癸卯七月风雨大作
京东零售·袁博文
僵卧双九不自哀,尚思为东戍轮台。
夜阑卧听珊瑚雨,铁马内核入梦来。

前言略长,只关心技术的同学可直接跳过看第二章
一、前言:技术的底色是什么?
这个问题在技术人心中其实没有标准答案,每个人都有每个人的见解。架构师眼里大抵是高屋建瓴,统领全局;技术大牛的视角可能是剖根溯源,精刀细琢;新人小白或许更单纯,无非就是学习进步,快速成长为大牛之类了。
但在我------一个京东数据库人的眼里,技术的底色或许应该是五彩斑斓的吧。
白是纯粹的起点
经常听人说,每个人呱呱坠地那一刻,都是一张白纸,父母在其上着墨。对于技术人来说又何尝不是呢?初学一门技术,初入一个领域,每个人都是一张白纸,在这张白纸上是随意草稿涂鸦,还是认真吸收不断进步,都取决于自己。
数据库内核技术,在 2020 年初,于我个人于内核团队于京东而言都是一个纯白的起点。自此开始探索MySQL内核的每一行源码、每一个模块,然后攻关研究每一个技术难点,再设计实现云原生的珊瑚数据库直到其落地承接业务。我和我们团队的小伙伴都可以拍着胸脯说,我们无愧于京东,无愧于这份纯白。
青是朝气是成长
内核团队每一个小伙伴,不论是社招还是校招,都是那么朝气蓬勃,都对数据库内核技术求知若渴。腾龙认真钻研探索,成功打通了MySQL测试用例线上部署和初始的内核监控框架;福哥将华为的优良编码风格带入团队并影响了许多小伙伴,还在DDL模块钻研并颇有造诣;海鹏探索并打通了内核与JED接口,为高可用付出良多;金蓬初入团队,甚至连技术栈都是初学,抱着一本经典的《C++ Primer》边啃边研究MySQL内核源码,但不妨碍进步速度惊人,最终能够独当一面;海波攻关的change buffer影子页技术以及共享集群测试框架至今还在持续带来价值;珊哥和齐哥更不用说,一个将多年积累的开发经验与MySQL内核模块深入结合,做出了诸多贡献;另一个不但对元数据锁研究透彻,更是独自一人承担了整个珊瑚数据库的工程化落地与高可用及运维工具建设。作为校招生的彭凯和宇歆,更是在短短的时间内,迅速成长,深入研究MySQL词法和语法解析,以及binlog主从复制模块,并为新产品的铸剑做出了突出的贡献。现在,越来越多的朝气蓬勃的新伙伴陆续加入了我们团队,大家的快速成长都有目共睹。
大家都从当初的青涩小白,成长成了各个内核领域的专家,或者独当一面的人才。所以青这个底色,一定是技术人努力成长,拼搏向上的颜色吧。
黄是最后的执着
在眼看京东数据库内核团队蒸蒸日上,大家在内核领域日渐深耕的时候,不出意外的还是出意外了......
集团层面的架构调整,让零售和科技的技术团队不得不融合成一个团队了,我想初衷肯定是好的,大家也都为之努力过。但出于种种不便明说的原因,数据库内核团队成了大的架构齿轮磨合下的那个代价,团队动荡,未来不明,无奈之下许多初露锋芒的优秀小伙伴不得不做出各自的选择。就在我以为京东数据库内核就要黄了的时候,不幸中的万幸,在零售众多大佬同事的全力保护下,内核的种子留了下来,静待花开。而属于技术人的这份坚守,或许就像鹅卵黄一样,等待破壳重生的那一刻吧。
赤是对技术的热忱
如果希望有颜色,那么一定是红色!
就像赤色当年卧薪尝胆,艰苦奋斗,爬雪山过草地,把希望带给神州大地一样。属于京东技术的赤色,也在京东技术中心迎来新的大家长后随之到来。我不知道其他团队是不是有类似的感受,但数据库团队在回归零售以后,大家的心气神都不一样了,对技术那颗火热的心又重新燃了起来。数据库团队也迎来了新leader:一位在数据库领域有着二十年经验的超级大佬和一位在数据库内核领域有十多年经验的资深大佬。在两位大佬的带领下,我们开始朝着新的方向前进。
同时,数据库内核团队也很快迎来了越来越多的新鲜血液:来自其他大厂的林康、正茂、张扬,将他们所掌握的数据库内核以及工程化经验引入,为我们内核的研发装上了加速器;来自各大名牌高校的校招生以及实习生晓冰、江昊、一贤、祖才等等,也都快速学习迅速成长,以最饱满的热情融入我们团队并做出了相应的贡献。
大家都饱含赤诚,携手开始向未来进发!
