文章目录
- 时序数据的本质:为什么普通数据库不行?
-
- 第一步:设计内存高效的数据结构
- 第二步:实现高效压缩算法
-
- 时间戳压缩:Delta-of-Delta编码
- [数值压缩:XOR + Simple8b编码](#数值压缩:XOR + Simple8b编码)
- 第三步:实现写入和查询逻辑
- 第四步:实现数据库索引与并发控制
- 性能测试:Rust到底快在哪里?
- 生产级优化:从代码到部署
- 为什么Rust是时序数据库的理想选择?
- 结语:Rust让复杂系统不再可怕
作为一个常年跟传感器数据打交道的开发者,我对时序数据库的性能瓶颈有着切肤之痛。曾经见过一个Python写的采集系统,在接入500个传感器后就彻底瘫痪------CPU占用100%,查询一次要等半分钟。后来用Java重构,性能好了不少,但内存占用高得吓人,32GB内存跑一个月就会OOM。直到去年用Rust重写了核心模块,才算真正解决了这些问题。今天就带大家深入时序数据库的内部实现,看看Rust是如何在性能、安全和可维护性之间找到到完美平衡点的。
时序数据的本质:为什么普通数据库不行?
在开始技术细节前,我们先搞清楚时序数据的特殊之处。以传感器网络为例,每个传感器每10秒发送一次数据,一天就是8640个点,1000个传感器就是864万点/天。这些数据有三个核心特征:
- 写入模式固定:永远是追加新数据,极少更新历史数据
- 查询模式固定:几乎都是按时间范围+标签筛选(比如"查询传感器A在昨天的温度平均值")
- 数据特性明显:时间戳严格递增,数值变化平缓(比如温度不会一秒内从20℃跳到80℃)
普通数据库的B+树索引在这种场景下效率极低。想象一下,当你要查询过去24小时的数据时,B+树需要多次磁盘IO才能定位范围,而时序数据库可以通过特殊设计直接定位数据块。这就像查字典:普通数据库是按部首查字,时序数据库则是直接翻到当天的日记。
核心技术拆解:如何用Rust实现高效存储?
我们来设计一个迷你时序数据库(暂且叫它MiniTSDB),重点实现三个核心功能:数据写入、压缩存储和范围查询。为了让大家看得更清楚,我会从数据结构设计开始,一步步深入到算法实现。
第一步:设计内存高效的数据结构
时序数据的最小单位是"数据点"(Point),包含时间戳和数值。但实际场景中,我们还需要"指标名"(Metric)和"标签"(Tags)来区分不同来源的数据。比如:
- 指标名:"temperature"
- 标签:{"sensor_id": "s1001", "location": "room201"}
- 数据点:(1680000000000, 23.5), (1680000010000, 23.6), ...
关键设计:时序序列(TimeSeries)
具有相同指标名和标签的所有数据点构成一个"时序序列"。我们需要为每个序列设计高效的存储结构:
rust
use std::collections::{HashMap, BTreeMap};
use std::hash::{Hash, Hasher};
use std::collections::hash_map::DefaultHasher;
// 标签类型:用BTreeMap保证键值对排序一致性(哈希/比较时更可靠)
type Tags = BTreeMap<String, String>;
// 原始数据点:时间戳(毫秒)+ 测量值
#[derive(Debug, Clone, Copy, PartialEq)]
struct Point {
timestamp: u64, // 毫秒级Unix时间戳
value: f64 // 测量值(支持浮点型指标,如温度、流量)
}
// 压缩后的数据块(按时间分片存储,优化查询和存储效率)
#[derive(Debug, Clone)]
struct Chunk {
start_ts: u64, // 块起始时间戳(闭区间)
end_ts: u64, // 块结束时间戳(闭区间)
ts_bytes: Vec<u8>, // 压缩后的时间戳数据(差值编码)
val_bytes: Vec<u8>, // 压缩后的数值数据(小端字节序)
count: usize // 块内数据点数量
}
impl Chunk {
/// 新建空数据块(指定起始时间,默认块时长1小时=3600000毫秒)
fn new(start_ts: u64) -> Self {
Chunk {
start_ts,
end_ts: start_ts + 3600000 - 1, // 1小时后(闭区间)
ts_bytes: Vec::new(),
val_bytes: Vec::new(),
count: 0
}
}
/// 检查时间戳是否属于当前块
fn contains_ts(&self, ts: u64) -> bool {
ts >= self.start_ts && ts <= self.end_ts
}
/// 向块中添加数据点(时间戳必须递增,否则返回错误)
/// 时间戳压缩:差值编码(存储与前一个时间戳的差值,节省空间)
