多模态人工智能正从单一感知能力迈向视觉、音频与文本的统一融合,即全模态大模型(Omni-models)时代。然而,相应的评测体系却相对滞后。现有的评测工具不仅稀缺、各自为战,且几乎完全以英文为中心,缺乏对中文场景的有效支持。此外,一些现存的数据集在设计上存在局限性,例如部分问题的解答路径并非严格依赖于多模态信息的融合,这为科学评估模型真实的跨模态能力带来了一定的复杂性。

针对这些痛点,美团LongCat团队提出了一套高质量、多样化的一站式全模态大模型评测基准------UNO-Bench。该基准通过一个统一的框架,不仅能同时精准衡量模型的单模态与全模态理解能力,更首次验证了全模态大模型的"组合定律"------该定律在能力较弱的模型上呈现为短板效应,而在能力较强的模型上则涌现出协同增益,为行业提供了一种全新的、跨越模型规模的分析范式。这一发现的背后,是其系统性的数据构建流程:通过完全人工标注确保高质量与丰富度,有效防止数据污染。此外,该团队还引入了创新的"多步开放式问题",旨在突破传统选择题的局限,更具区分度地刻画模型在复杂链路上的推理能力。
接下来,我们将详细介绍UNO-Bench是如何构建的,以及它如何为推动下一代AI的智慧演进奠定基础。
01. 评测现状:从单模态繁荣到全模态挑战
当前,面向单模态的评测基准已发展成熟且生态繁荣。无论是针对通用视觉理解的MMBench、检验复杂数理逻辑的MathVision,还是覆盖动态视频场景的MVBench,以及在音频领域进行探索的MMAU,这些高质量的评测资源极大地推动了AI在细分维度下的认知能力发展。然而,这些资源彼此独立,难以适应向全模态大模型演进的趋势。
当我们将目光投向新兴的全模态大模型评测领域,现状则面临挑战。尽管如Gemini、Qwen-3-Omni等兼容视听双模态的顶尖全模态大模型已崭露头角,但能够有效评估其综合能力的基准却稀缺且存在明显不足。例如,OmniBench的部分数据存在错误答案,而WorldSense中由于使用音视频同步数据,大部分题目无需跨模态信息即可解答,导致难以有效衡量全模态的整合能力。
正是在这样的背景下,UNO-Bench应运而生。LongCat团队通过1250条人工标注的全模态样本和2480个增强的单模态样本,构建了一个适用于中文场景、横跨44类任务的综合性评测体系。其中,高达98%的问题被严格设计为必须在跨模态条件下才能正确解答,这弥补了现有评测无法有效检验模型真实跨模态能力的痛点,为科学评估与推动全模态大模型的发展提供了坚实可靠的基石(详见表格1)。

