在上一章中,我们使用 MCP 构建了一个多智能体系统(Multi-Agent System,MAS)。这个系统可以工作,但有一个很大的局限:它的"知识"都是模拟出来的。对于学习来说这没问题,但也意味着这些智能体被困在了我们预先设计好的沙盒里:它们不能访问真实信息,也无法根据当前环境即时调整行为。
在这一章,我们要把它们从盒子里"放出来"------让智能体通过基于向量存储(vector store)构建的实时信息管道,连接到外部数据。
精彩的部分现在才开始。我们将引入一个更强大的架构:双 RAG 多智能体系统(dual RAG MAS) 。
它会用两种方式来使用检索增强生成(Retrieval-Augmented Generation,RAG):
- 第一种是你熟悉的:从知识库中检索事实;
- 第二种则是新的:检索"过程性指令",也就是实现过程化 / 动态 RAG所需的"执行脚本"。
这种新增能力改变了游戏规则:
系统不仅能"学会说什么(what to say)",还可以"学会怎么说(how to say it)",并能按需切换风格和结构。
我们会在两个 Notebook 中一步步构建这一系统:
- 第一个 Notebook 聚焦于数据摄入(ingestion) :
我们会为"事实"创建一个知识库(knowledge base),
为"语义蓝图(semantic blueprints)"创建一个上下文库(context library)。 - 第二个 Notebook 负责"运行时执行(runtime execution)":
展示智能体如何在实时执行中检索并组合这两类上下文。
在这个过程中,我们会介绍一个新的专业智能体:上下文馆员(Context Librarian) ,
并看到 Orchestrator(编排器)如何让整个团队保持协同。
本章主要涵盖以下内容:
- 设计一个双 RAG 的 MAS 架构
- 将"事实性知识"和"过程性指令"分离管理
- 为事实构建知识库(Knowledge Base)
- 为语义蓝图创建上下文库(Context Library)
- 使用向量存储的命名空间(namespace)管理不同数据类型
- 实现新的专业智能体,比如 Context Librarian
- 通过编排让整个系统生成"具备上下文感知能力"的内容
接下来,我们先从 RAG MAS 的架构入手。
设计双 RAG MAS 架构
Architecting a dual RAG MAS
要构建这个具备上下文感知能力的系统,我们需要先清晰地理解它的架构。
从高层来看,整个过程被划分为两个互相独立又相互关联的阶段,我们会分别设计和实现:
- Phase 1:数据准备(Data Preparation) ------ 负责把数据准备好
- Phase 2:运行时执行(Runtime Execution) ------ MAS 使用准备好的数据来响应用户目标
本章会在两个对应的 Notebook 中完成这两个阶段。
