源代码仓库
惜哉剑气疏/programs_0![]() https://gitee.com/zirui-shu/programs_0
https://gitee.com/zirui-shu/programs_0
项目前瞻
目标网站:
https://www.jiansheku.com/search/enterprise/
爬取的是图中的公司信息数据。
此文章多讲解了调用堆栈的使用。
JS逆向过程实现
首先,老规矩:找到目标动态数据并构建基本的爬虫代码:

并且得到输出结果:
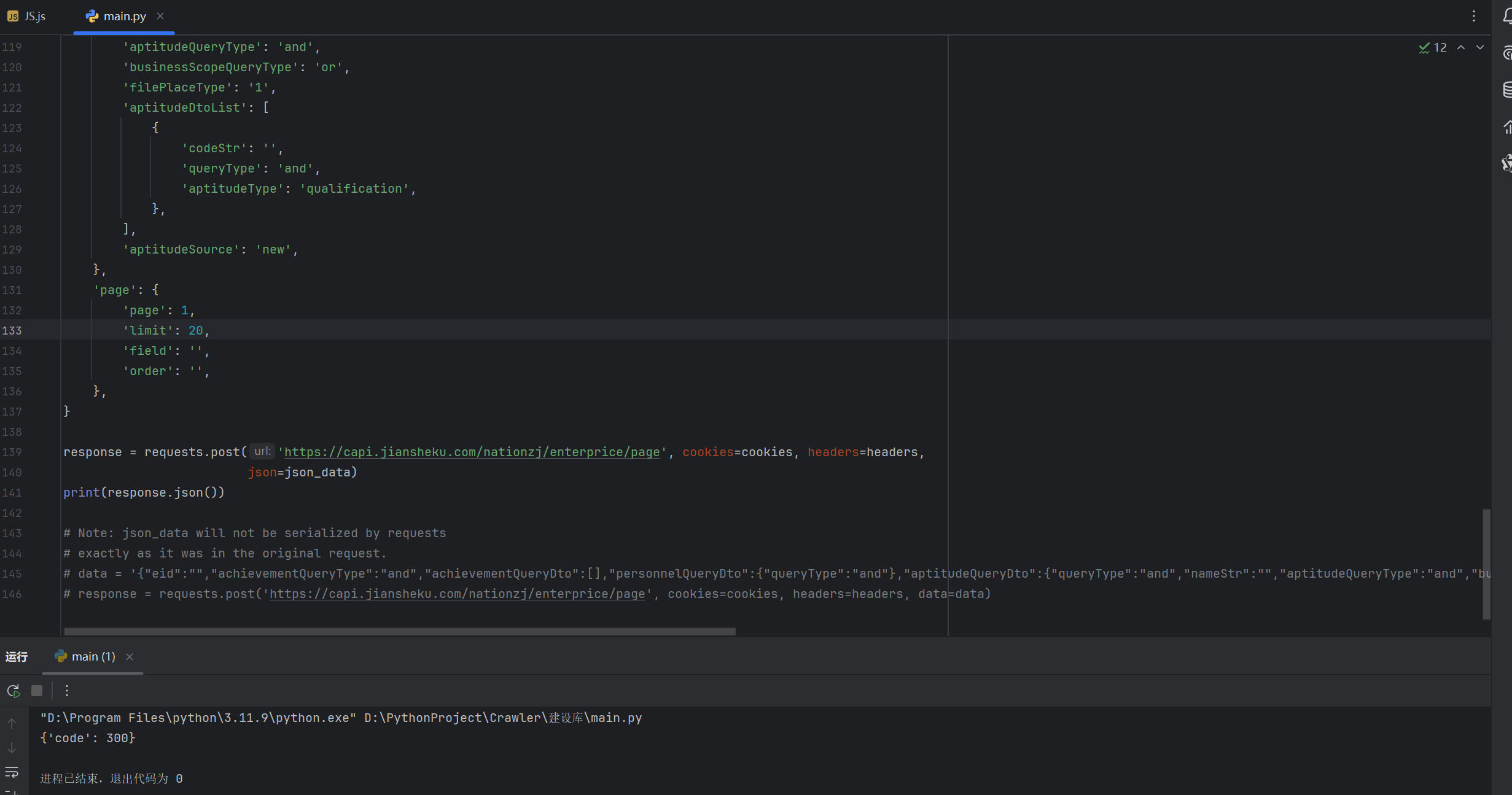
很显然,返回的300状态码是错误的,也就是说我们构建的基本爬虫代码是不够的。而在对文件进行观察之后,发现请求头有两个特殊的数据:

一个是标签 一个是时间戳。它会根据我们的时间动态生成两个数据以阻止我们的爬虫程序。
调出文件的调用堆栈:

前面两个导出函数不用管它。点击Promise.then后面的第一个函数链接,进入到发送请求的函数里,打上断点并刷新页面:
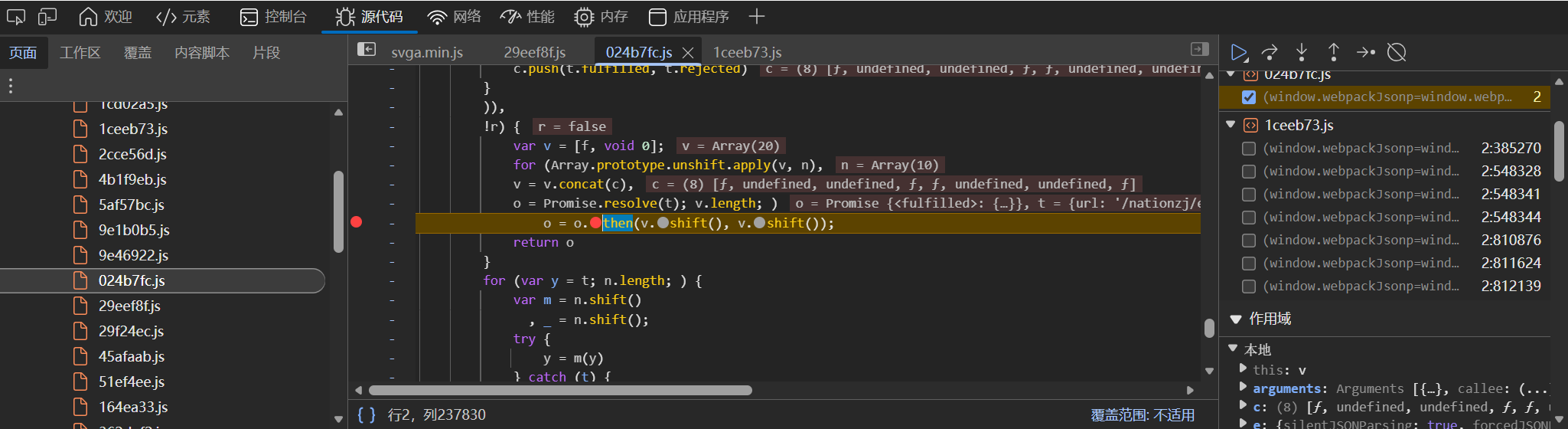
在右侧的作用域->本地可以看到:
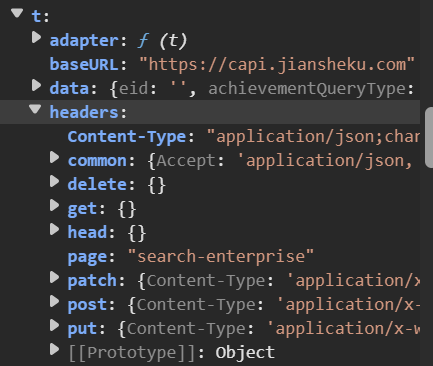
说明这个t变量跟请求头数据生成有关。再结合刚刚在调用堆栈看到的v.request,以及在本地里所见:
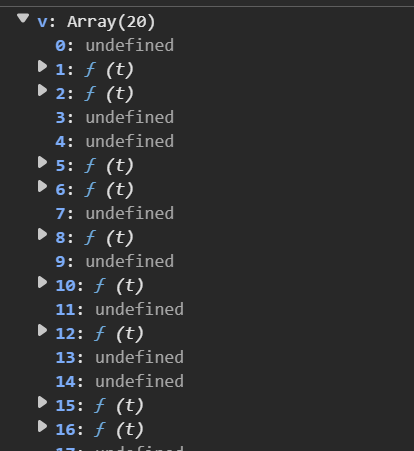
基本可以确定所需要的函数就在v里面了。找出v数组里面对应方法的函数体打上断点(注意函数名包含request 关键字,包含response 的是响应与数据生成无关)。去掉之前在调用then时的断点,重新加载页面并不断调试断点,最终出现两个变量时停在图中的页面:
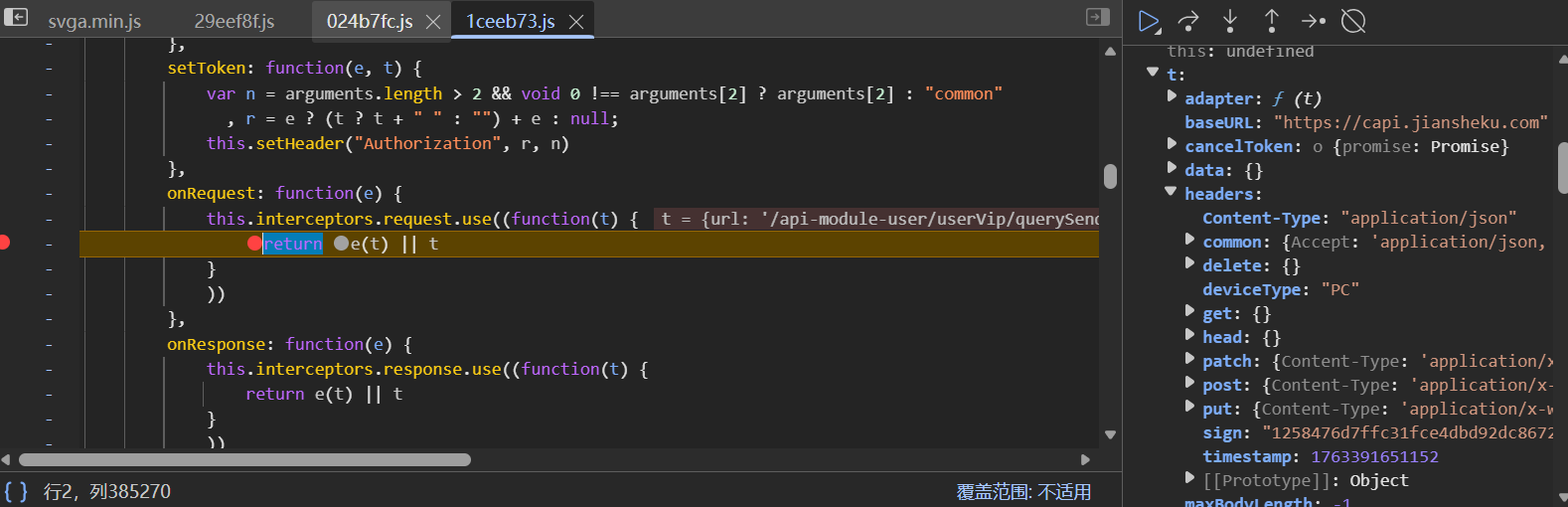
