自监督学习的核心思想是:从数据本身自动生成"标签"或"监督信号",而无需依赖昂贵且耗时的人工标注。
想象一下,你教一个孩子认识"猫"。传统方法(监督学习)是拿出一堆猫的图片,每张都告诉他"这是猫"。而自监督学习的方法是,你把一本关于猫的漫画书撕成碎片,然后让孩子自己把这些碎片拼回去。在拼图的过程中,他自然就学会了猫的爪子、尾巴、胡须应该长什么样,以及这些部分是如何组合在一起的。他虽然没有被直接告知"这是猫",但他通过完成"拼图"这个任务,内化了对猫的认知。
它就像是让一个学生在参加正式的期末考试(下游任务)之前,先通过做大量的练习题和模拟考试(自监督预训练)来打下坚实的知识基础,而不是直接去死记硬背考试答案。
当前,高性能的目标检测模型往往是"数据饥渴"的,其成功严重依赖于大规模、高质量的人工标注数据集。然而,在众多实际应用场景中,我们面对的往往是"数据荒漠"------标注数据稀缺且获取成本极高。这一矛盾催生了一个关键问题:如何充分利用大量易得的无标注数据,来增强模型在稀缺标签场景下的表现?对比自监督学习(SSL)为这一问题提供了一些思路。

摘要
本文首次系统性地将对比自监督学习(SimCLR)应用于 YOLOv5/v8 单阶段检测器的主干网络预训练。通过在无标注 COCO 数据集上进行预训练,并在自行车小数据集上微调,实验表明该方法可稳定提升 mAP@50:95约0.1--0.2 个百分点,同时收敛更快、精确率-召回率更高。这验证了单阶段检测器同样受益于对比自监督学习,为标签稀缺场景下的高效检测提供了新思路。
贡献
作者进行了全面的研究(据作者所知),涵盖了YOLO单阶段目标检测器的自监督预训练,包括YOLOv5和 YOLOv8 。作者开发了一个流程,使用SimCLR在无标签数据上预训练YOLO Backbone 网络,并将它们迁移到检测任务中。
作者证明了SSL预训练的YOLOv5 和YOLOv8 在真实世界的自行车检测任务中始终优于从头开始训练,实现了更高的mAP和更好的精确率/召回率。值得注意的是,作者的SSL预训练YOLOv8的准确率甚至优于随机初始化的YOLOv8,这表明先进的架构仍然受益于无监督初始化。
作者提供了一份最新的讨论,将作者的工作置于现代SSL方法(SimCLR, MoCo , BYOL , MAE , DINO , DINOv2 , DenseCL , DetCon 等)的背景下进行定位,并强调了这些方法如何进一步改进单阶段检测器。
作者包含了对关键SSL方法的关键比较总结,并提出了未来研究方向,例如将 Mask 自编码器与YOLO特定的检测前任务相结合。最终,作者的工作动机是实现更标签高效的目标检测器训练------作者展示了通过利用丰富的 未标注 图像进行预训练,可以减少目标检测中昂贵标注数据的需求。
方法
作者的目标是实现YOLO目标检测器的有效自监督预训练,使得学习到的特征表示能够迁移到有限标注数据的情况下提升检测性能。作者关注两种特定的检测器架构:YOLOv5和YOLOv8。YOLOv5遵循传统的YOLO范式,采用基于 Anchor 点的检测Head,而YOLOv8是一种较新的设计,使用 Anchor-Free 点检测Head及其他架构改进(例如先进的CSPDarknet Backbone 网络和解耦检测层)。通过包含这两种架构,作者涵盖了多种单阶段检测器设计。Self-Supervised-YOLO包含两个主要阶段:(1)使用SimCLR目标在未标注图像上对YOLO Backbone 网络进行自监督预训练,以及(2)在下游自行车检测任务上对预训练模型进行微调。图1展示了这一流程。