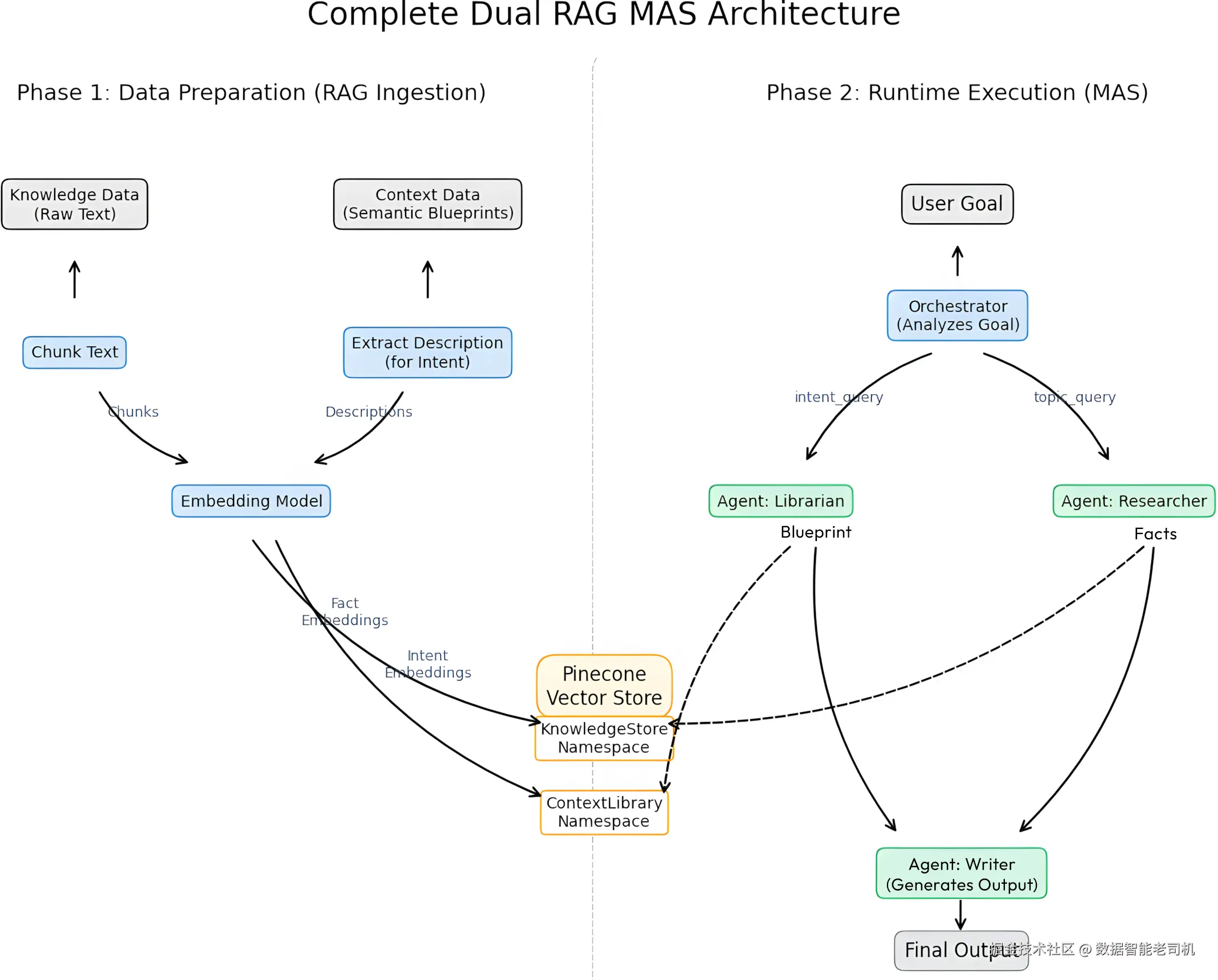
图 3.1:双 RAG MAS 的整体架构
上图展示了双 RAG MAS 架构中数据流与执行流 的全貌,箭头表示组件之间在高层上的连接关系。
在进入具体代码之前,我们先按图把每个部分梳理一遍。
阶段一:数据准备(Phase 1: Data preparation)
在 Phase 1 中,我们专注于准备数据 ,这一部分对应图 3.1 左侧。
系统从两类不同的输入源开始:
- 知识数据(Knowledge data) :
系统应该"知道"的事实性信息 - 上下文数据(Context data) :
结构化指令,或者说语义蓝图(semantic blueprints) ,这在第 1 章中已经介绍过
这两类数据都由同一个**嵌入模型(embedding model)**来处理:
- 对于知识数据,我们会把文本切分成多个 chunk,并对每个 chunk 进行向量化(embedding)。
- 对于上下文数据 / 语义蓝图 ,我们只对"蓝图意图(intent)的描述"进行向量化。
之后的检索将基于"意图"来进行匹配。
完整的蓝图内容则单独存储在一个 JSON 对象中,并与其描述建立关联。
所有的向量会存入 Pinecone 向量数据库,这个库会承载系统需要的一切外部数据。
我们只用一个 Pinecone 索引,但将它划分成两个严格分离的命名空间(namespace):
- KnowledgeStore :
存储来自"事实数据"的向量 - ContextLibrary :
存储来自"过程蓝图 / 语义蓝图"的向量
当这两个命名空间都就位后,系统就可以进入第二阶段。
阶段二:运行时执行分析
Phase 2: Runtime execution analysis
在 Phase 2 中,MAS 会真正开始执行用户请求,对应图 3.1 的右侧。
流程从一个**用户目标(user goal)**开始,这是一条由用户提交的高层指令,例如:
"写一篇关于阿波罗 11 号的悬疑故事"(Write a suspenseful story about Apollo 11)
Orchestrator 收到这个目标,作为系统的中央协调者,它会分析这条请求,并识别出两个关键成分:
-
intent_query :
这是用于"馆员(Librarian)查询"的"意图向量",与期望的风格或结构有关
- 在例子中就是: "悬疑故事(suspenseful story)"
-
topic_query :
这是用于"研究员(Researcher)查询"的"主题向量",与主题内容本身有关
- 在例子中就是: "阿波罗 11 号(Apollo 11)"
随后,Orchestrator 会把这两个查询分派给各自的专业智能体:
-
Librarian 智能体(上下文馆员)
- 职责:检索"指令脚本"(instruction scripts)。
- 它通过引擎的 MCP 消息层接收
intent_query, - 查询的是 ContextLibrary 命名空间,