细心的你肯定发现了:在断点进行时到停止,只有左边这一个函数一直执行。那么,我们就可以去掉另一个函数的断点,并且把这个函数的断点放在e(t) 前,执行断点再找到其对应的函数体(注意!不换断点直接找可能会导致函数不对应):
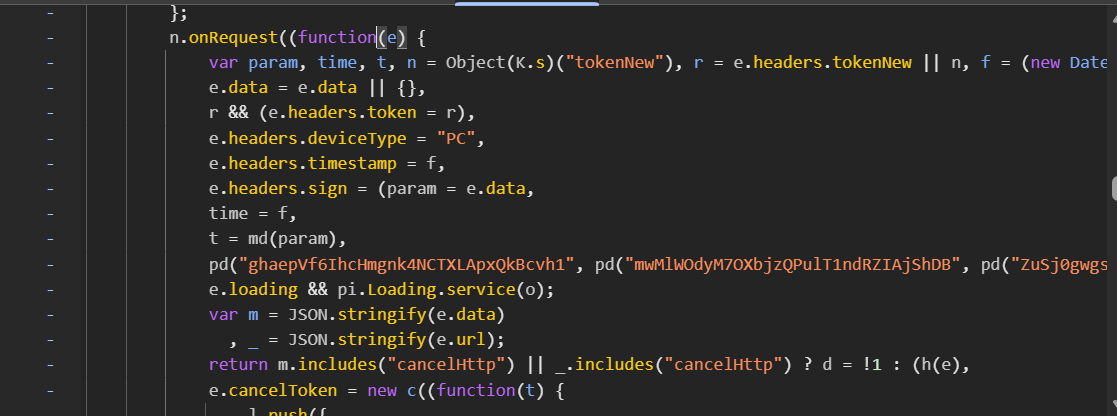
找到了sign 和timestamp的生成方式。按照我前几篇文章讲的方法补充一个个函数和变量,生成对应的标签和时间戳变量值:
gd = function (e) {
var t = new Array
, n = 0;
for (var i in e)
t[n] = i,
n++;
return t.sort()
}
_d = function e(t) {
var n;
if (Array.isArray(t)) {
for (var r in n = new Array,
t) {
var o = t[r];
for (var i in o)
null == o[i] ? delete t[r][i] : Array.isArray(t[r][i]) && e(t[r][i])
}
return n = t,
JSON.stringify(n).replace(/^(\s|")+|(\s|")+$/g, "")
}
return n = t && t.constructor === Object ? JSON.stringify(t) : t
}
md = function (e) {
var t = gd(e)
, n = "";
for (var i in t) {
var r = _d(e[t[i]]);
null != r && "" != r.toString() && (n += t[i] + "=" + r + "&")
}
return n
}
const crypto = require('crypto');
