在快速发展的自动驾驶领域,英伟达刚刚发布了一个革命性创新:Alpamayo-R1 (AR1),这是一款先进的视觉-语言-动作 (VLA) 框架,在 arXiv 上以一份详尽的 41 页论文形式呈现。该论文于 2025 年 10 月 30 日发布,针对当前端到端自动驾驶系统的弱点------在罕见、安全关键的"长尾"场景中表现脆弱------提供了解决方案。通过将结构化因果推理与精确轨迹规划融合,AR1 为实现 L4 级(高度自动化)自治铺平了实际道路。
如果你从事 AI、机器人或自动驾驶技术,这篇论文绝对值得一读。它不仅展示了英伟达在物理 AI 方面的实力,还承诺了具有闪电般快速推理的真实世界部署。让我们一步步剖析,基于论文的核心洞见、数据集细节以及 X(前 Twitter)上的社区热议。
1.核心理念:桥接推理与动作,实现稳健自治
传统的端到端架构通过模仿学习在常见场景中表现出色,但在边缘情况下因监督信号稀疏和因果理解不足而失败。例如,模型可能幻觉认为直行绿灯允许左转------这可能导致灾难性错误。AR1 通过将因果链 (Chain of Causation, CoC) 推理与动作预测集成来解决这一问题,将推理从单纯的附加功能转变为提升泛化性和安全性的核心功能。
本质上,AR1 是一个模块化 VLA 模型,它处理多摄像头输入,生成可解释的因果推理轨迹,并输出动态可行的轨迹。这种"推理优先"的方法受到了大型语言模型 (LLM) 如 OpenAI 的 o1 的启发,其中推理时间推理提升了决策。在驾驶中,这意味着在承诺动作前进行显式反事实思考(例如,"如果现在左转,我将与对面来车碰撞,因为红灯")。
摘要中的关键亮点:与仅基于轨迹的基准相比,AR1 在挑战性场景中的规划准确率提升高达 12%,仿真中偏离车道率降低 35%,近距离碰撞率降低 25%。 车载测试确认端到端延迟为 99 毫秒,使其可在真实城市环境中部署。
2.关键创新:从架构到训练
论文的 41 页充满了技术深度。以下是三大支柱的分解:
2.1. 因果链 (CoC) 推理集成
AR1 将推理结构化为简洁、因果锚定的轨迹,仅基于历史观测------避免窥视未来以防止因果混淆。这确保决策可解释且可验证,通过显式检查如交通规则和智能体交互来提升安全性。
2.2. 模块化 VLA 架构
基于Cosmos-Reason构建,这是一个为物理 AI 预训练的 VLM,包含 2.47k 个驾驶特定 VQA 样本,AR1 添加了:
- 高效视觉编码:支持单图像、多摄像头(例如,三平面用于 token 压缩高达 3.9 倍)或视频 token 化(例如,Flex 用于 20 倍减少),以实时处理 360° 多步输入。
- 基于流匹配的轨迹解码器:使用扩散专家生成连续、多模态轨迹,基于自行车运动学,确保物理可行性和快速解码(比自回归方法更快)。
