文章目录
- 通过Golang订阅binlog实现轻量级的增量日志解析,并解决缓存不一致的开源库cacheflow
-
- [代码开源库地址 https://github.com/xzhHas/cacheflow](#代码开源库地址 https://github.com/xzhHas/cacheflow)
- 为什么需要缓存一致性
- 快速开始
- 内置功能
- 流程
- 使用示例
- 实战演示
- 性能
- 注意事项
- 最后
通过Golang订阅binlog实现轻量级的增量日志解析,并解决缓存不一致的开源库cacheflow
代码开源库地址 https://github.com/xzhHas/cacheflow
cacheflow:https://github.com/xzhHas/cacheflow
为什么需要缓存一致性
- 更新数据库后,旧缓存可能被读到,造成数据不一致。
- 复杂系统中引入 Canal、MQ、独立同步服务会增加维护成本。
- 以最小成本开启 binlog→缓存维护,保证最终一致性和读性能。
- 避免数据库数据更新之后,缓存里面还在维护旧的数据。
快速开始
go
package main
import "github.com/xzhHas/cacheflow"
func main() {
s, _ := cacheflow.StartSyncer(cacheflow.Config{
MySQL: cacheflow.MySQLConfig{Addr: "127.0.0.1:3306", User: "root", Password: "", Flavor: "mysql", ServerID: 1001},
Redis: cacheflow.RedisConfig{Addr: "127.0.0.1:6379", DB: 0},
Tables: []cacheflow.TableConfig{{DB: "user", Table: "users", Strategy: cacheflow.CacheAside}},
})
defer s.Stop()
}- 不提供
Key时默认使用db:table:id - 监听整个库:
{DB:"user", Table:"*", Strategy: cacheflow.CacheAside} - 监听多个表,在syncer里面也提供了Tables()的函数,可以支持监听一个库里面的多张表,如下:
go
// cacheflow库
func Tables(db string, strategy CacheStrategy, names ...string) []TableConfig {
tcs := make([]TableConfig, 0, len(names))
for _, n := range names {
tcs = append(tcs, TableConfig{DB: db, Table: n, Strategy: strategy})
}
return tcs
// 案例
func main() {
tables:=cacheflow.Tables(db,cacheflow.CacheAside,"users","order","xxx","xxx")
s, _ := cacheflow.StartSyncer(cacheflow.Config{
MySQL: cacheflow.MySQLConfig{Addr: "127.0.0.1:3306", User: "root", Password: "", Flavor: "mysql", ServerID: 1001},
Redis: cacheflow.RedisConfig{Addr: "127.0.0.1:6379", DB: 0},
Tables: tables, // 修改这里即可
})
defer s.Stop()
}适配微服务 :将 StartSyncer 放在服务初始化钩子里,优雅退出时调用 Stop。
内置功能
- 策略 提供两种缓存一致性解决方案,可自行选择
CacheAside:删除缓存,读时重建(默认,强最终一致性)WriteThrough:写穿,将变更数据写入缓存,更友好的读延迟,支持TTLSeconds
- Key 构造
- 默认
db:table:id - 无
id时支持KeyFields组合值;可加Prefix前缀
- 默认
- 事件接口(类似 Canal)
Subscribe(func(Event))注册回调;或消费Events() <-chan Event
- 失败重试(可选)
- RabbitMQ 生产/消费,同步失败后退避重试
- 自动
server_id- 未配置时自动生成;用环境变量
CACHEFLOW_SERVER_ID=12345覆盖
- 未配置时自动生成;用环境变量
- 监听范围
- 指定表或整个库(
Table: "*");支持批量构造Tables(db, strategy, names...)
- 指定表或整个库(
流程
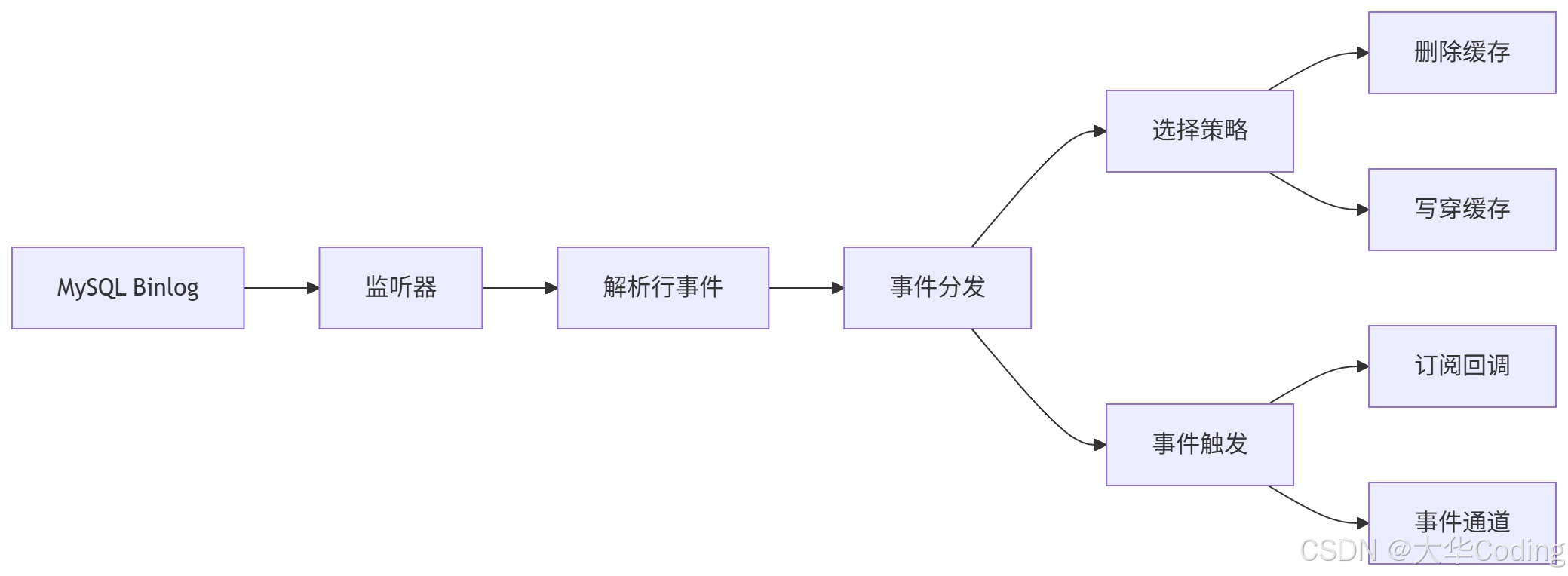
- Binlog 订阅:封装在
internal/binlog,对外不可见 - 事件处理:由
Syncer接收并分发,先执行策略,再发事件 - 位点持久化:避免重复/丢失事件
- 失败重试:将失败操作封装为消息入队,退避重试
使用示例
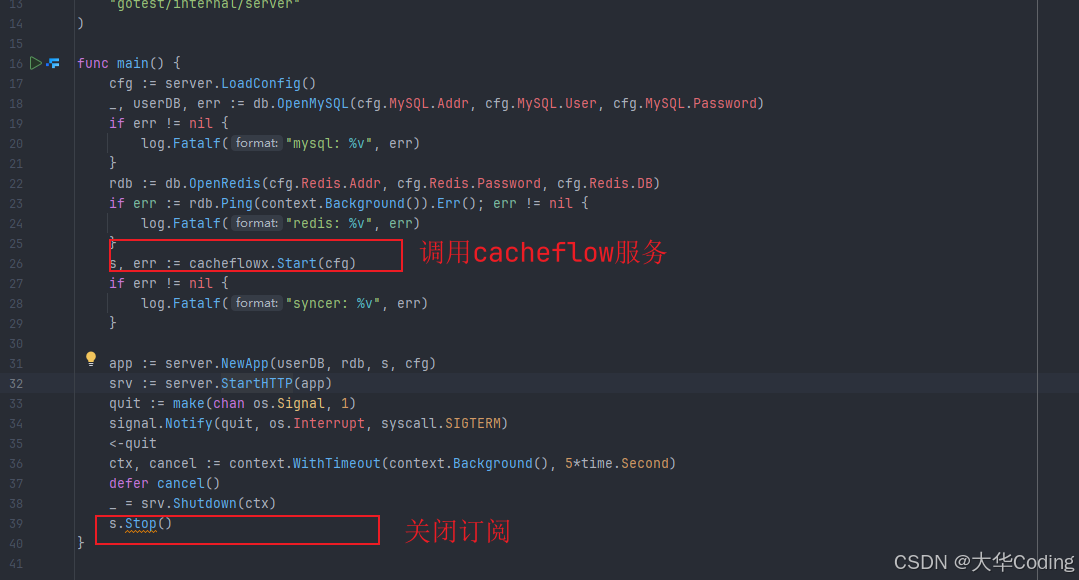
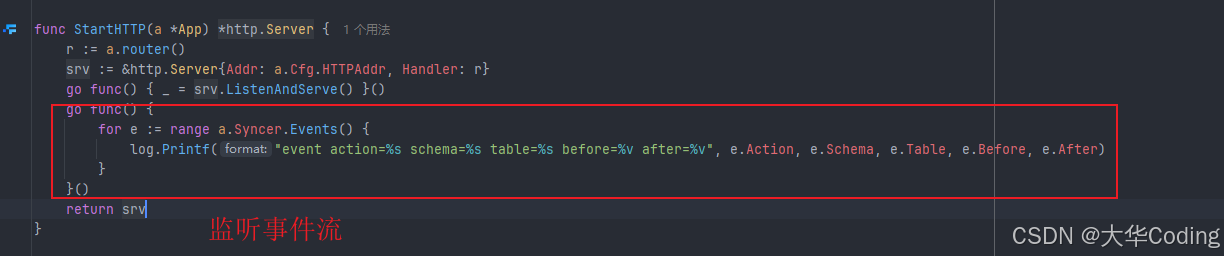
实战演示
演示流程:增加数据后,进行查询,这里需通过缓存Get,然后进行更新或删除数据,与此同时,查看缓存数据是否更新。注:此测试选择cacheflow.CacheAside的方式,也就是删除缓存的方式,做一致性同步。
删缓存演示
创建用户信息
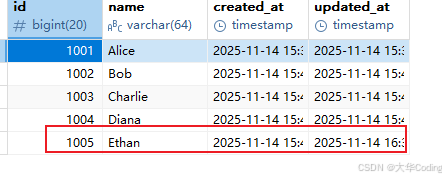