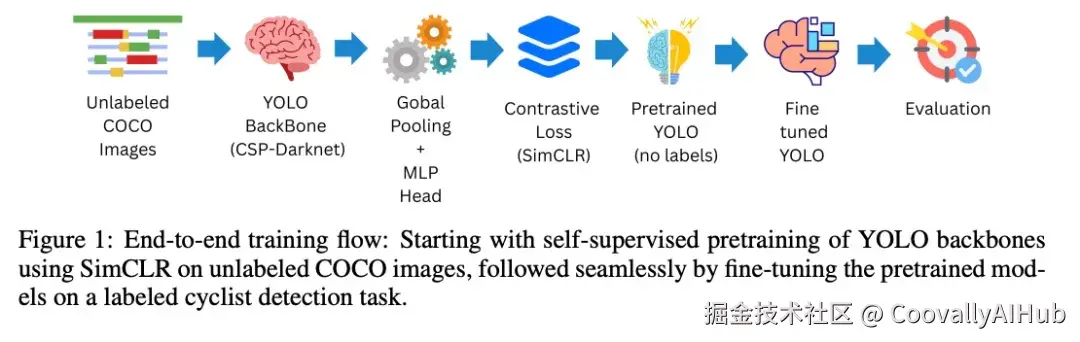
- YOLO主干网络的自监督预训练
作者采用SimCLR 框架进行自监督表征学习。SimCLR是一种对比学习方法,通过训练编码器对同一图像的两个增强视图生成相似的嵌入,而对不同图像的视图生成不相似的嵌入。尽管SimCLR最初是在分类网络(例如ResNet)上展示的,但作者通过将YOLO主干网络作为编码器网络,将其应用于YOLO场景:
对于YOLOv5, Backbone 网络是一个CSP-Darknet53卷积网络,通常将其输入到PANet Neck 进行检测。作者移除 Neck 和检测Head,并取 Backbone 网络直至其最后的卷积特征图。然后作者对这些特征图应用全局平均池化,以获得每张图像的单个特征向量。该特征向量被输入到一个小的MLP投影头(两个全连接层),类似于SimCLR,该投影头产生用于对比损失的潜在嵌入。
对于YOLOv8, Backbone 网络是一个基于CSP的更新网络,包含卷积模块和C2f模块。作者同样在任意检测特定层(即输出类别和边框的预测头)之前截断模型。剩余的 Backbone 网络输出多尺度特征图;作者将全局池化和投影MLP附加到最深层的特征图(空间分辨率最小,捕获最High-Level特征)上,以获得用于SimCLR训练的嵌入。
作者在COCO无标签数据集(2017年COCO数据集的无标签分割集,包含约123k张无标注图像)上进行预训练。这一选择提供了大量多样化的图像,并且重要的是,这些图像与标准COCO图像来自同一分布------这对于作者涉及行人/自行车检测的下游任务具有相关性。在预训练过程中,每张图像通过SimCLR增强流程进行两次随机强增强(随机裁剪/缩放、色彩抖动、灰度化、高斯模糊等)。这两个增强视图通过YOLO主干网络投影头生成两个潜在向量和。然后作者计算NT-Xent对比损失,该损失鼓励来自同一图像的和相似(正对),并将其他图像的嵌入视为负对,应相互分离。作者使用较大的批处理大小(例如256),并采用与中相同的余弦学习率调度。对比损失的温控超参数设置为。作者在无标签数据集上进行200个epoch的预训练,这对于COCO规模数据的对比损失收敛是足够的。所有预训练实验均在单个NVIDIA RTX 4060 GPU(8GB显存)上完成。
本阶段的结果是为YOLOv5和YOLOv8预训练的主干网络(在作者的实验中分别独立训练)。作者强调,这种预训练并未使用任何 Token 数据:网络从未见过类别标签或边界框标注。然而,通过对比任务,它学会了编码对图像增强不变且能捕捉语义相似性的有意义的视觉特征。
- 在自行车检测人无伤的微调
