索的问题:如何进行给定的字段进行排序,这个很重要,又或者说当矢量的时候怎么处理呢?