引言:今天我们分为两大部分讲AI大模型的知识点,第一个部分是注意力机制,第二个部分是自注意力机制。
一、注意力机制
01 一句话秒懂
注意力机制=让AI学会"抓重点"的魔法!
可以简单理解为"学霸划重点"。
就像我们在读书时用荧光笔标关键句和重要知识点,AI也主要用注意力机制决定"哪些信息值得放大看"~
02 原理拆解
输入: 一段信息(比如"我爱吃炸鸡")
计算权重: 每个字分配注意力的分数,"炸鸡"分数UP!"我"分数DOWN...
加权输出: 高分信息会被强化处理,最终AI不仅记住句子,还能get到「炸鸡才是灵魂」!
03 为什么颠覆传统?
旧版RNN: 强迫症式逐字处理,记不住长文本;每个字平等对待→学得慢还抓不住重点
注意力机制: 一秒扫描全局,动态锁定关键信息;动态权重分配→哪里重要点哪里!
就像学渣VS学霸的笔记差别
04 举个栗子
输入: "我爱北京天安门"
模型内心OS:
"爱"要重点看(情感核心)
"北京"和"天安门"疯狂打call(实体关联)
"我"稍微记一下就行(主语常规操作)
05 核心技术解析
1)核心思想
通过动态权重分配,让神经网络在处理序列数据时,能够针对不同位置的信息分配不同的关注度(attention)。类比人类阅读时对关键词的重点关注。
2)核心组件
QKV矩阵(Query-Key-Value):
Query: 当前处理位置的表示向量(需要查找什么)
Key: 所有位置的索引向量(能提供什么信息)
Value: 实际携带的信息向量(最终传递的信息)
三者均通过线性变换从输入向量获得,共享同一组输入但承担不同角色
3)计算过程
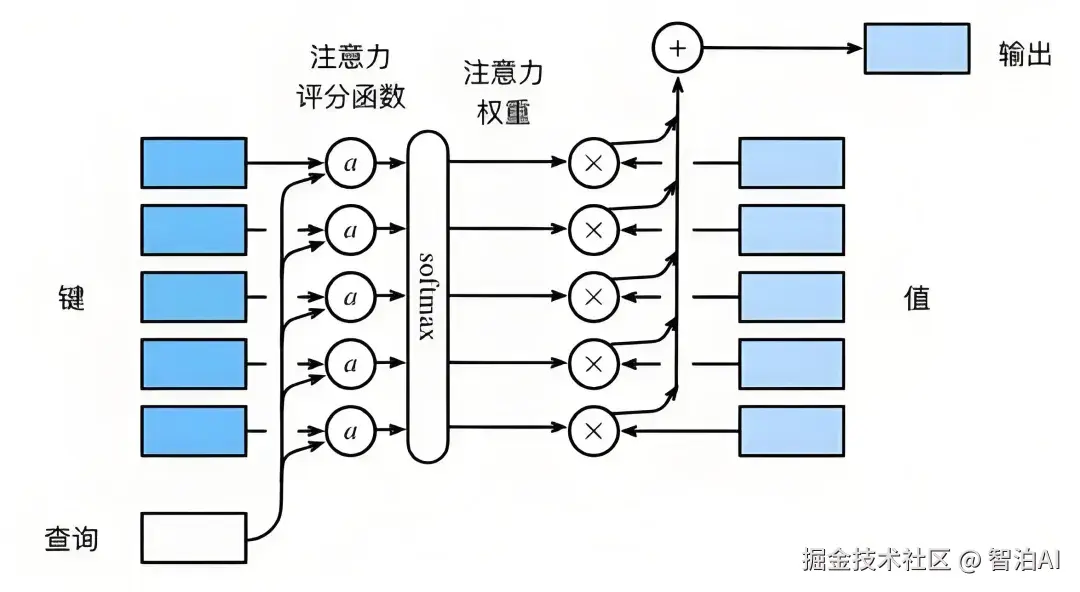
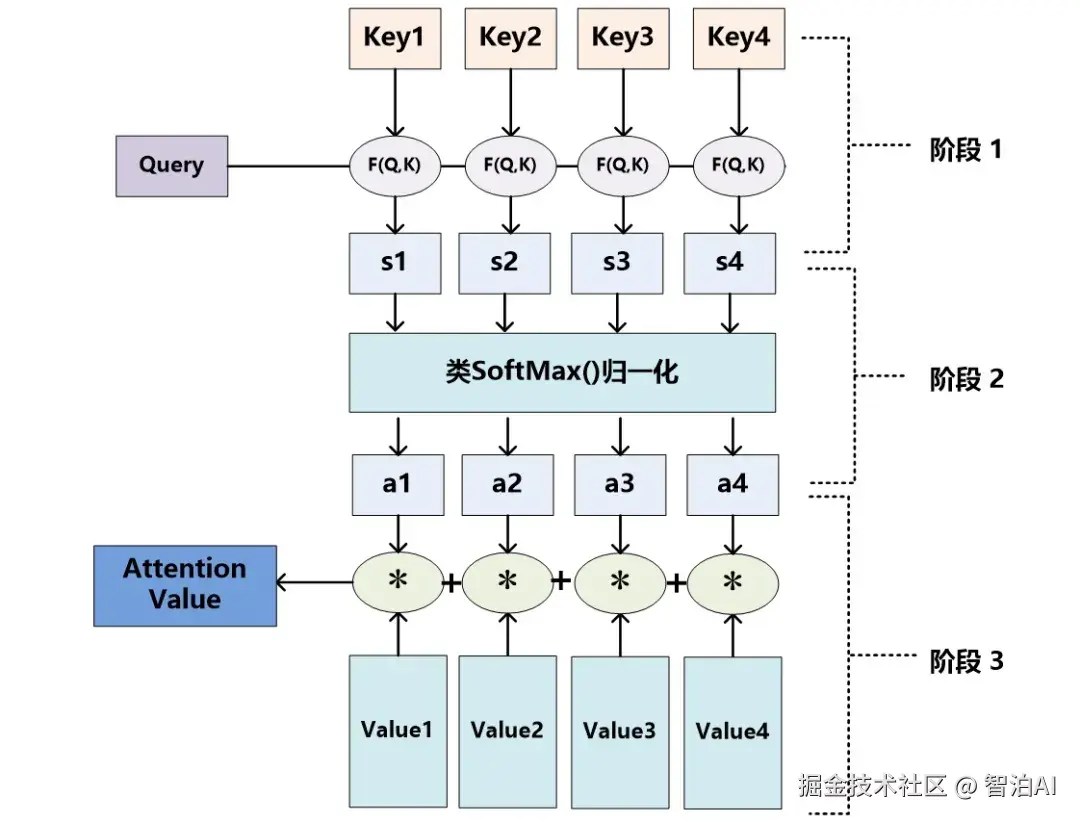
Step 1: 相似度计算: 通过Query与所有Key的点积计算注意力分数
Step 2: 权重归一化: 使用Softmax函数将分数转换为概率分布: AttentionWeights=Softmax(Score)
