作者:戴志勇
当"即查即算"遇上数据爆炸
你是否经历过这样的场景?
在阿里云日志服务里,一个看似简单的看板,点开却要等上几十秒;高峰期多人同时查日志,系统直接"卡成 PPT";更糟的是,有时结果还不准------因为达到资源限制,系统只能"估算"答案。
这背后,是日志规模爆炸式增长带来的现实困境:当数据量从 GB 跃升至 TB 甚至 PB 级,"边查边算"的传统模式已力不从心。
- 查得慢: 复杂聚合动辄几十秒,看板刷新比泡杯咖啡还久
- 扛不住: 一到高峰,查询互相抢资源,一个慢、全链路崩
- 不准了: 资源超限被迫降级,数据失真,决策风险陡增
而这些痛点,恰恰集中在最常用的场景------监控大屏、运营看板、实时报表。它们有个共同特点:查询模式固定、时间跨度大、但要求秒级响应、结果精准。
现在,阿里云日志服务带来破局利器------物化视图。
它就像给你的日志数据"提前算好答案,存好快照"。通过智能增量预计算 + 自动查询改写,系统在后台默默把高频查询的结果提前准备好。当你发起请求时,不再扫描全量原始日志,而是直接读取预计算结果------查询速度提升数十倍乃至百倍,资源消耗大幅降低,结果还更稳、更准。
用一点额外的存储空间,换回秒级洞察力。从此,再大的日志量,也能做到"点开即见,所见即所得"。
日志服务物化视图优势
物化视图的核心思想是:用额外的存储空间,换来查询速度的飞跃。日志服务的物化视图主要支持两种场景的查询加速。
1. 过滤加速:只留"有用"的日志
比如你只关心"错误日志",物化视图会提前把所有 error 级别的日志筛选出来单独存好。下次查错误,就不用翻遍全部日志,直接查这个"精选集",速度提升几十倍。
2. 预聚合加速:提前算好统计结果
比如每天要统计"各地区的用户访问量",物化视图会每隔一段时间自动算好这个数据并存起来。你查的时候,系统直接拿现成结果,不用再从原始日志里一条条加总------数据量可能从亿行变成百行。
与业界其他物化视图方案相比,日志服务物化视图具有以下优势:
1. 异步物化视图,增量刷新,不影响写入性能
物化视图的构建完全独立于数据写入流程,采用异步更新机制,每次刷新只针对新写入的数据,更新任务由后端托管,对用户透明。
2. 自动数据合并,写入即可查
自动合并未物化的最近数据和已物化的历史结果,有效解决了同类产品的关键问题:
- 异步刷新痛点:无法读取最新数据,秒级刷新也无法保证数据实时性
- 同步刷新痛点:严重影响写入性能,系统吞吐量大幅下降
3. 支持复杂聚合函数的改写
除了常用的聚合函数(sum、count、avg、min、max等),还支持如下复杂的聚合函数:
count(distinct):精确去重统计approx_percentile:近似百分位数计算approx_distinct:高效近似去重
