信息检索领域本周热门论文精选
主要研究亮点
本期聚焦以下10项重要研究:
- Capital One的生产级LLM成对重排序优化方案
- 字节跳动在抖音上实现的十亿级端到端长序列推荐
- Netflix关于个性化推荐价值的结构化分析
- Meta将结构化人类先验知识整合到生成式推荐系统
- 医疗领域RAG系统的细粒度分析
- 推荐系统中协同信息的量化理解框架
- 降低智能体RAG系统token开销的框架
- 优化信息检索中语义精度和上下文连贯性的双层框架
- 腾讯大规模广告推荐的统一生成框架
- NVIDIA的通用多语言文本嵌入模型
研究详解
1 LLM优化实现实时成对重排序
Capital One的AI基础团队展示了如何让基于LLM的成对重排序在实时RAG系统中真正可用。他们把单次查询的延迟从61秒降到了0.37秒,提速166倍,同时性能几乎没有损失。
这个惊人的效果来自六个关键优化:
- 换用更小的模型(用FLAN-T5-XL替代FLAN-UL2)
- 采用单次滑动窗口重排序,专注于找出最相关的那一个文档
- 精心调整发送给重排序器的Top-K文档阈值
- 用更低精度(bfloat16)加载模型
- 使用单向顺序推理来缓解位置偏差,同时把比较次数减半
- 通过精心设计提示词,限制模型只生成单个token
这项研究证明,经过精心设计的优化策略,可以让计算成本高昂的成对重排序在对延迟敏感的生产环境中真正落地,实现亚秒级响应。
📚 论文链接:https://arxiv.org/abs/2511.07555
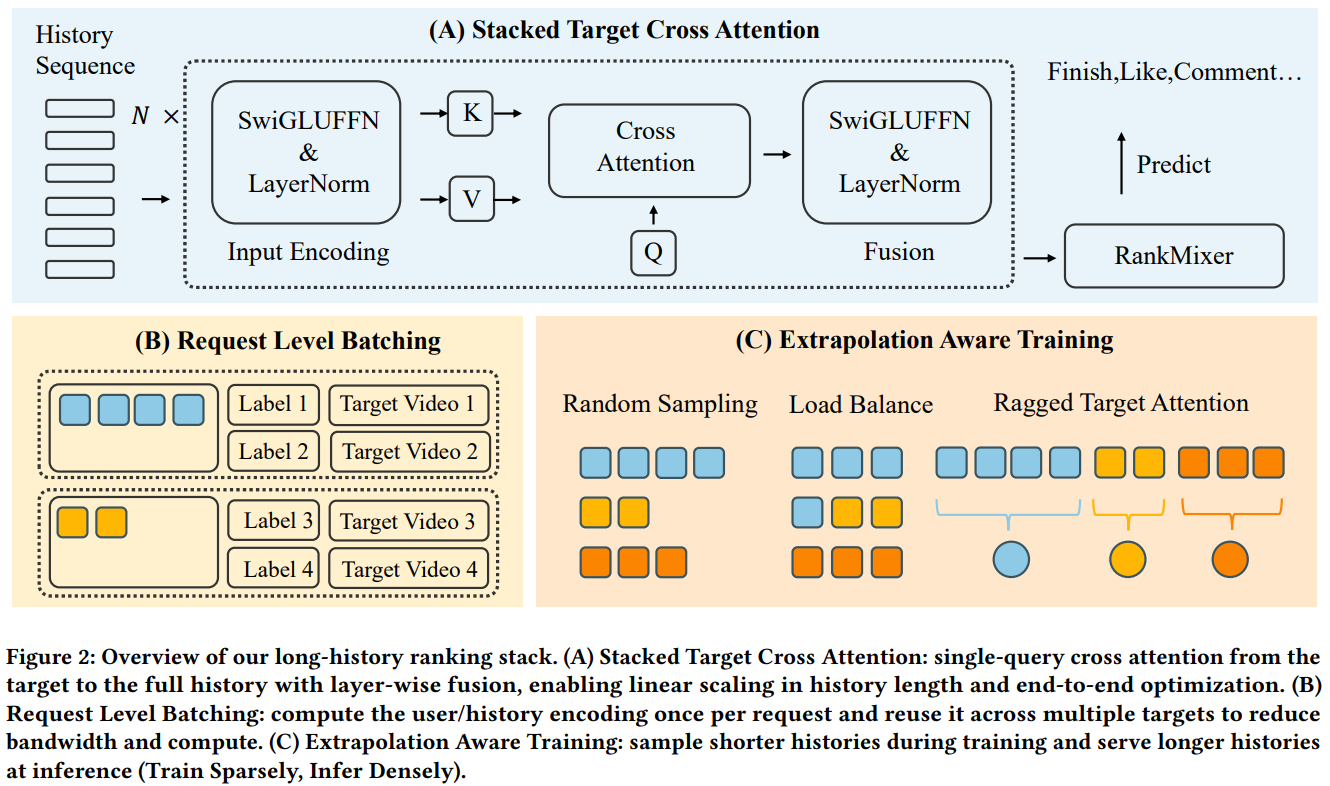
2 抖音上的万级序列端到端建模
字节跳动这篇论文解决了一个超级硬核的问题:如何在抖音(中国版TikTok)这种十亿级用户规模的平台上,处理长达10000的用户历史序列,还要保持严格的延迟限制。
三个核心创新点:
(1)堆叠目标到历史交叉注意力机制(STCA)
用线性复杂度的交叉注意力替代了二次复杂度的历史自注意力,把目标物品当作单个查询去关注完整的历史序列。
(2)请求级批处理(RLB)
