提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 数据库](#1. 数据库)
- [2. 数据基本类型](#2. 数据基本类型)
- [3. 表操作](#3. 表操作)
-
- [3.1 建表](#3.1 建表)
- [3.2 查看表结构](#3.2 查看表结构)
- [3.3 删除表](#3.3 删除表)
- [3.4 插入](#3.4 插入)
- [3.5 查看表](#3.5 查看表)
- [3.6 查询](#3.6 查询)
- [3.7 分页查询](#3.7 分页查询)
- [3.8 分页查询](#3.8 分页查询)
- [3.9 删除操作](#3.9 删除操作)
- [3.10 表约束](#3.10 表约束)
- [3.11 表的设计](#3.11 表的设计)
- [3.12 新增](#3.12 新增)
- [3.13 聚合查询](#3.13 聚合查询)
- [3.14 GROUP BY子句](#3.14 GROUP BY子句)
- 总结
前言
1. 数据库
sql
show databases;
sql
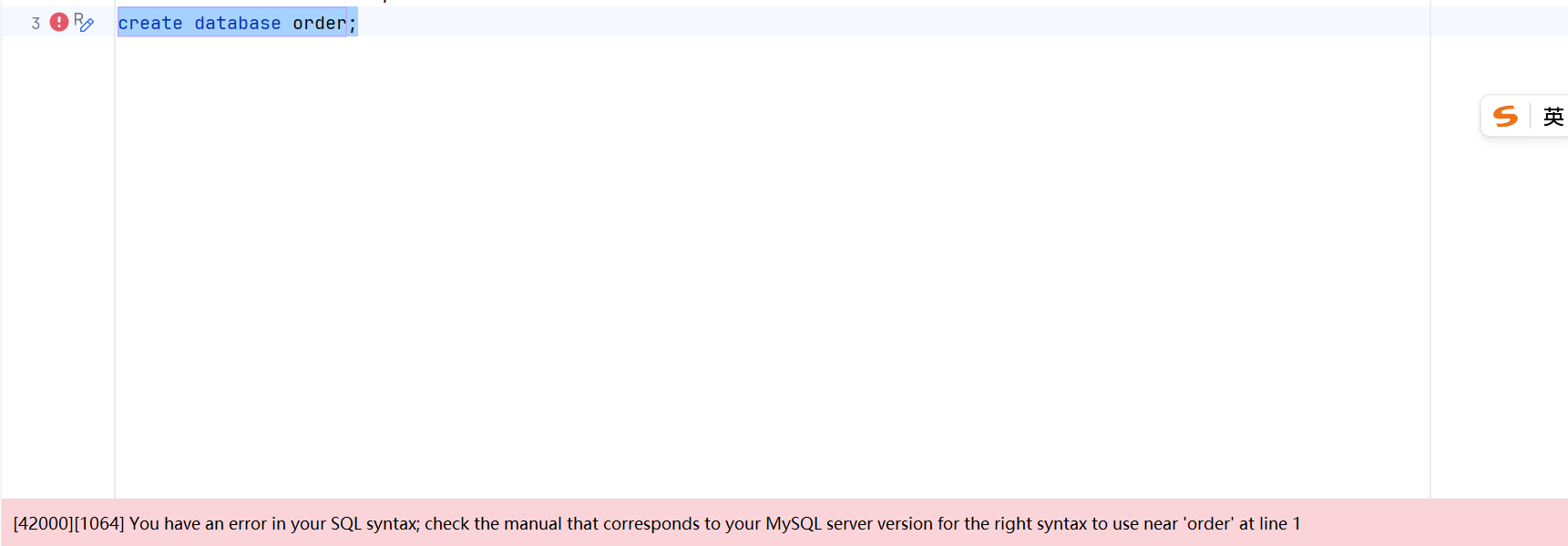
create database java11;创建的数据库的名字不能和SQL的关键字重合
sql
create database `create`;加上这个Tab上面的引号就可以创建和SQL的关键字一样的数据库名字了
SQL中不区分大小写
一般写小写字母
创建数据库的时候,一般还要指定数据库的字符集charset
因为使用不同的字符集---》中文占的字节就是不同的
GBK:一个中文两个字节
UTF-8:一个中文三个字节---》能表示世界任何一个语言
如果不指定字符集---》插入中文的话---》会出错
msql8--》默认就是utf-8
sql
create database java111 charset utf8;
sql
create database if not exists java111 charset utf8;这个的话,就算java111数据库已经存在了,也不会报错的
sql
show warnings ;这个是查看警告信息
sql
use java111;选择数据库
sql
drop database java111;删除数据库
2. 数据基本类型
bit
tinyint
int
bigint
float
double
varchar()可变长字符串
char()固定字长
text可变长,但是很长
图片,视频,音频等二进制数据---》blob
但是最大只能保存64kb,所以不建议用数据库存储图片这种二进制数据
datetime
timestamp:时间戳
BIT (M) M指定位数,默认为1 二进制数,M范围从1到64,存储数值范围从0到2^M-1
常用Boolean对应BIT,此时默认是1位,即只能存0和1
TINYINT 1字节 Byte
