Cannot serialize access for this transaction
隔离级别
隔离级别定义
ANSI 和 ISO/IEC 基于 SQL 标准定义了四种隔离级别 ,隔离级别 根据事务并发执行过程中必须防止的现象定义。
可预防的异象包括:
-
脏读(Dirty Read)
一个事务读到其他事务尚未提交的数据。
-
不可重复读(Non Repeatable Read)
曾经读到的某行数据,再次查询发现该行数据已经被修改或者删除。 例如:
select c2 from test where c1=1;第一次查询c2的结果为1,再次查询由于其他事务修改了c2的值,因此c2的结果为2。 -
幻象读(Phantom Read)
只读请求返回一组满足搜索条件的行 ,再次执行发现另一个提交的事务已经插入满足条件的行。
基于以上异象定义的四种隔离级别:
-
读未提交(Read Uncommitted)
-
读已提交(Read Committed)
-
可重复读(Repeatable Read)
-
可串行化(Serializable)
MySQL Mode 支持读已提交、可重复读两种隔离级别
Oracle Mode 支持读已提交和可串行化两种隔离级别。
两种模式下,OceanBase 数据库默认的隔离级别是读已提交。
写读并发
对某行数据而言,读写事务和只读事务并发执行,只读事务读取过程中,该行正在被读写事务修改且尚未提交,我们称之为写读并发。
该场景下,OceanBase 数据库的正确性保证逻辑如下:
读写事务 T1 提交过程中,确定 commit 成功之前,该事务的提交版本号(commit version)是无法知道的。此时如果有读事务 T2 并发读取该行,是否能够读到该事务的修改呢?需要分情况讨论:如果 T1 的提交版本号(commit version) < T2 的读快照(read version),则 T2 需要读到 T1 的修改;否则 T2 不需要读到 T1 的修改。
具体而言,如果 T1 此时尚未收到用户发来的 commit,那么 T2 的 read version 一定会小于 T1 的 commit version,因此该情况下 T2 不需要等T1提交结束;如果T1此时处于正在提交过程中,则T2需要等T1确定 commit version,才能决定是否需要读T1修改的数据。这里的等待对用户而言是透明的,因此仍能满足"写不阻塞读"的这一结论。
读写并发
对某行数据而言,读写事务和只读事务并发执行,读写事务操作该行之前,已经有只读事务对该行进行读操作,我们称之为读写并发。该场景下,OceanBase 数据库的正确性保证逻辑如下:
只读事务读取过程中,读写事务还在执行,客户端尚未发出 commit,因此 T1 的 read version 一定小于 T2 的 commit version,T1 不需要读到 T2 的修改。T1 和 T2 不会相互等待。
写写并发
写写并发场景,主要通过对行加互斥锁来实现,即前一个事务尚未提交结束,后一个需要操作同一行的事务需要等待。写写并发场景,lost update 问题是重点需要解决的。考虑事务 T1 和事务 T2,两者并发单分区表 A 中的同一行 R1,待更新的列上有局部索引。执行流程如下:
-
事务 T1 和事务 T2 语句开启,获取相同的语句快照版本号,假设均为 100。
-
事务 T1 语句执行过程中,先于 T2 获取行锁,并执行更新。事务 T2 出现行锁冲突,重试等行锁释放。
-
事务 T1 提交结束,行锁释放。
事务 T2 该如何执行?如果 T2 直接持有行锁,继续修改,将会出现数据一致性问题,因为 T2 并没有看到 T1 的修改,直接将其数据进行了覆盖。OceanBase 数据库为了解决该问题,T2 加上 R1 的行锁之后,会进行一次 Double Check,如果发现存在该问题,不同隔离级别下的处理方法不同:
-
RC 隔离级别下重试执行该语句。
-
RR可串行化隔离级别下,该语句不能重试并且需要向用户返回如下错误:
ORA-08177: Cannot serialize access for this transaction
当数据库返回 ORA-08177 时,用户可以根据业务的情况做出决定:
