如今,大语言模型(LLM)已成为我们学习和工作中的常用工具。当你在对话框输入问题时,或许会好奇,这些模型为何能精准、迅速地生成回答?本文将用通俗易懂的语言,为你拆解背后的核心工作流程。
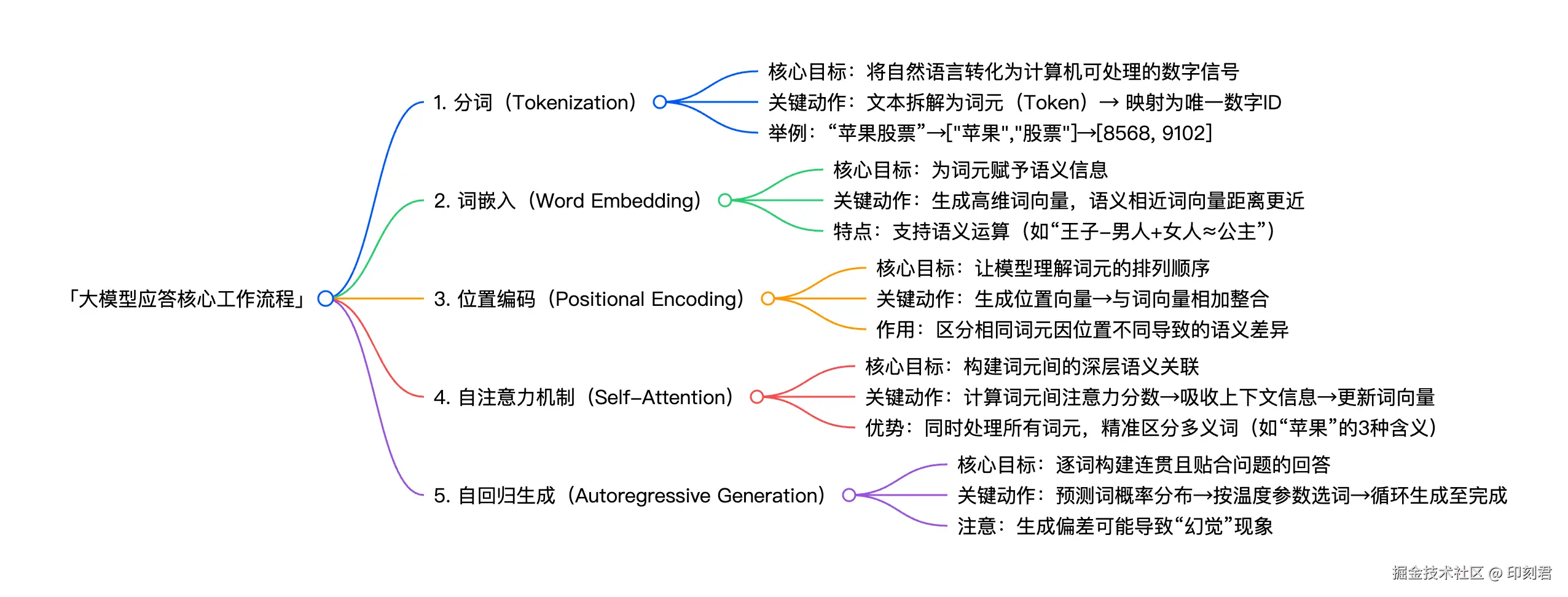
简单来说,大模型处理问题主要包含五个关键环节,分别是:
- 分词(Tokenization)
- 词嵌入(Word Embedding)
- 位置编码(Positional Encoding)
- 自注意力机制(Self-Attention)
- 自回归生成(Autoregressive Generation)
这些专业名词虽然看起来吓人,但只要理清它们各自要解决的核心问题,理解起来其实并不难。
我是印刻君,一位探索 AI 的程序员,关注我,了解更多有温度的轻知识,有深度的硬内容。
1. 分词(Tokenization):将语言转化为数字信号
计算机无法直接处理自然语言,仅能识别和处理数字。因此模型接收问题后,首要任务是分词 (Tokenization) ------将文本拆解成一系列有意义的基本单元,也就是词元 (Token)。这是后续所有处理的基础。
举个例子,输入文本:"沙特王子喜欢买苹果股票,女人喜欢用苹果拍照,仓鼠喜欢吃苹果。三个苹果区别在哪里?"。
分词后会得到:["沙特", "王子", "喜欢", "买", "苹果", "股票", ",", "女人", "喜欢", "用", "苹果", "拍照", ",", "仓鼠", "喜欢", "吃", "苹果", ...]