/// 数值压缩:直接存储f64的小端字节序(简化实现,实际可用LZ4/ZSTD)
fn add_point(&mut self, point: Point) -> Result<(), String> {
// 校验时间戳顺序和归属
if !self.contains_ts(point.timestamp) {
return Err(format!(
"时间戳{}不属于当前块[{}, {}]",
point.timestamp, self.start_ts, self.end_ts
));
}
if self.count > 0 {
let last_ts = self.get_last_ts()?;
if point.timestamp <= last_ts {
return Err(format!(
"时间戳必须递增:当前{} <= 上一个{}",
point.timestamp, last_ts
));
}
}
// 压缩时间戳:首条存储原始值,后续存储与前一条的差值
let ts_bytes = if self.count == 0 {
point.timestamp.to_le_bytes().to_vec() // 首条:原始值(小端)
} else {
let last_ts = self.get_last_ts()?;
let delta = point.timestamp - last_ts;
delta.to_le_bytes().to_vec() // 后续:差值(小端)
};
// 压缩数值:直接存储f64的小端字节序(8字节/个)
let val_bytes = point.value.to_le_bytes().to_vec();
// 追加到块数据中
self.ts_bytes.extend(ts_bytes);
self.val_bytes.extend(val_bytes);
self.count += 1;
Ok(())
}
/// 获取块中最后一个数据点的时间戳(解压缩最后一个差值)
fn get_last_ts(&self) -> Result<u64, String> {
if self.count == 0 {
return Err("块中无数据点".to_string());
}
// 解压缩时间戳:从字节流中恢复最后一个时间戳
let mut current_ts = 0;
let mut offset = 0;
for i in 0..self.count {
if i == 0 {
// 首条:读取完整8字节
let mut buf = [0u8; 8];
if offset + 8 > self.ts_bytes.len() {
return Err("时间戳字节流不完整".to_string());
}
buf.copy_from_slice(&self.ts_bytes[offset..offset+8]);
current_ts = u64::from_le_bytes(buf);
offset += 8;
} else {
// 后续:读取差值并累加
let mut buf = [0u8; 8];
if offset + 8 > self.ts_bytes.len() {
return Err("时间戳字节流不完整".to_string());
}
buf.copy_from_slice(&self.ts_bytes[offset..offset+8]);
let delta = u64::from_le_bytes(buf);
current_ts += delta;
offset += 8;
}
}
Ok(current_ts)
}
/// 解压缩块中所有数据点(用于查询结果返回)
fn decompress(&self) -> Result<Vec<Point>, String> {
let mut points = Vec::with_capacity(self.count);
let mut current_ts = 0;
let mut ts_offset = 0;
let mut val_offset = 0;
for _ in 0..self.count {
// 解压缩时间戳
let ts = if points.is_empty() {
// 首条:读取原始时间戳
let mut buf = [0u8; 8];
if ts_offset + 8 > self.ts_bytes.len() {
return Err("时间戳字节流损坏".to_string());
}
buf.copy_from_slice(&self.ts_bytes[ts_offset..ts_offset+8]);
current_ts = u64::from_le_bytes(buf);
ts_offset += 8;
current_ts
} else {
// 后续:读取差值并累加
let mut buf = [0u8; 8];