- 执行语义检索,找到最匹配本次意图的"蓝图描述",
- 然后取回对应的语义蓝图(semantic blueprint) 。
-
Researcher 智能体(研究员)
- 职责:检索"事实信息"。
- 它接收
topic_query, - 查询的是 KnowledgeStore 命名空间,
- 检索与主题相关的事实性文本块(chunks),
- 并把这些信息综合为简明的"研究结论"。
当这两路结果都准备好之后,Orchestrator 会把:
- 来自 Librarian 的指令脚本 / 蓝图,以及
- 来自 Researcher 的综合事实
一并"交付"给 Writer 智能体。
在图 3.1 中,这一过程被箭头表示为:蓝图(blueprint)和事实(facts)从 Librarian 与 Researcher 流向 Writer。
Writer 智能体作为系统的"生成引擎":
- 将"事实"用作内容素材;
- 将"蓝图"用作结构与风格的强约束指令;
在这双重约束下,它生成最终输出:既满足事实正确性 ,又符合过程性 / 风格性指令。
这种架构带来了极高的灵活性与可扩展性:
- 更新知识库,不需要修改指令脚本;
- 新增语义蓝图,也不需要触碰事实数据;
- 在运行时,智能体会根据检索到的上下文,动态调整自身行为。
至此,架构已经讲清楚了。
接下来,我们就可以进入实现部分:第一步是构建 RAG 数据摄入管道(RAG ingestion pipeline) 。
RAG 流水线中的数据摄入(上下文与知识)
在第 2 章里,我们用模拟数据 构建了一个 MAS。
这些智能体"会查资料",但它们能查到的东西只来自一个简单的 Python 字典。
本章要迈出下一步:
用一个真实的 RAG 流水线替换掉这个模拟层。
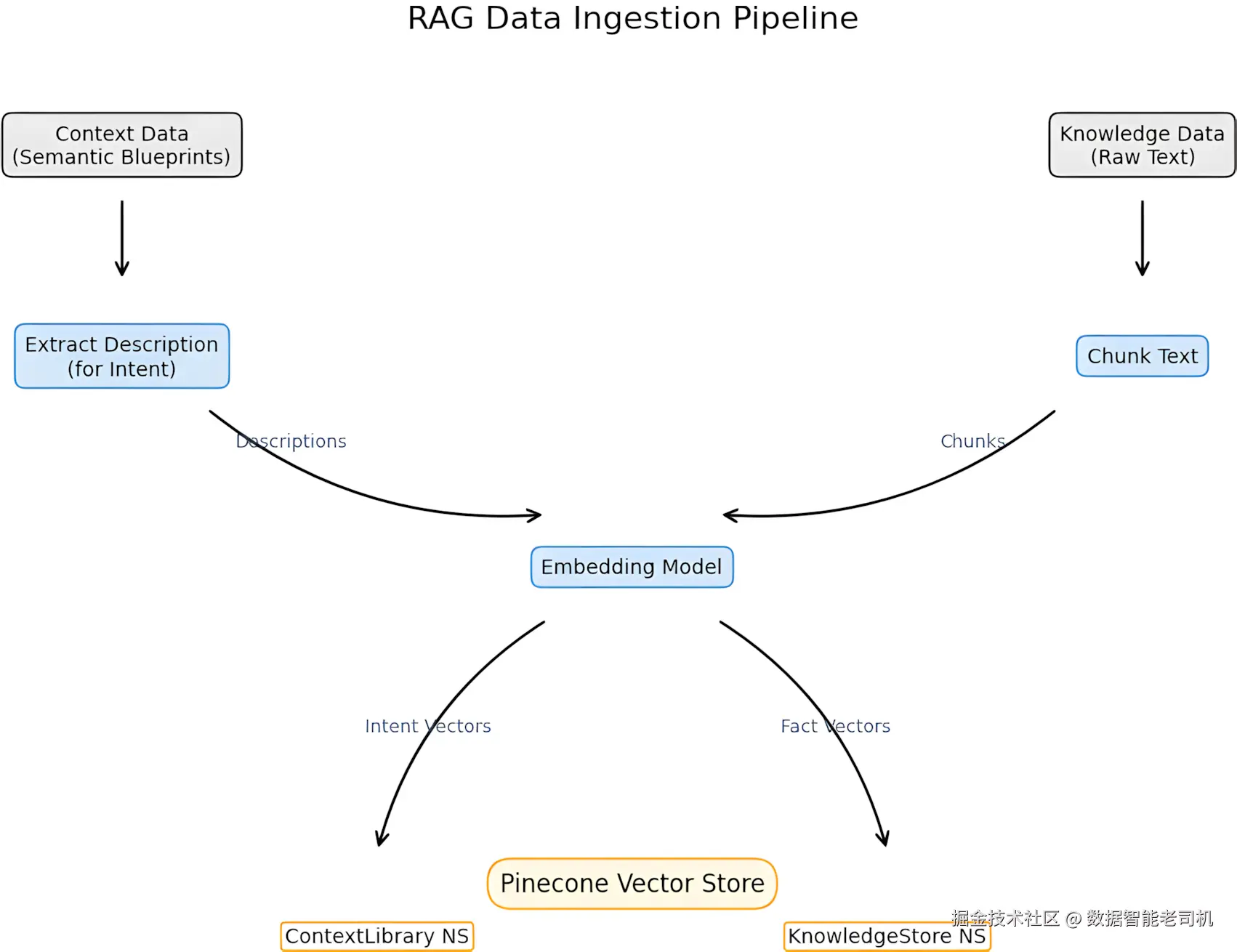
图 3.2:RAG 数据摄入流水线流程图
图 3.2 展示了这条流水线的整体流程。
在智能体能够高效检索之前,我们必须先准备并构建它们要用的数据库。
这里我们引入两种互补的 RAG 形式:
-
知识库(Knowledge base,事实型 RAG) :
存储事实信息。这是最经典、工程师们最熟悉的 RAG 用法。
-
上下文库(Context library,过程型 RAG) :
存储指令或语义蓝图(semantic blueprints) (在第 1 章中介绍过)。
智能体查询这个库,是为了决定:
自己应该用什么结构来组织回答、采用什么风格。
要实现这一切,请打开本章仓库中的 RAG_Pipeline.ipynb。
在这个 Notebook 里,我们将:
- 构建两个数据库(知识库与上下文库);
- 提取并转换数据为向量(embeddings);
- 将这些向量上传到 Pinecone 向量存储中;
- 并通过 namespace 将这两个数据库严格隔离。
安装与环境准备
Installation and setup