这个训练策略很聪明,它会计算一次用户侧编码,然后在多个候选物品间复用,带宽降低77-84%,吞吐量提升2.2倍。
(3)长度外推训练方法
在平均约2k token的序列上训练,但推理时部署在10k长度的历史上,把训练成本和部署时的上下文长度解耦了。
系统展现出明显的规模定律特性,性能随着序列长度和模型容量的增加而可预测地提升。这项工作表明,通过精心的架构选择和系统级优化,可以让真正的端到端长序列建模在十亿级推荐场景中落地,避免了传统"先召回再排序"两阶段范式固有的信息损失。
📚 论文链接:https://arxiv.org/abs/2511.06077
3 Netflix:个性化推荐的真实价值
Netflix开发了一个离散选择模型,分别量化了个性化推荐的价值和底层内容偏好。用的是2025年初35天里200万美国用户和约7000个标题的数据。
模型嵌入了推荐诱导效用、低秩偏好异质性,以及基于观看历史的灵活状态依赖。研究团队利用Netflix推荐算法探索产生的特异性变化来识别这些组成部分,并用实验数据验证了模型,取得了很强的样本外性能。
关键发现很有意思:
- 如果把当前推荐系统换成矩阵分解或基于热度的算法,参与度会分别下降4%和12%,消费多样性也会降低
- 推荐效果可以分解为:选择效应(51.3%)、曝光效应(6.8%)和定向效应(41.9%)
- 有效的个性化,而不仅仅是机械性曝光,驱动了大部分消费增长
- 中等热度的内容从定向推荐中获益最多,而不是那些大热或超小众的内容
研究证明,现代推荐算法比早期的矩阵分解等方法提供了实质性的额外价值。
📚 论文链接:https://arxiv.org/abs/2511.07280
4 Meta:用多头解码引导生成式推荐器
Meta AI提出了一个框架,把结构化人类先验知识(像物品分类、时间模式、交互类型这些领域知识)直接整合到生成式推荐系统里。
不同于事后调整或完全无监督学习,这个方法使用多头解码,每个适配器头专门建模用户意图的特定方面,沿着可解释的维度(比如物品类别、短期vs长期兴趣、交互模式)。
