前端能做的
| 类型 | 可做任务 | 示例模型 | 前端场景 |
|---|---|---|---|
| 图像 | 分类、检测、分割、姿态识别、手势识别、风格迁移 | mobilenet, coco-ssd, bodypix, handpose, style-transfer | 商品识别、健身、AR、艺术滤镜 |
| 文本 | 情感分析、分类、相似度、实体识别 | toxicity, universal-sentence-encoder | 评论分析、搜索、问答 |
| 音频 | 语音识别、音频分类 | speech-commands | 语音控制、事件触发 |
| 视频 | 实时姿态/手势识别 | pose-detection, handpose | 健身动作捕捉、游戏交互 |
| 综合 | 自定义迁移学习、生成式 AI | mobilenet+自训练、pix2pix | 行业识别、内容生成 |
TensorFlow.js 是什么?
TensorFlow.js 是 Google 官方推出的前端 + 后端通用的机器学习框架。一句话总结:你可以用 JavaScript 在浏览器或 Node.js 里运行 AI(深度学习模型)。
- 完全不需要后台服务器,也不需要 Python。
- 不上传数据,隐私更安全。
- Web 端性能高,运行在 GPU/WebGL 上。
TensorFlow.js 有什么用?(真实场景)
| 应用类型 | 描述 |
|---|---|
| 人脸表情识别 | 判断是否开心、生气、惊讶 |
| 图片识别 | 判断图片里是什么(猫/狗/人/车等) |
| 摄像头识别 | 实时识别人脸、物体 |
| 手势识别 | 识别比心、点赞等动作 |
| 声音识别 | 判断"上"、"下"、"停"等指令 |
| 文本情绪分析 | 判断文字是正面还是负面 |
| 物体跟踪 | 行为识别、目标跟踪 |
TensorFlow.js 能做什么?(官方模型一览)
| 模型 | 用途 |
|---|---|
| mobilenet | 图片分类(物体识别) |
| coco-ssd | 检测多个物体并框出 |
| face-api / blazeface | 人脸检测 |
| face-expression | 表情识别 |
| handpose | 手势识别 |
| posenet / movenet | 人体姿态 |
| speech-commands | 语音命令识别 |
| toxicity | 文字攻击性检测 |
| qna | 问答模型 |
| universal-sentence-encoder | 文本向量 |
TensorFlow.js 如何使用
安装 npm install @tensorflow/tfjs
示例 1:识别图片内容
import React, { useState } from "react";
import * as tf from "@tensorflow/tfjs";
import * as mobilenet from "@tensorflow-models/mobilenet";
export default function App() {
const [result, setResult] = useState("");
const [model, setModel] = useState<any>(null);
// 加载模型
React.useEffect(() => {
mobilenet.load().then(setModel);
}, []);
const handleImage = async (e: any) => {
const file = e.target.files[0];
if (!file || !model) return;
const img = document.createElement("img");
img.src = URL.createObjectURL(file);
await img.decode();
const predictions = await model.classify(img);
setResult(
predictions.map((p: any) => `${p.className} (${(p.probability * 100).toFixed(2)}%)`).join("\n")
);
};
return (
<div>
<h2>图片识别 Demo</h2>
<input type="file" onChange={handleImage} />
<pre>{result}</pre>
</div>
);
}可识别 猫、狗、香蕉、键盘、车、人、动物等 1000 类物体。
示例 2:摄像头实时识别
import React, { useEffect, useRef } from "react";
import * as mobilenet from "@tensorflow-models/mobilenet";
import Webcam from "react-webcam";
export default function App() {
const webcamRef = useRef<Webcam>(null);
const modelRef = useRef<any>(null);
useEffect(() => {