SMALLINT 2字节 Short
INT 4字节 Integer
BIGINT 8字节 Long
FLOAT(M, D) 4字节 单精度,M指定长度,D指定小数位数。会发生精度丢失 Float
DOUBLE(M,D)8字节 Double
DECIMAL(M,D)M/D最大值+2双精度,M指定长度,D表示小数点位数。精确数值 BigDecimal
NUMERIC(M,D)M/D最大值+2和DECIMAL一样 BigDecimal
后面对应的是java类型
VARCHAR (SIZE) 0-65,535字节 可变长度字符串 String
TEXT 0-65,535字节 长文本数据 String
MEDIUMTEXT 0-16 777 215字节 中等长度文本数据 String
BLOB 0-65,535字节 二进制形式的长文本数据 byte\[\]
DATETIME 8字节范围从1000到9999年,不会进行时区的检索及转换。java.util.Date、java.sql.Timestamp
TIMESTAMP 4字节范围从1970到2038年,自动检索当前时区并进行转换。java.util.Date、java.sql.Timestamp

3. 表操作
3.1 建表
sql
show tables;
sql
create table 表名(列名 类型,列名 类型);
sql
create table test (id int,name varchar(20));
sql
create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2),
resume text);comment 是注释,只能用于建表语句中的注释
一般--和#都是注释
3.2 查看表结构
sql
desc stu_test;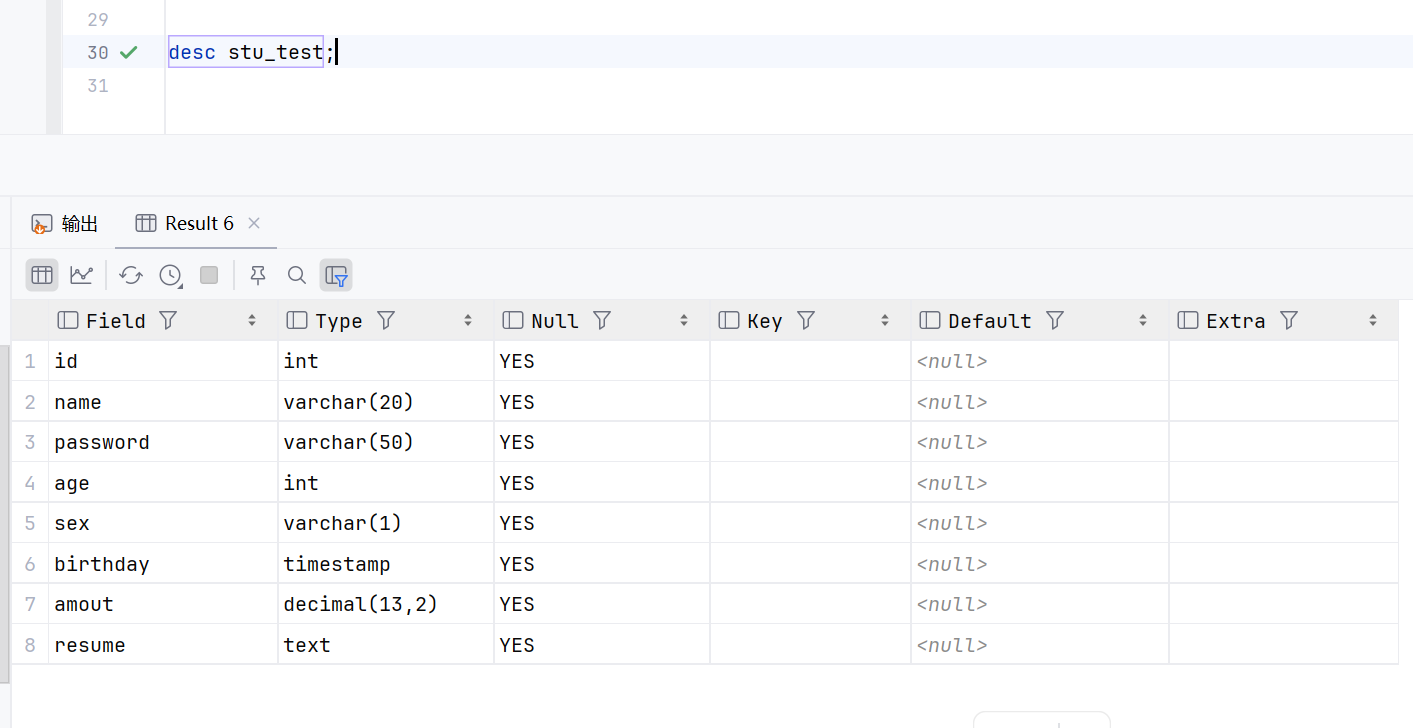
3.3 删除表
sql
drop table stu_test;3.4 插入
sql
insert into 表名 values(值,值,值);SQL表示字符串,单引号和双引号都是一样的
java单引号就是字符
sql
insert into test values(1,'zhangsan');可以插入中文---》要指定utf8
mysql8默认就是utf8
sql
insert into test (name) values ('李四');这样id就是null了
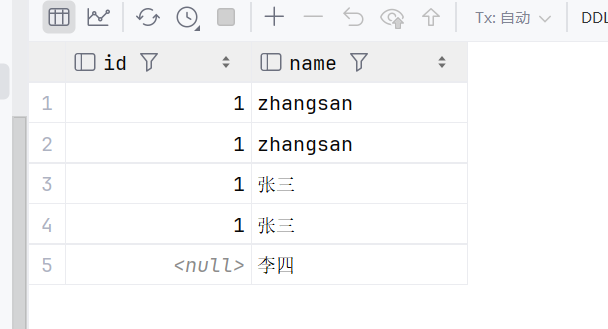
sql
insert into test (id,name) values (1,'李四');
sql
insert into test values (1,'a'),(2,'b'),(3,'c');这是插入多条
3.5 查看表
sql
select * from test;
sql