4. 支持动态更新物化视图
更改物化视图的 SQL 定义时,历史物化视图无需重建,不影响已物化的历史结果。对于经常动态增加列或减少列的场景,这一特性显得尤为重要,可以避免频繁更新物化视图带来的存储和计算成本增加。
5. 透明改写
除了支持 SQL 的透明改写,对于查询语句也可以做谓词的自动补偿。举例说明:
用户创建物化视图的语句:
vbnet
level:error | select latency, host from log where message like '%xxx%'对于如下的查询请求:
sql
level:error and latency > 100 | select avg(latency), host from log where message like '%xxx%' group by host优化器自动添加 latency > 100 作为查询条件去查物化结果,用户完全无感。对于过滤性加速场景,多个 SQL 可以最大化复用物化结果,有效降低了物化带来的存储开销。
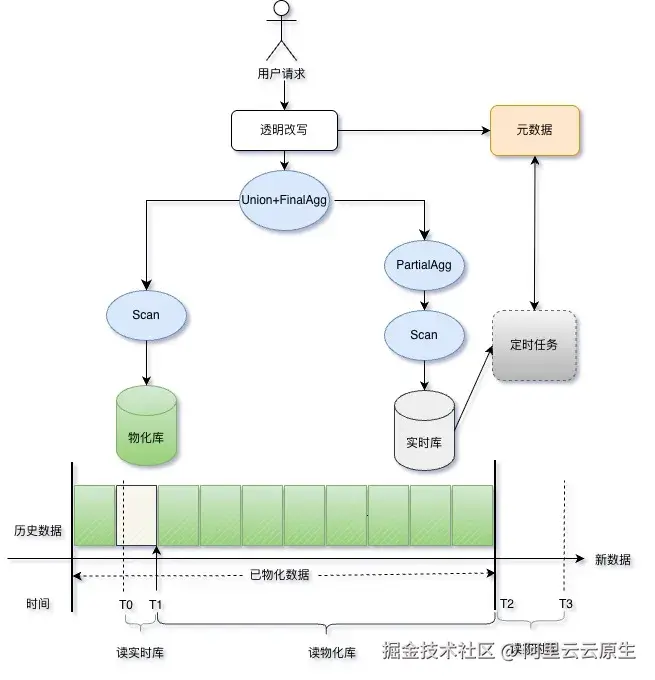
原理介绍
对于用户创建的物化视图,日志服务会在后台自动托管整个计算与维护流程------无需用户干预,一切静默完成。
具体来说,系统会为每个物化视图启动一个智能定时任务,持续追踪新写入的日志数据。每隔一段时间,它就会自动执行您创建视图时指定的 SQL(无论是简单的过滤条件,还是复杂的聚合逻辑),并将计算结果持久化存储起来。每次任务完成后,系统还会精准记录"已处理到哪个时间点",为后续查询提供优化依据。这一切对用户完全透明:不用写调度脚本、不用管任务失败、也不用担心数据一致性------日志服务全权负责。
当发起查询时,基于成本的优化器(CBO)会自动介入:
- 如果发现有匹配的物化视图,它会智能选择最优的一个;
- 对于非聚合类查询,优化器将执行计划改写为"原始数据 + 物化数据"的轻量级 Union;
- 对于聚合类查询,则巧妙地将新数据实时聚合后,再与预计算结果合并。
整个过程无缝衔接,既保证了结果的实时性与准确性,又大幅降低了查询延迟和资源开销。整个架构图如下所示(以聚合场景为例)。
案例分享:Dashboard 从"超时失败"到"秒级响应"
在 Dashboard 场景中,用户对仪表盘打开时间极为敏感,通常要求秒级响应。当多个用户同时刷新 Dashboard 时,如果单个 SQL 请求消耗大量计算资源,会导致计算资源争抢,所有用户都在等待,严重影响用户体验。通过物化视图预计算关键指标,可以将原本需要分钟级计算的复杂查询优化为秒级响应,显著提升用户体验。