框架是主干无关的,包含一个层次化组合策略,可以建模不同先验类型间的复杂交互,同时缓解稀有组合的数据稀疏性问题。
在三个大规模数据集上用HSTU和HLLM架构评估,这个方法在标准准确性指标(Recall、NDCG)和超越准确性的目标(包括多样性、新颖性、个性化)上都表现出一致的改进。
📚 论文链接:https://arxiv.org/abs/2511.10492
👨🏽💻 代码:https://github.com/zhykoties/Multi-Head-Recommendation-with-Human-Priors
5 重新思考医疗RAG:大规模系统性专家评估
这篇来自Kim等人的论文对医疗应用中的RAG系统做了全面评估,揭示了一些颠覆常识的重大局限性。
18位医学专家贡献了超过80000条标注,评估了GPT-4o和Llama-3.1-8B在200个查询上的表现,系统性地评估了RAG流程的三个组件:证据检索、证据选择和响应生成。
研究发现真的很打脸:
- 标准RAG常常让性能变差而不是变好(只有22%的检索段落是相关的)
- 模型在证据选择上很挣扎(精确率41-43%,召回率27-49%)
- 与非RAG基线相比,事实性和完整性分别下降了6%和5%
研究确定检索不足和证据选择差是主要瓶颈,模型经常纳入不相关的内容,同时遗漏可用的相关信息。
为了解决这些问题,作者提出了两个实用干预措施:证据过滤(移除不相关段落)和查询重构(提高检索精度)。组合使用时,这些策略在挑战性基准上产生了实质性改进。
这项研究挑战了在医疗领域默认应用RAG的做法,强调了在可靠的临床AI应用中进行阶段性评估和深思熟虑的系统设计的必要性。
📚 论文链接:https://arxiv.org/abs/2511.06738
👨🏽💻 代码:https://github.com/Yale-BIDS-Chen-Lab/medical-rag
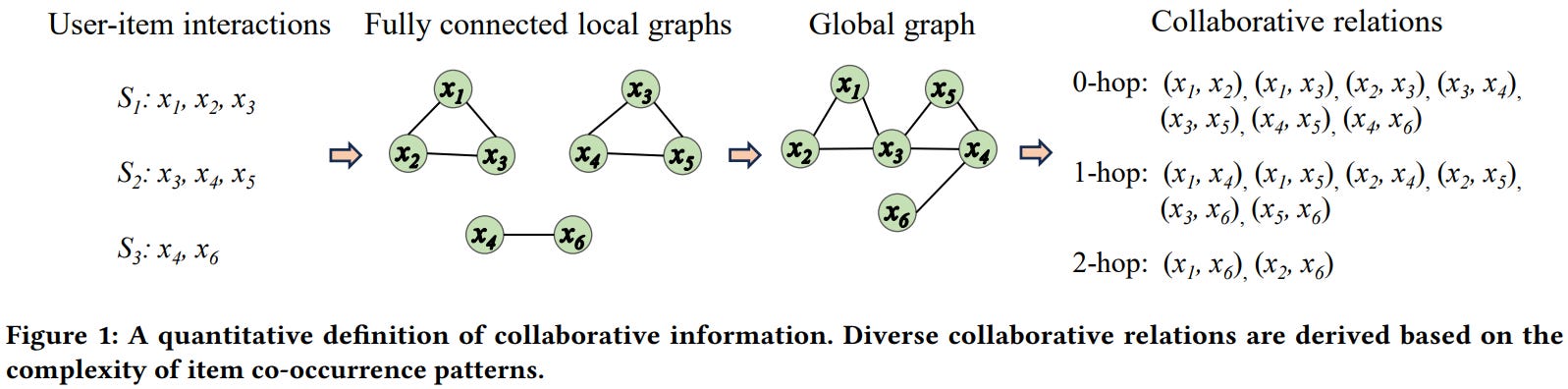
6 真的理解协同信息了吗?实证研究
Zhang等人对推荐系统中的协同信息进行了系统性的实证研究。