说明:表格中,I、A、V、T分别代表图像、音频、视频和文本模态。Acc.代表问答对的准确率,Solvable代表需要全模态才能解决的问题比例。Source代表素材来源,分为可防止数据污染的私有数据集和公开数据集。QA Type代表问答类型,MC、MO分别代表选择题和多步开放式问答。EN和ZH分别代表英文和中文。
02. UNO-Bench构建:从顶层设计到创新实现
一个卓越的评测基准始于一个科学的顶层设计。我们从定义模型核心能力体系出发,通过标准化的数据生产线确保高质量与多样性,并最终引入创新的评测方法与优化算法,共同构建了UNO-Bench的基石。
2.1 顶层设计:科学定义全模态大模型能力体系
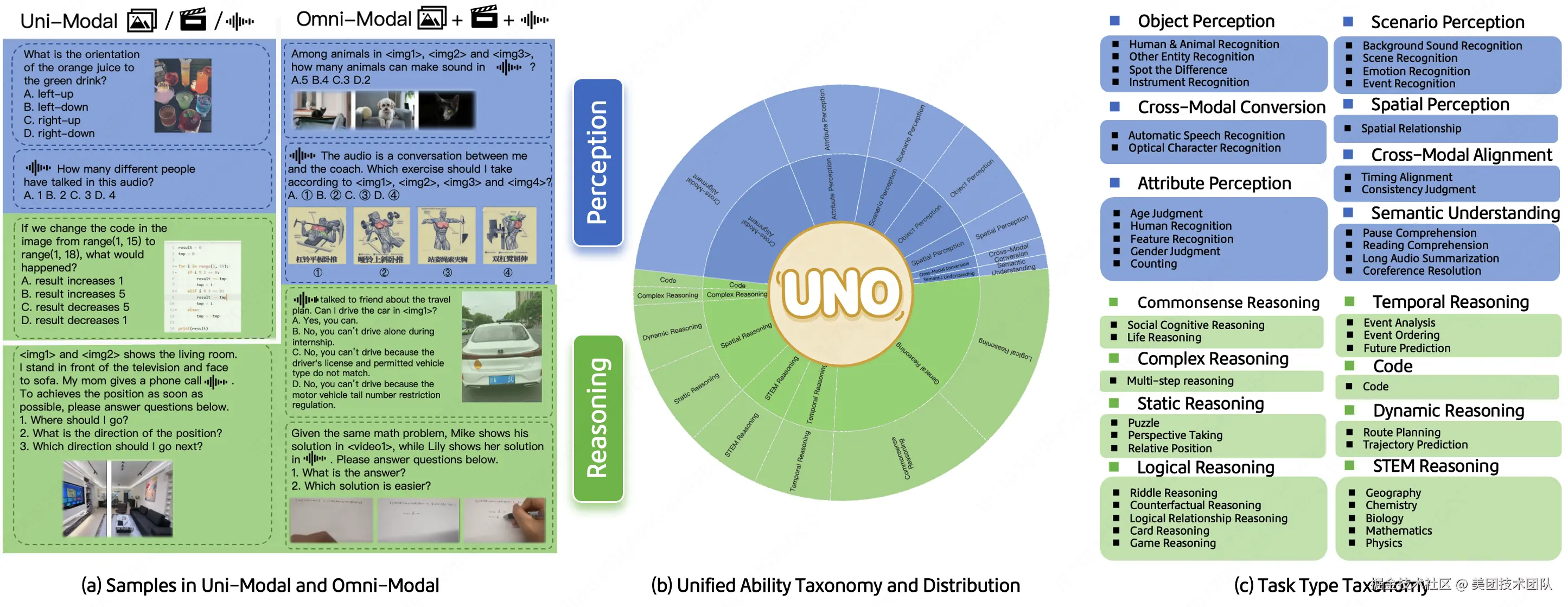
该团队首先将模型的综合智能系统性地解构为两大核心层面:感知层与推理层。
- 感知层:覆盖了从对象、属性、场景的基础识别,到空间关系判断、跨模态转换及语义理解等六大认知能力,并特别增设了跨模态对齐这一能力。
- 推理层:在通用、STEM、代码等传统推理类别之上,着重加入了空间推理、时序推理、复杂推理等更能体现全模态大模型特色的高阶推理任务。其中通用推理细拆为常识推理和逻辑推理,空间推理细拆为静态推理和动态推理。
这一双维能力框架不仅为后续的数据构建提供了清晰的蓝图,也使得对模型能力的细粒度剖析成为可能。
2.2 数据构建:标准化的高质量生产线
为确保数据的顶尖品质,LongCat团队建立了一套包含精选数据素材、专家级问答标注、严苛的多轮质检三个关键环节的标准化生产流程。所有关键对话均由超过20位真人录制,以高度还原真实世界的声学特征(如普通话、四川话等)。其中最关键的质检环节是模态消融实验:通过移除任一模态的信息来检验问题是否依然可解,以此严格确保98%以上数据的"跨模态可解性"。

说明:图(a)展示了必须结合视听信息才能解答的问题,而图(b)和图(c)则分别展示了仅凭音频或视频即可解答的问题。
通过三个小案例(a, b, c)对比,清晰地展示了什么是必须由多个模态结合才能解答的问题,以及什么是仅凭单模态就能解答的问题。
数据生产流程的核心在于:
- 针对现有数据集中普遍存在的两大问题------数据污染(视频素材可能已被模型在训练阶段"见过")和信息冗余(视频自带的音频与画面高度同步,降低了跨模态推理的难度),我们采取了独特的素材构建策略。
