
InfiniteTalk 是一个能根据音频生成无限时长人物说话/唱歌视频的AI模型,无论是给现有视频配音,还是让静态图片"开口说话",还是让人物图片"唱歌",它都能实现精准的唇形同步和自然的肢体动作。
今天分享的 InfiniteTalk V2版 ,基于上个版本 的工作流更新升级,新增了适合新手小白操作的WebUI,如果是使用ComfyUI且下载过上个ComfyUI的老司机,无需下载这个版本。WebUI支持自定义切换Wan主模型和InfiniteTalk 模型,网盘自带Q4和Q8两个版本,大家根据自己的显卡切换。当前WebUI只支持单人生成,下个版本会集成双人版。
下载地址:点此下载
核心特点
全维度同步
不仅唇形与音频匹配,还会自动生成对应的头部转动、身体姿态和面部表情,让虚拟人物更生动。
传统配音工具只调整嘴唇,而InfiniteTalk连肢体语言一起模拟。
无限时长生成
支持超长视频生成(如1小时以上),通过分段处理技术保证连贯性。
普通AI视频模型通常限制在几十秒内。
双模式输入
视频+音频:给现有视频换配音(如翻译配音、内容修改)。
图片+音频:让一张静态照片"开口说话"(如虚拟主播、教育视频)。
高稳定性
相比同类模型(如MultiTalk),显著减少了手部扭曲和身体变形的问题。
多分辨率支持
兼容480P和720P,可根据设备性能选择清晰度。
应用领域
影视娱乐:电影配音、短视频角色配音、虚拟偶像直播
数字人生成:一键生成数字人视频,助力小白进军自媒体
教育科普:定制化教学视频、历史人物"亲口"讲解
商业宣传:品牌虚拟代言人自动生成多语言宣传片
社交娱乐:让自拍照片念台词、生成个性化生日祝福视频
使用教程: (建议N卡,显存8G起,建议cuda≥12.8)
整合包包含所需所有节点,下载主程序和模型(ComfyUI文件夹即为模型),解压主程序一键包,将ComfyUI文件夹移动到主程序目录下即可。
ComfyUI模式
双击启动ComfyUI,进入页面后,点击左侧的 工作流,选择对应的工作流(包含单人+多人+视频驱动视频三种模式),根据需要选择。上传需要生成的人物图片和音频文件,设置相关参数,运行即可。ComfyUI模式,建议专业人士使用,小白可以使用下面的WebUI模式。
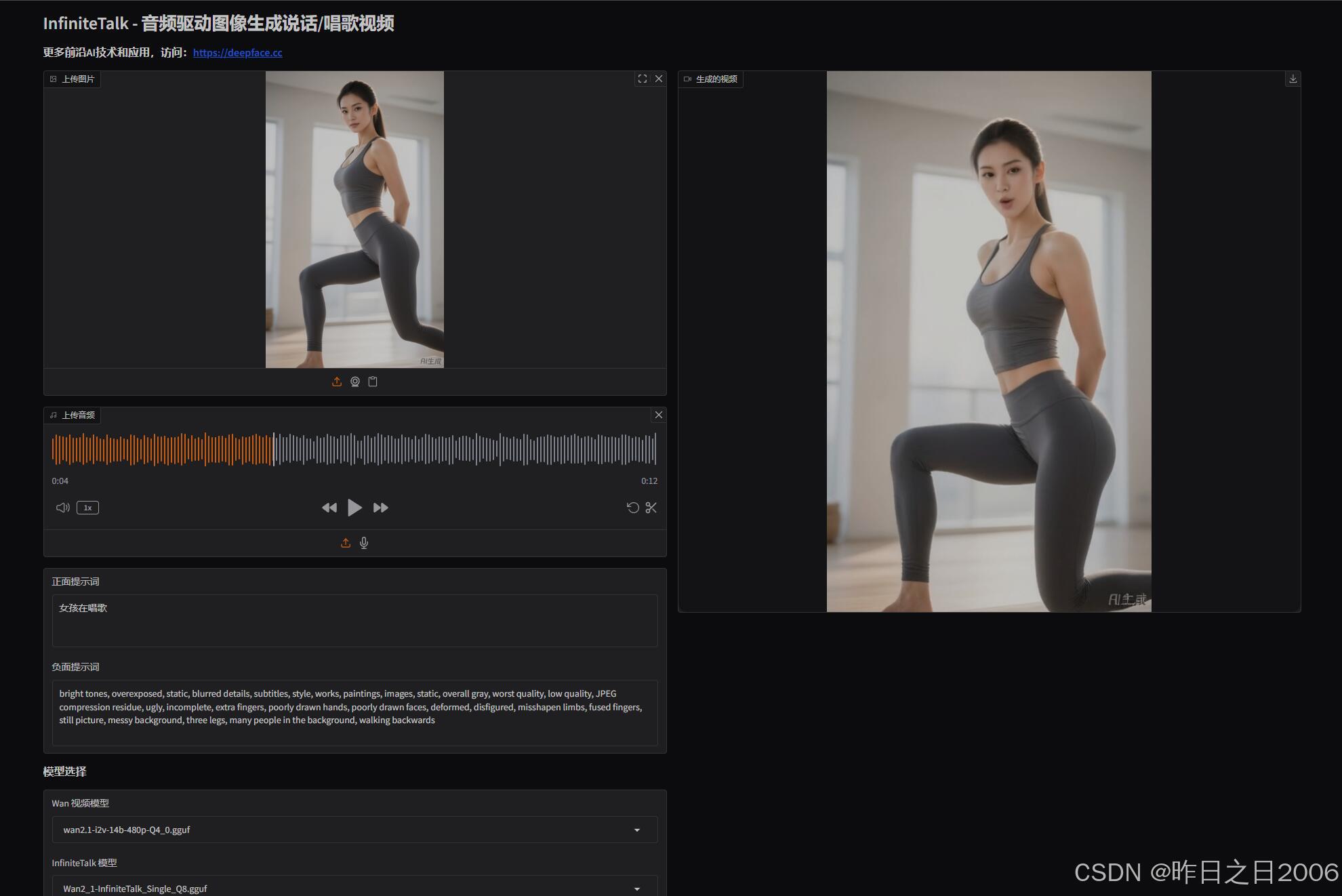
WebUI模式
双击启动WebUI,进入页面后,上传需要生成的人物图像和音频文件,设置相关参数,生成即可。
这里说下几个参数,显卡好的,可以下载精度更高的模型,比如 Wan 视频模型 和 InfiniteTalk 模型;加速模式这个参数,默认开启sag加速,如果卡在采样报错,请切换至sdpa或者手动 安装vc编译器;交换块大小默认是20,如果显卡好,比如4090或5090等,可以改成40。
InfiniteTalk 模型可以根据显卡选择,显存8G的可以切换到Q4版,显存≥12G的,建议使用Q8版。其他版本可以 移步此链接 ,下载后,放到ComfyUI\models\diffusion_models 目录,网页端切换即可。