完成分词后,每个词元会被映射到唯一的数字 ID。假设模型词典中 "沙特" 对应 1345、"王子" 对应 5369、"苹果" 对应 8568,那么部分词元序列会转化为数字串 [1345, 5369, ..., 8568, 9102, ...]。
需要注意的是,此时模型仅获得文本的数字化形式,尚未理解语义。比如句中三个 "苹果" 的 ID 完全相同(均为 8568),模型无法区分其具体指向 ------ 是苹果公司、苹果手机,还是作为水果的苹果。
2. 词嵌入(Word Embedding):为词元赋予意义
仅靠数字 ID 无法表达词元的含义,第二步 词嵌入(Word Embedding) 就是为每个词元生成包含语义信息的数学表示 ------词向量(Word Vector)。
词向量本质是高维空间中的坐标点,由一串浮点数组成。例如简化版 "苹果" 词向量为:[0.12, -0.45, 0.67, 0.88, ..., -0.24](真实维度通常达数百甚至数千维)。你可将其理解为 "语义空间" 中的精准定位,核心特点是:语义越相近的词,空间坐标越靠近。
为了更直观理解,我们可以参考简化的二维坐标系:
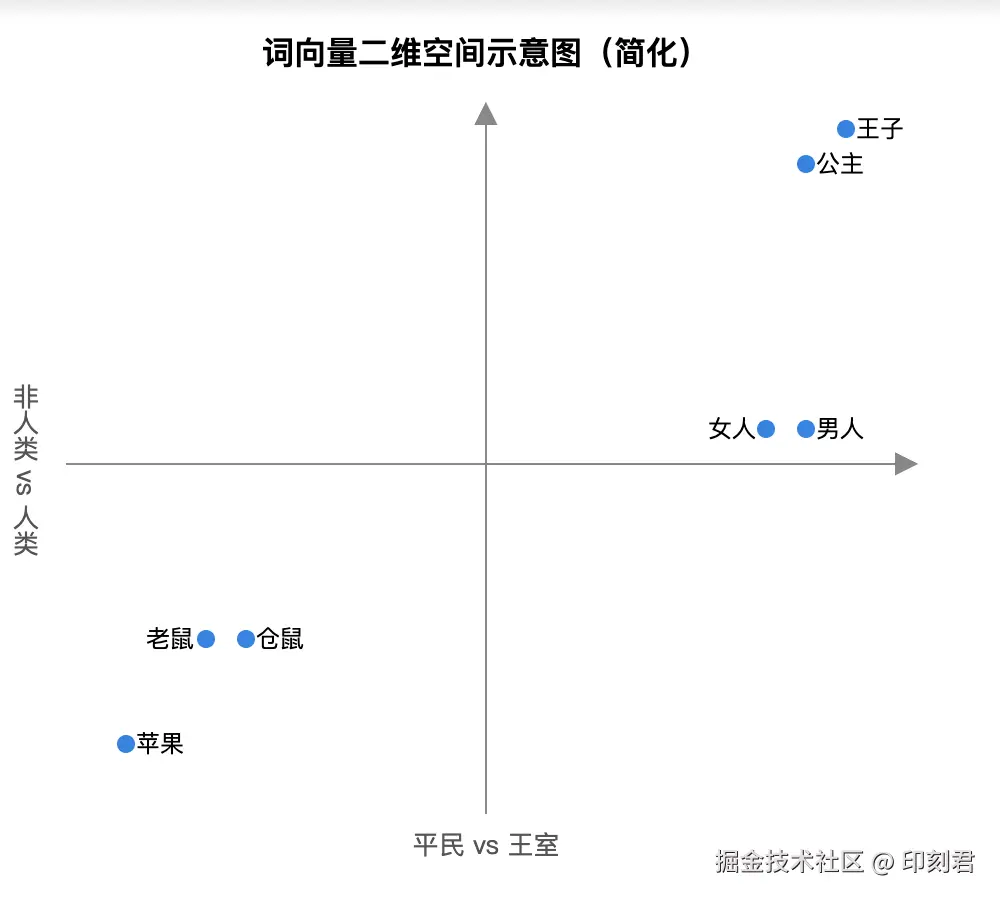
从简化图中能看到,"王子""公主" 聚集在右上角,二者语义相近;"老鼠""仓鼠" 则聚集在左下角,与 "王子" 的语义差异较大。
更有趣的是,这些向量支持有意义的数学运算,比如 王子 - 男人 + 女人 ≈ 公主。这意味着模型不仅能学习词义,还能捕捉词与词之间的逻辑关系(如性别、身份差异)。
对于 "苹果" 这类多义词,此阶段会生成融合多种含义(公司、设备、水果)的通用向量,其具体含义将在后续步骤中结合上下文进一步精准定义。
3. 位置编码(Positional Encoding):引入位置概念
词序直接决定句意,"仓鼠喜欢吃苹果" 与 "苹果喜欢吃仓鼠" 的含义天差地别。为让模型理解词元的排列顺序,第三步需引入位置编码(Positional Encoding) ------ 为序列中每个位置生成独特的位置向量,再与对应词元的词向量整合(通常为相加)。
然后,这个位置向量会与对应位置的词向量进行整合(通常是相加)。举个简化的例子,假设:
简化示例:
- 词向量("苹果")=
[0.1, 0.2, 0.3, ...] - 位置向量(第 5 个位置)=
[0.0, 0.5, 0.1, ...] - 整合后向量 =
[0.1, 0.7, 0.4, ...]