作者通过物品共现模式定义协同信息,识别出三个关键特征:传递性、层次性和冗余性。他们提出根据复杂性将协同关系(CR)分类(0-hop、1-hop、2-hop等),其中0-hop代表直接共现,更高阶关系代表越来越复杂的模式。
通过在六个基准数据集上使用传统方法、神经网络和基于LLM的方法进行实验,研究揭示了几个关键发现:
- 直接协同关系很稀少但高度有价值
- 间接关系主导物品交互
- 推荐系统在简单关系上的表现明显好于复杂关系
研究表明,神经模型主要通过捕获复杂协同关系的能力超越传统技术,而基于LLM的方法尽管在其他领域很成功,但在从用户-物品交互中编码协同知识方面还是有困难。
📚 论文链接:https://arxiv.org/abs/2511.06905
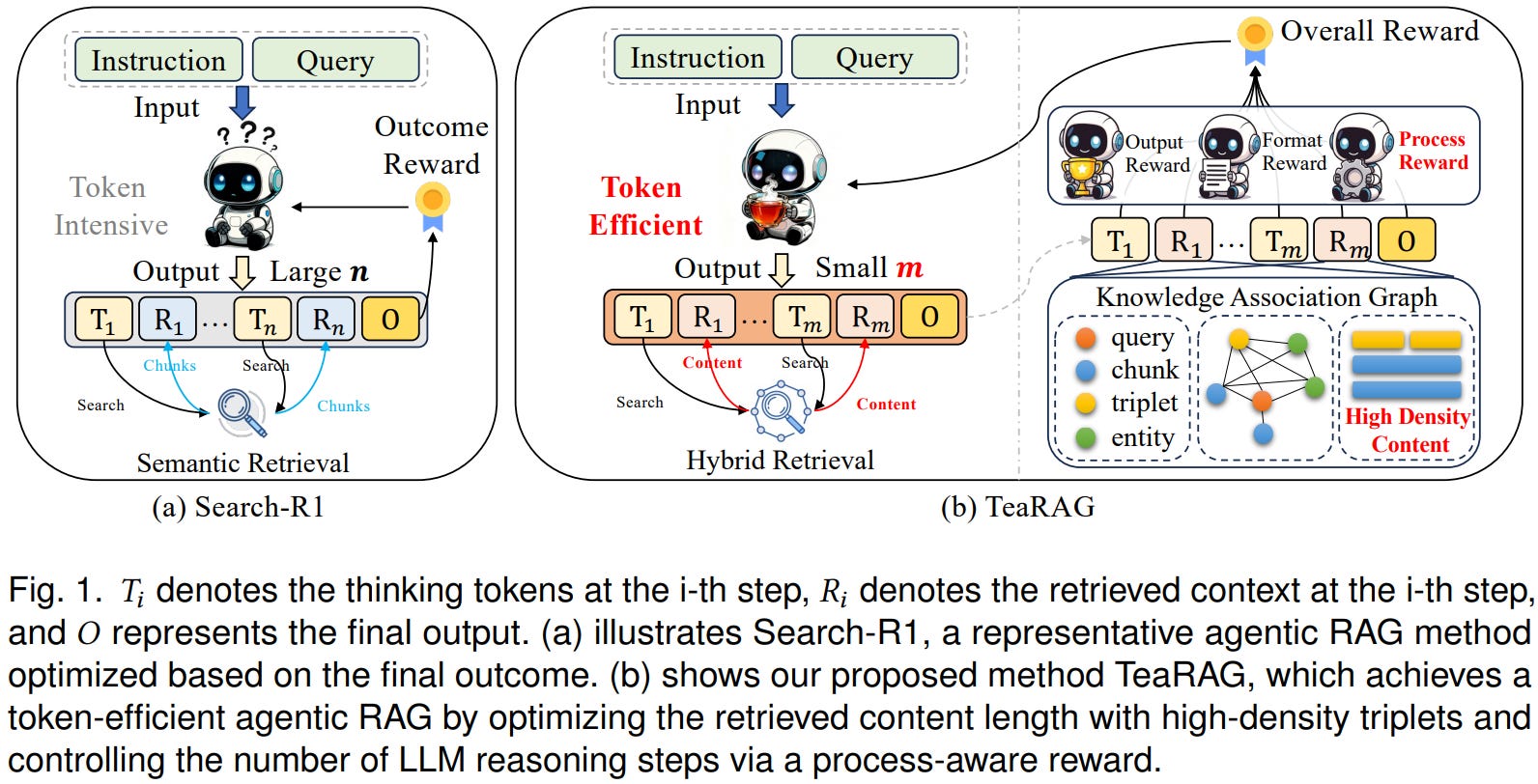
7 TeaRAG:Token高效的智能体RAG框架
Zhang等人提出的TeaRAG解决了当前智能体系统中过高的token开销问题。现有系统为了追求准确性,通过多轮检索和推理牺牲了效率。
框架通过两个关键机制实现效率提升:
(1)压缩检索内容
- 用简洁的知识三元组增强基于块的语义检索,配合图检索
- 从语义相似度和共现关系构建知识关联图
- 应用个性化PageRank过滤冗余信息,同时保留必要上下文
(2)减少推理步骤
通过迭代过程感知直接偏好优化(IP-DPO),使用一个奖励函数,通过子查询生成、上下文检索和总结维度的知识匹配来评估知识充分性,同时惩罚过度的推理步骤。
训练范式包括在MuSiQue数据集上进行监督微调以建立基本推理能力,然后进行迭代DPO,将采样和训练阶段分离以实现高效优化。
在六个QA基准上评估,TeaRAG在Llama3-8B-Instruct上将平均精确匹配分数提高了4%,在Qwen2.5-14B-Instruct上提高了2%,同时输出token分别减少了61%和59%。
📚 论文链接:https://arxiv.org/abs/2511.05385
👨🏽💻 代码:https://github.com/Applied-Machine-Learning-Lab/TeaRAG