举个真实场景:当系统延迟突然飙升,如何快速定位问题?
假设一个高并发的在线服务,其日志数据被写入某个 Logstore 中。每条日志记录的关键信息:
- 请求延迟(latency)
- 请求类型(RequestType)
- 用户 ID(ProjectId)
- 状态码(Status)
- 请求数据量(InFlow)
- 返回数据量(OutFlow)
某时刻,监控告警响起------系统平均延迟突然升高!是正常波动?是流量激增导致?还是某个特定用户或接口出了问题?你需要立刻响应,不想等上几十秒甚至最后超时无法看到结果。
创建物化视图的 SQL:
csharp
*| select avg(latency) as avg_latency,date_trunc('hour', __time__) as time from log group by time
*| select sum(InFlow) as in_flow,sum(OutFlow) as out_flow,avg(latency) as latency, ProjectId,RequestType,Status from log group by ProjectId,RequestType,Status仪表盘使用的 SQL:
sql
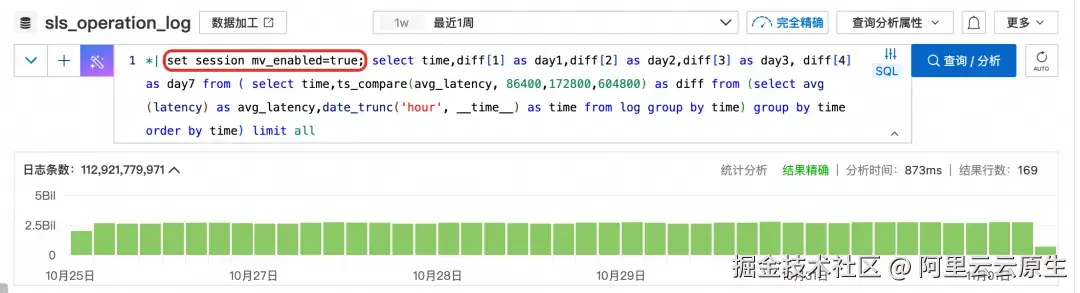
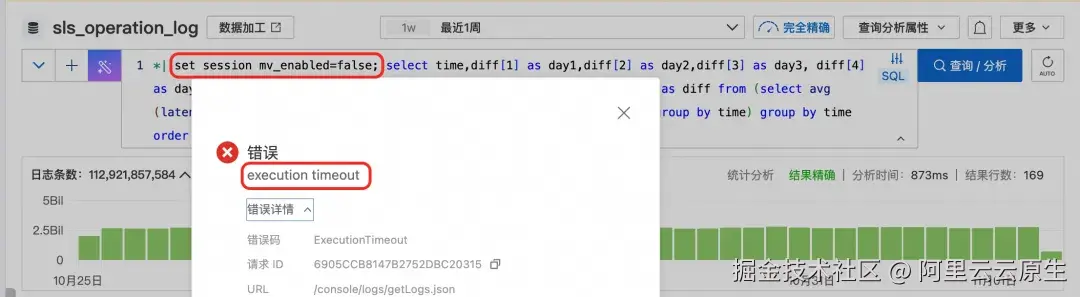
统计每个小时的平均延迟同比一天前、三天前和一周前的变化
*| select time,diff[1] as day1,diff[2] as day2,diff[3] as day3, diff[4] as day7 from ( select time,ts_compare(avg_latency, 86400,172800,604800) as diff from (select avg(latency) as avg_latency,date_trunc('hour', __time__) as time from log group by time) group by time order by time) limit all
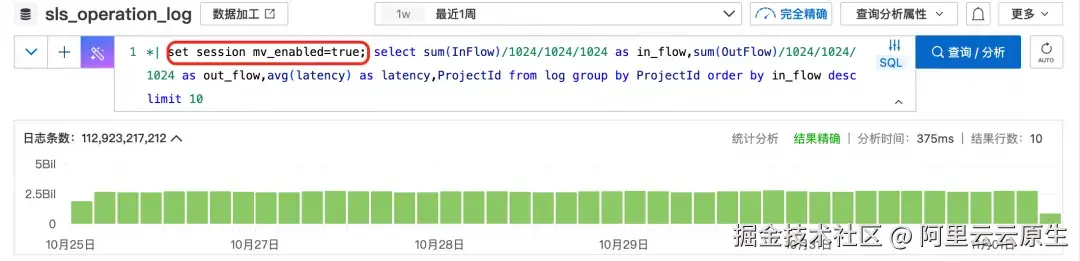
按照 ProjectId 维度统计读写流量和延迟的变化
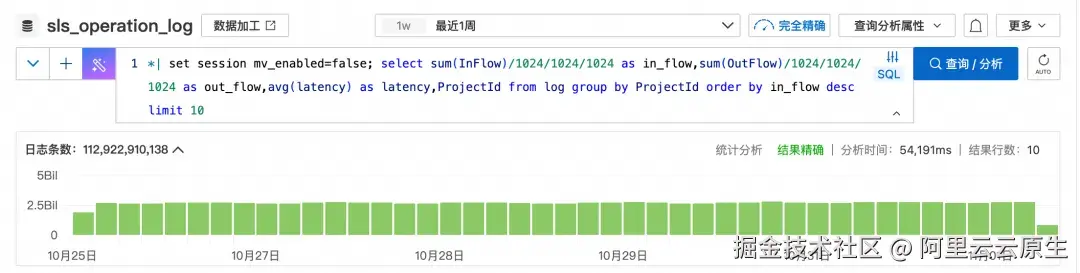
*| select sum(InFlow)/1024/1024/1024 as in_flow,sum(OutFlow)/1024/1024/1024 as out_flow,avg(latency) as latency,ProjectId from log group by ProjectId order by in_flow desc limit 10
