下载并安装软件

上传安装软件到服务器
解压安装:tar -xzvf hadoop-3.4.1.tar.gz -C /opt/module/
Hadoop配置
-
配置hadoop环境变量:
bashsudo vim /etc/profile.d/myprofile.sh #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.4.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_CLASSPATH=$(hadoop classpath)应用变更: source /etc/profile
-
配置hadoop使用的JAVA环境
bashsudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh # 配置Hadoop使用的JAVA路径 export JAVA_HOME=/opt/module/jdk-17.0.10 -
配置core-site.xml
bashvim $HADOOP_HOME/etc/hadoop/core-site.xmlXML<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mydoris:9000</value> <description>NameNode的地址</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop/tmp</value> <description>hadoop数据存储目录</description> </property> </configuration> -
配置hdfs-site.xml
bashvim $HADOOP_HOME/etc/hadoop/hdfs-site.xmlXML<configuration> <property> <name>dfs.replication</name> <value>1</value> <!-- 单机只需1副本 --> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> </configuration> -
配置 yarn-site.xmlbashvim $HADOOP_HOME/etc/hadoop/yarn-site.xmlXML<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
配置mapred-site.xml
bash
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
XML
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>-
解决Hadoop 3.4与JDK 17冲突问题
bash# 编辑 Hadoop 环境配置文件 cd /opt/module/hadoop-3.4.1 vim etc/hadoop/hadoop-env.sh # 文件末尾 添加以下内容: # Fix for JDK 17+ module access restrictions export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.lang=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.lang.reflect=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.net=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.util=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/sun.nio.ch=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.nio=ALL-UNNAMED" export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.util.concurrent=ALL-UNNAMED" # 若已经启动过hdfs,需要清理并重启hadoop # 停止 ./sbin/stop-yarn.sh ./sbin/stop-dfs.sh # 删除临时数据(避免 clusterID 冲突) rm -rf /tmp/hadoop-* # 重新格式化(使用 JDK 17) hdfs namenode -format # 启动 ./sbin/start-dfs.sh ./sbin/start-yarn.sh
启动Hadoop服务
格式化 NameNode(首次)
bash
./bin/hdfs namenode -format启动 HDFS + YARN
bash
./sbin/start-dfs.sh
./sbin/start-yarn.sh
验证服务
bash
jps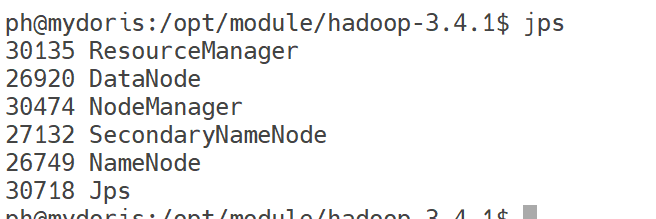
4.
查看启动日志
- 日志路径:/opt/module/hadoop-3.4.1/logs/
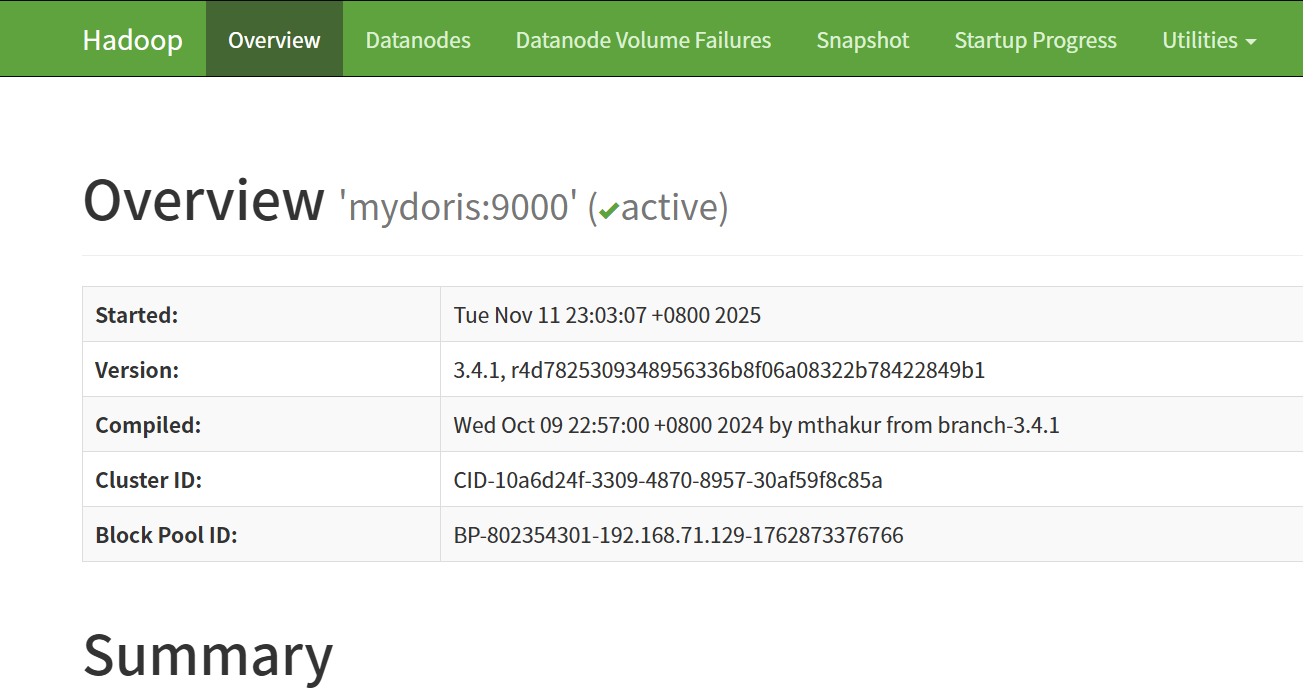
访问 WEB UI
- HDFS: http://mydoris:9870
YARN: http://mydoris:8088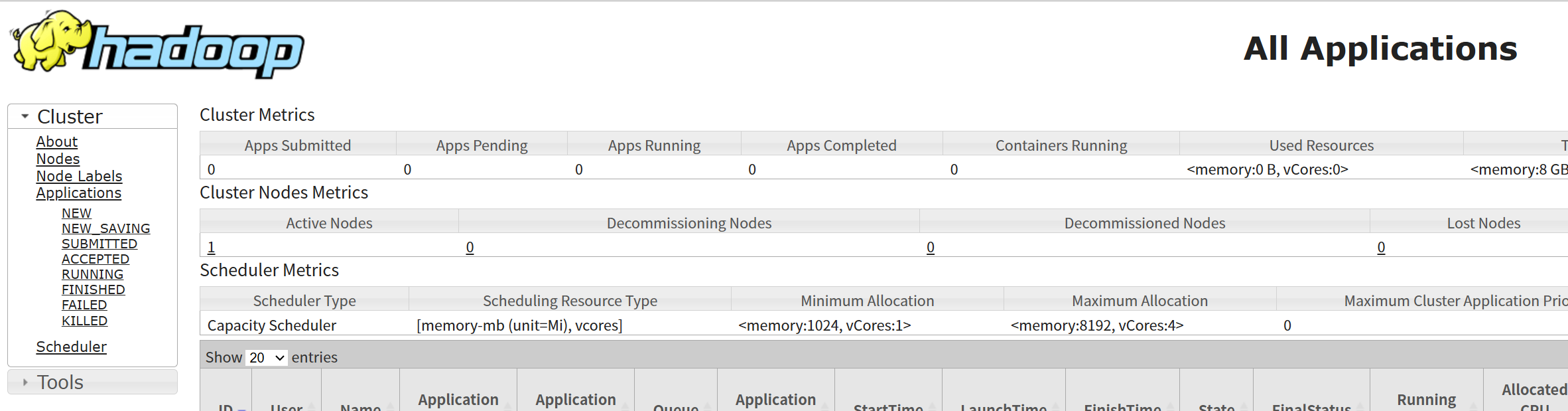
### 测试 HDFS 读写```bash
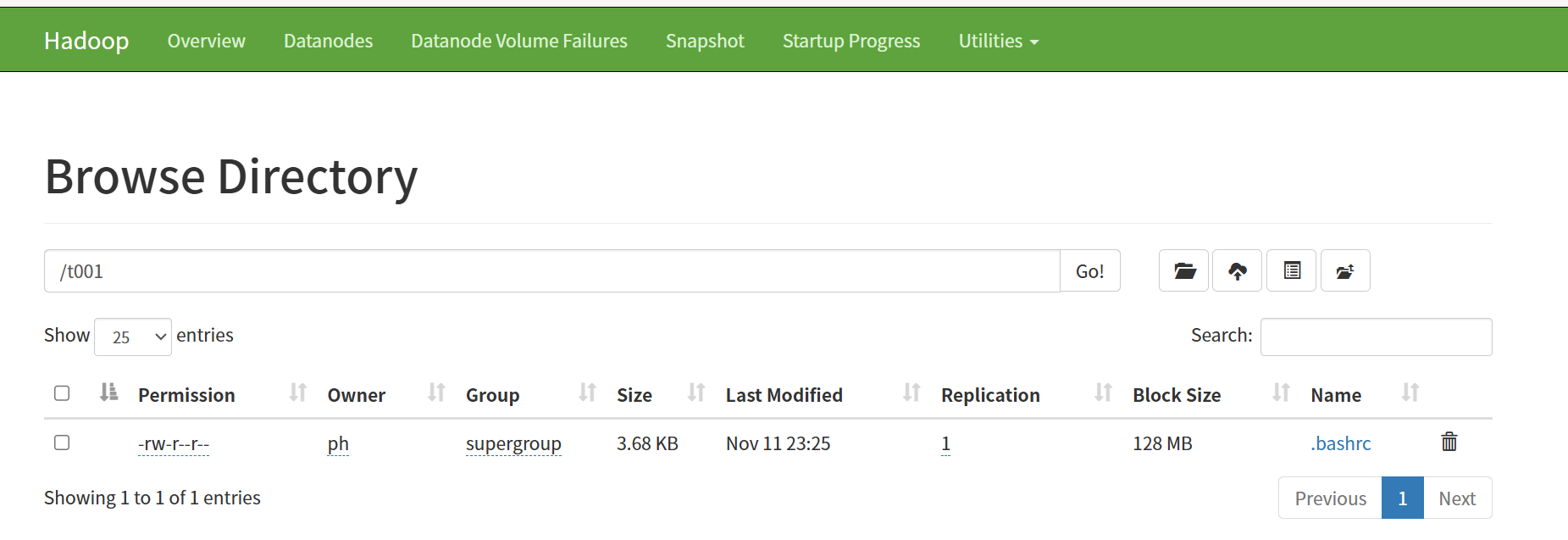
./bin/hadoop fs -mkdir /t001
./bin/hadoop fs -put ~/.bashrc /t001/
./bin/hadoop fs -ls /t001
```