8 搜索不等于检索:RAG中语义匹配与上下文组装的解耦
Dell Technologies提出的SINR(Search-Is-Not-Retrieve)框架通过双层架构将语义匹配与上下文组装分离。
传统RAG系统使用统一的块大小,导致必须在精度(小块)和上下文(大块)之间权衡。SINR通过采用细粒度搜索块(约100-200 token)进行精确语义匹配,以及粗粒度检索块(600-1000 token)提供充足推理上下文,解决了这个问题。
系统使用确定性父映射函数,将每个搜索块连接到恰好一个检索块,使检索过程能够首先通过精确的语义搜索识别相关内容,然后扩展到上下文完整的段落,不产生额外计算开销。
这个架构带来几个优势:
- 独立优化搜索精度和上下文质量
- 当多个搜索块共享同一父块时自然去重
- 从查询到答案的可追溯性更好
- 可扩展到数十亿文档,映射开销可忽略不计(不到嵌入存储的1%)
📚 论文链接:https://arxiv.org/abs/2511.04939
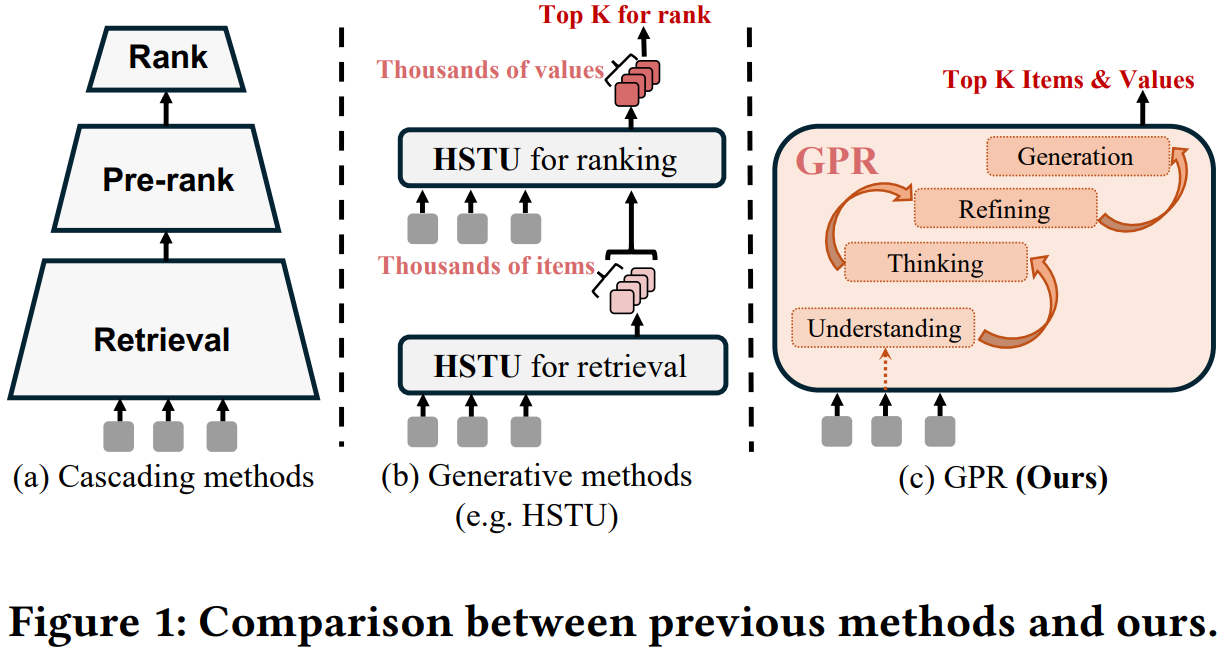
9 腾讯GPR:大规模广告推荐的生成式预训练统一范式
腾讯推出的GPR(Generative Pre-trained Recommender)是一个端到端生成框架,用统一的单一模型方法替代了传统的多阶段级联系统(召回-粗排-精排)。
系统解决了三个关键挑战:广告和有机内容混合带来的极端数据异质性、训练和推理中的效率-灵活性权衡,以及多方价值优化。
GPR的核心创新包括:
- RQ-Kmeans+:改进的token化方法,将异质内容映射到共享语义ID空间
- 异构层次解码器(HHD)架构:具有双解码器,将用户意图建模与广告生成分离
- 多阶段训练策略:结合多token预测、价值感知微调和层次增强策略优化(HEPO)
部署在腾讯视频号广告系统中,GPR通过大量A/B测试,在GMV和CTCVR等关键指标上展现出显著改进。
📚 论文链接:https://arxiv.org/abs/2511.10138