黑是五彩斑斓的未来
始于白,终于黑。就像太极阴阳鱼一样,生生不息,周而复始。技术也一样!
自然界当所有的颜色混在一起后,只有一个颜色------黑。数据库内核的团队也在沉淀和挫折中更加强大,随着不断补充新鲜的血液,从市场上吸引更多优秀的数据库内核人才,当所有技术的底色混在一起后,所有的五彩斑斓,所有的初心、成长、坚守、希望融为一体后,所有的不同领域的人才齐心协力共渡难关后,那结合在一起的力量,其实就只剩下未来那无限的可能------五彩斑斓的黑。内核技术的深渊也如黑洞般,深不见底,等待我们去探索。但我相信,只要我们秉持技术人的底色,就一定可以达到那个彼岸!
二、正篇:五彩熔炉,铸剑!
正篇开始!
抱歉大家,前面扯了这么多其实只是前言。但我又不想像以前写前言那样,只是简单的交代一下背景。花了五节的笔墨介绍我心中的技术底色,只希望大家能懂一点------我们会以最大的热情和最强的技术为京东打造基础数据库产品,为大家带来更优质的数据库服务。
到底铸了什么剑?
属于我们京东电商版本的自研MySQL数据库内核------DongSQL!
五年前,数据库内核团队立项直接瞄准了新的数据库形态------云原生关系型数据库,也就是存算分离共享存储架构的珊瑚数据库(shared storage),这一版其实也是MySQL内核基础上改造的,其技术难点主要是在共享存储的架构以及云原生的数据一致性,其产品价值主要是在节约数据库成本以及极致的云上资源伸缩性等。但由于与存量JED库(shared nothing)采用了不一样的技术架构,所以面临一个现实问题------存量用户版本无法平滑升级。
