导读: 数据集的高基数(High-Cardinality)问题一直困扰着诸多主流的时序数据库(Time Series Database,TSDB)产品。一些数据库管理系统,在基数较低时表现良好;但是随着基数的增加,数据库的表现也会变差,这就给数据库管理员带来了很大的挑战,他们需要通过相关设计降低基数,避免与之相关的问题。
TDengine 完美解决了高基数问题的时序数据库,本文将分享其设计思路。
何谓高基数问题?
讲到高基数问题,首先,我们要理解什么是基数(Cardinality)。基数可以定义为一个数据集中值的数量。数据集不同,基数可以很高,也可以很低。比如,如果是布尔数据,它的值只能是 true 或 false,则该数据集的基数为 2。但是如果是像设备 ID 这样的数据集,其基数就非常大了。
对于时序数据,事情就更复杂了。时序数据总会关联一些元数据,比如标签。因此,一个系统的基数就是每个标签的基数的叉乘。比如,以智能电表为例,它会关联设备 ID、城市 ID、厂商 ID 和模型 ID 等标签。几百个城市,百万级设备,再加上不同的厂商、模型,基数轻松超过百亿级。
高基数有什么问题呢?这会增加定位一个唯一的值所需要的时间。对于数据库而言,延迟与基数直接相关。许多时序数据库,如 InfluxDB、OpenTSDB 和 Prometheus,都采用了键值存储模型,其中的键是由标签组合唯一识别的。这种模式有个副作用,它会极大增加数据集的基数。
那 TDengine 时序数据库是如何解决高基数问题的呢?下面我们一起看一下它的几个核心设计。
数据模型:一个数据采集点一张表
特有的数据模型,是 TDengine 的一大核心设计,即"一个数据采集点一张表"。也就是说,TDengine 建议为数据采集点创建一张单独的表。一般情况下,一个设备就是一个数据采集点;但是在更复杂的情况下,一个设备可能包含多个数据采集点,而且不同的采集点有不同的采集频率。
在设计上,TDengine 使用一致性哈希来确定哪个虚拟节点(vnode)负责存储特点表(table)的数据。在 vnode 内部,系统会构建索引,以提升定位 table 的速度。随着表数量的增多,TDengine 会创建更多 vnode,尽量减少定位到某个 table 的时间,并支持系统轻松伸缩。
这种设计保证了向任何一个表插入数据或从任何一个表查询数据的延迟,即使表的数量呈指数增长。因此,延迟不受 TDengine 中高基数的影响。
将元数据与时序数据分离
通过"一个数据采集点一张表"的设计,TDengine 可以保证单一表的延迟。但是,现实世界的具体应用往往需要聚合多个表或设备中的数据。这是 TDengine 在设计上要面对的一个主要挑战。
为了解决这个问题,TDengine 引入了超级表(supertable)。与标准的数据库不同,超级表允许应用程序将一组标签关联到每个表。TDengine 会将这些标签与采集到的时序数据分开存储:使用 B 树为标签建立索引,将其保存到元数据存储中;而时序数据保存在一个单独的时序数据存储中。元数据存储中的每张表只有一行数据,而且可以根据需要更新。在时序数据存储中,每个表都有许多行数据,而且数据集会随着时间的推移而增长,直到其生命周期结束。
为了聚合多个表的数据,应用程序可以通过标签来过滤。当执行时,TDengine 首先搜索元数据存储,并获得满足过滤条件的表的列表,然后再来获取存储在时序数据存储中的数据块,并完成聚合过程。
首先扫描元数据存储,因为这个数据集比时序数据存储的规模要小得多,TDengine 就可以提供非常高效的聚合能力。这个过程可以用下图表示。
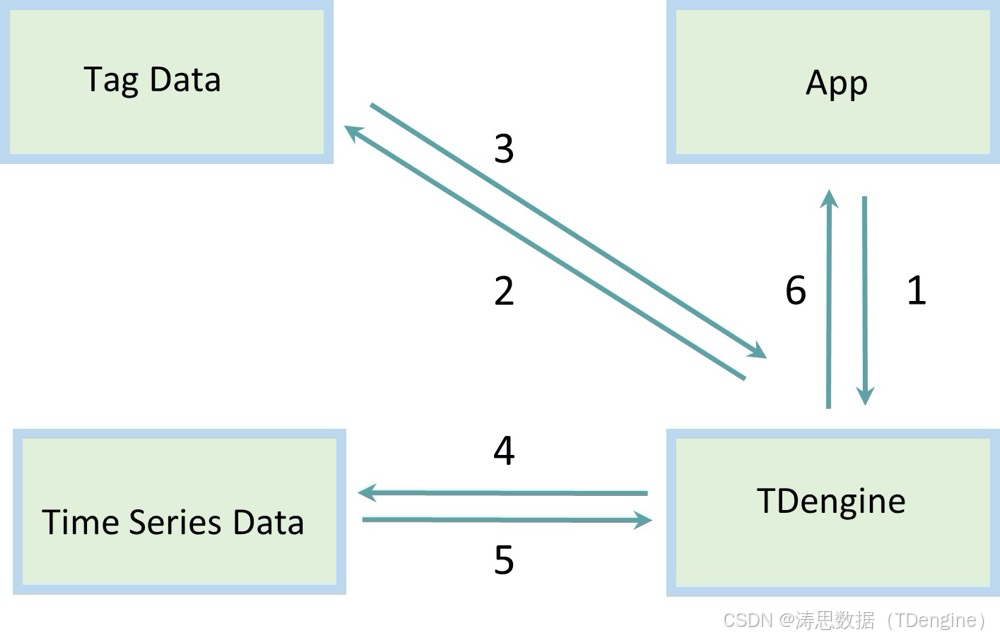
分布式存储元数据
在 TDengine 2.x 的设计中,表的元数据,比如模式和标签,都存储在管理节点(mnode)上。如果创建的表的数量达到千万级,这就会成为 TDengine 的一个瓶颈:过滤这么多标签的延迟会明显增加了。
到了 TDengine 3.0,我们会将元数据存储分布在 vnode 中,而不再是集中化存储在 mnode 上。当一个应用想从多个表聚合数据时,TDengine 会同时向所有的 vnode 发送过滤条件。然后,每个 vnode 并行工作,找到所要求的表,聚合数据,最后将结果送回查询节点或驱动,并在那里执行合并操作。
现在,TDengine 3.0 的分布式设计保证了标签过滤操作的延迟,只要系统资源充足,mnode 不再是瓶颈。随着创建的表的增多,TDengine 只需要为其分配更多资源,创建更多 vnode,以确保系统的可扩展性。
总的来说,通过创新的设计,TDengine 时序数据库 3.0版本后很好地解决了高基数问题,为业务创新提速。