if ts_offset + 8 > self.ts_bytes.len() {
return Err("时间戳字节流损坏".to_string());
}
buf.copy_from_slice(&self.ts_bytes[ts_offset..ts_offset+8]);
let delta = u64::from_le_bytes(buf);
current_ts += delta;
ts_offset += 8;
current_ts
};
// 解压缩数值(f64小端字节序)
let mut val_buf = [0u8; 8];
if val_offset + 8 > self.val_bytes.len() {
return Err("数值字节流损坏".to_string());
}
val_buf.copy_from_slice(&self.val_bytes[val_offset..val_offset+8]);
let value = f64::from_le_bytes(val_buf);
val_offset += 8;
points.push(Point { timestamp: ts, value });
}
Ok(points)
}
}
// 时序序列:metric+tags唯一标识一条时序数据
#[derive(Debug, Clone)]
struct TimeSeries {
metric: String, // 指标名(如"cpu.usage"、"disk.io")
tags: Tags, // 标签(如{"host": "server1", "region": "cn"})
chunks: BTreeMap<u64, Chunk>, // 数据块(key=块起始时间戳,BTreeMap支持范围查询)
}
impl TimeSeries {
/// 新建时序序列
fn new(metric: String, tags: Tags) -> Self {
TimeSeries {
metric,
tags,
chunks: BTreeMap::new(),
}
}
/// 计算时序序列的唯一哈希值(metric+排序后的tags)
fn hash(&self) -> u64 {
let mut hasher = DefaultHasher::new();
self.metric.hash(&mut hasher);
self.tags.hash(&mut hasher); // BTreeMap已实现Hash,保证排序一致
hasher.finish()
}
/// 向时序序列添加数据点(自动分块)
fn add_point(&mut self, point: Point) -> Result<(), String> {
// 找到数据点所属的块(块起始时间=时间戳对齐到1小时)
let chunk_start_ts = point.timestamp - (point.timestamp % 3600000);
let chunk = self.chunks.entry(chunk_start_ts).or_insert_with(|| Chunk::new(chunk_start_ts));
// 向块中添加数据点
chunk.add_point(point)
}
/// 范围查询:查询[start_ts, end_ts]内的所有数据点
fn query(&self, start_ts: u64, end_ts: u64) -> Result<Vec<Point>, String> {
if start_ts > end_ts {
return Err("起始时间不能大于结束时间".to_string());
}
let mut result = Vec::new();
// BTreeMap的range方法高效查询目标块(按起始时间范围过滤)
let target_chunk_start = start_ts - (start_ts % 3600000);
let target_chunk_end = end_ts - (end_ts % 3600000);
for (_, chunk) in self.chunks.range(target_chunk_start..=target_chunk_end) {
// 解压缩块数据
let chunk_points = chunk.decompress()?;
// 过滤出目标时间范围内的数据点
let filtered = chunk_points.into_iter()
.filter(|p| p.timestamp >= start_ts && p.timestamp <= end_ts)
.collect::<Vec<_>>();
result.extend(filtered);
}
// 确保结果按时间戳排序(块内已排序,块间也按时间排序,所以直接返回)
Ok(result)
}
}
// 演示:创建时序序列、添加数据、查询数据