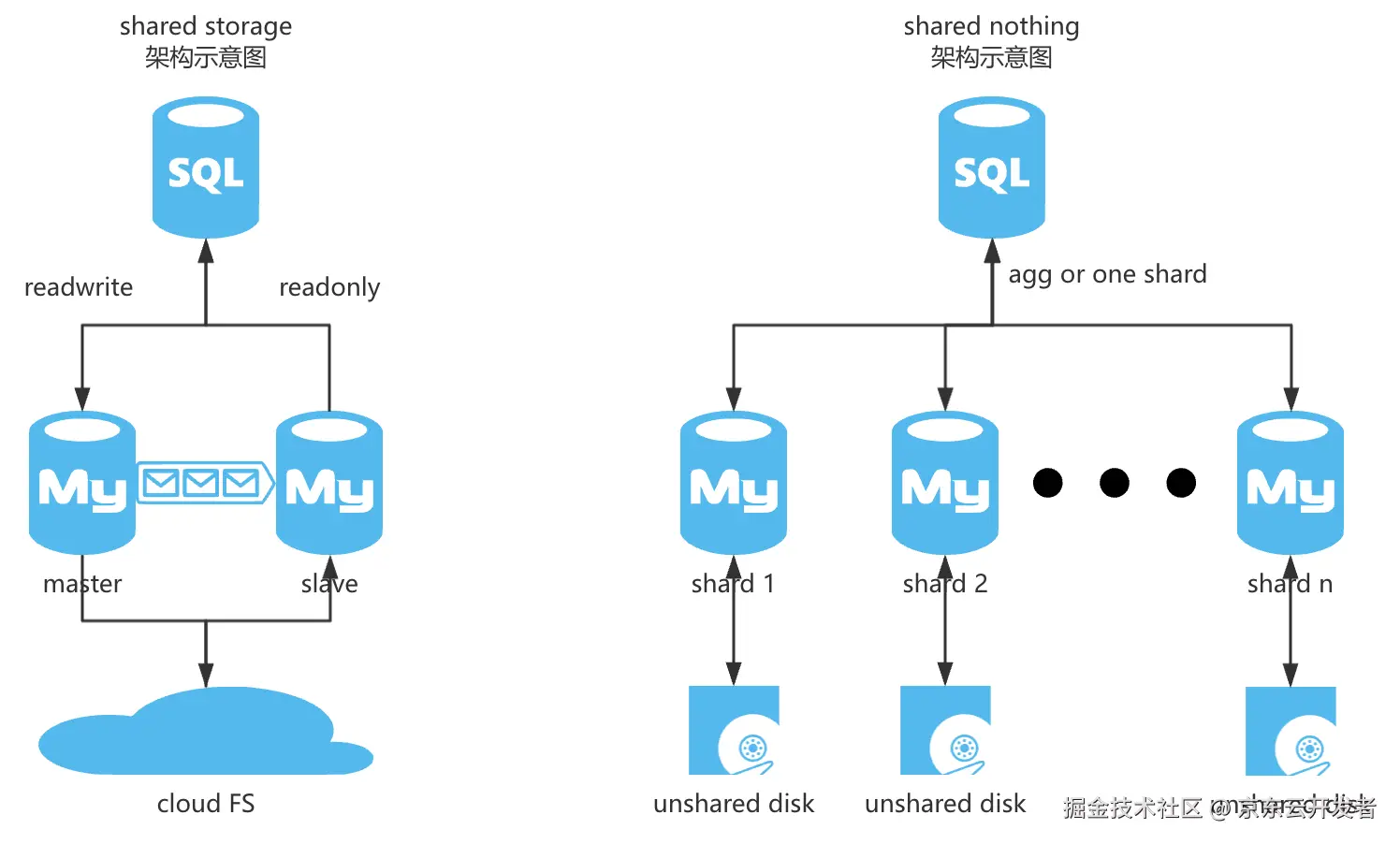
用过或者了解数据库的人都知道,有的时候不是大家不想使用更新的版本,更强的性能,更优秀的功能,而是数据库本身太基础太重要了,如果业务系统已经建设很多年,与数据库绑定太深的话,更多还是求稳为主,能不动则不动。这也是为什么即使现在MySQL都出到 9.* 版本了,长期稳定支持版本都 8.4 了,很多人连 8.0 都没尝试过,京东的主流数据库版本还是 5.7,甚至普通MySQL还存量不少 5.6 5.5 版本的原因。这不是京东独有的情况,可以说整个行业皆是如此,这叫技术惯性。正是因为采用了新的技术架构,带来了一个问题:存量业务如果要使用必须进行数据库的迁移。就这一个原因,很多业务就望而却步。
正是由于这个原因,在新leader带领我们团队以后,基于丰富的数据库经验,敏锐地察觉到京东整个数据库的基本盘其实是存量的数据库,解决存量数据库用户的问题才能带来更大的价值。再优秀的产品,如果没人用一样白费力气。
因此,我们需要做的是,一个完全基于MySQL(Percona)原生binlog主从复制架构的数据库内核,不引入更复杂的架构变更和过多的设计,只在其基础上对数据库内核性能进行优化、对配套能力进行提升、对零售电商场景进行针对性扩展,完美支持JED以及DongDAL,秉持稳定性和兼容性为前提的基础上,让京东的数据库内核更好用,更强大!