这里进行更新操作,如果没有缓存一致的话,是无法更新缓存里面的数据的,但是在启动我这个cacheflow库后,是可以更新的。
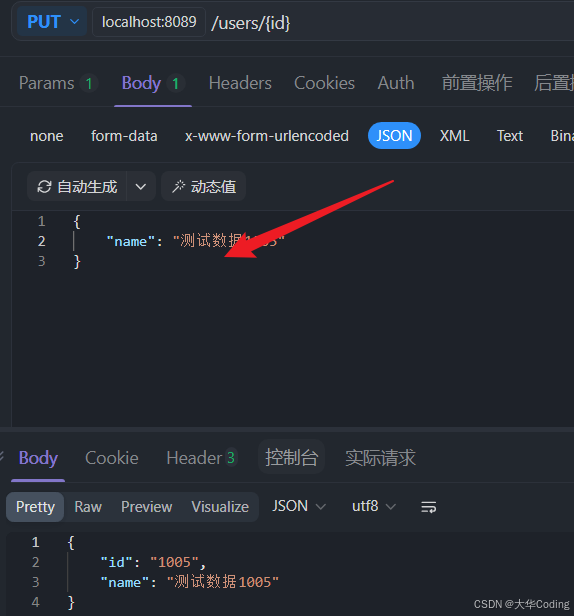