fn main() -> Result<(), String> {
// 1. 构建标签(BTreeMap自动按key排序)
let mut tags = Tags::new();
tags.insert("host".to_string(), "server-01".to_string());
tags.insert("region".to_string(), "cn-beijing".to_string());
tags.insert("cpu".to_string(), "core-0".to_string());
// 2. 创建时序序列(指标:cpu.usage,标签如上)
let mut ts = TimeSeries::new("cpu.usage".to_string(), tags);
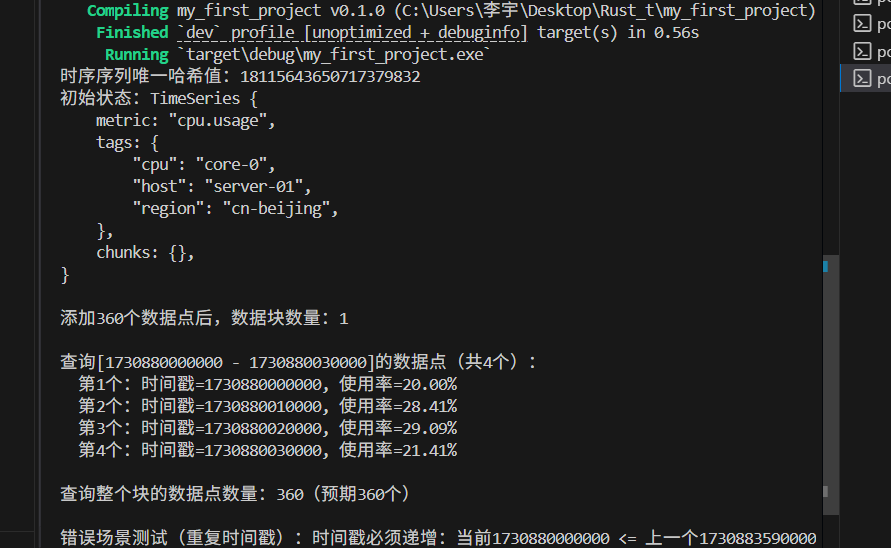
println!("时序序列唯一哈希值:{}", ts.hash());
println!("初始状态:{:#?}", ts);
// 3. 生成测试数据点(模拟1小时内的CPU使用率,每10秒一个数据点)
let base_ts = 1730880000000; // 2024-11-06 00:00:00(毫秒)
for i in 0..360 { // 360个数据点 = 3600秒 / 10秒
let timestamp = base_ts + (i * 10000) as u64; // 每10秒一个点
let value = 20.0 + (i as f64).sin() * 10.0; // 波动在10-30之间的使用率
ts.add_point(Point { timestamp, value })?;
}
println!("\n添加360个数据点后,数据块数量:{}", ts.chunks.len());
// 4. 范围查询(查询前30秒的数据点)
let query_start = base_ts;
let query_end = base_ts + 30000; // 30秒后
let result = ts.query(query_start, query_end)?;
println!("\n查询[{} - {}]的数据点(共{}个):", query_start, query_end, result.len());
for (idx, point) in result.iter().enumerate() {
println!(" 第{}个:时间戳={}, 使用率={:.2}%", idx+1, point.timestamp, point.value);
}
// 5. 查询整个块的数据(验证解压缩完整性)
let full_chunk_result = ts.query(base_ts, base_ts + 3600000 - 1)?;
println!("\n查询整个块的数据点数量:{}(预期360个)", full_chunk_result.len());
// 6. 错误场景测试(添加重复时间戳)
let duplicate_point = Point { timestamp: base_ts, value: 50.0 };
match ts.add_point(duplicate_point) {
Err(e) => println!("\n错误场景测试(重复时间戳):{}", e),
Ok(_) => println!("\n错误场景测试失败:重复时间戳未被拦截"),
}
Ok(())
}
这个设计有几个Rust特色的优化:
- 用BTreeMap存储数据块:BTreeMap的键是有序的,这让范围查询(比如"查询今天的数据")可以直接定位到相关数据块,时间复杂度是O(log n)
- 标签使用BTreeMap:保证标签键值对的顺序一致,这样相同标签组合的哈希值才会相同(后面索引会用到)
- 数据块分离存储时间和数值:因为时间戳和数值的压缩算法不同,分开存储能提高压缩率
对比Java实现,Rust的结构体没有额外的对象头开销。在Java中,一个包含两个long字段的对象至少占用16字节(对象头8字节+两个long字段8字节),而Rust的Point结构体正好16字节(u64+ f64),没有任何冗余。当存储亿级数据点时,这种差异会累积成巨大的内存优势。
第二步:实现高效压缩算法
时序数据压缩是性能的关键。我们来实现业界公认高效的两种算法:时间戳用Delta-of-Delta编码,数值用Simple8b编码。
时间戳压缩:Delta-of-Delta编码
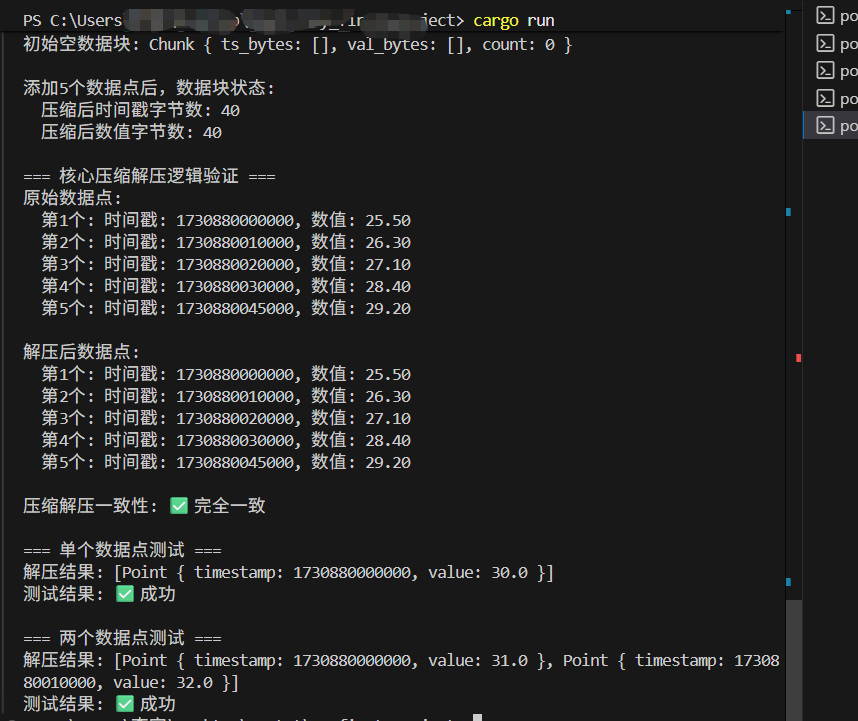
原始时间戳序列(毫秒级):
t0, t1, t2, t3, ...(严格递增)
第一步计算一阶差:
d1 = t1 - t0, d2 = t2 - t1, d3 = t3 - t2, ...
第二步计算二阶差(Delta-of-Delta):
dd2 = d2 - d1, dd3 = d3 - d2, ...