insert into test values('1','张三');这里可以隐式类型转换,----》弱类型系统
把字符串转换为int了
把字符串1转换为整数1了
动态类型:变量的类型可以改变
sql
create table test2(time datetime);
sql
insert into test2 values ('2025-05-03 20:38:10');
sql
insert into test2 values (now());now就是获取当前时间
3.6 查询
sql
select * from 表名*就是通配符,代表所有的列
sql
select 列名,列名 from 表名
sql
select name,id from test;
sql
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
sql
select name,chinese+10 from exam_result;查询出来的结构,chinese就会展现出加10的效果
sql
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);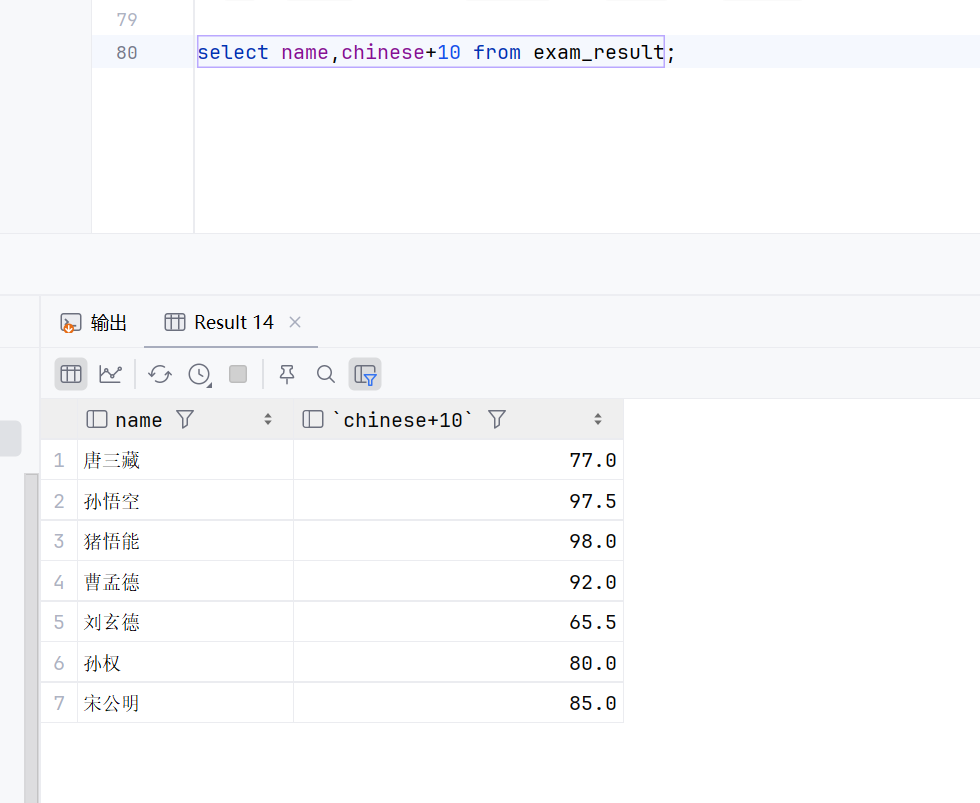
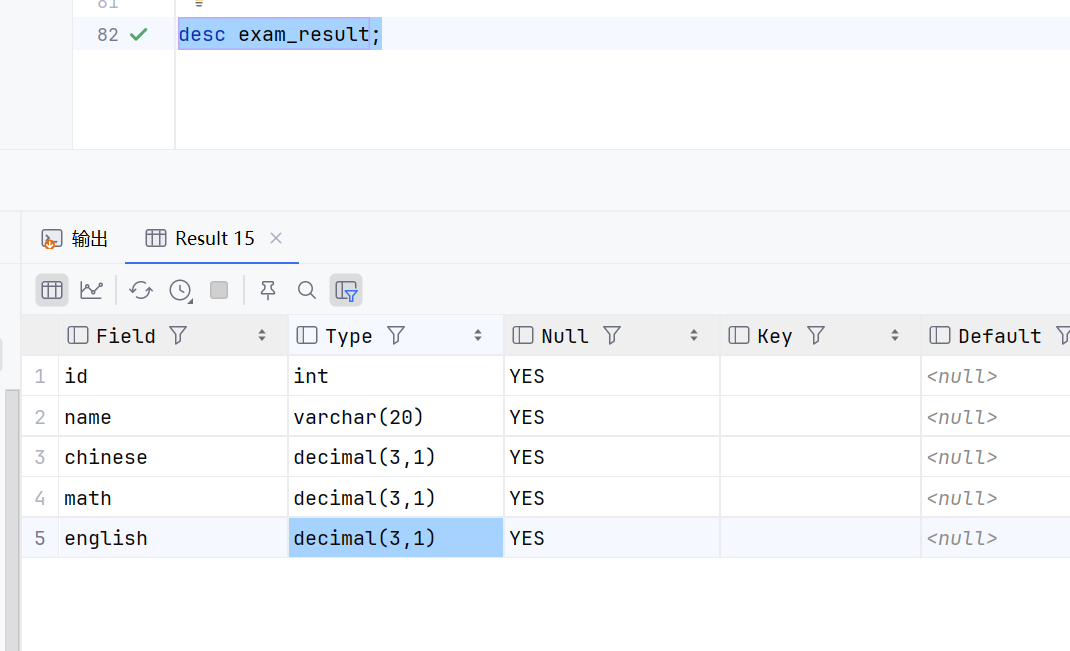
但是不能加20
因为decimal(3,1)表示位数总共是三位,小数位占一位
加20,108.0----》长度是四位了
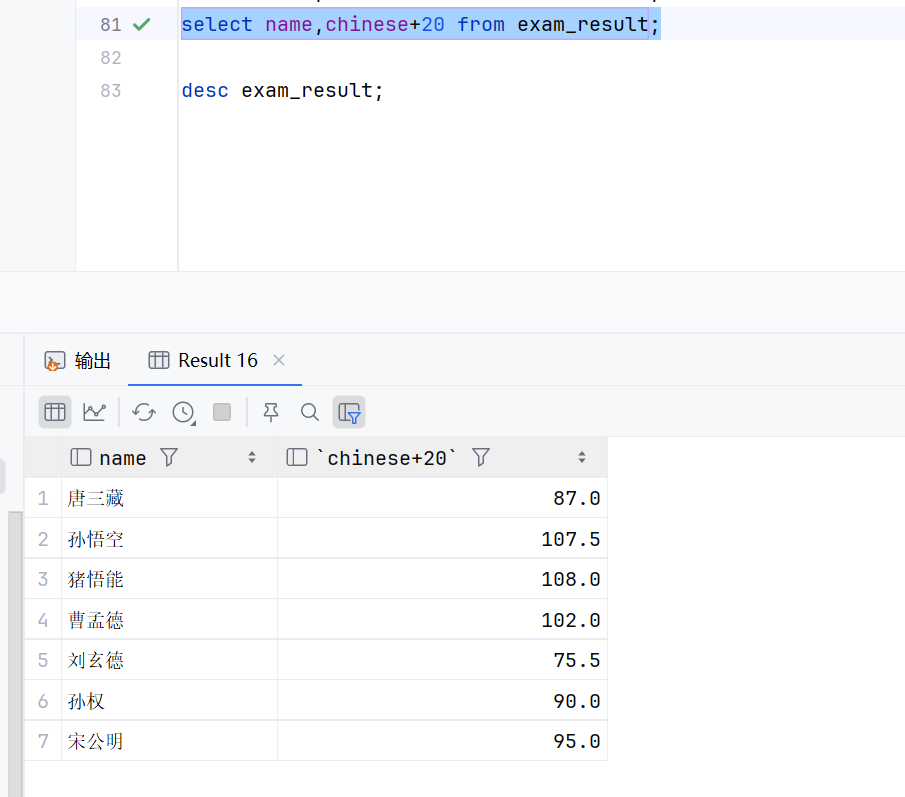
但是仍然可以查询,因为decimal(3,1)是要求硬盘存储的,查询出来的不太受这个decimal(3,1)的限制
sql
select name,chinese+math+english from exam_result;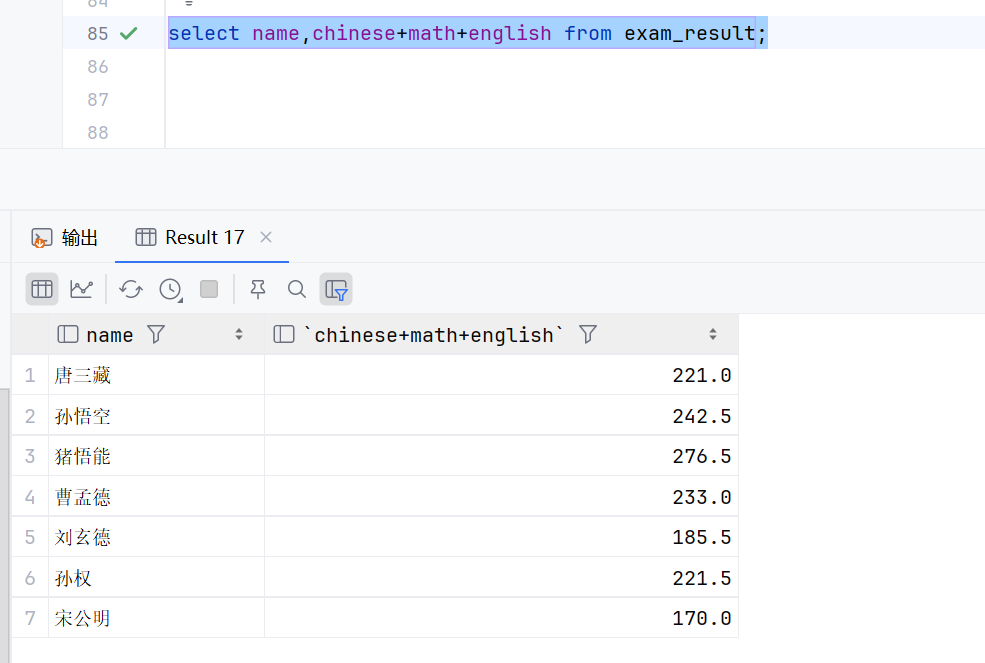
sql
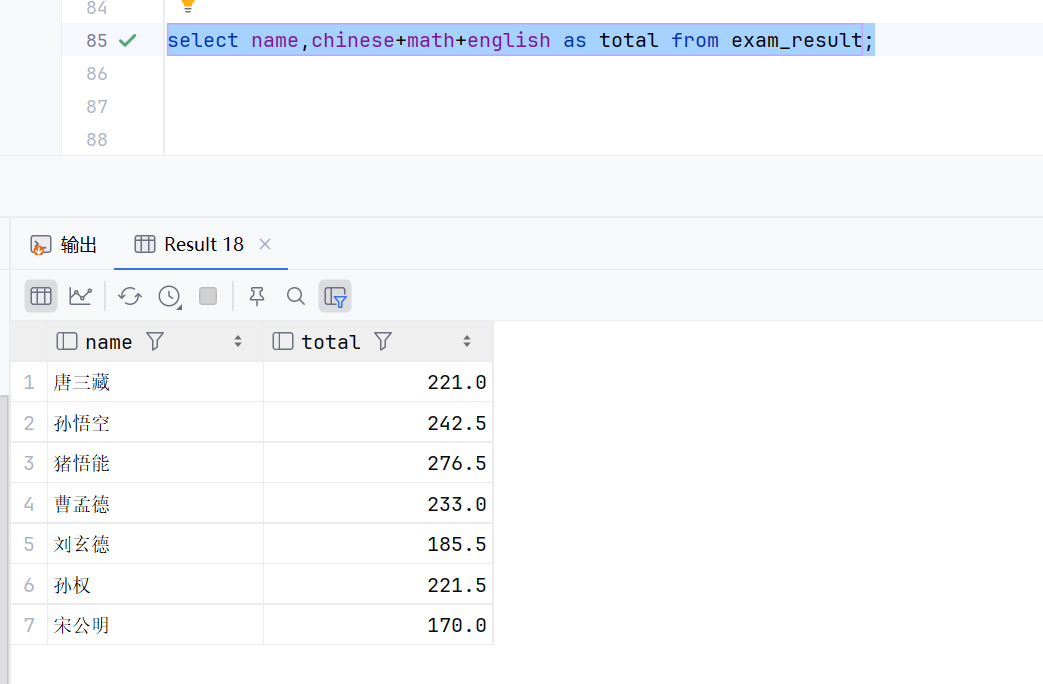
select name,chinese+math+english as total from exam_result;这个是取别名
sql
select name,chinese+math+english total from exam_result;as可以去掉
建议不要去掉
sql
select distinct 列名 from 表名这个就是查询一列,然后一列中不能有重复数据
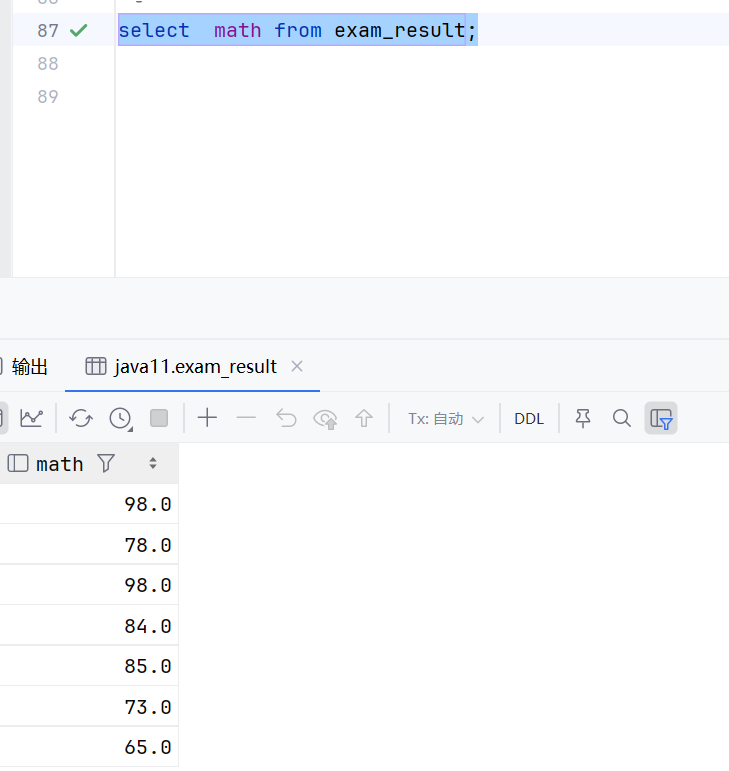
sql
select distinct math from exam_result;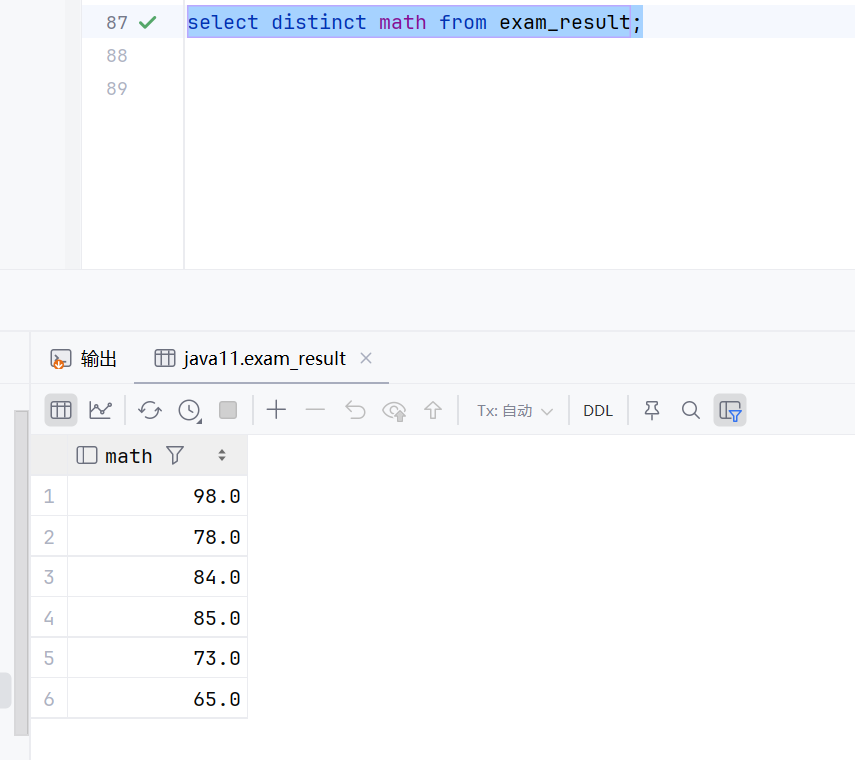
sql
select distinct name,math from exam_result;这个就是必须两列都一样才会去重的
sql
