本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
为什么 LLM 需要向量数据库?
一旦我们训练好了 LLM,它就会有一些用于文本生成的模型权重。向量数据库在这里扮演什么角色呢?让我解释一下矢量数据库如何帮助 LLM 生成更准确、更可靠的结果。首先,我们必须明白,LLM 是在从训练期间输入的语料库的静态版本学习后部署的。
例如,由于 LLM 是使用静态语料库训练的,也就是说,它训练完成并实现部署,它将不知道部署后的时间发生的事情。
每天用新数据反复训练一个新模型(或调整最新版本)既不切实际,又不划算。事实上, LLM的训练可能需要很多 GPU 训练数周甚至更长时间。此外,如果我们开源了 LLM,而其他人想在他们私人持有的数据集上使用它,那该怎么办?正如预期的那样,LLM对此一无所知。
但如果你仔细想想,我们的目标真的是让 LLM了解世界上的每一件事吗?这不是我们的目标。相反,它更多的是帮助 LLM 学习语言的整体结构,以及如何理解和生成它。
因此,一旦我们在足够大的训练语料库上训练了这个模型,就可以预期该模型将具有相当水平的语言理解和生成能力。因此,如果我们能够找到一种方法,让 LLM 查找未经训练的新信息并将其用于文本生成(无需再次训练模型),那就太好了!
一种方法是在提示本身中提供该信息。换句话说,如果不需要训练或微调模型,我们可以在给 LLM 的提示中提供所有必要的细节。