这种设置允许无缝集成预训练 VLM,同时适应驾驶约束。
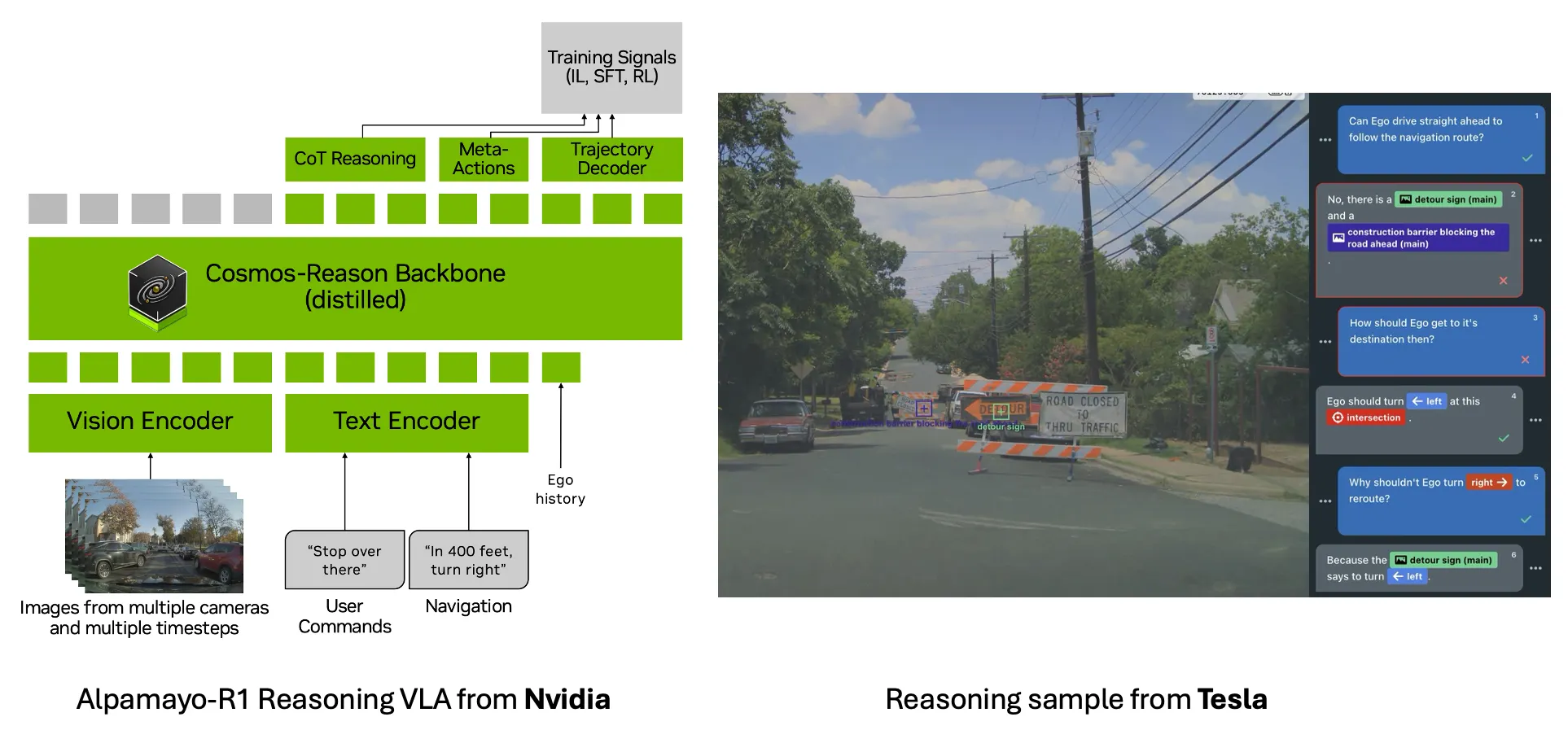 近期行业趋势是采用推理功能的自动驾驶技术栈(例如英伟达的 Alpamayo-R1 和特斯拉在 ICCV 2025 上的演讲)
近期行业趋势是采用推理功能的自动驾驶技术栈(例如英伟达的 Alpamayo-R1 和特斯拉在 ICCV 2025 上的演讲)
2.3. 多阶段训练策略
- 动作模态注入:训练时注入离散 token,推理时切换到连续流匹配。
- 有监督微调 (SFT) :在 CoC 数据集上激发因果推理。
- 强化学习 (RL) 后训练:通过大型推理模型 (LRM) 反馈优化质量(提升 45%)、推理-动作一致性(提升 37%)和安全奖励。
模型从 0.5B 到 7B 参数的缩放产生持续收益,与 AI 缩放定律一致。
python
import torch
# 假设 VLM 模型
class VLMModel(torch.nn.Module):
def forward(self, inputs): # inputs: tokenized 观测 + 文本
# 自回归生成推理 token,并计算 KV 缓存
kv_cache = self.compute_kv(inputs) # 从 Transformer 层提取
return kv_cache
# 在推理时
vlm = VLMModel()
kv_cache = vlm(inputs) # 生成 KV 缓存
class ActionExpert(torch.nn.Module):
def __init__(self):
super().__init__()
self.transformer = torch.nn.Transformer(...) # 与 VLM 共享注意力维度,但更小
self.mlp_head = torch.nn.Sequential(...) # 投影到向量场
def forward(self, kv_cache, noisy_control, t):
# 嵌入时间 t
t_embed = self.embed_t(t)
# 组合输入:KV 缓存 + 噪声控制嵌入 + t_embed
features = self.transformer(kv_cache + noisy_control + t_embed)
vector_field = self.mlp_head(features) # 预测 \hat{v}_\theta (向量场)
return vector_field
# 推理时切换
expert = ActionExpert()
num_steps = 5 # 默认 5 步