- UNO-Bench中超过90%私有化原创 。其中,大部分视觉素材来源于广泛的众包实拍,多样性、真实性更好的同时,也有效避免了模型因训练集覆盖而产生的"穿越"问题。
- 更关键的是,为了打破信息冗余,所有关键的音频内容(尤其是对话)均独立设计并由真人录制,然后与视觉素材进行人工组合。这种"视听分离再组合"的方式,确保了音频和视频各自承载着不可替代的关键信息,迫使模型必须进行真正的跨模态信息融合,而不是简单的同步确认。
2.3 数据优化:单模态补全与高效压缩
为构建全面的评测体系,我们不仅自建数据,还针对性地从AV-Odyssey、WorldSense等公开数据集中筛选了高质量样本进行补全(在整体全模态数据中占比11%)。此外,为降低大规模评测带来的算力消耗,我们独创了聚类引导的分层抽样法。实验证明,该方法在保持模型排名高度一致性的前提下,成功将评测成本降低了超过90%。

2.4 评测创新:多步开放式问题与通用评分模型

为了打破传统选择题无法有效评估复杂推理的局限,引入了创新的多步开放式问题(MO,Multi-step Open-ended question)。这种题型将一个复杂的长链条推理任务,拆解为多个相互依赖、层层递进的子问题,并要求模型对每一步都给出开放式的文本答案。
评分则由专家根据每一步的难度与重要性进行加权赋分(满分10分)。这种设计能够直观地揭示模型在多步推理中的能力衰减现象,从而精准地区分出模型的"浅层猜测"与"深度思考",是衡量顶尖模型推理能力的关键指标,具体示例如图5所示。
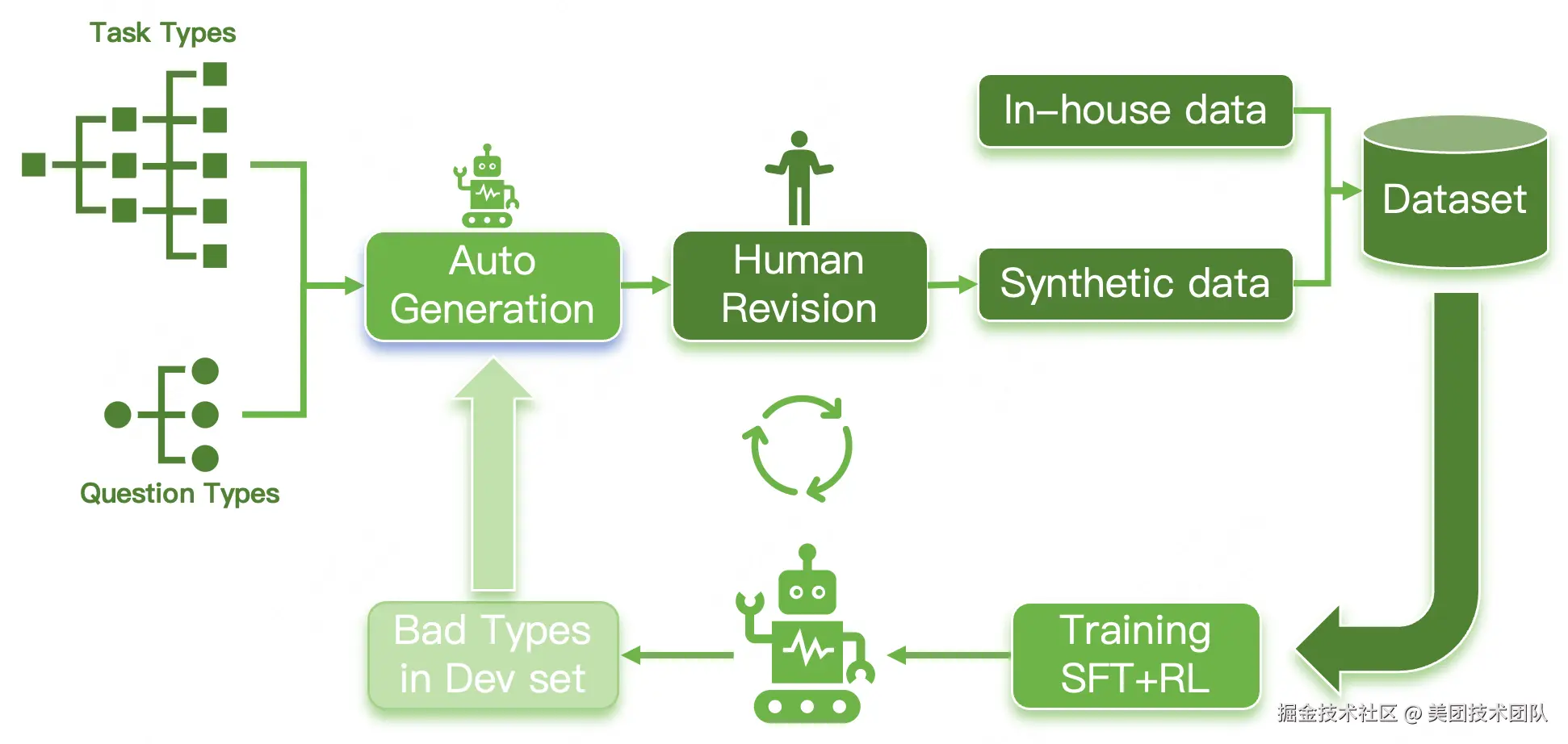
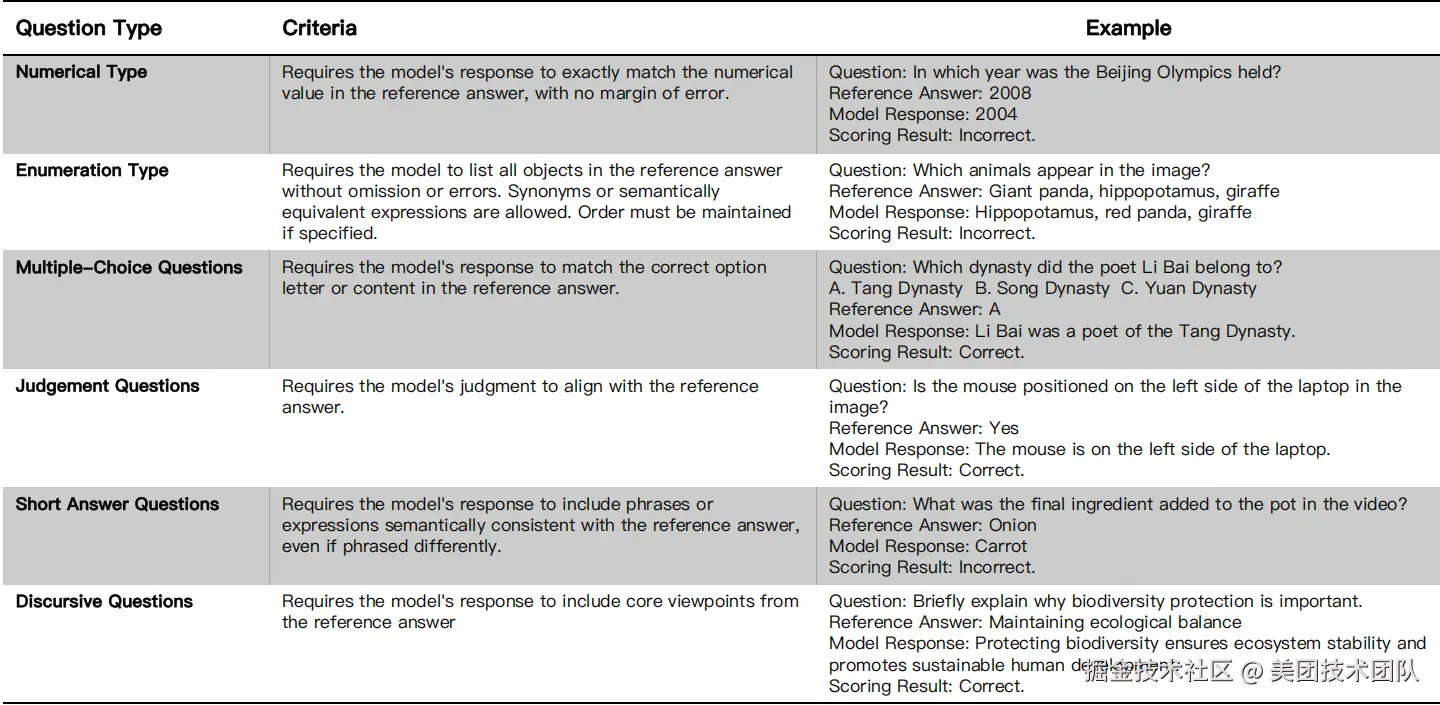
为实现自动化评估,LongCat团队还提出了一个通用评分模型,通过对问题类型进行细分(如图7所示),并结合人工和自动标注多轮质量迭代的数据集(如图6所示),使其能够支持6种通用问题类型的自动评分,在分布外的模型和基准测试中达到了95%的准确率。
03. 实验与分析:揭示全模态大模型的真实能力与演进规律
LongCat团队在UNO-Bench上对包括Qwen、Baichuan、MiniCPM以及Gemini系列在内的多款主流全模态大模型进行了全面评测。实验设计旨在回答三个核心问题:
- 当前全模态大模型的智能水平及其短板何在?
- 单模态与全模态能力之间存在何种关系?
- UNO-Bench作为一站式评估方案的有效性如何?