整合后的向量同时包含语义信息(来自词嵌入)和位置信息(来自位置编码)。即便三个 "苹果" 词元相同,因所处位置不同,最终向量也会存在差异,为后续区分含义提供基础。
4. 自注意力机制(Self-Attention):构建深层语义联系
完成前三步后,模型已获得含语义和位置信息的词元向量,但还需理解词元间的关联,才能掌握句子深层含义。目前主流大语言模型(如 GPT 系列)均基于 Transformer 架构构建,其核心正是自注意力机制(Self-Attention Mechanism)。
在 Transformer 出现前,旧模型采用逐词顺序处理模式,存在明显缺陷:理解当前词元时,仅能依赖前文信息,无法提前获取后文内容。以三个 "苹果" 为例:
- 读到第一个 "苹果" 时,仅能看到 "沙特王子喜欢买",无法判断是公司、手机还是水果;
- 读到第二个 "苹果" 时,虽看到 "女人喜欢用",但未看到 "拍照" 前仍无法确定是电子设备;
- 第三个 "苹果" 也需结合后文 "吃" 才能精准判断为水果。
这种 "单向语境" 不仅难以捕捉长距离语义关联,计算效率也较低。而 Transformer 抛弃循环结构,允许模型同时处理所有词元,核心就在于自注意力机制------每个词元会 "审视" 序列中所有其他词元,计算 "注意力分数"(衡量关联强度),并根据分数从其他词元中吸收有效信息,更新自身向量表示
简单来说,就是每个词元,都会关注上下文,结合上下文信息明确自身含义。
回到示例:
- 第一个 "苹果" 会重点关联 "王子、买、股票",向量被修正为 "公司 - 苹果";
- 第二个 "苹果" 会聚焦 "女人、用、拍照",向量更新为 "设备 - 苹果";
- 第三个 "苹果" 会关联 "仓鼠、吃",向量定义为 "水果 - 苹果"。
这一过程会在模型的多层 Transformer 模块中反复进行,不断精炼语义理解,最终形成对句子全面、深刻的认知。
5. 自回归生成(Autoregressive Generation):逐词构建连贯回答
在充分理解输入信息后,模型开始生成回答。它并非先构思完整提纲再落笔,而是采用 "边写边想" 的模式,从第一个词开始,逐个拼接出完整回答,这就是 "自回归生成"------ 简单说,就是 "写一个词,再根据这个词写下一个,循环直至回答完成"。
还是以 "三个苹果区别" 的问题为例,模型生成答案过程如下:
- 预测概率分布,确定开头第一个词:模型先明确问题核心是 "区分三个'苹果'的含义",随后在词汇库中计算所有词作为回答开头的 "可能性",形成概率排行。
| 词元 | 概率 |
|---|---|
| 三个 | 40% |