select * from exam_result order by chinese;默认是升序
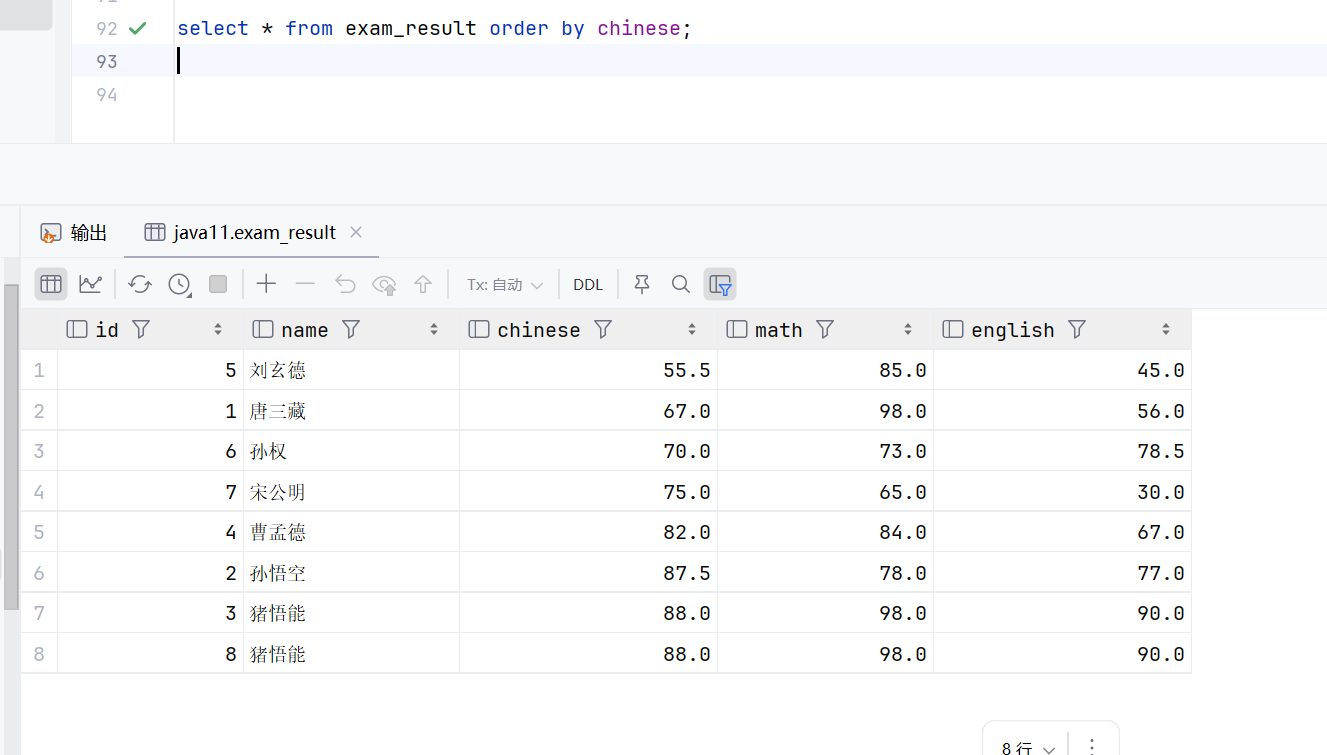
sql
select name from exam_result order by chinese;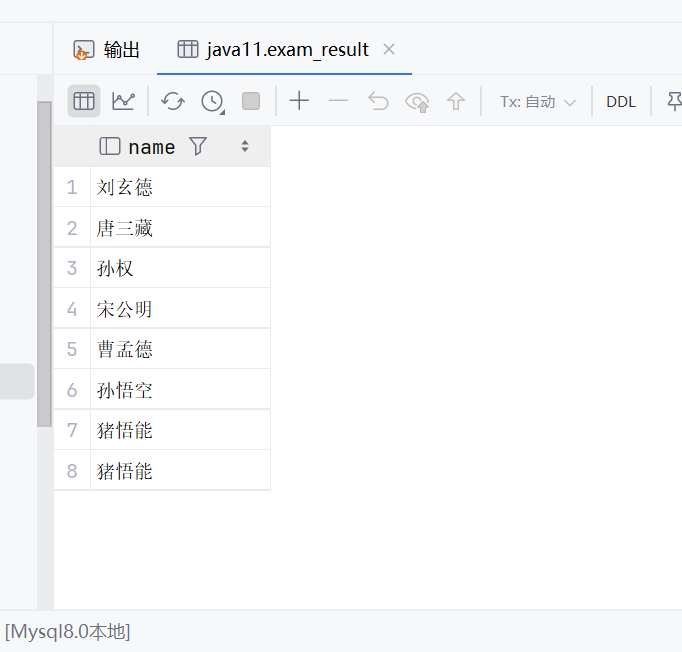
sql
select * from exam_result order by chinese desc ;这样就是降序
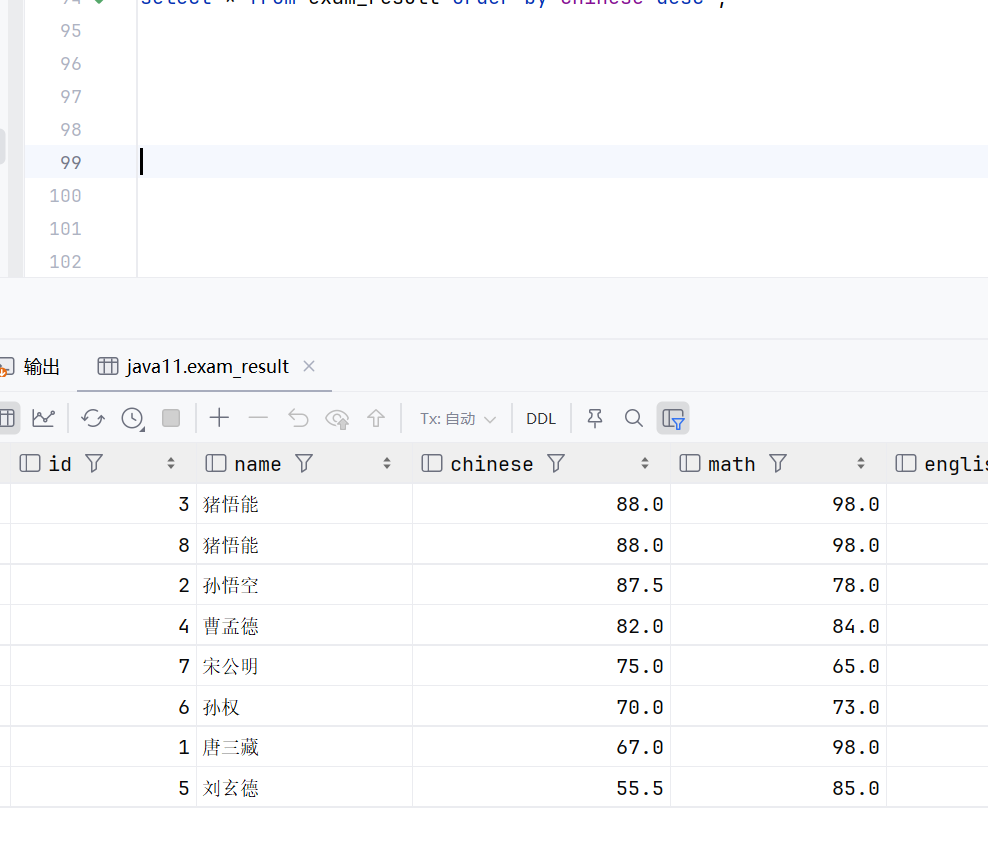
sql
select * from exam_result order by chinese asc ;这个是升序
sql
select * from exam_result order by chinese ,math ;这个就是按照多列来排序
sql
select 列名 from 表名 where 条件;SQL中比较相等使用的是=
NULL 不安全,例如 NULL = NULL 的结果是 NULL
NULL进行运算还是NULL
sql
insert into exam_result values (null,null,null,null,20);
sql
select name,chinese+math+english from exam_result;
NULL和任何东西进行运算都是NULL
NULL就是false
<=>这个也是比较相等的
可以针对NULL进行比较
NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1)
!=和<>都是比较不相等
BETWEEN a0 AND a1
in(options)
is NULL
is NOT NULL
LIKE
AND
OR
NOT
sql
select * from exam_result where english<60;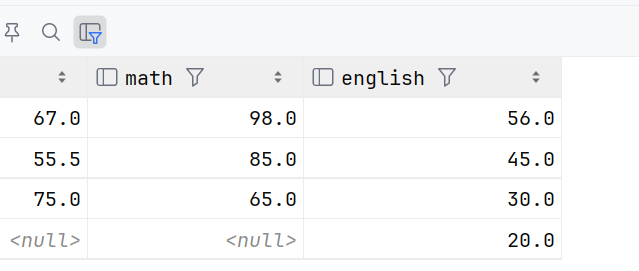
sql
select * from exam_result where english<chinese;
sql
select * from exam_result where english+chinese+math < 200;
这样写是不行的,因为条件是先执行的,所以它不认识total
sql
select * from exam_result where english < 200 and english>20;还有OR的话---》加括号
sql
select * from exam_result where english between 20 and 90;SQL里面的between 是闭区间的,前闭后闭
sql
select * from exam_result where english in (90,80);模糊查询
%:匹配0个或者任意个任意的字符