mobilenet.load().then(model => (modelRef.current = model));
const interval = setInterval(async () => {
if (webcamRef.current && modelRef.current) {
const video = webcamRef.current.video as HTMLVideoElement;
if (video) {
const predictions = await modelRef.current.classify(video);
console.log("识别结果:", predictions);
}
}
}, 500);
return () => clearInterval(interval);
}, []);
return (
<div>
<h2>摄像头识别 Demo</h2>
<Webcam ref={webcamRef} />
</div>
);
}创建rea
ct 项目
npx create-react-app my-ai-demo --template typescript示例demo
安装命令
npm install @tensorflow/tfjs@4 @tensorflow-models/mobilenet@2 react-webcam @vladmandic/face-api
@tensorflow/tfjs@4
@tensorflow-models/mobilenet@2
@tensorflow-models/speech-commands
react-webcam示例 3:语音识别(speech-commands)
使用 CDN 才能运行:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/speech-commands"></script>
const recognizer = (window as any).speechCommands.create("BROWSER_FFT");
await recognizer.ensureModelLoaded();
const words = recognizer.wordLabels();
recognizer.listen(result => {
const scores = Array.from(result.scores);
const bestIndex = scores.indexOf(Math.max(...scores));
console.log("识别到:", words[bestIndex]);
});可识别:
"yes"
"no"
"up"
"down"
"left"
"right"
"stop"
"go"图片识别、 摄像头识别 音频检测(关键字识别)
import { useEffect, useRef, useState } from "react";
import * as mobilenet from "@tensorflow-models/mobilenet";
import * as speech from "@tensorflow-models/speech-commands";
import Webcam from "react-webcam";
function App() {
const webcamRef = useRef<Webcam>(null);
const imgRef = useRef<HTMLImageElement>(null);
const [model, setModel] = useState<mobilenet.MobileNet | null>(null);
const [audioModel, setAudioModel] = useState<any>(null);
const [imageResult, setImageResult] = useState("");
const [cameraResult, setCameraResult] = useState("");
const [audioResult, setAudioResult] = useState("");
/** -------------------------
* 初始化加载模型
--------------------------*/
useEffect(() => {
const loadModels = async () => {
const imgModel = await mobilenet.load();
setModel(imgModel);
const recognizer = await speech.create("BROWSER_FFT");
await recognizer.ensureModelLoaded();
setAudioModel(recognizer);
console.log("All models loaded!");
};
loadModels();
}, []);
/** -------------------------
* 上传图片识别
--------------------------*/
const handleUploadImage = async (e: React.ChangeEvent<HTMLInputElement>) => {
if (!model) return alert("模型加载中...");