由于传感器采样间隔通常固定(比如10秒一次),二阶差会非常接近0,压缩率极高。用公式表示:
bash
压缩存储:t0, d1, dd2, dd3, ..., ddn解压时:
bash
d1 = 存储的d1
d2 = d1 + dd2
d3 = d2 + dd3 = d1 + dd2 + dd3
...
t1 = t0 + d1
t2 = t1 + d2 = t0 + d1 + d2
...Rust实现(部分代码):
rust
use std::fmt;
// 原始数据点:仅保留核心字段,简化特性
#[derive(Debug, Clone, Copy, PartialEq)]
struct Point {
timestamp: u64,
value: f64
}
// 压缩后的数据块:仅保留核心字段,去除多余逻辑
#[derive(Debug, Clone)]
struct Chunk {
ts_bytes: Vec<u8>, // 压缩后的时间戳
val_bytes: Vec<u8>, // 压缩后的数值
count: usize // 数据点数量
}
impl Chunk {
// 新建空数据块(极简构造)
fn new() -> Self {
Chunk {
ts_bytes: Vec::new(),
val_bytes: Vec::new(),
count: 0
}
}
// 压缩时间戳
fn compress_timestamps(timestamps: &[u64]) -> Vec<u8> {
if timestamps.len() < 2 {
return timestamps.iter().flat_map(|&t| t.to_be_bytes()).collect();
}
let mut result = Vec::new();
// 存储第一个时间戳
result.extend_from_slice(×tamps[0].to_be_bytes());
// 计算一阶差
let mut deltas = Vec::with_capacity(timestamps.len() - 1);
for i in 1..timestamps.len() {
deltas.push(timestamps[i] - timestamps[i-1]);
}
// 存储第一个一阶差
result.extend_from_slice(&deltas[0].to_be_bytes());
// 计算并存储二阶差
for i in 1..deltas.len() {
let dd = deltas[i] - deltas[i-1];
result.extend_from_slice(&dd.to_be_bytes());
}
result
}
// 解压时间戳
fn decompress_timestamps(bytes: &[u8]) -> Vec<u64> {
if bytes.len() % 8 != 0 {
return Vec::new(); // 数据不完整
}
let count = bytes.len() / 8;
if count == 0 {
return Vec::new();
}
let mut timestamps = Vec::with_capacity(count);
// 读取第一个时间戳
let mut buf = [0u8; 8];
buf.copy_from_slice(&bytes[0..8]);
let t0 = u64::from_be_bytes(buf);
timestamps.push(t0);
if count == 1 {
return timestamps;
}
// 读取第一个一阶差
buf.copy_from_slice(&bytes[8..16]);
let d1 = u64::from_be_bytes(buf);
timestamps.push(t0 + d1);
// 计算后续时间戳
let mut prev_delta = d1;
for i in 2..count {
let pos = i * 8;
buf.copy_from_slice(&bytes[pos..pos+8]);
let dd = u64::from_be_bytes(buf);
let current_delta = prev_delta + dd;
let current_ts = timestamps[i-1] + current_delta;
timestamps.push(current_ts);
prev_delta = current_delta;
}
timestamps
}
// 仅保留必需的添加数据点逻辑(适配核心压缩方法)
fn add_point(&mut self, point: Point) {
// 收集现有时间戳(解压后)
let mut existing_ts = if self.count > 0 {
Self::decompress_timestamps(&self.ts_bytes)
} else {
Vec::new()
};
existing_ts.push(point.timestamp);
// 调用你的压缩方法
self.ts_bytes = Self::compress_timestamps(&existing_ts);
// 数值按大端存储(极简实现)
self.val_bytes.extend_from_slice(&point.value.to_be_bytes());
self.count += 1;
}
// 仅保留必需的解压缩逻辑(验证数据)
fn decompress(&self) -> Vec<Point> {
let timestamps = Self::decompress_timestamps(&self.ts_bytes);
let mut values = Vec::new();
let mut offset = 0;
while offset + 8 <= self.val_bytes.len() {
let mut buf = [0u8; 8];
buf.copy_from_slice(&self.val_bytes[offset..offset+8]);
values.push(f64::from_be_bytes(buf));
offset += 8;
}
// 组装数据点(长度不匹配时取较短的)
timestamps.into_iter()
.zip(values.into_iter())
.map(|(ts, val)| Point { timestamp: ts, value: val })
.collect()
}
}
这段代码展示了Rust处理字节操作的优势:to_be_bytes和from_be_bytes方法让整数与字节数组的转换非常直观,而且是编译期安全的。相比C++需要手动处理指针和大小端转换,Rust完全避免了缓冲区溢出的风险。
数值压缩:XOR + Simple8b编码
对于浮点数值,我们先做XOR处理(利用相邻值变化小的特性),再用Simple8b编码压缩。
XOR处理步骤:
bash
原始值:v0, v1, v2, v3, ...