_:匹配一个特定的字符
sql
select * from exam_result where name like '孙%';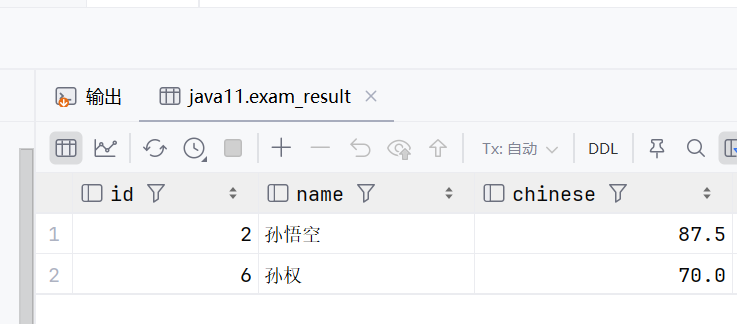
匹配到孙开始的name
sql
select * from exam_result where name like '%孙';查询孙结尾
sql
select * from exam_result where name like '%孙%';中间带孙
sql
select * from exam_result where name like '孙__';三个字,孙开头
不要使用=和null比较,因为都是null,都是false,一个都查不出来
sql
select * from exam_result where name <=> null;
sql
select * from exam_result where name is null;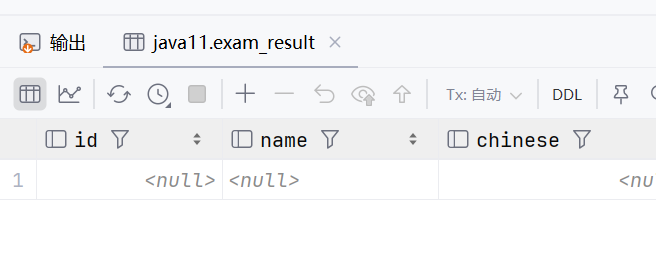
3.7 分页查询
sql
select 列名 from 表名 limit N
sql
select * from exam_result limit 5;只包含前面五条数据
sql
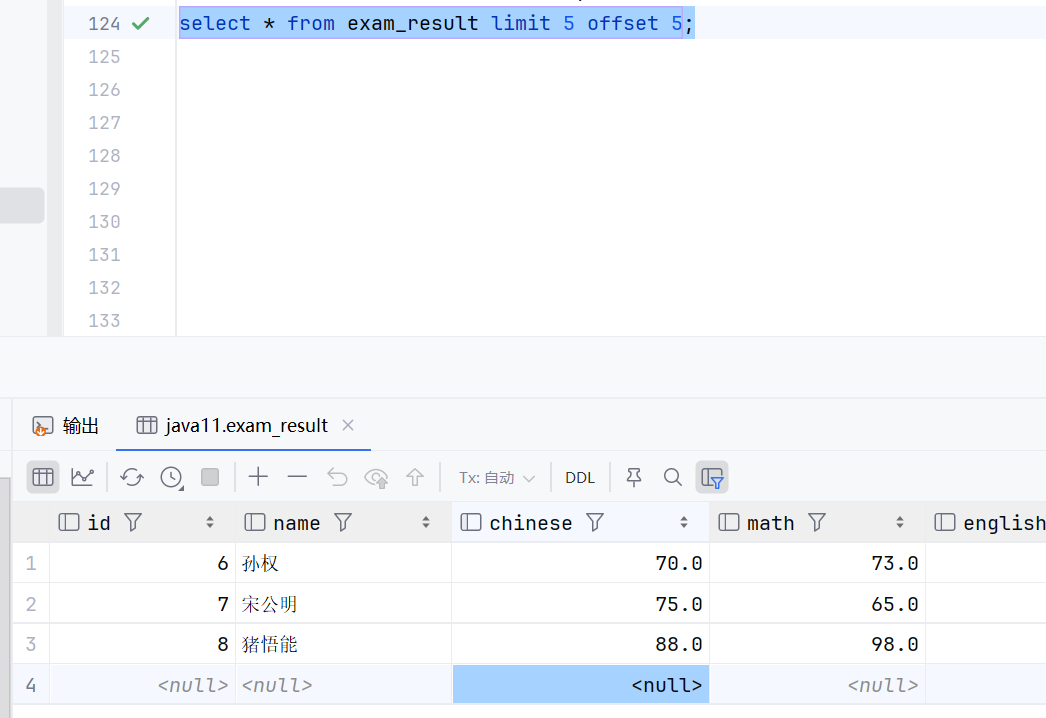
select * from exam_result limit 5 offset 5;offset 表示从第几个开始查询五个
sql
select * from exam_result limit 5 , 5;这样写也是一样的
3.8 分页查询
sql
update 表名 set 列名=值,列名=值;还可以结合where ,order by,limit
sql
update exam_result set math =80 where name ='孙悟空';where匹配到几行,就修改几行
sql
update exam_result set math =math+1 ;这个是修改所有行
sql
update exam_result set math =math-1 ,chinese=60 where id =6;
sql
update exam_result set math =math-1 ,chinese=60 order by chinese+math+english limit 3;这个修改的对象就是总成绩倒数三个
注意null时最小的
3.9 删除操作
sql
delete from 表名 where 条件 /order by /limit;匹配到什么就删除什么,删除行
sql
delete from exam_result where id IS NULL;
sql
insert into 表名
selecct from 表名
update 表名
delete from 表名3.10 表约束
sql