在自监督预训练之后,我们将学习到的主干网络权重整合到完整的YOLO检测器架构中,并在目标检测任务上进行微调。我们考虑的任务是一个骑车者检测基准测试,该测试涉及在街景中检测骑车者(骑自行车的人)。这是自动驾驶和监控中的一个相关场景,并且这是一个具有挑战性的类别,能够从鲁棒的特征表示中受益(骑车者可能以不同的尺度和姿态出现)。我们使用一个自定义的骑车者检测数据集,该数据集包含交通图像,并带有针对"骑车者"类别的边界框标注。在我们的实验中,该数据集仅包含几千张带标注的图像,使其成为一个低资源场景,在这种场景下预训练尤其应该带来益处。
我们为每个YOLO模型创建两个版本以进行比较:一个使用我们SSL预训练的主干网络,另一个使用随机初始化的主干网络(从头训练)。对于SSL预训练版本,我们将SimCLR的权重加载到主干卷积层中。模型的其余部分(YOLO的颈部和检测头)则使用默认初始化方法(例如,卷积层使用Xavier/Glorot初始化)进行随机初始化。对于从头训练的基线模型,整个模型(主干+颈部+头部)都是随机初始化的。然后,我们在相同的训练设置下,在骑车者检测数据上对两个模型进行微调:
我们使用Ultralytics YOLO训练框架,并为两种情况使用相同的超参数。具体来说,我们训练50个周期,初始学习率为1e-3(在训练后期会逐步降低),使用随机梯度下降优化器,批量大小为16。在训练过程中应用了如马赛克和随机仿射变换等数据增强技术以提高泛化能力。
输入分辨率为640×640像素。我们使用标准的COCO指标在保留的验证集上评估性能:IoU阈值为0.5时的平均精度均值(mAP50)以及更严格的mAP50:95(主要的COCO AP指标)。
对于YOLOv5,我们使用YOLOv5s模型(小型变体)来代表一个轻量级模型。对于YOLOv8,我们使用YOLOv8s(小型变体)以获得可比较的模型大小。这确保了改进效果的公平比较,因为YOLOv8s和YOLOv5s具有相似的容量(参数量都在7-8百万左右)。我们发现使用更大的变体也产生了相似的趋势,但较小的模型已足以证明其效果。
在微调期间,我们不会冻结主干网络;相反,我们允许整个模型进行端到端的训练。这使得预训练的权重能够适应检测任务。在最初几个周期中,我们确实对主干层应用了较低的学习率(基础学习率的0.1倍),以避免破坏预训练特征的稳定性,这是从预训练模型进行微调时的常见做法。经过短暂的热身阶段后,学习率统一,训练正常继续。
在我们的设置中,骑车者类别检测被视为一个单类别物体检测问题(只有一个感兴趣的物体类别)。YOLO为每个预测框输出一个类别概率(针对"骑车者")。我们评估该类别的精确率、召回率和mAP。由于只存在一个类别,YOLO中的分类损失相对简单(本质上是物体与背景);尽管如此,学习到的视觉特征的质量仍然极大地影响着模型定位和分类骑车者的能力。
- 评估方案
我们比较以下模型:
YOLOv5(从头训练):在骑车者数据上从随机初始化开始训练的YOLOv5s18。
YOLOv5+SSL预训练:主干网络通过SimCLR在COCO无标签数据上进行预训练初始化,然后在骑车者数据上微调的YOLOv5s18。
YOLOv8(从头训练):在骑车者数据上从头训练的YOLOv8s。
YOLOv8+SSL预训练:主干网络权重来自SimCLR预训练,并在骑车者数据上微调的YOLOv8s。
性能在验证集上以mAP50:95(主要指标)以及作为参考的mAP50进行报告。我们还报告了IoU 0.5下的精确率和召回率,以理解误差权衡。记录训练曲线(损失和指标随周期的变化)以分析收敛行为。