电商场景下原生MySQL痛点的解决之道
电商场景的数据库需求其实是用户最迫切的,因此我们在首选开刀方向时,没有选择引入花里胡哨高大上的功能等角度。而是从用户中来,回到用户中去,深入分析目前线上用户最常见的问题,以及大促最常见的故障场景,针对性的引入了内核层新的解决方案。
问题一:"过载" 大促激增的流量,或者超时SQL不断重试直接把数据库CPU打满甚至打挂
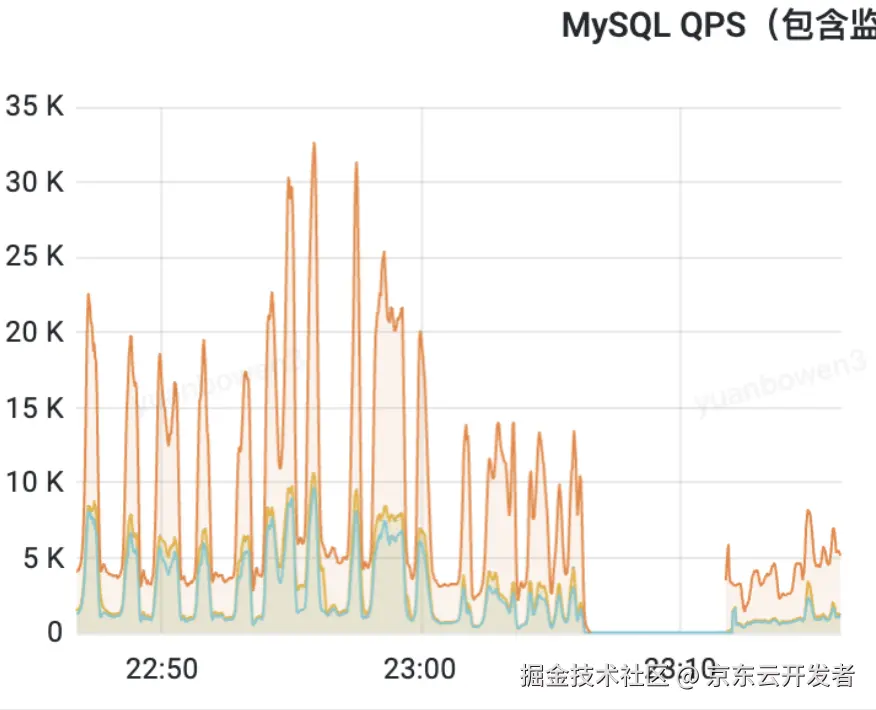
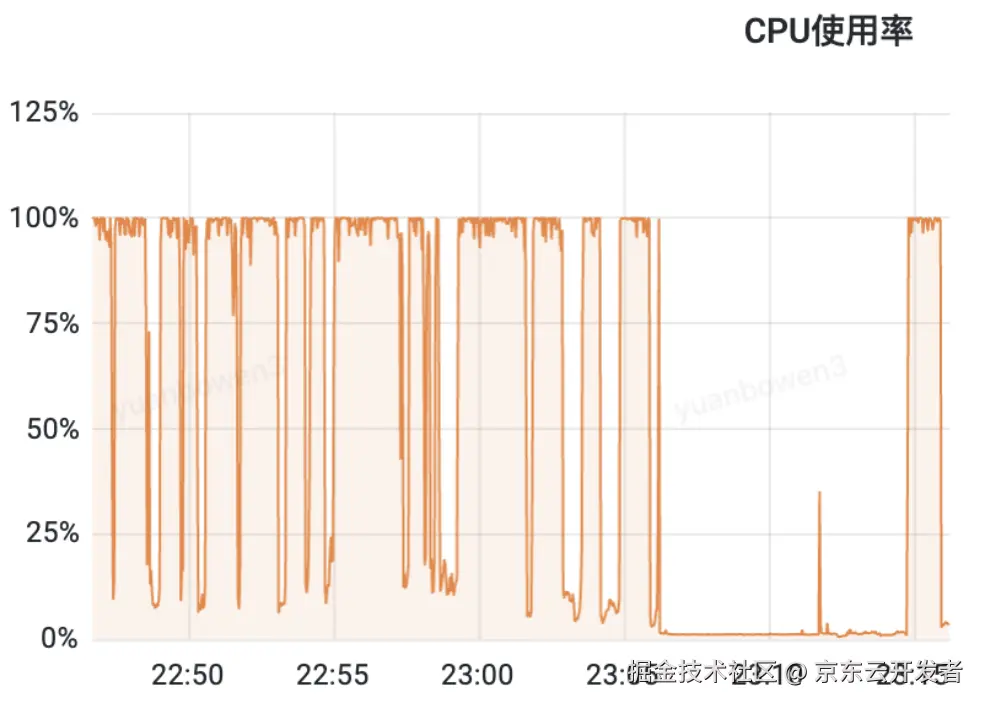
这种场景真的非常常见,甚至前段时间还有一个白虎故障就是类似的原因。业务研发在设计功能的时候,其实是无法预知线上生产环境真实的流量的,或许可以设计应用侧限流,也或许可以加缓存抗量,但限流不是每个系统都有,即使有也可能存在疏漏,缓存如果被击穿那带给数据库的流量更是暴击。有的时候甚至不是真实暴增的流量,而只是超时机制的负反馈,失败的不断重试就带来了超出预期的数据库请求。
当MySQL请求流量突然暴涨时或者突发的慢sql占用大量资源时,它会像一个被瞬间涌入人群挤垮的服务台:每个新连接都需要数据库创建一个线程来处理,大量线程的创建、上下文切换和维持本身就会吃掉可观的内存和CPU;更重要的是,每个查询进来,MySQL都要疯狂工作------解析复杂的SQL语句、在成千上万条索引条目中查找路径、拼凑关联多张表的数据、进行排序分组计算、管理事务保证一致性(这涉及到频繁的加锁解锁,高并发时极易堵塞排队)、还要不断从磁盘读取数据或把改动写回去。所有这些操作都是极度消耗CPU算力的密集计算。当每秒涌入的请求远超CPU能处理的速度时,CPU就会被完全占满,所有查询都挤在一起排队等待计算资源。与此同时,高并发下锁冲突剧增,大量线程因等待锁而阻塞却不释放资源;内存可能被临时表、排序缓存塞爆;严重时磁盘IO也跟不上。