NOT NULL - 指示某列不能存储 NULL 值。
UNIQUE - 保证某列的每行必须有唯一的值。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略
CHECK子句
sql
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY,
sn INT UNIQUE NOT NULL,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);PRIMARY KEY一个表只能有一个
插入数据的时候要指定id
sql
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE NOT NULL,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);auto_increment:自动增加
插入数据的时候,可以不指定id,但是也至少写为null,因为没有指定字段就是所有字段,所以要写null,指定字段插入的话,就可以不写id了
sql
insert into student values (null,1,'11','aa');
sql
insert into student values (21,2,'11','aa');这样也是可以的,可以指定id的
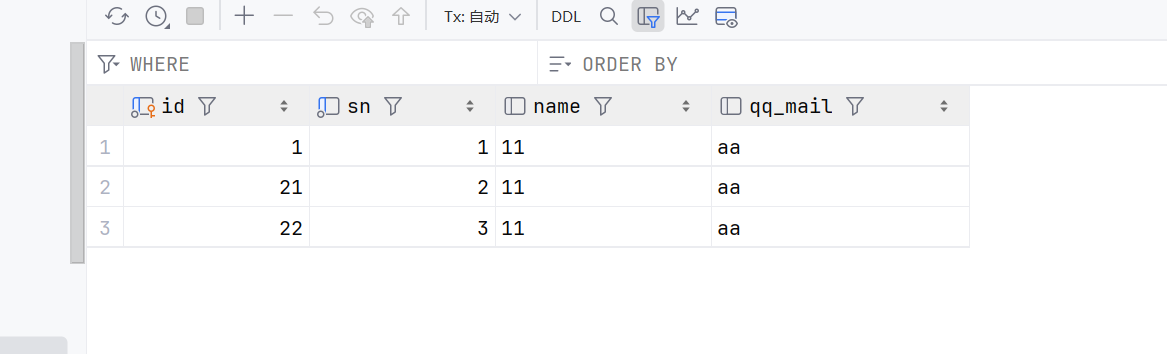
如果指定了大的id,那么后面的id都是从这个大的id自动增加的
sql
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);增加的student 的classes_id 必须存在
删除classes的classes_id的时候,要考虑student 的classes_id
定义一个字段----》可以实现逻辑删除
sql
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);3.11 表的设计
实体之间的关系:一对一,一对多,多对多,没关系


一对一:放在一起,或者直接存储另一个的id

因为Mysql中没有数组类型,所以只能设计为一对多的形式
redis中可以设置数组形式

多对多就要建立一个新的表了
3.12 新增
sql
create table student(id int,name varchar(20));
create table student2(id int,name varchar(20));
insert into student values (1,'zhangsan');
insert into student2 select * from student where id <50;这个操作就是把一个表中数据插入另一个表,但是这样写,要保证两个表的字段结构一致
要求列数,类型,顺序一致,列的名字可以是不同的