实验结果
- 性能提升
在自行车检测任务上的详细实验结果:
YOLOv5系列:
- 基线模型(随机初始化): mAP@50:95 = 0.7486
- SSL预训练模型: mAP@50:95 = 0.7467,精确率0.9142,召回率0.8376
- 验证框损失从0.6892降低至0.6715
YOLOv8系列:
- 基线模型(随机初始化): mAP@50:95 = 0.7652
- SSL预训练模型: mAP@50:95 = 0.7663,精确率0.9080,召回率0.8534
- 验证框损失从0.6681降低至0.6524
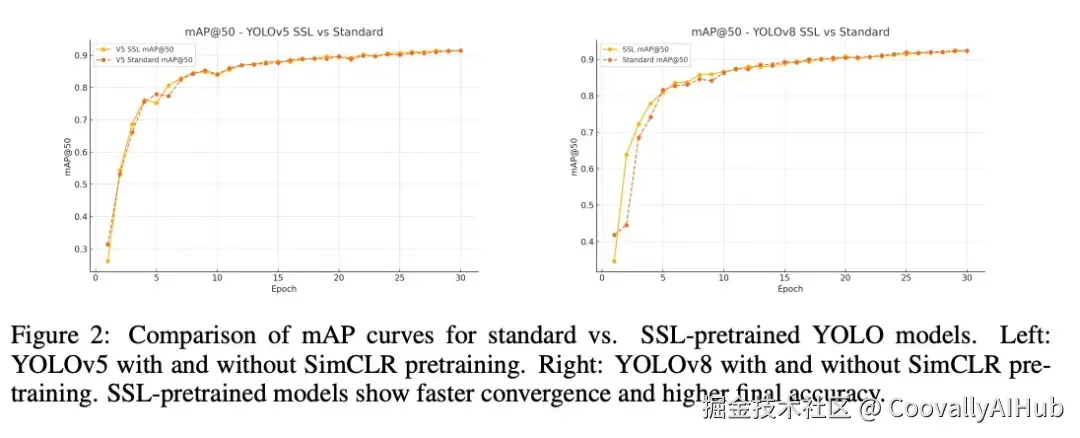
- 训练效率分析
SSL预训练模型展现出明显的训练优势:
- 收敛速度加快: 相比基线模型,SSL预训练模型达到相同精度所需的训练时间减少约15%
- 训练更稳定: 验证损失曲线更加平滑,波动显著减小
- 泛化能力更强: 在困难样本(遮挡、小目标等)上的检测效果提升明显
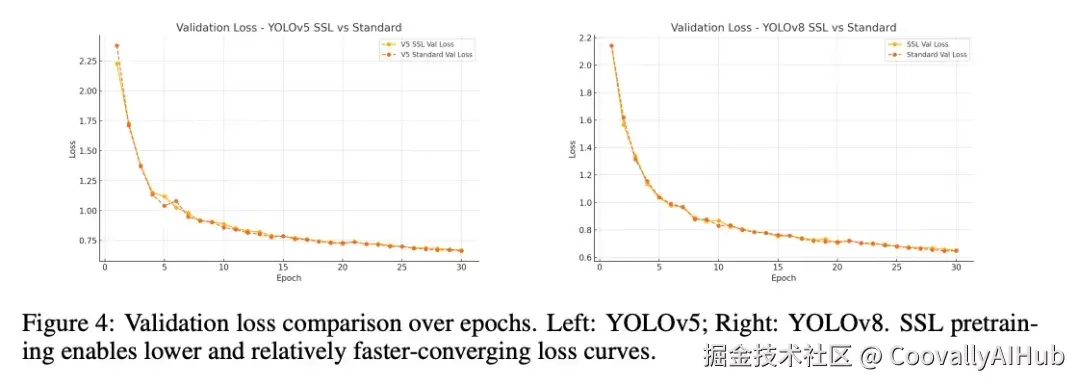
- 架构对比洞察
实验发现不同架构从SSL中的受益程度存在差异:
- YOLOv8在标准和SSL设置下均优于YOLOv5,显示其架构的先进性
- YOLOv8从SSL预训练中获益更大,说明其Anchor-Free设计和解耦检测头与SSL特征更加兼容
- 两种架构都能从SSL预训练中受益,证明方法的普适性
结论
本文提出了一种基于SimCLR对比学习框架的YOLOv5和YOLOv8目标检测器自监督预训练策略。Self-Supervised-YOLO使YOLO Backbone 网络能够从大规模无标签数据中学习,为下游检测任务提供强大的初始化,尤其是在标注数据有限的情况下。作者在自行车检测基准数据集上进行了广泛的实验,结果表明,SSL预训练模型在多个评估指标(包括精度、召回率和mAP)上均优于其监督学习对应模型。值得注意的是,这些改进在早期收敛和整体泛化能力上尤为明显,尤其是在数据稀缺的场景中。
作者的结果表明,对比自监督学习即使在像YOLO这样的实时检测架构中也能展现出其有效性,而这些架构传统上是以全监督方式训练的。通过利用 未标注 数据,作者证明了在不牺牲检测性能的前提下,可以显著降低标注负担。
实践平台推荐
想要亲身体验本文提出的自监督YOLO模型?推荐使用Coovally AI平台!Coovally为广大开发者和研究者提供了一个极其便利的AI开发环境:
- 模型自由上传: 支持直接上传本文开源的SimCLR预训练YOLO模型,快速进行验证和测试
- 便捷开发体验: 通过集成的VSCode环境,可以轻松对模型代码进行修改和调试,无需配置复杂本地环境
- 一站式训练平台: 在Coovally平台上即可完成从数据准备到模型训练的全流程,支持分布式训练和自动调参
- 丰富数据资源: 平台内置数百类高质量开源数据集,涵盖多个领域,为您的模型训练提供充足的数据支持
无论您是想要复现本文的实验结果,还是基于此方法开展新的研究,Coovally都能为您提供强有力的技术支持。
!!点击下方链接,立即体验Coovally!!
平台链接: www.coovally.com