-
回滚事务,然后重新执行整个事务。或者,
-
提交该语句之前的事务。或者,
-
回滚到某个 save point 然后执行其他分支。
transaction error,need to rollback
OceanBase是一台内存数据库,兼容MySQL协议以及SQL协议,拥有跟内存数据库一样的属性:所有的数据都需要先写入到内存里面,但是并不会立刻落盘写入到存储里面,需要等一次合并操作,将内存里面所有的改动落盘到存储里面。所以发生这种合并操作的时候,伴随着资源的使用,也会出现问题。
查看qps、tps监控,确实那个时间段相对的系统负载要比平时高。
然后,看一下是否由于压力的问题,导致了系统发生了合并操作。
OceanBase (root@oceanbase)> show tables like '%rootservice%';
+-------------------------------------+
| Tables_in_oceanbase (%rootservice%) |
+-------------------------------------+
| __all_rootservice_event_history |
| __all_rootservice_job |
+-------------------------------------+
2 rows in set (0.02 sec)合并操作记录在__all_rootservice_event_history表中。
select * from __all_rootservice_event_history where gmt_create between '2017-09-25 16:00:00' and '2017-09-25 17:00:00' order by gmt_create;查看发生故障时间段是否发生过合并状态。
发现在故障时间点确实是存在合并操作的。通过之前的操作可以看到75是这次合并操作的序号
select count(*)
from __all_rootservice_event_history
where gmt_create between '2017-09-25 16:00:00' and '2017-09-25 17:00:00' and
value1 = 75
order by gmt_create;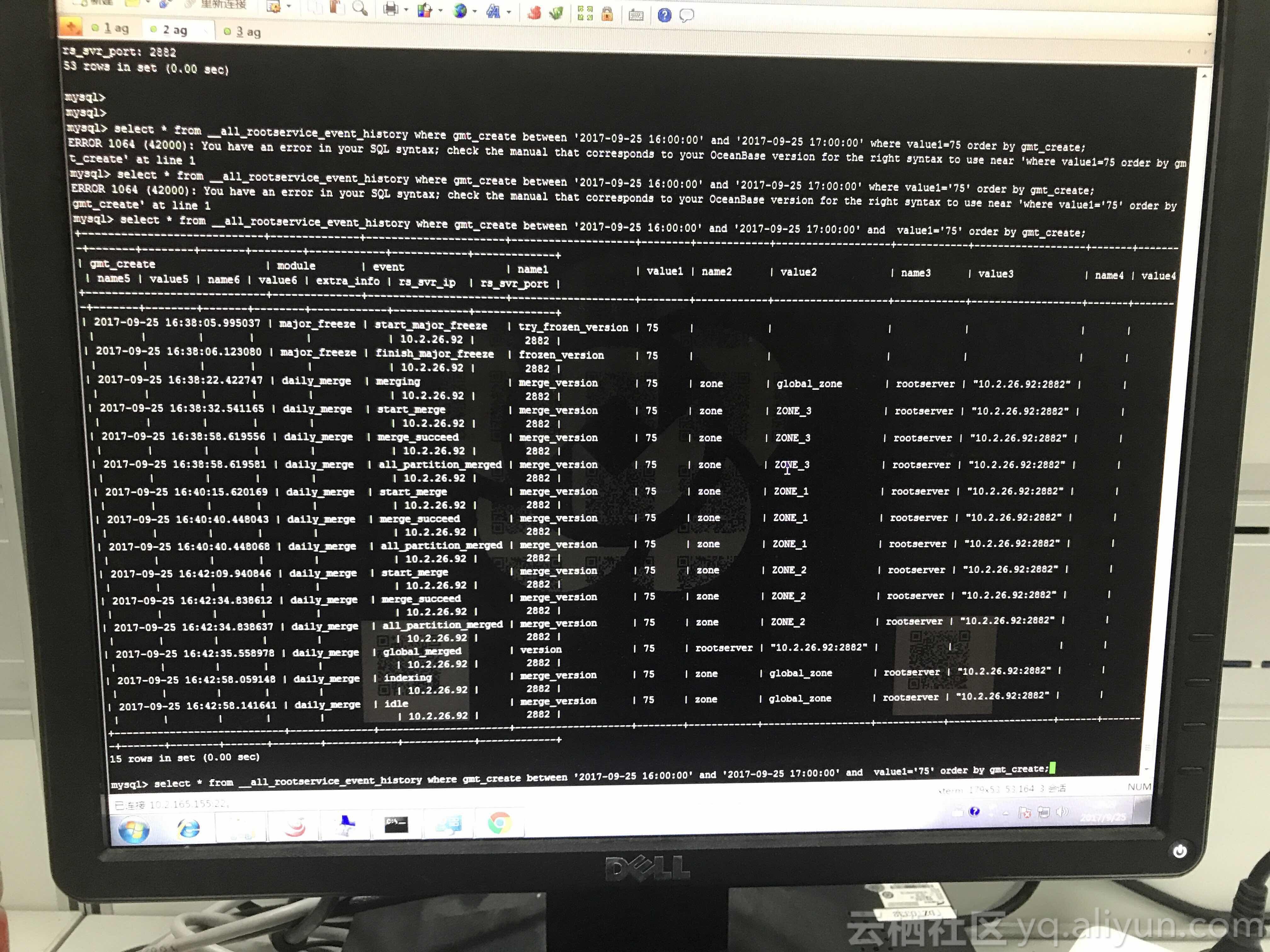
show parameters like '%turn%';发现enable_merge_by_turn打开,表示轮转合并是打开的,也就是3个zone不是同时合并,是依次合并。每个zone合并前,会把当前zone的所有leader切到别的不合并的zone,结束后再切回来
这是一次非计划的合并,说明性能测试写操作太猛,租户的memstore增长太快,达到一定阈值后就自动触发了合并操作。
Over tenant memory limits
错误码 4030 的错误信息如下。
ERROR 4030 ( HY000 ): Over tenant memory limits该错误码表示 MemStore 内存不足,该错误通常发生在 INSERT、UPDATE、DELETE 语句及 table_scan 动作等 MemStore 操作上,此时错误的日志信息不是 ERROR 级别,而是 WARN 级别。
当 MemStore 内存超限时,需要检查数据写入是否过量或未做限流。当遇到大量写入且数据转储跟不上写入速度的时候就会报这种错误。
模块内存超限,可能需要先调整单独模块的内存。如租户内存过小,也需要加租户内存。
内存爆分类
内存爆主要分为五类,可以通过关键词 OOPS 确定内存爆的类型。
| 内存爆的类型 | 日志信息(关键字为 OOPS) |
|---|---|
| SINGLE_ALLOC_SIZE_OVERFLOW | single alloc size large than 4G is not allowed(alloc_size: %ld) |