最终,CPU被彻底耗尽,新连接无法建立,已有查询完全卡死,整个数据库进程失去响应,就像被"打挂"了一样,本质上就是所有关键资源(CPU、内存、IO、连接)在瞬间洪峰下被彻底榨干导致的系统性崩溃。
原因很清楚,解决方式也很简单,前面也提到了,限流即可,可实际生产环境操作起来还是会出现诸多困难。
业务层自行限流面临的主要挑战在于其"粗放"和"滞后"。它通常只能基于简单的请求频率或用户维度(如QPS)进行拦截,无法洞察数据库内部真实的瓶颈所在(比如是在CPU、内存、磁盘IO还是锁冲突)。这极易导致"误杀"------核心的重资源消耗型SQL可能未被拦住,反而大量高频但轻量的请求被限流,牺牲了业务可用性却未能真正缓解数据库压力。同时,在分布式微服务架构下,协调各个服务模块统一、实时地实施并调整限流策略异常困难,很容易出现限流不一致或响应迟缓,当业务层感知到数据库响应变慢或报错再触发限流时,往往已经错过了最佳干预时机,雪崩可能已经发生。
目前的实际操作往往是高可用程序或者DBA依靠HA机制进行主备切换来应对过载。切换过程本身必然导致数秒到数十秒的服务中断(连接闪断、短暂只读),对连续性要求高的业务会造成直接影响。更重要的是数据一致性问题:主库在故障或过载瞬间可能存在未同步到备库的事务数据,切换后这些数据可能永久丢失(异步复制下),即使使用半同步复制也可能因网络问题阻塞写入或退化为异步。历年大促线上生产环境不少故障甚至是发生在切换操作之后(普通MySQL集群以及低版本vitess集群风险尤其显著)。
解:SQL自提示实现精准限流
基于以上痛点,不少用户提出,如果可以实现精准限流就好了,既能在业务根据流量预测的基础上预防性限流,又能在过载发生后根据简单排查的结果定向限流。有求必应------MySQL Hint限流方案横空出世!