x_t = torch.randn(batch_size, traj_length * 2) # 初始噪声 (64点 x 2控制 = 128 dims)
delta_t = 1.0 / num_steps
for step in range(1, num_steps + 1):
t = step / num_steps # t 从 1 到 0
v_hat = expert(kv_cache, x_t, t) # 预测向量场
x_t = x_t - delta_t * v_hat # 欧拉积分去噪
# 最终 x_t 是连续控制序列,转为轨迹
trajectory = kinematics_model(x_t) # 用式(5)转换为位置/偏航欧拉积分去噪是把"理论上很强但太慢的自回归离散生成"变成"又强又能上车"的关键一招------它用极少的固定步数(5 步)完成了原本需要上百步的自回归任务,直接把推理延迟从秒级砍到毫秒级,实现了真正的实时可部署 L4 自动驾驶规划。
没有欧拉积分(或其他 ODE 求解器),流匹配的优势就发挥不出来;没有流匹配,欧拉积分也没东西可积分。这俩是绝配,正是 AR1 能在实车上跑通的核心原因之一。
你要从一个"完全乱七八糟的轨迹"(纯噪声)走到一个"干净正确的轨迹"(真实未来路径),这中间其实是一条连续的"去噪路径"。
流匹配(Flow Matching)模型在训练时已经学会了这条路径上每一刻的瞬时速度(数学上叫向量场 v(x,t)): "如果你现在在 x 这个噪声状态,时间还剩 t,那么你应该以多大的速度往干净轨迹的方向移动"。
推理时,我们只需要沿着这条已知的"速度场"从噪声走到干净轨迹,就完成了生成。
问题来了:这条路径是连续的,怎么在电脑里一步步走完?
2.3.1 自回归方式 vs 欧拉积分方式的本质区别(用最直观的比喻)
| 项目 | 自回归离散 token(128 步) | 流匹配 + 欧拉积分(5 步) |
|---|---|---|
| 比喻 | 走迷宫:每走一步都要停下来问路(跑一次完整 VLM) | 高速公路:手里有精准导航,每隔一大段距离看一眼方向盘就行 |
| 每一步在做什么 | 生成下一个 token(一个一个点) | 同时修正整个轨迹的 128 个点(并行!) |
| 单步计算量 | 巨大(完整 VLM 前向) | 很小(只跑一个轻量动作专家) |
| 总步数 | 必须 128 步(少一步就缺一个点) | 只需要 5 步(步子迈得大,相当于一次修正 20~30 个点) |
| 总时间 | 128 × 大计算量 ≈ 几秒到十几秒 | 5 × 小计算量 ≈ 几十毫秒 |
| 误差累积 | 每步错一点,最后可能偏离很多(自回归经典问题) | 步子虽大,但向量场本身训练得极准,5 步就足够收敛 |
2.3.2 欧拉积分到底在"偷"了哪些时间?