| CTX_HOLD_REACH_LIMIT | ctx memory has reached the upper limit(ctx_name: %s, ctx_hold: %ld, ctx_limit: %ld, alloc_size: %ld) |
| TENANT_HOLD_REACH_LIMIT | tenant memory has reached the upper limit(tenant_id: %lu, tenant_hold: %ld, tenant_limit: %ld, alloc_size: %ld) |
| SERVER_HOLD_REACH_LIMIT | server memory has reached the upper limit(server_hold: %ld, server_limit: %ld, alloc_size: %ld) |
| PHYSICAL_MEMORY_EXHAUST | physical memory exhausted(os_total: %ld, os_available: %ld, server_hold: %ld, errno: %d, alloc_size: %ld) |
频繁更新数据后读性能下降的排查
OceanBase 数据库的存储引擎基于 LSM-Tree 架构,以基线加增量的方式进行存储,当在一个表中进行大量的插入、删除、更新操作后,查询每一行数据的时候需要根据版本从新到旧遍历所有的 MemTable 以及 SSTable,将每个 Table 中对应主键的数据融合在一起返回,此时表现出来的就是查询性能明显下降,即读放大。
性能改善方式
对于已经运行在线上的 buffer 表问题,官方文档中给出的应急处理方案如下:
-
对于存在可用索引,但 OB 优化器计划生成为全表扫描的场景。需要进行执行计划 binding 来固定计划。
-
如果 SQL 查询的主要过滤字段无可用索引,此时推荐在线创建可用索引并绑定该计划。
-
如果业务场景暂时无法创建索引,或者执行的 SQL 多为范围扫描,此时可根据业务场景需要决定是否手动触发合并,将删除或更新的数据版本进行清理,降低全表扫描的数据量,提升速度。
另外,从 2.2.7 版本开始,OceanBase 引入了 buffer minor merge 设计,实现对 Queuing 表的特殊转储机制,彻底解决无效扫描问题,通过将表的模式设置为 queuing 来开启。对于设计阶段已经明确的 Queuing 表场景,推荐开启该特性作为长期解决方案。
ALTER TABLE table_name TABLE_MODE = 'queuing';但是社区版 4.0.0.0 的发布记录中看到,不再支持 Queuing 表。后查询社区有解释:OB 在 4.x 版本(预计 4.1 完成)采用自适应的方式支持 Queuing 表的这种场景,不需要再人为指定,也就是 Release Note 中提到的不再支持 Queuing 表。
OceanBase 3.2.3.0 GTS 无主致集群不可用:时钟跳变、重启卡 Partition 加载与 RS 选主失败
一次由历史时钟跳变触发的 GTS 服务无主故障,导致 OceanBase 3.2.3.0(1-1-1 架构)集群不可用。
应急重启→卡 PartitionGroupIndex 根因(ARM+INFO 日志 backtrace 过慢)→人工升降日志级别加速→RS 长期无主再重启→OCP 任务与状态订正→后续 chrony 优化配置。
断连接问题根因分析
当前用户请求执行的链路主要如下,请求从客户端发送到ObProxy,ObProxy将请求路由到对应的ObServer节点,ObServer处理请求发送回包给ObProxy,ObProxy回给客户端。目前整条链路上都可能发生断连接的场景,比如请求处理时间较长客户端长时间没有收到回包断开连接、用户登录填写错误的集群租户等导致无法登录、ObProxy以及ObServer的内部错误导致断开连接等等。
当断连接发生的时候,用户最直接得到的信息是ObServer返回的错误包提示,用户可以根据错误包的提示作初步的排查,这里提供的信息往往比较少,用户很难确定问题,而且一部分场景下用户无法得到错误包提示,需要排查整条链路上的问题。ObProxy针对断连接问题,提供断连接的诊断信息记录。
详情