sql
// 根据特定 SQL 指纹进行限流
update/*+ ccl_queue_digest(INT<当前语句的并行数>) */ t set col1 = col1+1 where 1=id;
update/*+ ccl_queue_digest() */ t set col1 = col1+1 where 1=id;数据库内核自身支持限流的核心优势是,我们能深入到SQL执行层,根据用户指定规则(如匹配特定SQL指纹、或者SQL语句全文等不同模式规则)实时识别并优先抑制那些真正"吃掉"大量资源的"罪魁祸首"查询。这如同在数据库引擎内部安装了一个智能节流阀,直接从源头(消耗资源的查询)进行精准控制,避免了业务层限流的盲目性和HA切换的破坏性。它能在资源紧张初现端倪时就主动干预,最大限度保障核心业务请求的通过和系统整体的稳定性,且由内核统一管理,规则生效及时、策略执行高效。
问题二:"秒杀" 单点高频写入带来的数据库性能下降,以及库存一致性问题
秒杀是电商业务非常常见的场景,无论秒杀业务是否设计缓存前置抗量,库存数据的最终变更都是需要落到数据库的。如果缓存发生击穿,更是需要数据库来进行兜底策略。但秒杀这个场景的数据库操作又极其特殊,甚至可以说会导致原生MySQL的痛点集中爆发。
首先,高频单行更新使行级锁竞争成为致命瓶颈:当海量请求同时扣减同一商品库存时,InnoDB的行锁强制串行更新,导致线程在锁等待中堆积;死锁检测机制在队列过长时(如超1000线程)触发深度遍历,CPU资源被疯狂消耗,事务响应时间骤增甚至超时。
其次,高频事务的ACID保障带来巨大开销:事务在MySQL中是核心能力之一,在秒杀场景下往往都是简单事务,但为了保证查询更新的一致性,又不得不开显式事务(非auto commit),而显式事务的BEGIN、Statement、COMMIT/ROLLBACK,每一个子句都会完整的经历应用侧到数据库底层的多级转发和网络开销,伴随多次网络交互(跨节点延迟加剧堵塞)及日志写入(undo/redo/binlog),单事务耗时飙升,系统吞吐量断崖式下跌。
最后,秒杀场景的库存扣减不允许出现意料外的更新:原生MySQL的高并发扣减需通过SELECT检查库存后再执行UPDATE,但两步操作存在时序漏洞------高并发下多个请求可能同时读到相同库存值,导致超卖;同时所有请求(包括库存不足的无效请求)均需竞争同一行锁,引发线程堆积和死锁检测的CPU暴增。
解:电商秒杀场景定制优化
秒杀排队:高频更新问题很好解决,借用限流的思路,只不过秒杀场景要限的是具体的字段甚至是具体的值,因为高频SQL是集中在具体数量的库存或者单一品类上的,要改的可能就几行甚至是一行数据。因此,我们借用了限流的Hint语法,业务只需要在预期秒杀需要更改的具体SQL上,加上对应的Hint规则,约定具体字段或者具体值需要进行限制排队执行,数据库内部就会对秒杀类的SQL进行管理排队,极大程度的规避了行锁的竞争以及其连锁反应,经测试单行更新高并发场景下,比原生MySQL的流量能提升一倍以上。
csharp
// 根据热点值限流
update/*+ ccl_queue_value('茅台') */ t set c=c+1 where name ='茅台';
// 根据热点字段限流
update/*+ ccl_queue_field(order_id) */ t set c=c+1 where order_id =1and name ='茅台';事务快速提交/回滚:针对秒杀事务的特性,设计了事务快速提交回滚的Hint,即用户在事务COMMIT/ROLLBACK前的最后一个SQL语句上,如果加上该Hint,则内核即明白该操作提交或者回滚了。此方案在秒杀场景下,尤其是特定单行更新的场景下,最高可以提升 3 倍以上的性能!优势非常明显。
影响行数约束:秒杀场景库存扣减,或者其他非秒杀场景也可能存在,业务侧的逻辑明确知道某条SQL更新后应该影响几行数据,如果数据库执行完发现影响的行数不符合预期则大概率出现问题了,需要将事务进行回滚。我们设计了预期影响行数的Hint,通过该Hint(示例 UPDATE /*+ TARGET_AFFECT_ROW(1) */ stock SET count=count-1 WHERE id=100 AND count>=1),可同步实现两大核心优化:
其一,引擎在加锁前优先校验 WHERE 条件(库存≥1),仅当库存充足时才尝试加锁更新,库存不足的请求直接返回影响行数=0,避免无效锁竞争;
其二,库存检查与扣减压缩为单原子操作,确保影响行数严格为1才成功,否则自动失败,彻底杜绝跨事务的脏读与超卖风险。当然也可以配置其他数值,只要与您预期的影响行数一致即可。