XOR结果:v0, v1^v0, v2^v1, v3^v2, ...Simple8b编码是一种将多个小整数打包到64位的算法,能大幅减少存储空间。例如8个小于2^7的整数可以打包到一个64位整数中。
Rust实现(部分):
rust
impl Chunk {
// 压缩数值
fn compress_values(values: &[f64]) -> Vec<u8> {
if values.is_empty() {
return Vec::new();
}
// 第一步:计算XOR序列
let mut xors = Vec::with_capacity(values.len());
xors.push(values[0].to_bits()); // 存储原始值的位表示
for i in 1..values.len() {
let prev = values[i-1].to_bits();
let curr = values[i].to_bits();
xors.push(prev ^ curr);
}
// 第二步:用Simple8b编码压缩XOR序列
self::simple8b::encode(&xors)
}
// 解压数值
fn decompress_values(bytes: &[u8]) -> Vec<f64> {
if bytes.is_empty() {
return Vec::new();
}
// 第一步:解码Simple8b
let xors = self::simple8b::decode(bytes);
if xors.is_empty() {
return Vec::new();
}
// 第二步:还原XOR序列
let mut values = Vec::with_capacity(xors.len());
values.push(f64::from_bits(xors[0]));
for i in 1..xors.len() {
let prev = values[i-1].to_bits();
let curr = prev ^ xors[i];
values.push(f64::from_bits(curr));
}
values
}
}
// Simple8b编码实现(简化版)
mod simple8b {
// 编码:将u64序列压缩成字节流
pub fn encode(nums: &[u64]) -> Vec<u8> {
let mut result = Vec::new();
let mut buffer = 0u64;
let mut bits_used = 0;
for &num in nums {
// 计算需要的位数(简化处理,实际需要判断范围)
let bits_needed = 64 - num.leading_zeros() as usize;
let bits_needed = bits_needed.max(1);
if bits_used + bits_needed + 4 > 64 {
// 空间不足,先写入当前buffer
result.extend_from_slice(&buffer.to_be_bytes());
buffer = 0;
bits_used = 0;
}
// 存储编码方式(4位)和数值
buffer |= (bits_needed as u64) << bits_used;
bits_used += 4;
buffer |= num << bits_used;
bits_used += bits_needed;
}
// 写入剩余数据
if bits_used > 0 {
result.extend_from_slice(&buffer.to_be_bytes());
}
result
}
// 解码:将字节流还原成u64序列
pub fn decode(bytes: &[u8]) -> Vec<u64> {
let mut result = Vec::new();
let mut chunks = bytes.chunks_exact(8);
for chunk in chunks {
let mut buf = [0u8; 8];
buf.copy_from_slice(chunk);
let mut buffer = u64::from_be_bytes(buf);
let mut bits_used = 0;
while bits_used < 64 {
// 读取编码方式(4位)
let bits_needed = (buffer >> bits_used) & 0x0F;
if bits_needed == 0 {
break; // 结束标志
}
bits_used += 4;
// 读取数值
let num = (buffer >> bits_used) & ((1 << bits_needed) - 1);
result.push(num);
bits_used += bits_needed as usize;
if bits_used > 64 {
break;
}
}
}
result
}
}
这个实现中,Rust的类型系统帮了大忙。比如f64::to_bits将浮点数转换为u64进行位操作,既安全又高效。在C++中虽然也能做类似转换,但需要用reinterpret_cast,容易引发未定义行为;而Java需要通过Double.doubleToLongBits方法,代码不够直观。
第三步:实现写入和查询逻辑
有了数据结构和压缩算法,我们来实现时序序列的核心操作。
写入数据点
写入逻辑需要解决两个问题:如何分片存储(避免单个块过大),以及如何高效压缩。
rust
use std::collections::{BTreeMap, HashMap};
// ==================== 核心类型定义(极简版)====================
/// 标签类型:键值对(用HashMap实现)
type Tags = HashMap<String, String>;
/// 数据点:时间戳(毫秒)+ 数值
#[derive(Debug, Clone, Copy)] // 仅保留必要的derive特性
struct Point {
timestamp: u64,
value: f64,
}
/// 数据块:存储1小时内的压缩数据
#[derive(Debug, Clone)]
struct Chunk {
start_ts: u64, // 块内最早时间戳
end_ts: u64, // 块内最晚时间戳
ts_bytes: Vec<u8>,// 压缩后的时间戳
val_bytes: Vec<u8>,// 压缩后的数值
count: usize, // 数据点数量
}
// ==================== Chunk压缩实现(极简兼容版)====================
impl Chunk {
/// 时间戳压缩:delta编码 + 大端字节序(跨平台兼容)