先把运行环境准备好。
本项目中我使用 Pinecone 作为向量数据库,但如果你更习惯其它平台,也可以替换;
只要满足向量检索能力即可。
同时,为了更实用一点,我们还会引入:
tqdm:用于监控上传进度;tenacity:用于在网络抖动时,让 API 调用更可靠(自动重试等)。
有一个我自己踩过很多次坑的经验要提前说:
Python 的库生态变化很快 ,如果不锁定版本,很容易从"做系统"变成"打依赖补丁"。
为了避免你也陷在这些问题里,我们在这里直接冻结一些具体版本:
ini
!pip install tqdm==4.67.1 --upgrade
!pip install openai==1.104.2
!pip install pinecone==7.0.0 tqdm==4.67.1 tenacity==8.3.0接下来,把本 Notebook 需要的模块导入进来:
python
# Imports for this notebook
import json
import time
from tqdm.auto import tqdm
import tiktoken
from pinecone import Pinecone, ServerlessSpec
from tenacity import retry, stop_after_attempt, wait_random_exponential
# general imports required in the notebooks of this book
import re
import textwrap
from IPython.display import display, Markdown
import copy要使用 OpenAI 和 Pinecone ,你需要 API Key。
如果你还没有注册,这两个平台的上手流程都很简单;
Pinecone 甚至提供带索引数量限制的免费计划,非常适合实验。
在这个 Notebook 里,我使用的是 Google Colab 的 Secrets Manager 来提供这些 Key;
如果你在本地跑,代码会退回到使用环境变量(environment variables)。
你可以根据自己的环境自由修改这一层。
在嵌入模型上,我使用的是 OpenAI 的 text-embedding-3-small:
- 它会输出 1536 维的向量,
- 对我们的场景来说已经绰绰有余。
你当然可以选择其它嵌入模型,但有一个关键原则:
用来创建向量的模型,必须与检索时使用的模型保持一致。
在完成 API Key 设置之后,我们会把这些细节写进配置变量:
ini
import os
from openai import OpenAI
from google.colab import userdata
# Load the API key from Colab secrets, set the env var, then init the client
...