问题三:"缓存更新一致性问题" 业务前置缓存失效时,会直接更新数据库,然后查询已更新数据并返回
许多业务系统会在数据库访问层之上引入缓存,例如京东的分布式缓存JIMDB,以利用其极致的读写响应速度优化用户体验。然而,缓存的易失性本质决定了其无法独立承担关键数据的持久化职责------数据库始终是不可或缺的兜底保障(除非数据可容忍丢失)。维护缓存与数据库之间的强一致性是系统设计的核心挑战,当缓存失效导致请求穿透至数据库时,业务常需同步获取刚更新的数据并实时刷新缓存或响应前端。原生MySQL在此场景下存在显著局限:若要在事务中确保更新后立即可见且数据一致,必须在DML操作后紧跟一条SELECT语句进行查询。但即便采用此方案,在读已提交(RC)隔离级别下,其他事务的并发修改仍可能导致该查询读到不一致数据,无法满足严格的实时一致性要求。
解:实现RETURNING语法
我们通过实现RETURNING语法解决这一问题:在UPDATE/INSERT等DML语句末尾追加RETURNING子句,就能直接获取修改后的完整行数据。比如库存扣减场景下,一条UPDATE inventory SET stock=stock-1 WHERE id=100 RETURNING *;语句既完成了原子扣减,又能立即返回最新库存值,无需额外SELECT查询。
这一内核级优化不仅消除了RC隔离下的并发脏读风险(DML与返回数据基于同一事务快照,其他事务的并发修改不会干扰结果),还将"更新 + 查询"的两次网络交互压缩为单次请求,把事务耗时再降一个级别。对缓存架构而言,业务侧拿到RETURNING返回的实时数据后,能立刻刷新缓存层,在事务提交时就完成数据对齐,让秒杀、大促等高并发场景下的"缓存击穿兜底逻辑",既快又稳。
问题四:"执行计划漂移" 好好的SQL突然就慢了
这个问题真的让人头疼,一条SQL在开发环境跑得飞快,到了线上就变成了蜗牛。更要命的是,有时候同一条SQL,今天还好好的,明天就突然慢得要死。
举个例子,我们有条订单查询的SQL:
sql
SELECT o.*, u.name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.create_time
BETWEEN '2025-10-01' AND '2025-10-30' AND o.status IN('PAID','SHIPPED')
ORDER BY o.create_time DESC LIMIT 100;平时这条SQL毫秒级就能出结果,用的是orders.idx_create_time索引。但有一天大促期间,这条SQL突然开始走全表扫描,30秒才能跑完,直接把系统拖垮了。
为什么会这样?MySQL优化器是个"聪明"的家伙,它会根据表的统计信息来选择执行计划。但问题就出在这些统计信息上------ANALYZE TABLE更新了统计信息,数据分布发生了变化,或者系统负载影响了成本计算,优化器就可能突然"变心",选择一个完全不同的执行路径。
这种情况在大促期间特别危险,数据量激增、系统负载变化,一条核心查询的执行计划突然劣化,整个系统可能就垮了。
传统的解决办法要么重启数据库(代价太大),要么业务研发加Hint强制索引(破坏代码可维护性,还得紧急上线,时间周期长),要么调优化器参数(可能影响其他SQL),都不是很好的选择。
解:Statement Outline执行计划固化功能
为了解决这个问题,我们实现了Statement Outline功能,可以把稳定高效的执行计划"固化"下来,让优化器按照我们指定的方式执行。这个功能通过dbms_outln存储过程包来管理,使用起来很简单。比如我们发现某个查询有个很好的执行计划,就可以把它记下来,一旦发生上述意外场景,可以立即将其注入数据库从而稳定该类型SQL的执行:
sql
-- 添加优化器hint的outline
CALL dbms_outln.add_optimizer_outline(
'your_db', -- 数据库名称
'', -- SQL语句的摘要,为空时自动计算
1, -- 位置,通常为1
'/*+ USE_INDEX(orders idx_create_time) */', -- 优化器提示文本
'SELECT o.*, u.name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.create_time BETWEEN '2025-10-01' AND '2025-10-30' AND o.status IN ('PAID', 'SHIPPED')
ORDER BY o.create_time DESC LIMIT 100;' -- SQL语句文本);
-- 添加强制索引的outline