3.1 模型性能的全面剖析
总体格局:闭源模型优势显著,开源模型仍在追赶
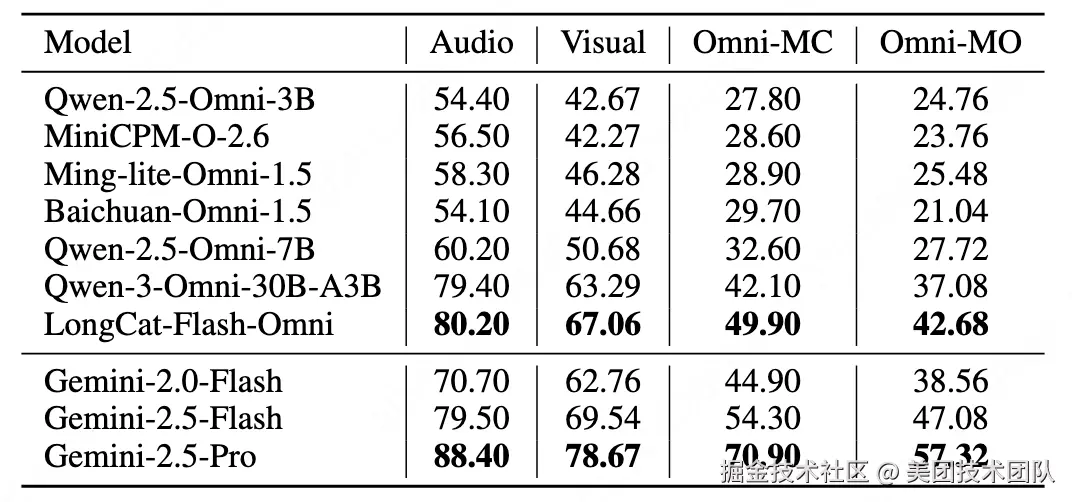
如表格2所示,在本次评测的开源模型中,LongCat-Flash-Omni表现出开源SOTA(State-of-the-Art)的成绩。该模型在音频(80.20)、视觉(67.06)、全模态选择题(49.90)以及全模态开放题(42.68)四大核心维度上,全面超越了本次评测中的其他开源模型。
与此同时,以Gemini系列为代表的闭源模型在所有评测维度上,特别是在顶尖性能层面,依然保持着领先优势,其中Gemini-2.5-Pro稳居行业标杆。当面对难度更高的"多步开放式问题"(Omni-MO)时,所有模型的性能普遍下滑,这清晰地反映出,长链条、跨模态的深度推理依然是整个AI领域亟待攻克的难题。
能力拆解:推理是区隔强弱的核心维度
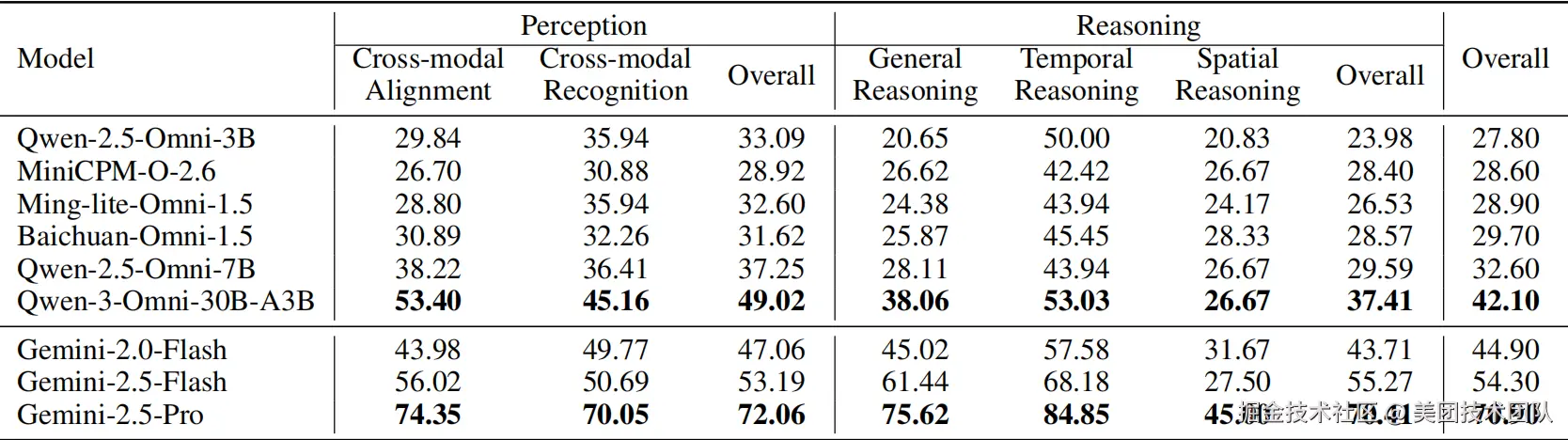
通过对感知与推理能力的细化分析(见表格3),我们发现:
- 感知层面,跨模态同步对齐比单纯的跨模态识别更具挑战。
- 推理层面,空间推断是所有子任务中最难的一项,即使是表现最佳的Gemini-2.5-Pro得分也仅为45分。
综合来看,模型的感知能力相对较强,而真正的性能差距主要体现在推理能力上。以Qwen-3-Omni-30B与Gemini-2.5-Pro为例,两者在感知能力上相差23分,但在推理能力上的差距则拉大到33分,这表明:推理能力是划分模型强弱的关键分水岭。
顶尖梯队与人机对比剖析