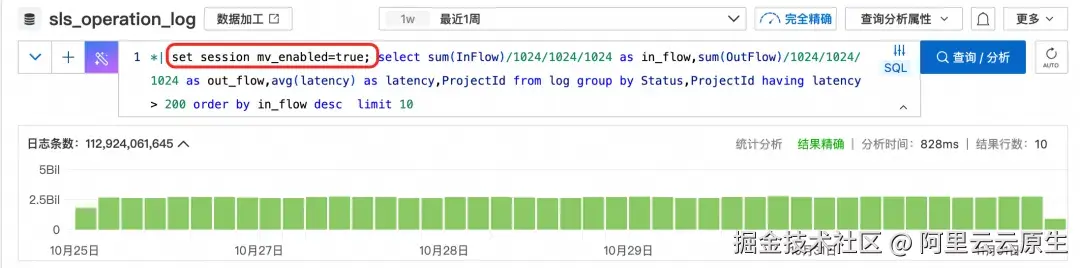
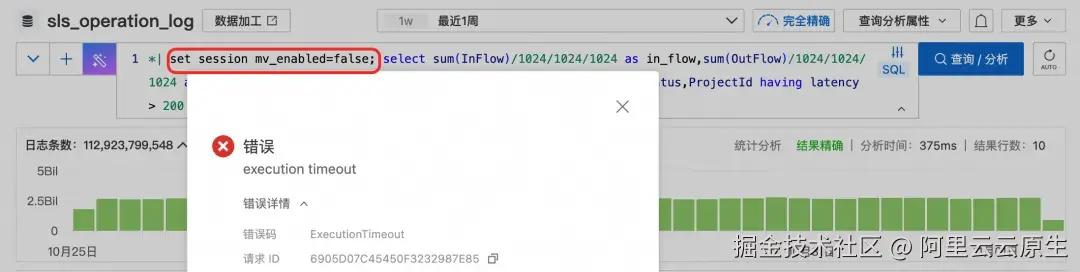
按照 Status 维度和 ProjectId 的维度,统计平均延迟大于 200 的读写流量
*| select sum(InFlow)/1024/1024/1024 as in_flow,sum(OutFlow)/1024/1024/1024 as out_flow,avg(latency) as latency,ProjectId from log group by Status,ProjectId having latency > 200 order by in_flow desc limit 10- 查看近一周延迟同比的变化情况,开启了物化视图的请求,千亿以上数据秒内出结果,未开启的请求直接超时。
- 按照 ProjectId 维度统计读写流量和延迟的变化,开启了物化视图的请求,千亿以上数据不到 400 毫秒返回结果,而未开启的请求 54 秒才返回,性能提升 100 倍以上。
- 按照 Status 维度和 ProjectId 的维度,统计平均延迟大于 200 的读写流量,由于统计的维度更多了,未使用物化视图的请求最后超时了,而使用物化视图后,800 多毫秒返回。
有趣的是,创建物化视图时写的 SQL 和系统实际执行的 SQL 并不完全相同。这正是阿里云日志服务强大的智能优化器在幕后工作------它能自动识别和改写查询逻辑,让用户无需深入了解底层细节,就可以轻松为仪表盘查询加速。
在千亿级数据规模的实测中,采用物化视图的图表可以秒开,而相同的 SQL 若不使用物化视图,即使是最快的情况也需要 50 多秒,更多时候会直接超时无法返回结果。这不仅是性能的提升,更是体验的质的飞跃。理论上来说数据规模越大,加速效果越好。在数据规模更加庞大的另一个 Region 中,万亿级数据的 SQL 查询也能稳定在 3 秒左右完成,进一步验证了随着数据量的增长,物化视图带来的性能收益呈现出更为显著的加速效果。

展望
在数据驱动的时代,阿里云日志服务物化视图通过预计算技术,从根本上解决了大规模日志分析中的性能瓶颈和吞吐量限制问题,为实时日志分析提供了新的技术解决方案。未来,我们将继续在以下方向深耕:
- 智能推荐:自动识别高频查询模式,一键生成最优物化视图
- 扩展使用场景:支持 join 算子的物化视图,支持数据删除场景
- 改写增强:支持表达式非精确匹配的改写