function md5(str) {
return crypto.createHash('md5').update(str, 'utf8').digest('hex');
}
pd = function (e, t, time) {
var n = t + e + time;
return n = md5(n)
}
function main(json_data){
f = (new Date).getTime()
headers = {}
headers.timestamp = f
headers.sign = (param = json_data,
time = f,
t = md(param),
pd("ghaepVf6IhcHmgnk4NCTXLApxQkBcvh1", pd("mwMlWOdyM7OXbjzQPulT1ndRZIAjShDB", pd("ZuSj0gwgsKXP4fTEz55oAG2q2p1SVGKK", t, time), time), time))
return headers
}(补充:原图片中对应的e_data 变量与生成的基础爬虫代码的json_data 类似,直接写成一个函数的形参传入;还有pd 方法中的原fd 方法,最终调用的是一个MD5加密方法(可以使用工具验证),在此使用AI直接写一个加密函数调用)
最终,构建完整爬虫代码:
import requests
import execjs
with open('JS.js', 'r', encoding='utf-8') as f:
js_code = f.read()
cookies = {
'Hm_lvt_03b8714a30a2e110b8a13db120eb6774': '1763301182,1763382265',
'HMACCOUNT': '481441E951CF8E41',
'Hm_lpvt_03b8714a30a2e110b8a13db120eb6774': '1763382808',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json;charset=UTF-8',
'devicetype': 'PC',
'origin': 'https://www.jiansheku.com',
'page': 'search-enterprise',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://www.jiansheku.com/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'sign': 'a454af043c83aa2fb735d937470d31d5',
'timestamp': '1763382812705',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0',
# 'cookie': 'Hm_lvt_03b8714a30a2e110b8a13db120eb6774=1763301182,1763382265; HMACCOUNT=481441E951CF8E41; Hm_lpvt_03b8714a30a2e110b8a13db120eb6774=1763382808',
}
json_data = {
'eid': '',
'achievementQueryType': 'and',
'achievementQueryDto': [],
'personnelQueryDto': {
'queryType': 'and',
},
'aptitudeQueryDto': {
'queryType': 'and',
'nameStr': '',
'aptitudeQueryType': 'and',