Step 3: 信息聚合: 加权求和Value向量: 0utput=Σ(Attention Weights * Value)
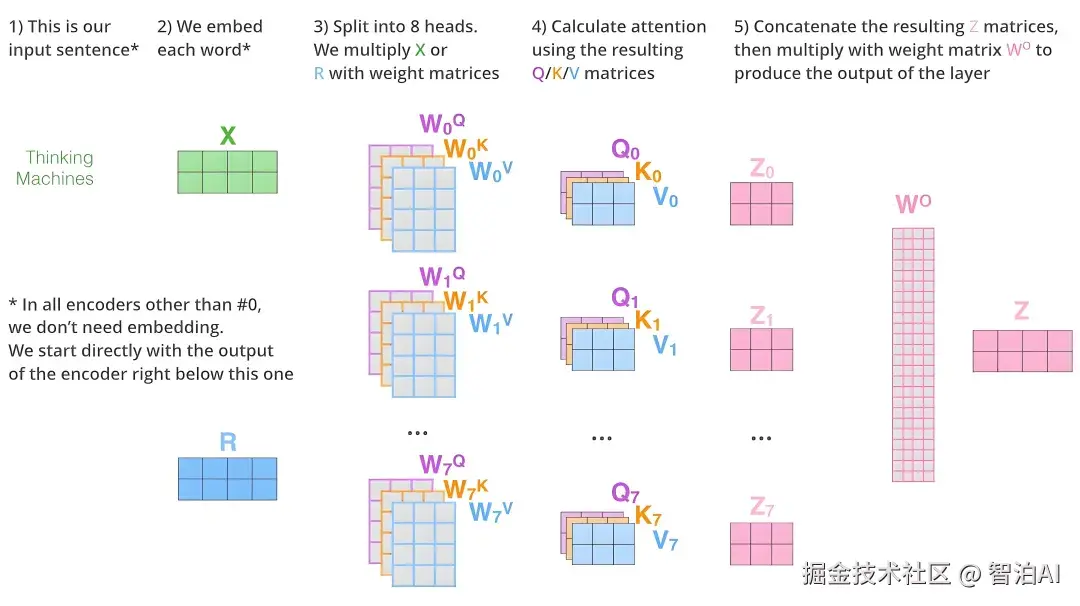
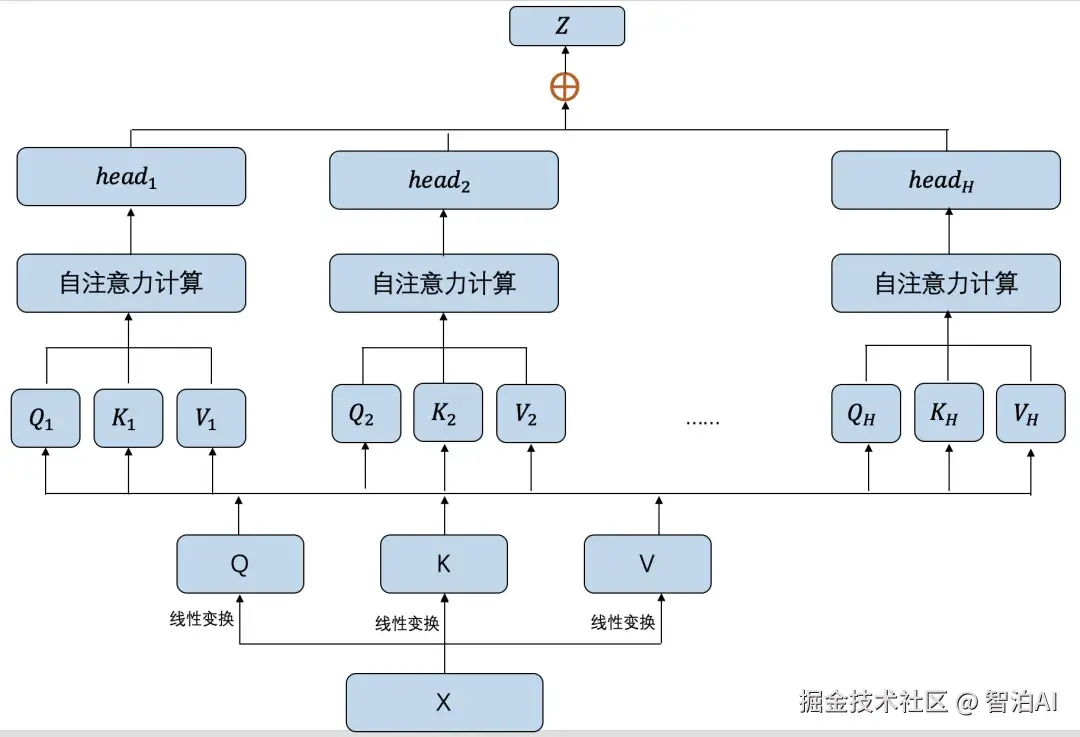
4)多头注意力(Multi-Head)
并行多个独立的OKV计算通道
每个"头"学习不同的语义空间关系
最终拼接所有头的输出并通过线性层融合
5)核心优势
上下文感知: 每个词的表示动态依赖上下文
并行计算: 突破RNN的序列依赖限制
长程依赖: 直接建立任意位置关联
6)实际应用理解
当处理句子"The animal didn't cross the street because it was tootired"时:
"it"的Query会与"animal"的Key产生高相关性
自动消除指代歧义,而非像RNN需要逐步传递状态
通过多头机制,同时捕获语法结构和语义关联
二、自注意力机制
1、自注意力机制是什么?