# Configuration
EMBEDDING_MODEL = "text-embedding-3-small"
EMBEDDING_DIM = 1536 # Dimension for text-embedding-3-small
GENERATION_MODEL = "gpt-5"关于模型选择的小提示:
这里我们使用 GPT-5 是为了在本章和后续章节中保持连续性。
但整个引擎本身是"模型无关"的:
你可以把
GENERATION_MODEL换成任何兼容的 LLM(例如 Mistral 或 Claude),而架构的其它部分(提示词、注册表、Planner/Executor)都可以保持不变。
如果一切配置无误,Notebook 会给出类似下面的提示:
vbnet
OpenAI API key loaded and environment variable set successfully.到这里,我们就可以继续前进,初始化 Pinecone 的索引了。
初始化 Pinecone 索引
Initializing the Pinecone index
现在环境已经准备好了,我们来用刚刚配置的 API Key 连接 OpenAI 和 Pinecone 。
第一步是为 Pinecone 索引起一个名字,本章中我们用:
ini
INDEX_NAME = 'genai-mas-mcp-ch3'接着,获取 Pinecone 的 API Key。示例中依然使用 Colab 的 Secrets Manager:
python
try:
# Standard way to access secrets securely in Google Colab
from google.colab import userdata
PINECONE_API_KEY = userdata.get('PINECONE_API_KEY')
...拿到 API Key 后,我们要为本项目定义两个命名空间(namespace):
它们会在 Pinecone 中将两类数据严格隔离:
NAMESPACE_KNOWLEDGE:存储事实(KnowledgeStore)NAMESPACE_CONTEXT:存储语义蓝图 / 指令(ContextLibrary)
我们使用的是 Pinecone 的 serverless 架构 ,
这也是 Pinecone 免费计划推荐的方式。
本示例中我使用 AWS 的 us-east-1 区域:
ini
# --- Initialize Clients ---
client = OpenAI(api_key=OPENAI_API_KEY)
pc = Pinecone(api_key=PINECONE_API_KEY)
# --- Define Index and Namespaces ---
INDEX_NAME = 'genai-mas-mcp-ch3'
NAMESPACE_KNOWLEDGE = "KnowledgeStore"
NAMESPACE_CONTEXT = "ContextLibrary"
# Define Serverless Specification
spec = ServerlessSpec(cloud='aws', region='us-east-1')在使用索引之前,我们需要先检查它是否已经存在:
如果不存在,就用我们之前定义的维度(1536)创建一个新索引,并将度量方式设为 cosine 相似度------这是文本向量对比很常用的指标:
ini
# Check if index exists
if INDEX_NAME not in pc.list_indexes().names():
print(f"Index '{INDEX_NAME}' not found. Creating new serverless index...")
pc.create_index(
name=INDEX_NAME,
dimension=EMBEDDING_DIM,
metric='cosine',
spec=spec
)
# Wait for index to be ready
while not pc.describe_index(INDEX_NAME).status['ready']:
print("Waiting for index to be ready...")
time.sleep(1)
print("Index created successfully. It is new and empty.")如果索引已经存在,我们可以选择是否清空其中数据。
在本示例中,我们希望每次都从"干净环境"开始,因此会删除两个命名空间里的内容:
ini
else:
print(f"Index '{INDEX_NAME}' already exists. Clearing namespaces for a fresh start...")
index = pc.Index(INDEX_NAME)
namespaces_to_clear = [NAMESPACE_KNOWLEDGE, NAMESPACE_CONTEXT]要清空索引,我们需要依次遍历每个命名空间并删除数据:
ini
for namespace in namespaces_to_clear:
# Check if namespace exists and has vectors before deleting
stats = index.describe_index_stats()
if namespace in stats.namespaces \
AND stats.namespaces[namespace].vector_count > 0:
print(f"Clearing namespace '{namespace}'...")
index.delete(delete_all=True, namespace=namespace)这里有一个"坑点":
删除操作有可能是异步的,而程序可能继续运行得太快。
这意味着:如果删除比较慢,而我们的上传已经开始,新写入的向量有可能被"顺带"删掉------这虽然不是必然,但显然是我们不想承担的风险。
因此,我们强制系统等待,直到向量数量真正变成 0 才继续:
python
# **CRITICAL FUNCTION: Wait for deletion to complete**
while True:
stats = index.describe_index_stats()
if namespace not in stats.namespaces or \
stats.namespaces[namespace].vector_count == 0:
print(f"Namespace '{namespace}' cleared successfully.")
break
print(f"Waiting for namespace '{namespace}' to clear...")
time.sleep(5) # Poll every 5 seconds
else:
print(f"Namespace '{namespace}' is already empty or does not exist. Skipping.")最后,我们就可以正式连接到这个索引,供后续操作使用:
ini
# Connect to the index for subsequent operations
index = pc.Index(INDEX_NAME)如果一切顺利,你会看到类似这样的输出:
vbnet
Index 'genai-mas-mcp-ch3' already exists. Clearing namespaces for a fresh start...
Namespace 'KnowledgeStore' is already empty or does not exist. Skipping.