const file = e.target.files?.[0];
if (!file) return;
const reader = new FileReader();
reader.onload = async () => {
if (imgRef.current) {
imgRef.current.src = reader.result as string;
const predictions = await model.classify(imgRef.current);
if (predictions.length > 0) {
setImageResult(
`${predictions[0].className}(置信度:${(
predictions[0].probability * 100
).toFixed(2)}%)`
);
}
}
};
reader.readAsDataURL(file);
};
/** -------------------------
* 摄像头识别
--------------------------*/
const handleCameraDetect = async () => {
if (!model) return alert("模型加载中...");
const video = webcamRef.current?.video;
if (!video) return;
const predictions = await model.classify(video);
if (predictions.length > 0) {
setCameraResult(
`${predictions[0].className}(置信度:${(
predictions[0].probability * 100
).toFixed(2)}%)`
);
}
};
/** -------------------------
* 音频识别
--------------------------*/
const handleStartAudio = async () => {
if (!audioModel) return alert("音频模型加载中...");
audioModel.listen(
(result: any) => {
const scores = result.scores;
const labels = audioModel.wordLabels();
const highest = scores.indexOf(Math.max(...scores));
setAudioResult(`检测到: ${labels[highest]}`);
},
{ probabilityThreshold: 0.75 }
);
};
const handleStopAudio = () => {
audioModel?.stopListening();
};
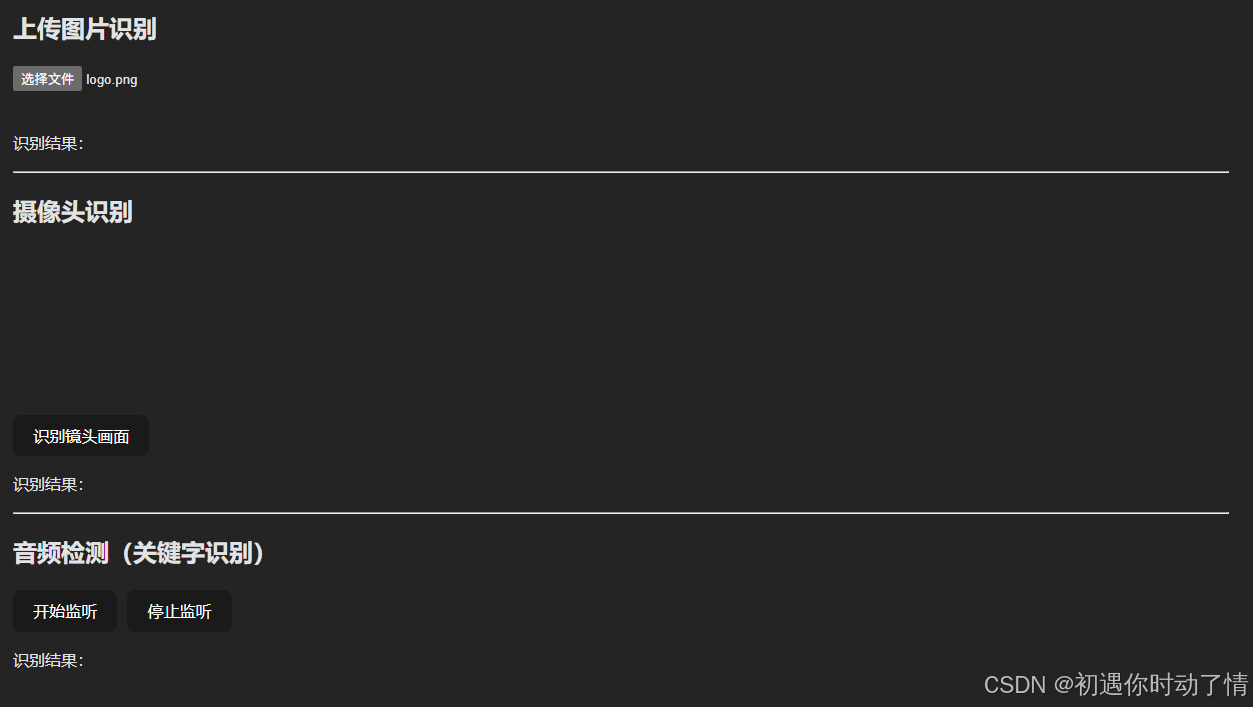
return (
<div style={{ padding: 20 }}>
<h1>TensorFlow.js Demo(上传图片 + 摄像头 + 语音)</h1>
{/* -------------- 上传图片识别 ---------------- */}
<section style={{ marginTop: 20 }}>
<h2>上传图片识别</h2>
<input type="file" accept="image/*" onChange={handleUploadImage} />
<br />
<img
ref={imgRef}
alt=""
style={{ width: 300, marginTop: 10, borderRadius: 10 }}
/>
<p>识别结果:{imageResult}</p>
</section>
<hr />
{/* -------------- 摄像头识别 ---------------- */}
<section style={{ marginTop: 20 }}>
<h2>摄像头识别</h2>
<Webcam
ref={webcamRef}
screenshotFormat="image/jpeg"
style={{ width: 300, borderRadius: 10 }}
/>
<div>
<button onClick={handleCameraDetect} style={{ marginTop: 10 }}>
识别镜头画面
</button>
</div>
<p>识别结果:{cameraResult}</p>
</section>
<hr />
{/* -------------- 语音识别 ---------------- */}
<section style={{ marginTop: 20 }}>
<h2>音频检测(关键字识别)</h2>
<button onClick={handleStartAudio}>开始监听</button>
<button onClick={handleStopAudio} style={{ marginLeft: 10 }}>
停止监听
</button>
<p>识别结果:{audioResult}</p>
</section>
</div>
);
}
export default App;