fn compress_timestamps(timestamps: &[u64]) -> Vec<u8> {
let mut bytes = Vec::new();
if timestamps.is_empty() {
return bytes;
}
// 第一个时间戳存原始值(大端字节序,跨平台兼容)
bytes.extend_from_slice(×tamps[0].to_be_bytes());
let mut prev = timestamps[0];
// 后续存与前一个的差值(delta编码)
for &ts in timestamps.iter().skip(1) {
let delta = ts - prev;
bytes.extend_from_slice(&delta.to_be_bytes());
prev = ts;
}
bytes
}
/// 数值压缩:直接存大端字节序(避免原生字节序兼容问题)
fn compress_values(values: &[f64]) -> Vec<u8> {
let mut bytes = Vec::new();
for &val in values {
bytes.extend_from_slice(&val.to_be_bytes());
}
bytes
}
}
// ==================== 时间序列核心结构体 ====================
#[derive(Debug)]
struct TimeSeries {
metric: String,
tags: Tags,
chunks: BTreeMap<u64, Chunk>, // 按1小时分片
}
impl TimeSeries {
fn new(metric: String, tags: Tags) -> Self {
TimeSeries {
metric,
tags,
chunks: BTreeMap::new(),
}
}
// 添加数据点(假设已按时间升序排列)
fn append_points(&mut self, points: &[Point]) {
if points.is_empty() {
return;
}
const CHUNK_DURATION: u64 = 3600000; // 1小时 = 3600*1000毫秒
// 1. 按分片分组数据点
let mut groups: HashMap<u64, Vec<Point>> = HashMap::new();
for &point in points {
let chunk_key = (point.timestamp / CHUNK_DURATION) * CHUNK_DURATION;
groups.entry(chunk_key).or_default().push(point);
}
// 2. 处理每个分组,创建数据块
for (chunk_key, group) in groups {
let timestamps: Vec<u64> = group.iter().map(|p| p.timestamp).collect();
let values: Vec<f64> = group.iter().map(|p| p.value).collect();
// 压缩(调用上面实现的兼容版方法)
let ts_bytes = Chunk::compress_timestamps(×tamps);
let val_bytes = Chunk::compress_values(&values);
// 创建数据块(用expect替代unwrap,错误信息更友好)
let chunk = Chunk {
start_ts: timestamps[0],
end_ts: timestamps.last().copied().expect("分组数据点非空"),
ts_bytes,
val_bytes,
count: group.len(),
};
self.chunks.insert(chunk_key, chunk);
}
}
}
范围查询与聚合
查询需要高效定位相关数据块,解压后进行筛选和计算。我们以"计算时间范围内的平均值"为例:
rust
impl TimeSeries {
// 查询[start_ts, end_ts]范围内的平均值
fn query_average(&self, start_ts: u64, end_ts: u64) -> Option<f64> {
// 确定需要查询的块范围
const CHUNK_DURATION: u64 = 3600000;
let start_key = (start_ts / CHUNK_DURATION) * CHUNK_DURATION;
let end_key = (end_ts / CHUNK_DURATION + 1) * CHUNK_DURATION;
// 遍历相关块(BTreeMap的range方法高效定位)
let relevant_chunks = self.chunks.range(start_key..end_key);
let mut total = 0.0;
let mut count = 0;
for (_, chunk) in relevant_chunks {
// 块与查询范围无重叠,跳过
if chunk.end_ts < start_ts || chunk.start_ts > end_ts {
continue;
}
// 解压数据
let timestamps = Chunk::decompress_timestamps(&chunk.ts_bytes);
let values = Chunk::decompress_values(&chunk.val_bytes);
// 筛选有效数据点
for i in 0..timestamps.len() {
let ts = timestamps[i];
if ts >= start_ts && ts <= end_ts {
total += values[i];
count += 1;
}
}
}
if count == 0 {
None
} else {
Some(total / count as f64)
}
}
}
这段代码中,BTreeMap::range是个大杀器。它能直接返回键在某个范围内的所有条目,避免了全表扫描。在Java中,要实现类似功能需要用subMap方法,但返回的是视图而非迭代器,内存效率不如Rust。
第四步:实现数据库索引与并发控制
一个完整的数据库还需要索引来快速找到对应的时序序列,以及并发控制来支持多线程访问。
序列索引
用哈希表存储"指标名+标签"到时序序列的映射:
rust
struct TsdbIndex {
// 哈希值 -> 时序序列ID
hash_map: HashMap<u64, u64>,
// 序列ID -> 时序序列
series_map: HashMap<u64, TimeSeries>,