欧拉积分的核心公式就一行:
python
x_t = x_t - Δt × v̂(x_t, t) # Δt = 1 / 5 = 0.2- 每一步把整个 128 维轨迹同时往前推一大步(Δt=0.2)。
- 而不是像自回归那样一次只推 1/128 那么一小步。
- 这相当于把"128 次小心翼翼的微调"压缩成了"5 次大胆但精准的大修正"。
数学上证明:流匹配训练出来的向量场 v̂ 足够平滑、准确,即使步子迈得很大(Δt=0.2),5 步后误差也极小(论文实验里 5 步和 50 步性能几乎一样,但速度差 10 倍)。
2.3.3 再用一个生活化的类比结束
- 自回归 = 你用筷子一粒一粒夹炒饭,吃完一碗要夹 128 次。
- 流匹配 + 欧拉积分 = 你直接用勺子一大口一大口吃,5 勺就吃完了,饭量(轨迹质量)几乎没差。
所以欧拉积分的"缩时间原理"就是: 把串行的、细粒度的 128 次小修正,变成了并行的、粗粒度的 5 次大修正, 而流匹配保证了"即使步子大,也不会走偏"。
这就是为什么同样生成一条 6 秒轨迹,别人要几秒,AR1 只要 99 毫秒就能上车跑的原因
X 上的社区兴奋得反应:英伟达 AV 研究负责人 Marco Pavone (@drmapavone) 将 AR1 突出为机器人出租车的核心技术,并归功于联合领导如 Wenjie Luo 和 Yan Wang。 Yan Wang (@yan_wang_9) 强调了其具身 AI 潜力,并指出英伟达 AV 团队的招聘机会。
3.数据工程:AR1 的支柱------构建 CoC 数据集
3.1. 数据收集与筛选
- 来源:基于内部驾驶数据集,采集自多辆车辆在 25 个国家、1700 多个城市的 8 万小时视频数据。包括多摄像头(通常 7 个,实现 360° 感知)、自车运动历史(位置、速度、偏航角等)和辅助信号(如车道拓扑、障碍物边界框)。
- 筛选逻辑 :并非所有数据都标注,仅选择"高信号"片段(即能明确建立因果关联的场景),分为反应型(立即调整,如避让行人)和主动型(预判,如变道寻隙)。使用基于规则的检测器(如低阶元动作转换检测)自动识别关键时刻。
- 关键帧选择:每个 20 秒片段生成多个样本(2 秒历史预测 6 秒未来)。反应型选行为变化前 0.5 秒;主动型选评估区间。确保因果因素仅来自历史窗口(避免未来泄露)。
- 平衡策略:规则检测确保数据集多样性(如天气、光照、路况、交通密度),并过滤无效数据(如不安全行为)。
- 输出:筛选后片段列表,每个片段包含原始观测序列(多摄像头图像序列、自车运动数据)和辅助元数据(如时间戳、地理信息)。
3.2. 标注与生成
- 混合标注流程 :结合自动(90% 规模标注)和人工(10% 高质量验证),生成结构化 CoC 轨迹。
- 自动标注 :使用先进 VLM(如 Gemini)多步推理。
- 输入:采样视频(2Hz)、辅助信号(轨迹、元动作如"轻微加速")。
- 流程:先仅用历史识别组件,后用未来解决歧义、排序因素、生成轨迹。提示引导避免因果混淆。
- 人工标注 :两阶段工具辅助流程。
- 第一阶段:仅看 2 秒历史窗口,识别关键组件(开放集,如交通规则、障碍物)。
- 第二阶段:看完整窗口(0-8 秒),确定驾驶决策(封闭集,如纵向"加速"、横向"左转"),撰写 CoC 轨迹(自然语言,锚定决策,仅用相关因素)。
- 工具支持:专用标注界面(区分历史/未来视频、可视化自车动力学图、鸟瞰图)。
- QA:严格检查(另一标注者 + 随机审核 10-20%),规则包括决策锚定、因果局部性、经济性。
- 评估:混合策略(LLM 结构化子任务 + 人工验证),对齐率 92%。结构化 CoC 较自由形式提升因果得分 132.8%。
- 自动标注 :使用先进 VLM(如 Gemini)多步推理。
- 输出:每个样本的 CoC 数据,包括决策、组件和轨迹文本。总规模 70 万,覆盖常规与长尾场景。
3.3. 预处理与格式化
- 数据格式 :每个训练样本建模为序列预测问题,格式为多模态 token 序列(视觉 + 语言 + 动作)。核心定义:
-
输入部分 :
- 观测序列:多摄像头、多时间步图像(历史 2 秒,10Hz 采样)和自车运动历史(位置、速度、偏航角、加速度、曲率)。
- 可选文本:用户指令、高阶导航(如"左转")。
-
输出部分 :
- 推理轨迹 (Reason):结构化 CoC 文本(自然语言,e.g., "由于前方红灯且无行人,自车应停车")。
- 元动作 (Meta-actions):可选,低阶原子动作序列(纵向/横向,如"加速" + "左转向")。
- 未来轨迹:6 秒预测(64 个路径点),采用控制表示(加速度 a、曲率 κ),基于单轮车动力学模型(避免噪声)。
-
完整序列格式 :统一 token 序列,如:视觉 token, 文本 token, 历史运动 token, \
- 轨迹编码:训练时离散化(量化为 token,128 个/轨迹);推理时连续嵌入(正弦位置编码 + MLP)。