不幸的是,这只对少量信息有效。这是因为 LLM 是自回归模型。自回归模型是指那些一步一步生成输出的模型,其中每一步都依赖于前面的步骤。对于 LLM 来说,这意味着该模型基于已经生成的单词,一次生成一个单词的文本。因此,当 LLM 考虑前面的单词时,它们有一个上下文窗口限制,实际上它们在提示中不能超过这个限制。总的来说,这种在提示中提供所有内容的方法并不是那么有前景,因为它将实用性限制在几千个标记上,而在现实生活中,附加信息可能有数百万个标记。
这就是矢量数据库可以提供帮助的地方。我们可以利用矢量数据库动态更新模型对世界的理解,而不是每次出现新数据或发生变化时重新训练 LLM。
RAG:向量数据库在 LLM 中的应用
正如本文前面所讨论的,向量数据库帮助我们以向量的形式存储信息,其中每个向量捕获有关被编码文本的语义信息。因此,我们可以通过使用嵌入模型将可用信息编码为向量,从而将其维护在向量数据库中。
当 LLM 需要访问此信息时,它可以使用提示向量的相似性搜索来查询向量数据库。更具体地说,相似性搜索将尝试在向量数据库中找到与输入查询向量相似的内容。
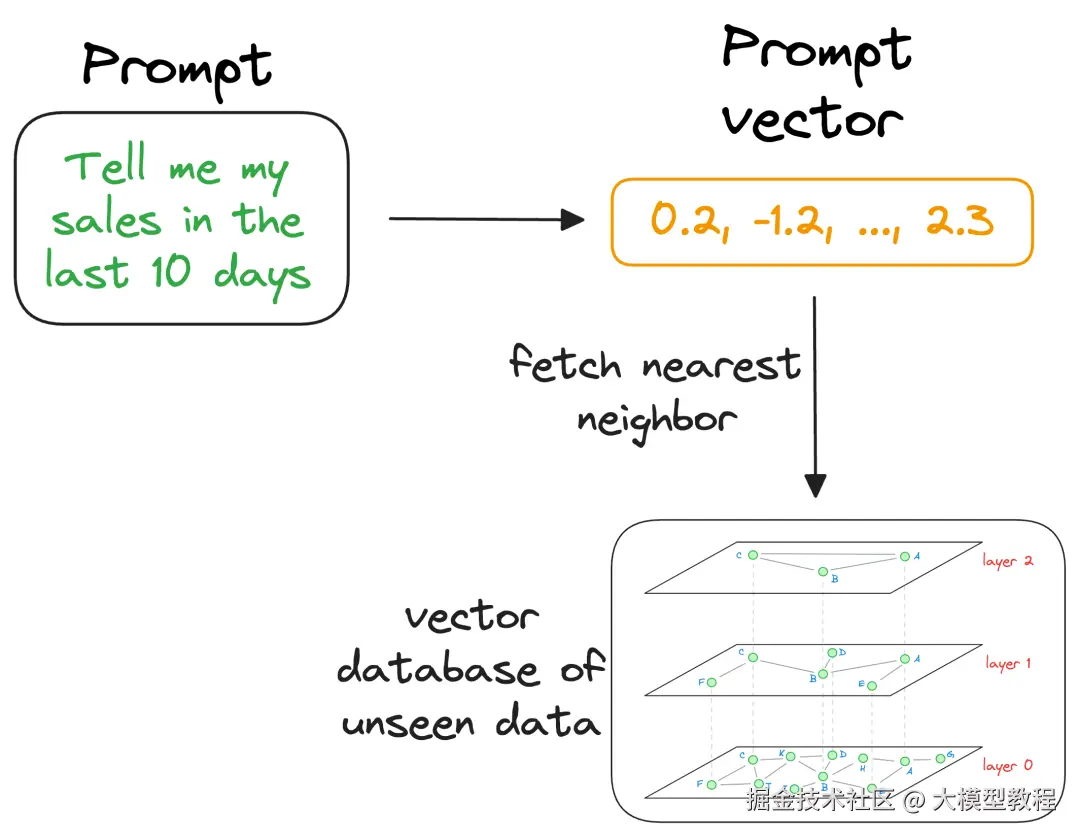
这就是索引变得重要的原因,因为我们的矢量数据库可能有数百万个向量。理论上,我们可以将输入向量与向量数据库中的每个向量进行比较。但为了实际用途,我们必须尽快找到最近的邻居。这就是为什么快速准确的索引技术如此重要的原因。它们帮助我们几乎实时地找到近似最近邻。接下来,一旦检索到近似最近邻,我们就会收集生成这些特定向量的上下文。注意,向量数据库不仅可以存储向量,还可以存储生成这些向量的原始数据。