Namespace 'ContextLibrary' is already empty or does not exist. Skipping.在生产环境中,你通常不会希望每次运行都清空命名空间 ------
很多时候你希望系统保留已构建好的知识。
不过,在我们的学习过程中,每次从"空环境"开始会更加清晰、可控。
索引准备就绪之后,我们就可以进入下一步:准备并写入数据。
数据准备:上下文库(Context Library,过程型 RAG)
在本小节中,我们要为上下文库(context library)定义数据。
这是整个 过程型 RAG(procedural RAG)的核心,因为这里我们引入的不是静态知识,而是"如何做事"的程序性指令 。
上下文库建立在第 1 章介绍的"语义蓝图(semantic blueprint)"概念之上,但这次我们会用一个更精确的结构来实现。
每条上下文库中的记录由三部分组成:
- id :
在 Pinecone 索引中的唯一标识符; - description(描述) :
用来说明这个蓝图的用途与风格。
我们只对 description 做向量化,以便在检索时找到需要的蓝图。
你可以把它想象成"图书馆的卡片",而不是书本本身。 - blueprint(蓝图) :
真正给 LLM 用的指令内容,以 JSON 格式存储。
蓝图本身不会被 embed;当我们通过 description 找到目标后,就像根据书目去书架取书一样,读取完整 JSON 蓝图。
在运行时,这么工作:
- 当 Orchestrator 需要某种特定风格时,
- Librarian(馆员智能体)会根据需求检索最匹配的 description,
- 找到后,再把对应的完整 JSON 语义蓝图取出来。
这种设计非常可扩展 :
你可以在向量库里不断新增新的 LLM 任务蓝图,而无需重写智能体逻辑。
下面我们先定义三个示例蓝图:
- 用于写悬疑叙事(creative writing,悬疑故事)
- 用于技术讲解(technical explanation,强调事实与精确性)
- 用于轻松口吻的总结(casual summary,常见 LLM 用例)
定义语义蓝图本身就是一种关键的上下文工程技能 。
LLM 不是读心术,它需要精心编写的指令 。
即便你借助 copilots 或 API 来自动生成这些蓝图描述,你仍然必须人工审核其质量。
来看第一个例子 ------ 悬疑叙事蓝图 。
这个蓝图是为"讲故事"设计的,目标是营造紧张氛围,让读者一直"紧绷着神经":
css
context_blueprints = [ { "id": "blueprint_suspense_narrative", "description": "A precise Semantic Blueprint designed to generate suspenseful and tense narratives, suitable for children's stories. Focuses on atmosphere, perceived threats, and emotional impact. Ideal for creative writing.", "blueprint": json.dumps({ "scene_goal": "Increase tension and create suspense.", "style_guide": "Use short, sharp sentences. Focus on sensory details (sounds, shadows). Maintain a slightly eerie but age-appropriate tone.", "participants": [ { "role": "Agent", "description": "The protagonist experiencing the events." }, { "role": "Source_of_Threat", "description": "The underlying danger or mystery." } ],
"instruction": "Rewrite the provided facts into a narrative adhering strictly to the scene_goal and style_guide."
})
},可以看到,这里的措辞要非常具体。
写"儿童向的悬疑故事"和写"技术说明文"完全不是一回事,蓝图必须体现这种差异。
下面是第二个蓝图 ------ 技术说明蓝图 。
它和上面的叙事蓝图几乎是反过来的:不用氛围和情绪,而是强调清晰、结构、客观性:
css
{
"id": "blueprint_technical_explanation",
"description": "A Semantic Blueprint designed for technical explanation or analysis. This blueprint focuses on clarity, objectivity, and structure. Ideal for breaking down complex processes, explaining mechanisms, or summarizing scientific findings.",
"blueprint": json.dumps({
"scene_goal": "Explain the mechanism or findings clearly and concisely.",
"style_guide": "Maintain an objective and formal tone. Use precise terminology. Prioritize factual accuracy and clarity over narrative flair.",
"structure": ["Definition", "Function/Operation", "Key Findings/Impact"],
"instruction": "Organize the provided facts into the defined structure, adhering to the style_guide."
})
},这种格式正是你在技术或科学场景中需要的那种可预测结构。
最后是第三个蓝图 ------ 轻松总结(casual summary) ,
这种风格很适合做快速浏览的说明文或"小白向解释":
css
{
"id": "blueprint_casual_summary",
"description": "A goal-oriented context for creating a casual, easy-to-read summary. Focuses on brevity and accessibility, explaining concepts simply.",
"blueprint": json.dumps({
"scene_goal": "Summarize information quickly and casually.",
"style_guide": "Use informal language. Keep it brief and engaging. Imagine explaining it to a friend.",
"instruction": "Summarize the provided facts using the casual style guide."