LongCat团队进一步对Gemini-2.5-Pro的卓越表现进行了剖析。一方面,这得益于其强大的单模态基础能力;另一方面,其内置的语音转写并自然融入推理链路的能力,是多数开源模型尚不具备的。
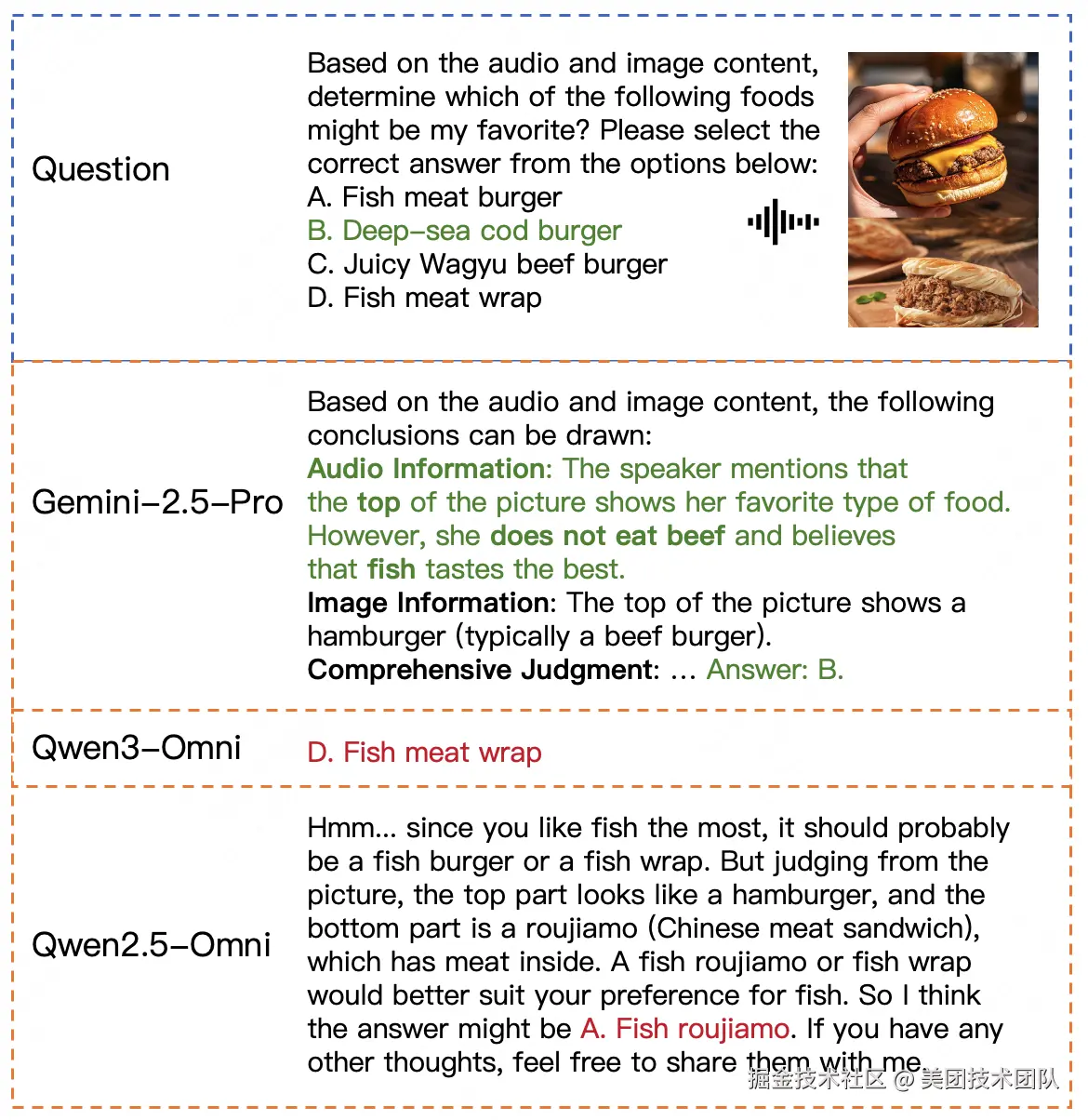

说明: Gemini-2.5-Pro在感知能力上与人类相当,但在推理能力上仍有差距。
如图9所示,观察到一个有趣的现象:
- 感知能力媲美人类:在全模态的感知任务上,Gemini-2.5-Pro的表现已能与人类专家相当。
- 推理能力仍存差距:然而,在更复杂的推理任务上,人类专家(81.3%)的表现依然优于Gemini-2.5-Pro(74.3%)。这揭示了AI与人脑在抽象归纳和复杂逻辑处理能力上的本质区别。
3.2 全模态与单模态的内在关联
得益于UNO-Bench统一的能力体系与高质量数据,通过回归与消融实验,揭示了单、全模态能力间的深刻关系。
"组合定律"成立,且遵循幂律协同
我们对各模型的单、全模态得分进行了回归分析,发现了一个强关联性,并将其形式化为一个科学定律。
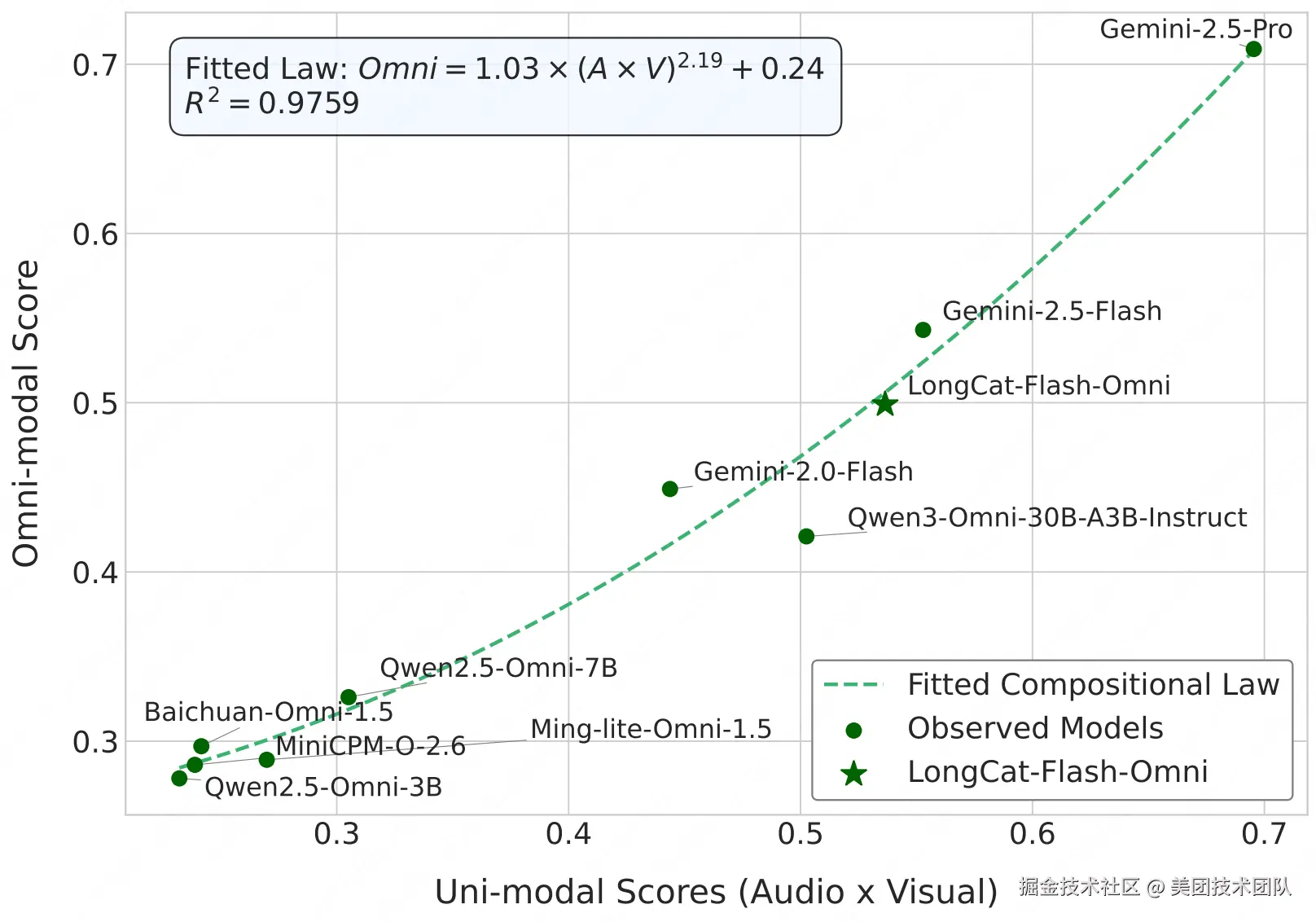
如图10所示,全模态的性能并非单模态能力的简单线性叠加,而是遵循一种乘积规律。通过严谨的数学推导和非线性拟合,得到了一个拟合度高达**97.59%**的幂律公式:
POmni ≈ 1.0332 · (PA × PV)^2.1918 + 0.2422
该幂律公式的指数大于1,使得函数曲线呈现为一条加速上升的凸形。这完美地解释了两种现象的涌现:
- 短板效应 (Bottleneck Effect):对于能力较弱的模型,其全模态性能的增长相对平缓。