自注意力机制就像"信息关联雷达"。假设你在读一句话,每个词都会自动扫描整句话的其他词,找出哪些词和自己相关(比如"猫"会更关注"抓"老鼠")。通过动态计算权重,模型决定在理解当前词时,应该"重视"哪些上下文信息。
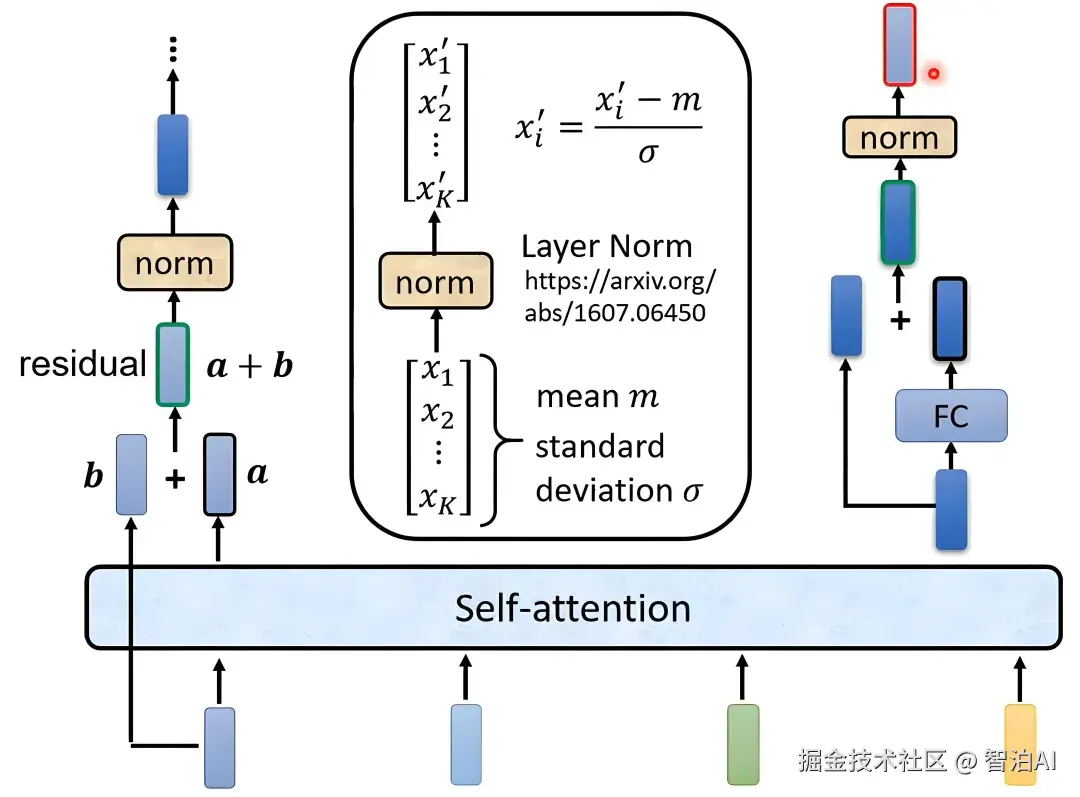
技术定义
自注意力(Self-Attention)是让输入序列中的每个元素(如单词)通过查询(Query)、键(Key)、值(Value) 向量,与其他元素计算相关性权重,最终加权聚合全局信息的机制。
2、自注意力的工作原理(简化版)
输入处理
每个词(如"猫")被转换为三个向量:
Query(要找什么)
Key(能提供什么)
Value(实际内容)
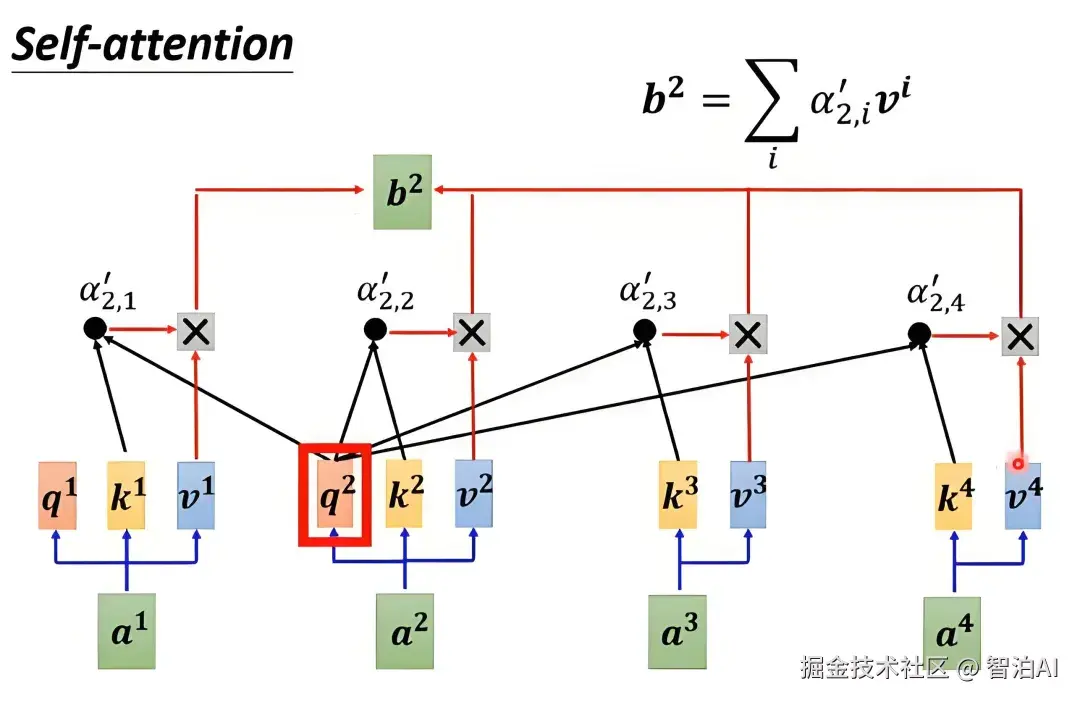
计算相关性
用Query和所有词的Key做点积,得到相关性分数(如"猫"和"抓"分数高,和"天空"分数低)。

归一化与聚合
对分数做Softmax归一化,得到权重(总和为1)
用权重对Value加权求和,得到当前词的新表示(融合了相关上下文)
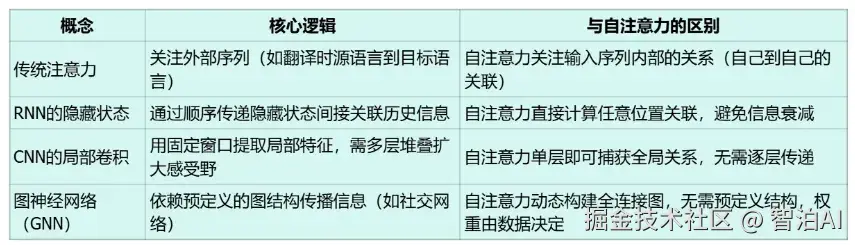
3、与相关概念对比
4、说人话版: 用"自助餐厅选餐"理解自注意力
想象你在自助餐厅搭配一份营养均衡的餐盘:
Query(需求) : 你今天的营养目标(比如"高蛋白、低糖")
Key(食物属性) : 每道菜的标签(如"牛排: 高蛋白; 蛋糕: 高糖")
Value(实际内容) : 食物本身。
自注意力过程:
你拿着需求(Query)扫描所有菜的标签(Key),计算匹配度(比如牛排得分高,蛋糕得分低)。
根据得分分配取餐量(Softmax权重): 牛排拿多,蛋糕拿少。
最终餐盘(输出)是各菜品(Value)按权重的组合,满足你的全局需求
对比传统方法:
RNN式选餐: 必须按顺序取菜,且每次只能参考前一道菜的选择,容易漏掉后面的优质选项
CNN式选餐: 每次只看相邻的3个菜,要来回走多次才能覆盖全部菜品
5、总结与学习建议
总结
自注意力机制通过"动态关联全局信息",解决了传统模型无法高效处理长距离依赖、计算冗余的问题。它是Transformer的核心,也是ChatGPT、BERT等大模型理解上下文的关键。
学习建议
1)先理解核心思想:
重点掌握Query、Key、Value的作用,以及"权重分配-聚合"的流程,暂时忽略数学细节。
2)对比实验:
用PyTorch/TensorFlow实现一个简单的自注意力模块(10行代码以内),对比输入输出变化。
3)结合经典论文:
精读《Attention Is All You Need》的注意力部分,配合代码解读(推荐Jay Alammar的博客)。
4)数学补充:
复习矩阵乘法、Softmax函数、向量点积的意义(关键公式不超过3个)
5)应用延伸:
研究多头注意力(Multi-Head)如何扩展模型能力,以及位置编码为何必要
一句话忠告:
自注意力不是魔法,本质是"通过数据驱动的权重分配,实现信息的高效整合"。先建立直觉理解,再深入数学和代码,避免被复杂公式劝退。
更多AI大模型学习视频及资源,都在智泊AI。