})
}
]在这种场景下,我们不需要太多角色或严格结构,
而是通过 style_guide 把 LLM 推向:
- 简短、
- 口语化、
- 更亲切易懂的语气,好像你在给同事或朋友解释一个概念。
为了确认蓝图格式是否正确,我们可以打印一下:
python
print(f"\nPrepared {len(context_blueprints)} context blueprints.")输出表明我们一共定义了三个蓝图:
erlang
Prepared 3 context blueprints.这里需要记住的要点是:创建语义蓝图既强大,也很"烧脑" 。
- 没有这些蓝图,你可能要为每一种 LLM 任务写一个独立的智能体 ------ 这根本不可扩展。
- 有了语义蓝图,你可以将"过程性指令"一次编码,多处复用。
与其在产品界面里不断增加几十个下拉选项,不如构建一个可扩展的自动化上下文引擎来调配这些蓝图。
蓝图这边搞定了,接下来就轮到双 RAG 中的另一半:知识库(Knowledge Base) 。
数据准备:知识库(Knowledge Base,事实型 RAG)
接下来,我们要为**知识库(knowledge base)**准备数据 ------ 这是 RAG 架构中"事实侧"的部分。
它存放相对静态的信息,Researcher 智能体会在其中检索,并把结果综合成简明的"研究结论"。
顺便强调一下现实情况:
你设计的是系统本身 ,而不是 LLM。
在那些看起来很酷的平台背后,实际上有大量需要人类细致设计与准备的工作。
在这个教学示例里,我们使用一个关于太空探索的小型数据集,包括:
- 太空竞赛与阿波罗 11 号任务;
- Juno 木星探测器;
- 火星探测车等内容。
为了让重点落在"架构"上,本章里我们直接用字符串来表示这份数据:
ini
knowledge_data_raw = """
Space exploration is the use of astronomy and space technology to explore outer space. The early era of space exploration was driven by a "Space Race" between the Soviet Union and the United States. The launch of the Soviet Union's Sputnik 1 in 1957, and the first Moon landing by the American Apollo 11 mission in 1969 are key landmarks.
...
Juno is a NASA space probe orbiting the planet Jupiter. It was launched on August 5, 2011, and entered a polar orbit of Jupiter on July 5, 2016.
...
A Mars rover is a remote-controlled motor vehicle designed to travel on the surface of Mars. NASA JPL managed several successful rovers including: Sojourner, Spirit, Opportunity, Curiosity, and Perseverance. The search for evidence of habitability and organic carbon on Mars is now a primary NASA objective. Perseverance also carried the Ingenuity helicopter.
"""接下来,我们会写一个小小的辅助函数,把这段文本切分成更适合检索的片段(chunks),再进行向量化。
分块与向量化的辅助函数
语言模型并不是直接处理"段落",而是处理token ------ 也就是模型能理解的最小文本单元。
例如,单词 encoding 可能会被拆成两个 token:encod 和 ing。
模型通过这些更细粒度的 token 来理解词与词之间的关系。
我们会使用 cl100k_base 这个 tokenizer,这是 OpenAI 最新模型的标准配置。
它有三个优势:
- 更聪明的分词方式 :
像encoding这样的词不会被当作一个整体,而是拆成encod和ing等有意义的片段,
有助于模型更好地理解不同词语之间的联系。 - 高效且适配对话/检索场景 :
对于聊天模型和要存入数据库的文本,它都非常高效。 - 与模型训练方式保持一致 :
你统计和格式化文本的方式与模型的预期一致,
也就能最大化检索的准确性。
这点非常关键:
如果我们的"分块逻辑"和嵌入模型的训练方式不匹配,
语义检索的结果就会走样------就像你在一个图书馆里查书,但卡片和书架用的是两套完全不同的编目系统。
先初始化 tokenizer:
ini
# Initialize tokenizer for robust, token-aware chunking
tokenizer = tiktoken.get_encoding("cl100k_base")RAG 在信息被**切分成聚焦的小块(chunks)**时效果最好。
相比按字符数截断,我们会按 token 数量 截断,更适合 LLM。
在示例程序中,我们设定:
chunk_size = 400tokensoverlap = 50tokens
**重叠(overlap)**可以帮助相邻块之间保持上下文连续性。
实际项目中,你需要根据数据类型来调节 chunk 大小与重叠大小。
下面的 chunk_text 函数就负责:
- 按 token 数量将长文本切成一个个重叠窗口,
- 再将这些窗口还原成文本,供后续向量化使用:
python
def chunk_text(text, chunk_size=400, overlap=50):
"""Chunks text based on token count with overlap (Best practice for RAG)."""
tokens = tokenizer.encode(text)
chunks = []
for i in range(0, len(tokens), chunk_size - overlap):
chunk_tokens = tokens[i:i + chunk_size]
chunk_text = tokenizer.decode(chunk_tokens)
# Basic cleanup
chunk_text = chunk_text.replace("\n", " ").strip()
if chunk_text:
chunks.append(chunk_text)
return chunks有了这些 chunk 之后,我们就需要把它们转换成 embeddings。
由于 API 调用有时会失败(比如网络抖动),我们会加一个带重试机制的封装。
tenacity 库提供的 @retry 装饰器可以自动重试失败的调用,并采用**指数退避(exponential backoff)**策略:
python
@retry(
wait=wait_random_exponential(min=1, max=60),
stop=stop_after_attempt(6)
)我们不会单条上传 chunk,而是按批成组发送,因此定义 get_embeddings_batch 函数:
它会将一批文本发送给 OpenAI 的 Embedding API,返回对应的向量:
python
@retry(
wait=wait_random_exponential(min=1, max=60),
stop=stop_after_attempt(6)
)
def get_embeddings_batch(texts, model=EMBEDDING_MODEL):
"""Generates embeddings for a batch of texts using OpenAI, with retries."""