10 NVIDIA的通用多语言文本嵌入模型
NVIDIA推出的llama-embed-nemotron-8b是一个开源文本嵌入模型,截至2025年10月在多语言大规模文本嵌入基准(MMTEB)上达到了最先进的性能。
基于Llama-3.1-8B架构并采用修改的双向注意力,该模型在250多种语言的检索、分类和语义相似性任务上表现出色。
训练利用了1610万查询-文档对的数据混合,结合了770万公开样本和840万从各种开放权重LLM合成生成的样本。
关键创新包括:
- 适应特定用例的指令感知嵌入
- 仅使用硬负样本的简化对比损失(优于批内或同塔负样本方法)
- 跨六个不同检查点的模型合并以增强鲁棒性
模型在MMTEB上获得39573个Borda投票,超越了Gemini Embedding和Qwen3-Embedding等竞品。
📚 论文链接:https://arxiv.org/abs/2511.07025
👨🏽💻 模型:https://huggingface.co/nvidia/llama-embed-nemotron-8b
额外工具推荐
🛠️ EncouRAGe:本地、快速、可靠的RAG评估工具
EncouRAGe是一个Python框架,旨在通过为数据集、检索方法、推理和指标提供模块化结构来支持RAG系统的开发和评估。
它通过面向对象的类型清单标准化数据,通过统一的工厂接口提供十种可配置的RAG方法,并集成了本地或基于云的LLM和嵌入模型。框架包含二十多个生成器、检索和基于LLM的评估指标,支持多种向量存储。
📝 论文:https://arxiv.org/abs/2511.04696
👨🏽💻 代码:https://anonymous.4open.science/r/encourage-B501/
总结
这周的论文涵盖面很广,从生产环境的系统优化到学术研究的深度评估,每一篇都在各自领域带来了新的见解。特别值得关注的是医疗RAG的评估研究,它提醒大家不要盲目套用RAG,而要针对具体场景做精心设计。
想深入了解某个方向的话,建议点开相关论文仔细研读。这个领域的进展速度真的很快,保持关注才能跟上节奏。