'businessScopeQueryType': 'or',
'filePlaceType': '1',
'aptitudeDtoList': [
{
'codeStr': '',
'queryType': 'and',
'aptitudeType': 'qualification',
},
],
'aptitudeSource': 'new',
},
'page': {
'page': 2,
'limit': 20,
'field': '',
'order': '',
},
}
response = requests.post('https://capi.jiansheku.com/nationzj/enterprice/page', cookies=cookies, headers=headers,
json=json_data)
pages = input('请输入页数:')
for i in range(1, int(pages) + 1):
json_data['page']['page'] = i
result = execjs.compile(js_code).call('main', json_data)
headers['sign'] = result['sign']
headers['timestamp'] = str(result['timestamp'])
response = requests.post('https://capi.jiansheku.com/nationzj/enterprice/page', cookies=cookies, headers=headers,
json=json_data)
print(response.json())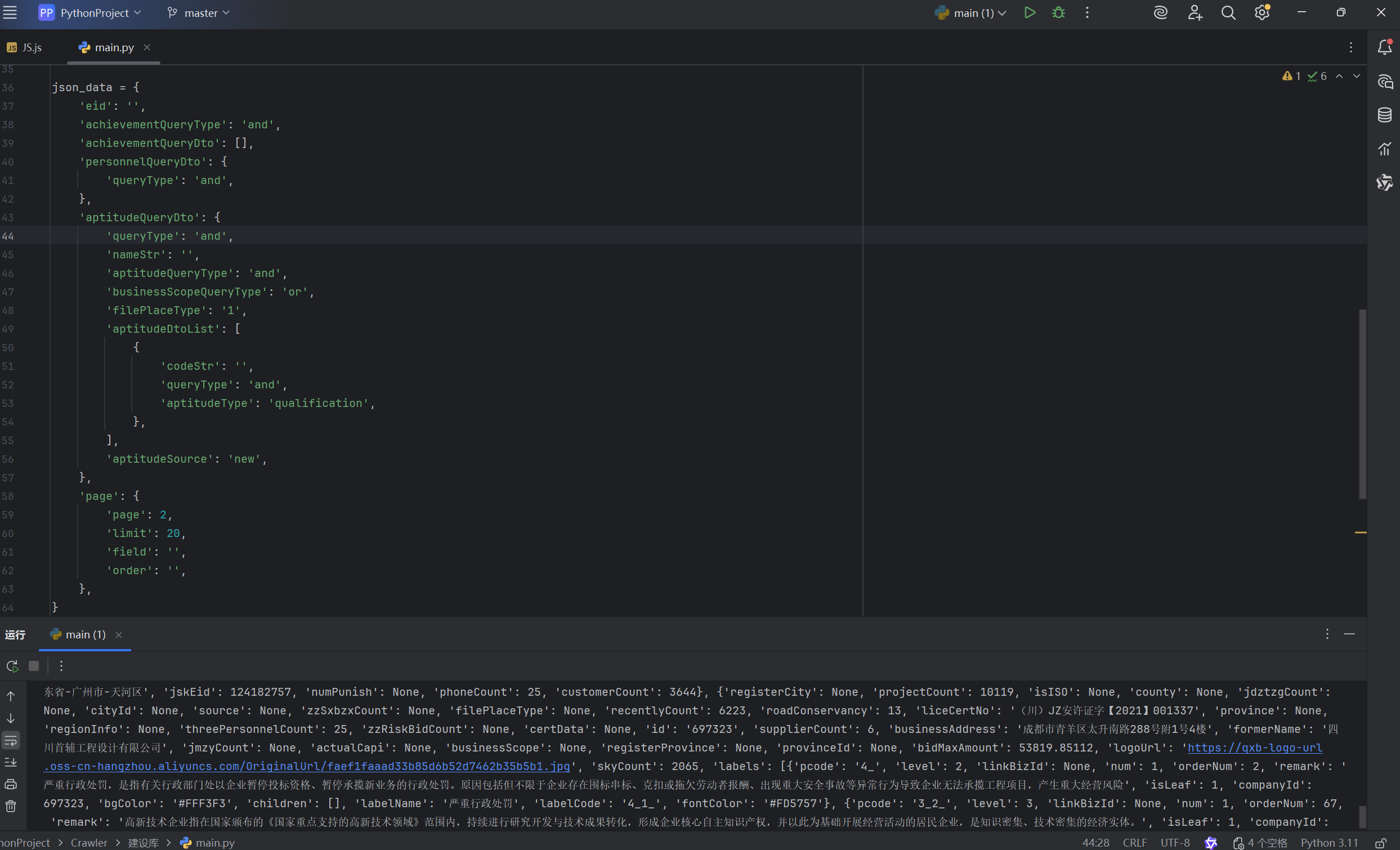
圆满结束。老规矩,提取关键数据交给读者...