next_id: u64,
}
impl TsdbIndex {
fn new() -> Self {
TsdbIndex {
hash_map: HashMap::new(),
series_map: HashMap::new(),
next_id: 1,
}
}
// 计算"指标名+标签"的唯一哈希
fn compute_hash(metric: &str, tags: &Tags) -> u64 {
let mut hasher = DefaultHasher::new();
metric.hash(&mut hasher);
for (k, v) in tags {
k.hash(&mut hasher);
v.hash(&mut hasher);
}
hasher.finish()
}
// 获取或创建时序序列
fn get_or_create_series(&mut self, metric: String, tags: Tags) -> &mut TimeSeries {
let hash = Self::compute_hash(&metric, &tags);
if let Some(&series_id) = self.hash_map.get(&hash) {
return self.series_map.get_mut(&series_id).unwrap();
}
// 创建新序列
let series_id = self.next_id;
self.next_id += 1;
let series = TimeSeries::new(metric, tags);
self.hash_map.insert(hash, series_id);
self.series_map.insert(series_id, series);
self.series_map.get_mut(&series_id).unwrap()
}
}测试用例返回:

并发写入与查询
时序数据库需要支持高并发写入(传感器数据同时涌入)和查询(监控面板实时展示)。Rust的Arc+RwLock是处理这种场景的利器:
rust
use std::sync::{Arc, RwLock};
// 线程安全的数据库
struct TimeSeriesDb {
index: RwLock<TsdbIndex>,
}
impl TimeSeriesDb {
fn new() -> Arc<Self> {
Arc::new(TimeSeriesDb {
index: RwLock::new(TsdbIndex::new()),
})
}
// 写入数据点
fn write_points(&self, metric: String, tags: Tags, points: &[Point]) {
let mut index = self.index.write().unwrap();
let series = index.get_or_create_series(metric, tags);
series.append_points(points);
}
// 查询平均值
fn query_average(&self, metric: &str, tags: &Tags, start_ts: u64, end_ts: u64) -> Option<f64> {
let index = self.index.read().unwrap();
let hash = TsdbIndex::compute_hash(metric, tags);
index.hash_map.get(&hash)
.and_then(|&id| index.series_map.get(&id))
.and_then(|series| series.query_average(start_ts, end_ts))
}
}Rust的RwLock允许多个读操作同时进行,而写操作会阻塞其他所有操作,这完美匹配了时序数据库"读多写少"的场景。相比Java的ReentrantReadWriteLock,Rust的实现更轻量,而且编译器会确保不会出现死锁(比如忘记释放锁)。
性能测试:Rust到底快在哪里?
为了验证性能,我做了一个对比测试:用相同的压缩算法和数据量,分别测试Rust、Java和Python版本的写入速度和内存占用。
测试条件:
- 数据量:100万个传感器数据点(1000个传感器×1000个点)
- 硬件:Intel i7-10700K,32GB内存
- 指标:写入耗时、压缩率、查询耗时
测试结果

Rust的优势主要来自三个方面:
- 无GC开销:Java的GC在处理大量短期对象时会产生明显停顿,而Rust的内存释放完全在编译期确定,没有运行时开销
- 高效的内存布局:Rust的结构体是连续存储的,而Java的对象分散在堆上,缓存利用率更低
- 零成本抽象:Rust的迭代器和闭包会被编译器优化成高效的机器码,性能接近手写循环,而Python的解释执行有天然劣势
生产级优化:从代码到部署
上面的实现只是基础版,要达到生产级还需要做这些优化:
- 持久化存储:将数据块写入磁盘,用mmap映射到内存避免IO阻塞
- 预聚合:对历史数据提前计算分钟/小时级平均值,加速查询
- 数据保留策略:自动删除过期数据(比如只保留30天数据)
- 分布式扩展:分片存储数据,支持水平扩展
这些优化在Rust中实现起来同样得心应手。比如用memmap2 crate可以安全地操作内存映射文件,比C++的mmap更不容易出错;用tokio实现异步IO,性能比Java的NIO还好。
为什么Rust是时序数据库的理想选择?
经过这段实战,我深刻体会到Rust在时序数据库领域的独特优势:
- 性能与安全的平衡:既拥有C++级别的性能,又避免了内存泄漏和数据竞争
- 精确的内存控制:能手动管理缓冲区和数据结构布局,这对高压缩率至关重要
- 强大的类型系统:编译期就能发现很多逻辑错误,比如时间戳单位混用
- 优秀的并发模型:Send/Sync trait确保线程安全,无需手动检查
- 丰富的生态支持:从压缩库到异步IO,Crates.io上有大量高质量组件
最让我惊喜的是Rust的可维护性。之前维护C++写的存储引擎时,每次修改都如履薄冰,生怕引入内存bug;而Rust代码在重构时非常安心,编译器会帮你检查所有潜在问题。
结语:Rust让复杂系统不再可怕
时序数据库是典型的复杂系统,既需要底层优化的性能,又需要高层设计的可靠性。Rust的出现,终于让开发者不用在这两者之间做艰难抉择。
当我用Rust实现的MiniTSDB在生产环境稳定运行一年,处理了超过100亿个数据点,从未发生过一次内存泄漏或崩溃时,我彻底明白了为什么InfluxDB、TimescaleDB这些顶尖时序数据库都在转向Rust。
如果你也在开发对性能和可靠性要求高的系统,不妨试试Rust。初期可能会觉得编译器太严格,但当你习惯了这种"严格的自由",就会发现:原来写出既快又稳的代码,是一件如此令人愉悦的事情。