
官网地址:https://hadoop.apache.org/
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 1。
优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点 3:
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 3。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 3。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 3。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 3。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低 3。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ 3。
Hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里 3。
构建案例:
前期准备
修改主机名
bash
hostname master
bash
或者
hostnamectl set-hostname master
bash修改静态IP
bash
vi /etc/sysconfig/network-scripts/ifcfg-ens33
##配置如下
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=327271d1-0f7c-488e-9896-7c245a2b7152
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.12.111
PREFIX=24
GATEWAY=192.168.12.2
DNS1=8.8.8.8
DNS2=114.114.114.114
# PEERDNS=no关闭防火墙
bash
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
iptables -F
setenforce 0修改IP映射
bash
vi /etc/hosts
配置如下图
配置SSH免密码登录
01.检验是否已经安装SSH
bash
rpm -qa | grep ssh02.配置
bash
# cd ~/.ssh/ #若无SSH目录,则需要先执行一次ssh localhost
# ssh-keygen -t rsa #会有提示,直接按回车即可
# cat id_rsa.pub >> authorized_keys #加入授权
# chmod 600 ./authorized_keys #修改文件权限03.验证
bash
# ssh localhost(完全分布式需要配置集群时间同步)
安装jdk
检查
bash
rpm -qa | grep jdk如果有预装的openjdk,删除它
bash
rpm -e --nodeps 软件名解压
bash
tar -zxvf jdk-8u144-linux-x64.tar.gz改名
bash
mv jdk1.8.0_144/ jdk1.8配置环境变量
bash
vi /etc/profile
##末行配置如下
export JAVA_HOME=/opt/hadoop/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=.:$PATH:$JAVA_HOME/bin配置文件生效
bash
source /etc/profile验证
bash
Java -versionHadoop2.7.2伪分布式安装
- 解压hadoop安装包
- 配置环境变量

- 修改hadoop配置文件
- hadoop-env.sh
- core-site.xml
- Hdfs-site.xml
- Mapred-site.xml
- Yarn-site.xml
- Slaves(完全分布式)
格式化集群(只在第一次启动时执行)

启动
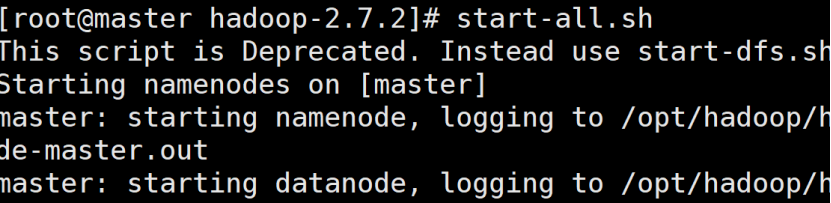
查看web ui
IP:50070
命令
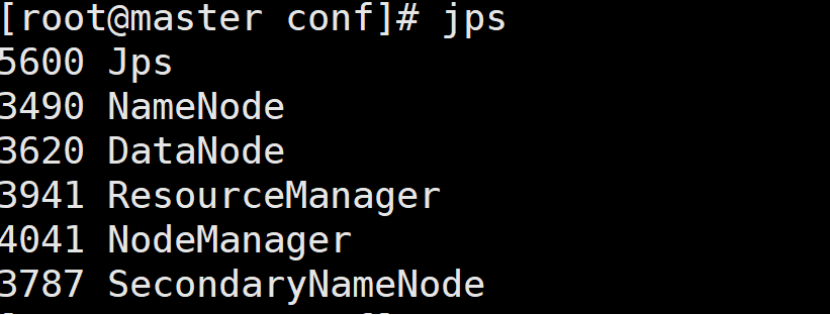
jps验证
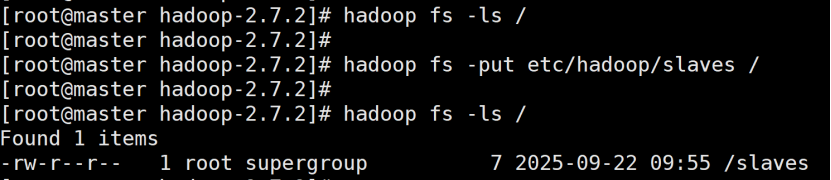
查看分布式文件系统根目录
上传文件
配置hbase1.3.1伪分布式集群
(此时还没有安装zookeeper,我们用hbase自带zk)
- 解压安装包
- 配置环境变量
vi /etc/profile
配置如下:

修改配置文件
Hbase安装包下conf目录
启动
先启动hadoop集群
启动hbase集群
关闭
和启动顺序相反,把上边命令中的start换成stop
验证
查看webUi
主机IP:16010
Jps命令
HMaster
HRegionserver
HQuorumPeer #这是zookeeper进程
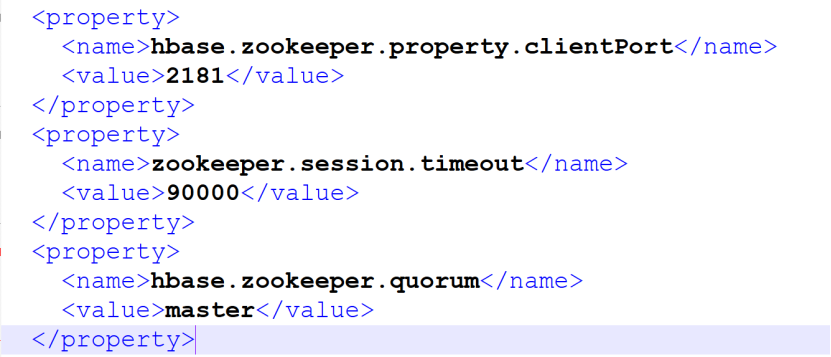
Hbase配置文件添加内容
Hbase-site.xml
Hbase shell操作