- 协同增益 (Synergistic Promotion):对于顶尖模型,单模态能力的增强会带来全模态性能的爆发式增长,实现了真正意义上的"1+1 >> 2"的多模态协同增益。
更重要的是,这个"组合定律"提供了一种全新的、跨越模型规模的分析范式。它允许研究人员将不同参数规模、不同架构的模型放置在同一个坐标系下进行比较,不再仅仅关注各自的绝对得分,而是通过它们在幂律曲线上的相对位置,来统一度量其"模态融合效率"。一个模型如果显著高于拟合曲线,则意味着其模态融合机制更为高效;反之,则可能存在融合瓶颈。这为评估和优化全模态大模型的内在融合能力,提供了一个极具价值的分析工具。
从图10的具体模型分布来看,其中参与拟合的模型由圆点表示,新增的LongCat-Flash-Omni模型表现较为突出。虽然Gemini系列的具体参数规模未知,但可以观测到LongCat-Flash-Omni的表现已非常接近Gemini-2.5-Flash,并显著领先于Qwen3-Omni-30B。其位置正处于曲线加速上升的"协同增益区",且与理论拟合曲线高度吻合,这表明该模型展现出了高效的多模态融合能力。
消融实验验证
这再次印证了多通道互补与融合是通往更高智能的必经之路。
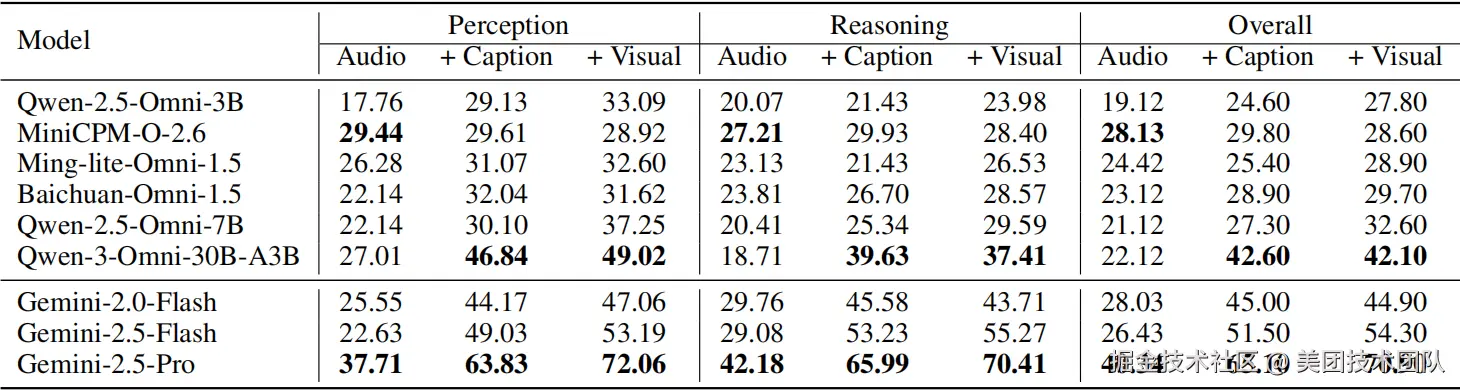
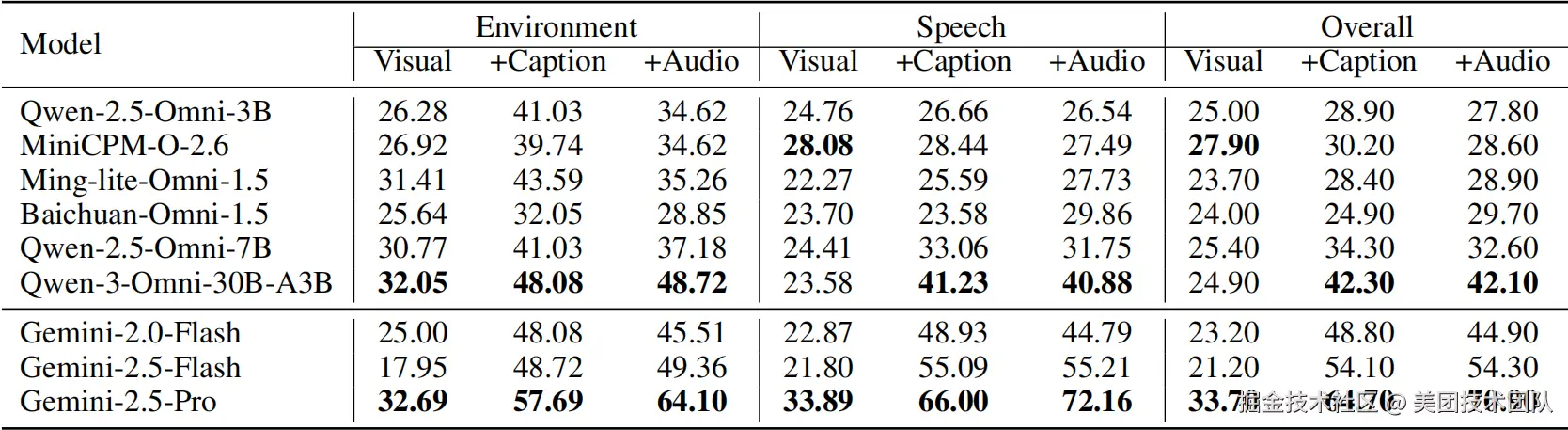
LongCat团队通过详尽的视觉与音频消融实验(具体数据参见表格4、5)进一步验证了这些发现。实验表明,对于多数模型,提供文本描述(Caption/ASR)比直接处理原始视听信息能获得更好的效果,但顶尖模型如Gemini-2.5-Pro则能从原始信号中提取比文本更丰富的信息。
