
How to Leverage LLMs for Auto-tagging & Content Enrichment
文章摘要
本文探讨了如何利用大语言模型(LLM)进行自动标注与内容增强,以提升企业内容管理的效率与质量。通过LLM较低的初始投资和高效的标注能力,组织能够快速为现有内容添加语义元数据,从而优化知识门户和搜索解决方案。本文详细介绍了LLM自动标注的流程、技术考量及实施步骤,为企事业单位和科研院所提供实用指南
。
正文:大语言模型(LLM)在内容管理中的革新应用
一、引言:内容管理中的痛点与LLM的潜力
在当今信息化时代,企事业单位和科研院所的数据和知识管理面临诸多挑战。一个常见的障碍是现有内容的质量不足------内容可能不相关、过时或缺乏语义上下文。这种情况极大地限制了高级工具(如知识图谱、个性化搜索和高级AI解决方案)的效能。
例如,若没有适当的标签和内容分类,知识门户的开发无法充分展示内容分面和聚合的价值,难以通过搜索、过滤和聚合功能体现出真正的组织价值。
为了解决这一问题,内容的元数据标注和组织上下文的添加成为关键步骤。传统的标注方法包括手动标注、通过分类和本体管理系统(TOMS)实现的自动标注,以及内容管理系统自带的工具或混合方法。然而,这些方法往往需要较高的初始投资或耗费大量人力。
相比之下,大语言模型(LLM)以其低成本、高效率的特点,成为近期内容增强的理想选择。本文将深入探讨LLM自动标注的流程、语义价值、技术考量及实施策略,为专业读者提供全面参考。
二、LLM自动标注的核心流程
LLM自动标注的过程与其他自动标注方法有相似之处,但其独特之处在于强大的语义解析能力。以下是LLM内容增强的主要步骤:
- 内容解析与语义提取:LLM通过解析内容,识别文档中的关键短语、术语或结构,以确定其上下文 。
- 提示工程与标签匹配:通过精心设计的提示,LLM将提取的语义成分(如命名实体、关键短语)与分类术语列表进行相似度比对,返回一组可用于分类的标签。可以通过设定相似度分数阈值,调整返回标签的质量 。
- 标签存储与应用:生成的标签被导出到一个数据存储库,并通过脚本或工作流程应用于内容源系统 。
值得注意的是,LLM的选择、其知识库的范围、内容源的位置以及参数调整(如提示设计、分类术语列表)都会显著影响标注的效果和准确性。例如,EK公司在与某贸易协会的内容现代化项目中,采用上述步骤将内容迁移到新的内容管理系统(CMS)中,并通过LLM自动标注元数据字段和内容类型,显著提升了内容的可查找性和标准化水平。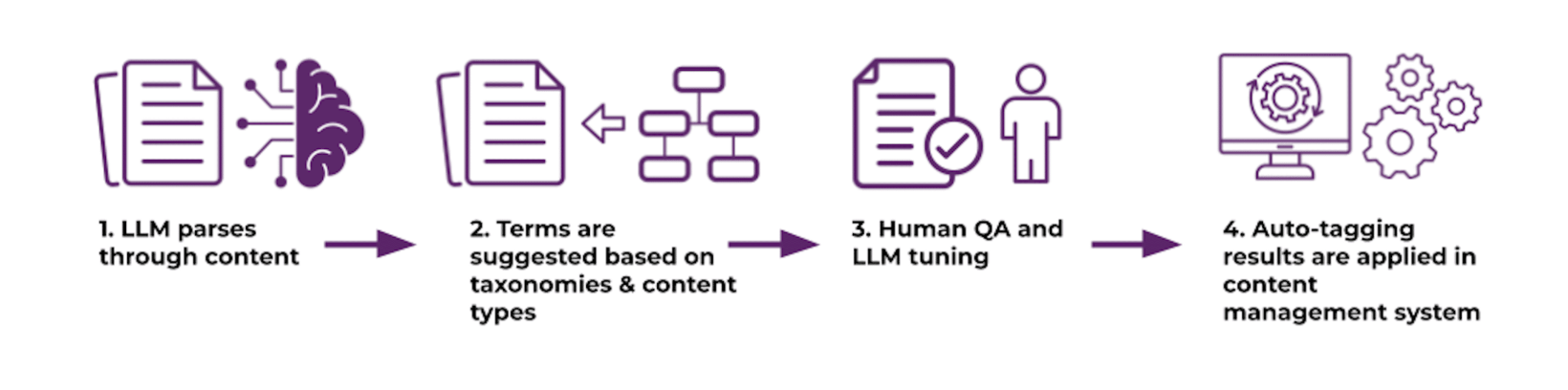
(Figure 1展示了LLM内容增强的高层步骤,建议在此处插入类似流程图以直观呈现上述步骤)。
三、语义模型在LLM自动标注中的价值
语义模型(如分类法、元数据模型、本体和内容类型)是指导LLM有效分类内容的重要输入。组织特有的上下文对LLM的训练至关重要。例如:
- 通过分类法或业务术语表为LLM提供上下文,可以避免误标。例如,将"Green Account"定义为符合特定环保标准的账户,而非与颜色或财务成功相关的账户 。