CALL dbms_outln.add_index_outline(
'your_db', -- 数据库名称
'', -- SQL语句的摘要,为空时自动计算
1, -- 位置,通常为1
'USE INDEX', -- 索引提示类型,如'USE INDEX'、'IGNORE INDEX'等
'idx_status', -- 索引列表,多个索引用逗号分隔
'', -- 索引提示选项,如'FOR JOIN'、'FOR ORDER BY'等
'SELECT o.*, u.name
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.create_time BETWEEN '2025-10-01' AND '2025-10-30' AND o.status IN ('PAID', 'SHIPPED')
ORDER BY o.create_time DESC LIMIT 100;' -- SQL语句文本);这样一来,即使统计信息变化了,优化器也会按照我们固化的执行计划来执行,保证查询性能的稳定性,让我们能够精确控制查询的执行方式。对于那些业务关键的SQL,这个功能简直是"定海神针",彻底解决了执行计划漂移的问题。
Outline还可以注入自定义的hint,比如"问题一"中的解决过载问题hint或者"问题二"中的秒杀场景hint。
问题五:"线程拥堵" MySQL官方竟然没有线程池
说起来可能很多人不知道,MySQL官方版本其实是没有线程池功能的!或者说开源版本是没有线程池功能的,要想拥有就得付费购买商业版本。而咱们京东一直以来都是使用的开源版本,每个连接都要创建一个独立的线程来处理,常规场景每连接每线程还很稳定,但高并发场景下就是灾难。
想象一下大促期间的场景:成千上万个连接同时涌入数据库,每个连接都要创建线程,线程创建和销毁的开销巨大,CPU忙着做上下文切换,真正用来处理SQL的时间反而不多。更要命的是,所有请求都是一视同仁,核心的支付查询可能被大量的日志写入、报表查询这些不紧急的请求给"淹没"了。在JED架构下,由vitess控制了连接的数量,这个问题还不大,但目前DongDAL直连DongSQL的架构,这个就成了不得不面对的重点问题!
线程拥堵的问题看起来和过载很像,但还略有一点区别。过载场景可以精确识别到个别问题SQL,并进行精准限流,从而保证不影响其他SQL。而线程拥堵的大部分甚至所有连接都是正常SQL,没有谁是受害者,只不过突发流量真的太大了!所以这种场景,我们就不得不祭出大杀器------MySQL官方需要付费才能使用的------线程池!
解:DongSQL线程池 - 基于Percona的增强版线程池
幸运的是DongSQL基于Percona Server源码进行京东本土化实现。Percona Server提供了完整的线程池功能,能够有效复用线程资源,避免频繁创建和销毁线程的开销。线程池会维护一组工作线程,新来的连接请求会被分配到空闲的线程上处理,这样就能大大减少上下文切换,提升高并发场景下的性能。
在Percona线程池的基础上,我们针对实际业务场景做了进一步优化,特别是加入了高优先级IP功能。这个功能特别实用,可以给重要的功能开"绿色通道":
sql
-- 把重点IP设为高优先级
SET GLOBAL thread_pool_high_priority_ips ='192.168.1.0/24,10.0.1.100';
-- 把重点user设为高优先级
SET GLOBAL thread_pool_high_priority_users="super_admin,dong_user"这样一来,来自核心服务器/核心用户的请求就能优先得到处理,不会被其他不那么紧急的请求给挤占了。系统会智能识别高优先级连接,确保关键功能的响应时间。
这些优化功能的加入,让DongSQL在高并发、大数据量的零售电商核心场景下展现出了更强的稳定性和性能。每一个功能都是我们在实际业务中遇到问题、分析问题、解决问题的结果,希望能够帮助更多的团队应对类似的挑战。
三、结语:技术的成色又是什么呢?
如果说技术的底色,是求知、是成长、是执着、是热忱、是我们所有技术人团结在一起爆发出的力量。
那么技术的成色,一定有脚踏实地,追根溯源,不浮于表象,而深入骨髓地解决根本问题。正所谓:求木之长者,必固其根本;欲流之远者,必浚其泉源。对于数据库,则必须具备掌控数据库内核的能力,方能使自身以及其上承接的业务行稳致远。
除此之外,更宏观的维度,技术的成色我想应该就是为团队、为公司、为用户、乃至为社会产生实实在在的价值吧!正如公司使命说的那样:技术为本,让生活更美好! 让我们携手所有业务研发团队做实事、有价值的事、长期的事,为京东的 35711 梦想付出我们自己的一份力!