3.3 UNO-Bench基准的有效性验证
除了核心的实验发现,UNO-Bench作为一个评测基准本身的科学性和有效性,也通过以下几个方面得到了验证。
多步开放式问题的卓越区分度
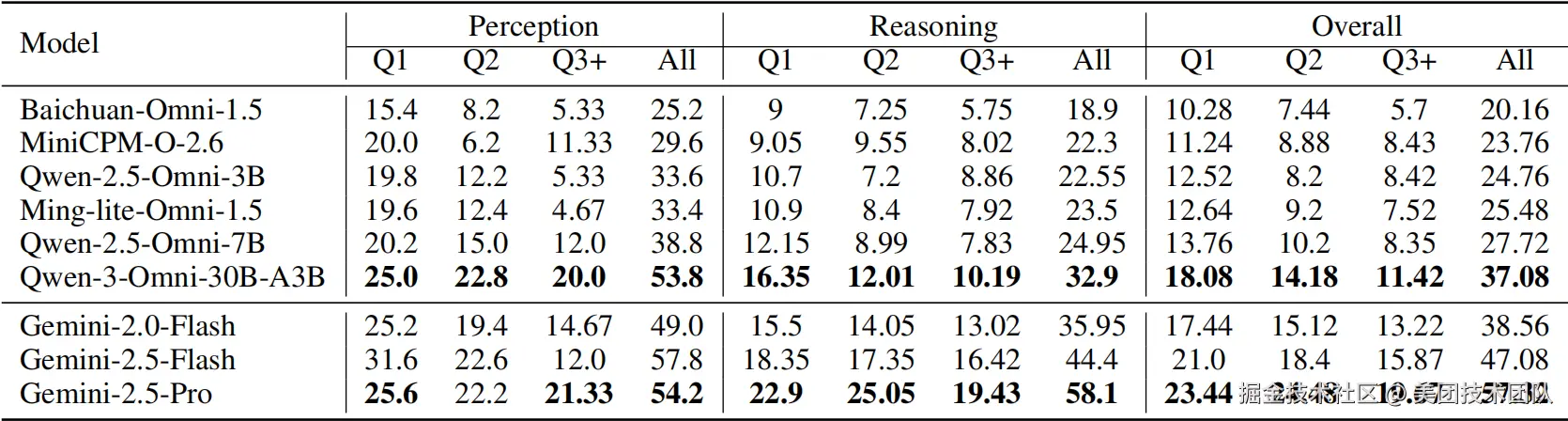
如表格6所示,创新的MO题型能够真实地刻画模型在长链条推理中的能力衰减,有效放大了模型间的认知鸿沟。
高效的数据集压缩算法
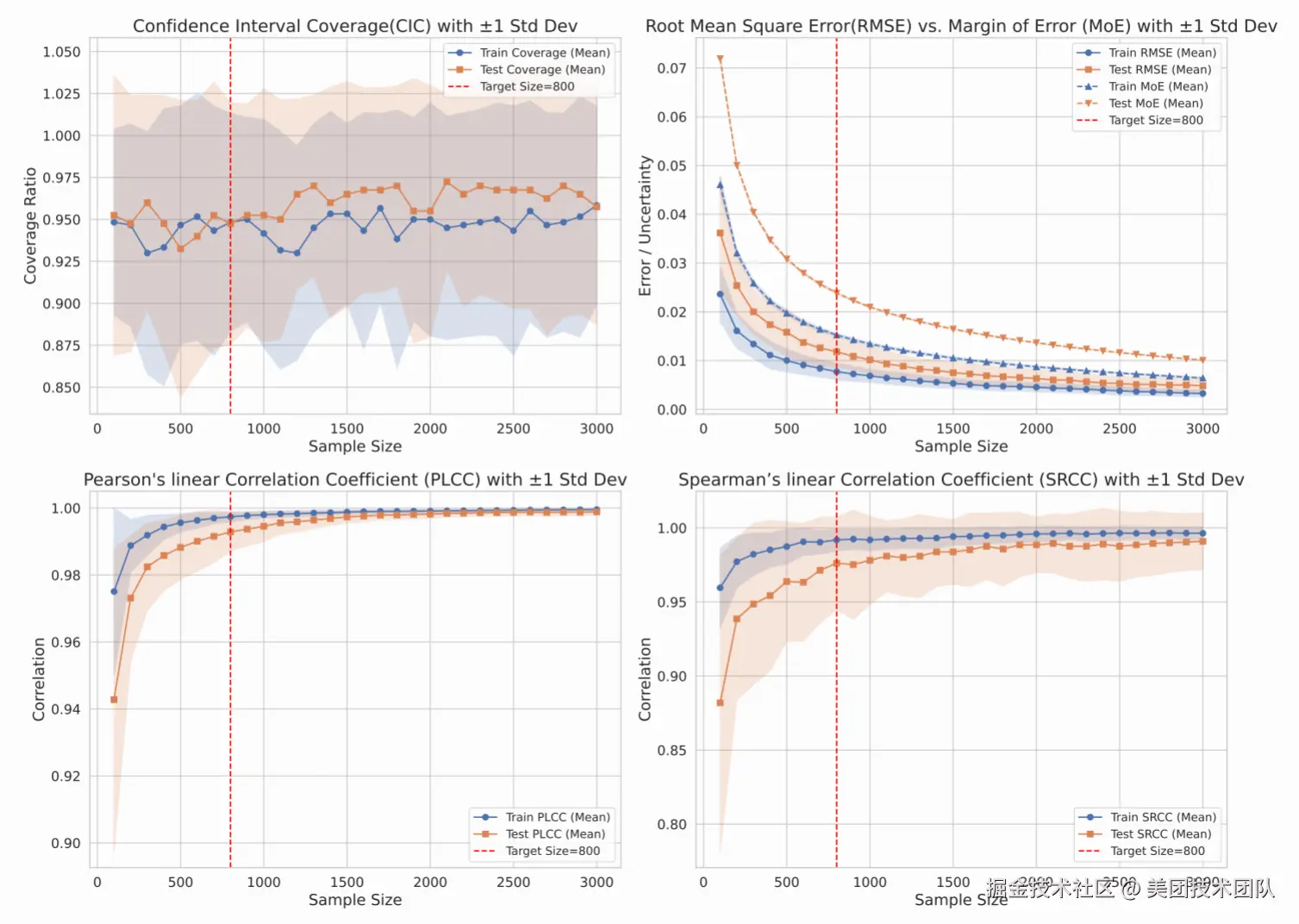
如图11所示,我们设计的聚类引导抽样法,能在保持模型排名一致性(SRCC/PLCC > 0.98)的前提下,将评测算力消耗降低超过90%,实现了效率与准确性的平衡。
卓越的数据质量与区分度
一个评测基准的有效性,最终体现在其数据的质量和区分模型优劣的能力上。UNO-Bench在这两方面都表现出色。
- 首先,在数据质量上,如前文表格1所示,UNO-Bench的全模态数据集问题准确率达到了100%,且有高达98%的问题被严格设计为必须跨模态才能解答,这确保了评测的公平性和对模型真实能力的有效检验。
- 其次,在区分度上,UNO-Bench的设计能够清晰地揭示不同模型间的性能梯度。
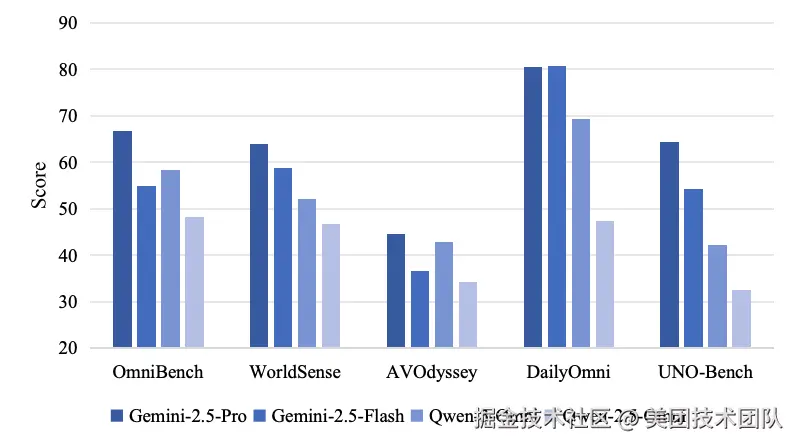