- 通过对特定术语加权、增加同义词或替代标签、提供组织特有定义,增强LLM对组织上下文的理解 。
此外,LLM方法的一个显著优势是其可进化性。随着标注结果的生成,分类法和内容模型可以不断优化,调整术语定义、层级结构或添加替代标签。同时,通过加权和提示工程等技术手段,可以提升LLM推荐术语的召回率(包含正确术语的比率)和精确率(仅选择正确术语的比率)
。例如,可以对分类术语赋予0到10的加权分数,优先使用组织偏好的术语。
四、LLM自动标注的实施考量
在实施LLM内容增强时,组织需要综合考虑时间框架、信息量、所需准确性、内容管理系统类型及期望功能等因素。以下是几个关键考量:
1. 标注准确性
LLM标签的准确性直接影响终端用户和依赖标签的系统(如搜索实例或仪表板)的体验。为确保用户信任标注内容,必须采取保障措施以提高召回率和精确率。例如,投入人力进行测试标注,并结合领域专家(SME)的输入,创建"黄金标准"标注数据集,用于训练LLM和调整术语权重,避免出现"幻觉"(事实错误或误导性内容)。
2. 内容存储库的访问复杂性
内容存储库的多样性增加了技术实施的复杂性。最佳实践是直接从内容源位置读取数据,以减少重复和下载内容的额外工作量。例如,SharePoint等平台拥有强大的API支持内容读取和标签应用,而一些较小众的平台可能缺乏类似支持。因此,在设计解决方案时,必须针对每个系统制定独特策略,以降低对终端用户的干扰。
3. 知识资产类型的多样性
LLM处理多种知识资产的能力不断提升,但复杂性的增加(如处理多种资产类型)会导致资源和时间的额外需求。例如,处理2-3页的PDF文档所需的令牌和资源远低于处理冗长的视觉或音频资产。从结构化内容标注到非结构化内容的过渡,会显著增加时间、资源和定制开发的成本。
4. 数据安全与权限管理
在使用LLM时,建议组织投资于私有或内部部署的LLM,而非公共模型,以确保文档安全性和更高的定制化能力。特别是在处理包含个人信息的用例时,内容的权限映射和标注需求分析尤为重要。此外,可以通过统一的权限系统(UES)创建集中化的政策管理系统,解决企业数据生态中数据访问、控制和合规性问题。
五、LLM标注的维护与未来发展
LLM标注解决方案的一个重要考量是长期的维护与治理。一些组织在完成初步内容增强后,结合手动标注和CMS表单维持标注标准。而对于管理多个内容存储库和系统的成熟组织,可以选择持续运营内容增强解决方案,或投资于TOMS系统。不论采用何种方法,初始的LLM内容增强都是向决策者证明语义和元数据价值的关键步骤。
通过内容标注和语义标准,组织可以进一步升级知识图谱、知识门户、语义搜索引擎甚至企业级LLM解决方案,充分展现组织价值。
六、总结与行动号召
大语言模型(LLM)为内容管理和增强提供了一种高效、低成本的解决方案,帮助企事业单位和科研院所克服内容质量不足的挑战。通过精心设计的自动标注流程和语义模型,LLM能够显著提升内容的可查找性和管理效率。本文提供的实施考量和未来发展建议,希望能为读者提供启发。
如果您的组织希望升级内容管理并开发新的知识管理(KM)解决方案,欢迎与我们联系,共同探讨更多可能性!
标签
#大语言模型 #LLM #自动标注 #内容增强 #知识管理 #KM