| 这 | 25% |
| 第一个 | 15% |
| 不同 | 8% |
| 无关词 | ... |
-
采样与选择开头词(温度参数影响选择):模型从概率排行中选择第一个词,"温度(temperature)" 参数决定选择方式。低温模式(0.1,偏保守)会直接选概率最高的 "三个";高温模式(1.5,偏灵活)可能选概率较低但更有画面感的 "这"。
-
循环生成(逐词接写,直到完成):选好第一个词后,它会被加入 "上下文",模型基于 "已写词语 + 原始问题" 继续预测下一个词,循环往复。
以低温模式为例:
- 输出:"三个",预测下一个词排行:"苹果"(60%)>"场景"(10%)→选 "苹果"
- 输出:"三个苹果",预测下一个词:"的"(55%)>"分别"(20%)→选 "的"
- 输出:"三个苹果的",预测下一个词:"区别"(70%)>"含义"(15%)→选 "区别"
- 输出:"三个苹果的区别",预测下一个词:"在于"(45%)>"是"(25%)→选 "在于"
- 输出:"三个苹果的区别在于",预测下一个词:"指代"(30%)>"对应"(20%)→选 "指代"
- 输出:"三个苹果的区别在于指代",预测下一个词:"不同"(50%)→选 "不同"
- 输出:"三个苹果的区别在于指代不同",预测下一个词:":"(35%)→选 ":"
如果生成中出现偏差,比如低温模式下第 7 步错把冒号预测为逗号,后续可能变成 "三个苹果的区别在于指代不同,第一个苹果指代苹果手机"(本该是 "苹果公司").
模型会基于 "苹果手机" 继续写:"第一个苹果指代苹果手机,适合沙特王子购买股票...",后续内容全跟着错,这就是模型 "幻觉" 现象的一种表现。
总结:大模型应答的核心流程
- 分词 (Tokenization):将输入文本分解为数字化的词元序列。
- 词嵌入 (Word Embedding):将每个词元ID映射到高维语义空间中的一个向量。
- 位置编码 (Positional Encoding):为词元向量注入序列位置信息。
- 自注意力机制 (Self-Attention):通过计算词元间的关联度,动态更新每个词元的向量表示,使其融入上下文信息。
- 自回归生成 (Autoregressive Generation):基于最终的理解,逐个词元地预测并构建出完整的回答。
整个过程虽涉及复杂的数学计算,但其核心目标是就是人类理解语言、思考并作出回应,希望我的文章,让你更清晰地看懂大模型的工作原理。
我是印刻君,一位探索 AI 的程序员,关注我,了解更多有温度的轻知识,有深度的硬内容。