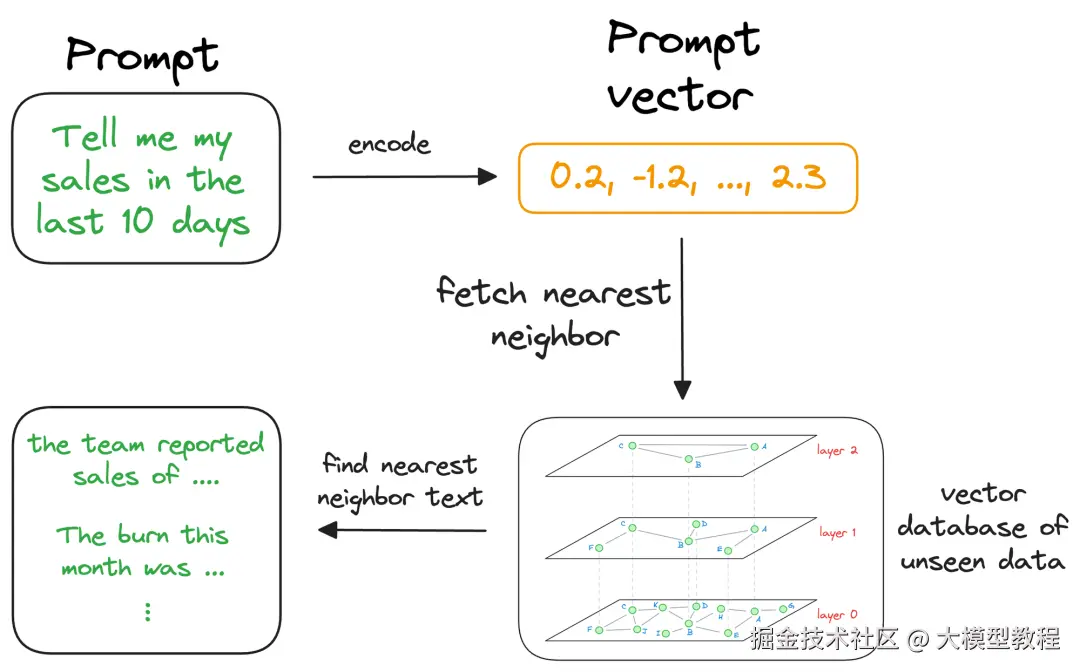
此搜索过程检索与查询向量相似的上下文,该查询向量代表 LLM 感兴趣的上下文或主题。我们可以将检索到的内容与用户提供的实际提示一起扩充,并将其作为 LLM 的输入。
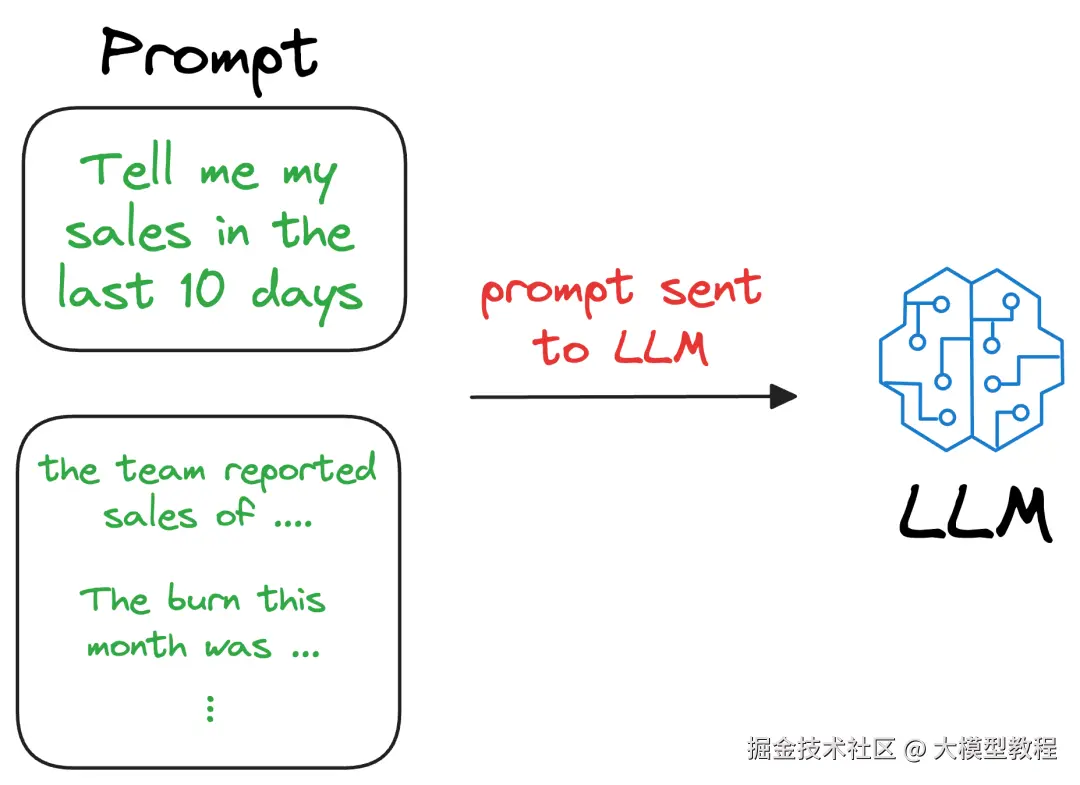
因此,LLM 可以在生成文本时轻松地合并此信息,因为它现在在提示中提供了相关的详细信息。这就是检索增强生成(Retrieval-Augmented Generation, RAG)。事实上,RAG的名字就完全证明了我们用这种技术所做的事情:
- 检索(Retrieve):从知识源(例如数据库或内存)访问和检索信息。
- 增强(Augment):通过附加信息或上下文来增强或丰富某些内容,在本例中为文本生成过程。
- 生成(Generation):创造或生产某种东西的过程,在这种情况下,是指生成文本或语言。
RAG 的另一个关键优势是它能显著帮助 LLM 减少反应中的幻觉。当语言模型生成不基于现实的信息或虚构事物时,就会出现幻觉。这可能导致模型生成不正确或误导性的信息,这在许多应用中都会出现问题。通过 RAG,语言模型可以使用从矢量数据库中检索到的信息(预计是可靠的)来确保其响应基于现实世界的知识和背景,从而降低出现幻觉的可能性。这使得模型的响应更加准确、可靠和与上下文相关,从而提高了其整体性能和实用性。

学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。