- 视觉编码:多种 tokenizer(如单图像:160 token/图像;多摄像头三平面:288 token/时间步;视频 Flex:压缩 20 倍)。减少 token 数以支持实时。
-
存储格式 :JSON 或 HDF5 文件,每个样本为字典:
java{ "sample_id": "xxx", "observations": { "images": ["cam1_frame1.png", ..., "cam7_frameN.png"], // 或直接 tensor "ego_motion": [[x1, y1, yaw1, v1, a1, κ1], ...] // 历史序列 }, "coc_trajectory": "因果链文本...", // 结构化推理 "driving_decision": {"longitudinal": "accelerate", "lateral": "straight"}, "key_components": ["red_light", "pedestrian_clear"], "ground_truth_trajectory": [[a1, κ1], [a2, κ2], ...] // 6s 控制序列 }- 规模:70 万样本,拆分为训练/验证/测试集(地理隔离避免泄露)。
-
- 预处理步骤:批量处理,包括图像 resize、token 化、轨迹从位置推导控制(最小二乘 + 正则化)、数据增强(如随机裁剪历史窗口)。
- observations.images :多摄像头图像序列(e.g., 7 个相机,历史 2 秒,10Hz 采样)。使用视觉编码器 token 化:
- 默认:单图像 token 化(每图像 ~160 token,使用视觉 Transformer 将图像分成像素块,下采样)。
- 高效选项:多摄像头三平面 (triplane) 或视频 tokenizer (Flex),压缩 token 数(e.g., 20 倍减少),计算公式:
- 输出:视觉 token 序列。
- observations.ego_motion:自车历史运动序列(x, y, yaw, v, a, κ,历史窗口)。使用正弦位置编码 + MLP 投影嵌入到模型空间,作为额外 token 附加到序列。
- coc_trajectory:结构化因果链文本(自然语言推理)。在训练时作为真值标签;在推理时作为提示或忽略。
- driving_decision:高阶决策(纵向/横向,封闭集)。转换为 token 或嵌入,用于锚定推理(确保推理轨迹以决策为核心)。
- key_components:因果因素列表(开放集)。用于构建/验证推理,确保因果局部性(仅历史证据)。
- ground_truth_trajectory:真实未来轨迹控制序列(6 秒,\[a1, κ1, ...])。训练时离散化为 token(量化成 128 个离散值);推理时作为参考评估。
- sample_id:用于日志/跟踪,不直接输入模型。
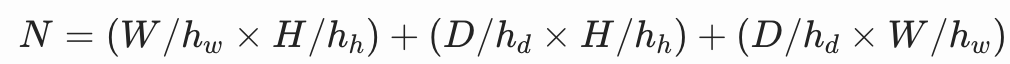
4.性能验证:从仿真到街道
评估涵盖开环指标(minADE 用于轨迹准确性)和 AlpaSim 中的闭环仿真,以及真实道路测试:
- 高难度收益:长尾情况下规划提升 12%。
- 安全指标:偏离车道率降低 35%,近距离碰撞率降低 25%。
- RL 影响:推理质量提升 45%,一致性提升 37%。
- 部署:英伟达 RTX 6000 上延迟 99 毫秒,成功城市导航。
Reddit讨论帖和YouTube科普视频赞扬 AR1 的实用性,一篇评论称其为"迈向更安全机器人出租车的一步"。

5.未来方向和开源计划
英伟达计划在 Hugging Face 上发布 AR1 变体和 CoC 子集,促进社区研究。探索包括按需推理、分层策略和世界模型集成,以更好地处理长尾场景。
正如 Jensen Huang 在 GTC DC 上预告的,这与英伟达的全栈生态系统(DGX、Omniverse、DRIVE AGX)相结合,用于扩展 L4 自治。 如果你对具身 AI 感兴趣,查看英伟达的招聘------他们正在招聘!
总之,Alpamayo-R1 不仅仅是一篇论文;它是更安全、更智能自动驾驶汽车的蓝图。深入 arXiv 或英伟达研究上的完整 41 页以获取细节。 你怎么看------因果推理是否会解锁真正的自治?在下方分享你的想法!
6.参考文章
https://www.mdpi.com/2032-6653/15/3/99
https://medium.com/data-science-collective/the-local-optimum-of-autonomy-de1969b77769
https://blogs.nvidia.com/blog/nvidia-leads-autonomous-vehicle-report/