如上,已订阅到binlog日志信息,并解析。现查看缓存。

如上,已更新。在执行删除操作。

如下:

一订阅到,并且删除缓存,从而实现缓存一致性。
性能
-
事件通道 type.Event 缓冲为 1024,满载时丢弃新事件(非阻塞投递):
-
回调同步调用,耗时逻辑建议内部异步化,避免阻塞 binlog 处理
-
位点持久化默认写文件
cacheflow.pos(可改PositionPath) -
重试采用退避与最大次数控制,避免雪崩
注意事项
- 默认 Key 依赖
id字段;无id时需提供KeyFields或自定义KeyFunc - 回调是同步执行
- 事件通道可能丢弃事件(满载时),用于旁路处理不是强一致通道
- 写穿策略要关注多源更新冲突与 TTL 设计
- 目前以行级事件为主,事务级语义未做更复杂的聚合
最后
cacheflow 的核心是把缓存一致性解决方案内嵌到你的服务进程内,用最少的配置快速获得"写数据库→删缓存/写缓存"的可靠行为,同时向上开放 Canal 风格事件接口以支持旁路场景。它不试图成为一个臃肿的分布式平台,而是一个好用的能力库:可被单体服务与微服务轻松嵌入,专注于"写入之后读到正确的东西"。 -- xizhenhua77