sql
DROP TABLE IF EXISTS student;
DROP TABLE IF EXISTS student2;
create table student(id int,name varchar(20));
create table student2(sudentId int,name varchar(20));
insert into student values (1,'zhangsan');
insert into student2 select * from student where id <50;还可以指定列的方式插入
sql
DROP TABLE IF EXISTS student;
DROP TABLE IF EXISTS student2;
create table student(name varchar(20),id int);
create table student2(sudentId int,name varchar(20));
insert into student values ('zhangsan',1);
insert into student2(name,sudentId) select * from student where id <50;
sql
DROP TABLE IF EXISTS student;
DROP TABLE IF EXISTS student2;
create table student(name varchar(20),id int);
create table student2(sudentId int,name varchar(20));
insert into student values ('zhangsan',1);
insert into student2(name,sudentId) select name,id from student where id <50;这样也可以
注意列的对应关系就可以了
3.13 聚合查询
这个是针对行进行操作
sql
COUNT([DISTINCT] expr) 返回查询到的数据的 数量
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
sql
select count(*) from exam_result;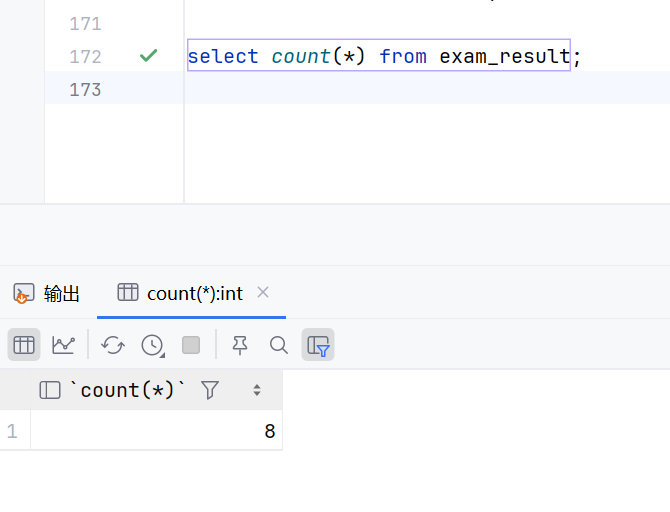
这个意思就是先执行select * from exam_result;然后在执行count
sql
select count(name) from exam_result;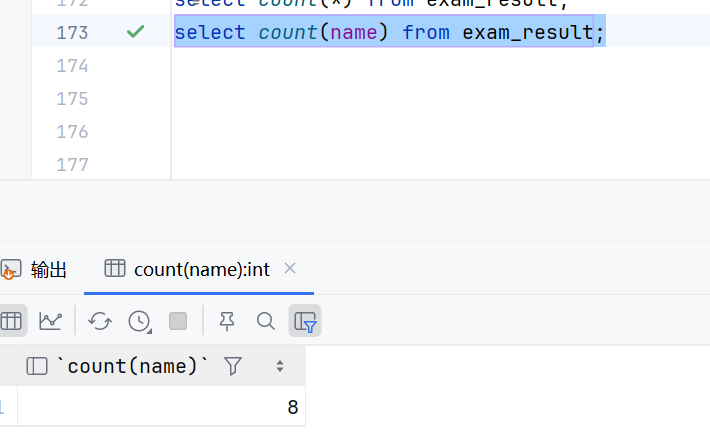
count(name)使用函数的时候,不要有空格
count(id,name)
这个是不能执行的
sql
select count(distinct *) from exam_result;这个算的是去重后的数量