而在与其他全模态基准的直接对比中(如图12所示),UNO-Bench的有效性也得到了进一步验证。它不仅通过更高的得分标准差(19.5 vs. 12.75)展现了比OmniBench更强的区分能力,还通过合理的难度设置,避免了像AV-Odyssey那样所有模型得分被压缩在狭窄低分区间的窘境。这确保了UNO-Bench既能有效评估当前模型,也为未来更强模型的涌现预留了足够的成长空间,是一个更可靠和富有洞察力的评测工具。
04. 总结与展望
本文提出了一站式全模态大模型评测基准------UNO-Bench。该基准通过科学的评测框架,首次揭示了多模态智能并非简单的线性叠加,而是遵循着一种乘积规律,这一规律在能力较弱的模型上体现为瓶颈限制,而在顶尖模型上则表现为协同增益的特性,这个全模态大模型的"组合定律"为行业提供了一种全新的、跨越模型规模的分析范式。LongCat团队的评测结果进一步表明,以Gemini为代表的闭源模型在单模态及跨模态理解上仍远超主流开源阵营,其顶配版本虽在感知能力上已逼近人类专家,但在复杂的推理层面仍存在亟待突破的空间。而这些发现,正是得益于UNO-Bench自身的较高的数据质量与创新的评价机制,它有效扩展了模型表现的区分度,为新一代智能体的持续成长奠定了坚实基础。
面向未来,LongCat团队将通过自动化人机共建流程持续扩充数据规模,引入STEM、Code等更具挑战性的场景,并深入探索模态间的互动关系,为下一代通用人工智能的发展开辟新路径。
开源资源
- GitHub :github.com/meituan-lon...
- Hugging Face :huggingface.co/datasets/me...
- 论文下载 :github.com/meituan-lon...
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。