sql
select sum(english) from exam_result;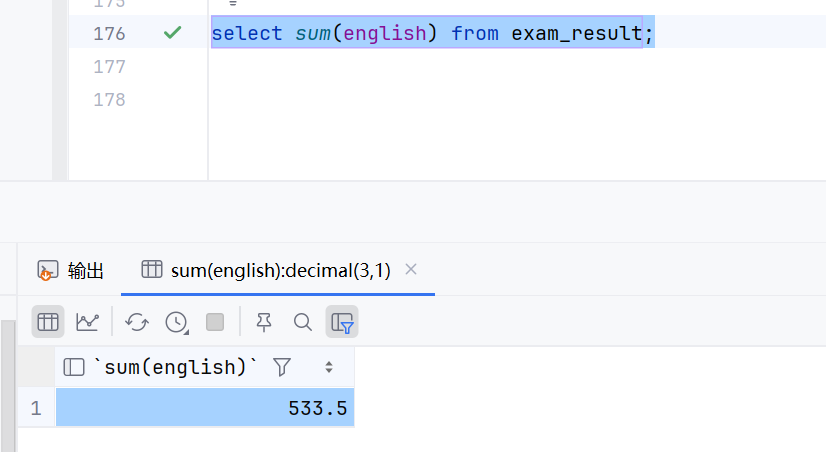
求和的这一列必须是数字
不能是字符串---》会有警告
sql
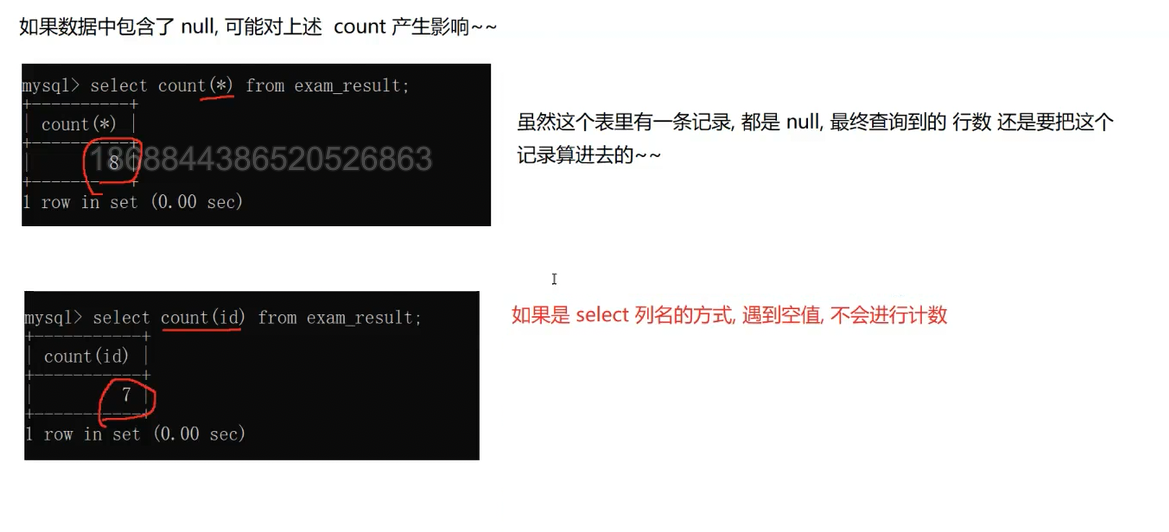
show warnings注意在sum里面,就算里面有null---》不会计算这个,自动忽略了,直接跳过了
sql
select sum(english+chinese+math) from exam_result;这个求得就是所有人的成绩和
然后还可以加条件
sql
COUNT([DISTINCT] expr) 返回查询到的数据的 数量
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
sql
select avg(english) from exam_result;算平均成绩也会忽略null,数量不会包含它,成绩也不会包含它
3.14 GROUP BY子句
sql
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);使用group by的时候,select后面的列名,要么写group by的列名,要么搭配聚合函数
sql
select role,count(*) from emp group by role;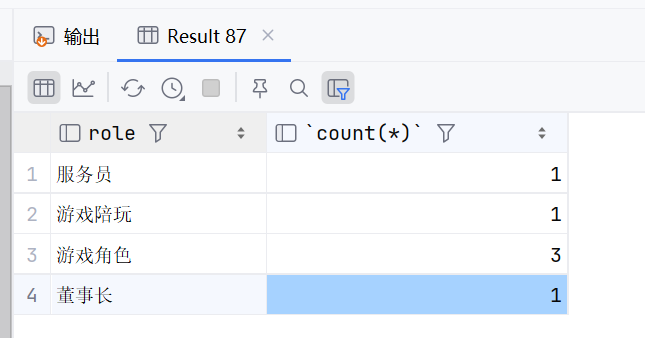
这个就是统计每个分组几个人
sql
select role,count(*),avg(salary) from emp group by role;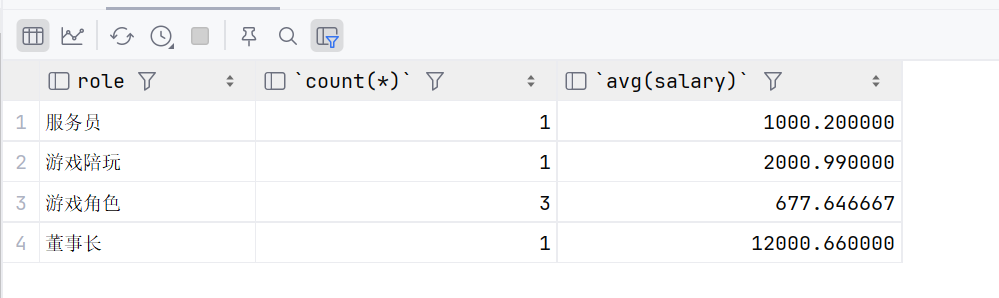
统计每个分组的平均薪资
sql
select role,count(*),avg(salary) from emp group by role order by avg(salary); 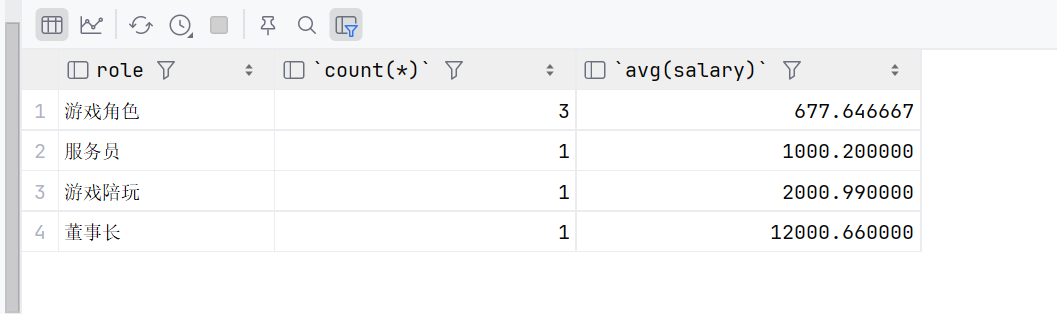
还可以加上排序
还可以搭配条件,分组前和分组后的条件
sql
select role,count(*),avg(salary) from emp where name!= '马云' group by role order by avg(salary);这个是在分组前指定条件了,不要马云参与分组
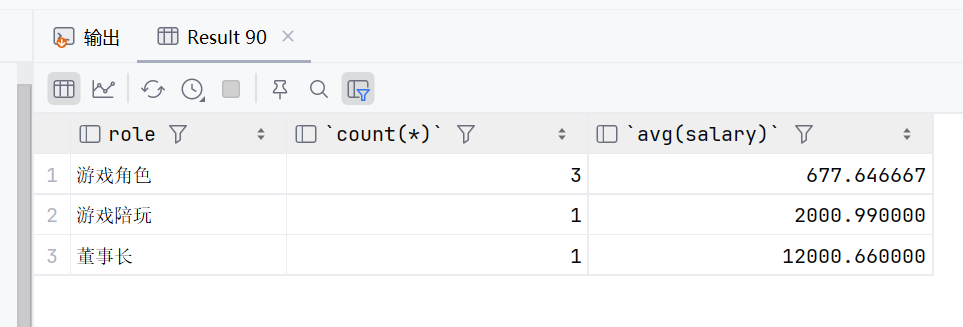
sql
select role,count(*),avg(salary) from emp where name!= '马云' group by role having avg(salary)<5000 order by avg(salary);这个就是分组后的条件了,只有平均薪资小于5000的组