# OpenAI expects the input texts to have newlines replaced by spaces
texts = [t.replace("\n", " ") for t in texts]
response = client.embeddings.create(input=texts, model=model)
return [item.embedding for item in response.data]现在,我们已经具备了:
- 按 token 切分文本的能力,
- 稳定生成 embeddings 的能力(带自动重试)。
下一步,就可以正式开始对"知识数据"和"上下文数据"进行处理,并把它们上传到向量库中了。
处理并上传(upsert)数据
数据准备的最后一步,就是处理这些数据并把它们上传到 Pinecone 。
这一步非常关键:只有当向量真正存进向量库后,智能体才能在运行时检索到它们。
我们分两部分来做:
- 上下文库(Context Library) :上传语义蓝图(semantic blueprints)
- 知识库(Knowledge Base) :上传事实数据
上下文库(Context Library)
先从上下文库开始。
这里存放的是我们的语义蓝图,也就是指导系统"该如何写"的程序性指令。
程序会遍历前面定义好的 context_blueprints 列表:
-
对每个 blueprint,用
get_embeddings_batch对其 description 做向量化;- 后续做语义检索时,查的就是这个描述文本,所以只有它需要进入向量空间。
-
同时构建 Pinecone 的向量对象:
-
id:唯一标识符; -
values:embedding 向量; -
metadata:包含两类信息:- 再存一份
description以便人类查看; - 最关键的是
blueprint_json,即完整的 JSON 语义蓝图指令。
- 再存一份
-
注意:JSON 蓝图本身不做向量化 ,而是作为 metadata 存储。
当我们通过 description 找到这个 vector 时,就能顺带把完整蓝图取出来使用。
代码如下:
python
# --- 6.1. Context Library ---
print(f"\nProcessing and uploading Context Library to namespace: {NAMESPACE_CONTEXT}")
vectors_context = []
for item in tqdm(context_blueprints):
# We embed the DESCRIPTION (the intent)
embedding = get_embeddings_batch([item['description']])[0]
vectors_context.append({
"id": item['id'],
"values": embedding,
"metadata": {
"description": item['description'],
# The blueprint itself (JSON string) is stored as metadata
"blueprint_json": item['blueprint']
}
})当所有向量准备好之后,我们就可以把它们upsert 到 Pinecone 里。
upsert = 如果 ID 已存在则更新,否则插入新数据。
我们将这些向量上传到 NAMESPACE_CONTEXT 对应的 namespace 中:
python
# Upsert data
if vectors_context:
index.upsert(vectors=vectors_context, namespace=NAMESPACE_CONTEXT)
print(f"Successfully uploaded {len(vectors_context)} context vectors.")如果运行成功,你会看到一条确认信息,说明上传了多少条向量。
到这一步为止,上下文库已经写入 ContextLibrary 命名空间,运行时 Librarian 智能体就可以开始查询它了。
接下来我们处理双 RAG 的另一半:知识库。
知识库(Knowledge Base)
现在来填充知识库 ------ 这里存放事实数据,供 Researcher 智能体检索。
第一步是对原始知识字符串 knowledge_data_raw 调用 chunk_text,
把它切成更小、易于检索的片段(chunks)。
然后我们按批次处理这些 chunks。
示例中使用的批大小是 100:
-
逐批生成 embeddings(
get_embeddings_batch); -
为 Pinecone 准备向量结构:
- 每个 chunk 分配一个唯一的
id; metadata中存储原始文本text,便于检索时返回。
- 每个 chunk 分配一个唯一的
代码如下:
python
# --- 6.2. Knowledge Base ---
print(f"\nProcessing and uploading Knowledge Base to namespace: {NAMESPACE_KNOWLEDGE}")
# Chunk the knowledge data
knowledge_chunks = chunk_text(knowledge_data_raw)
print(f"Created {len(knowledge_chunks)} knowledge chunks.")
vectors_knowledge = []
batch_size = 100 # Process in batches
for i in tqdm(range(0, len(knowledge_chunks), batch_size)):
batch_texts = knowledge_chunks[i:i+batch_size]
batch_embeddings = get_embeddings_batch(batch_texts)
batch_vectors = []
for j, embedding in enumerate(batch_embeddings):
chunk_id = f"knowledge_chunk_{i+j}"
batch_vectors.append({
"id": chunk_id,
"values": embedding,
"metadata": {
"text": batch_texts[j]
}
})
# Upsert the batch
index.upsert(vectors=batch_vectors, namespace=NAMESPACE_KNOWLEDGE)
print(f"Successfully uploaded {len(knowledge_chunks)} knowledge vectors.")运行后,输出会同时展示上下文库与知识库的上传进度:
-
tqdm进度条会实时显示每一步嵌入的情况; -
在这个示例中:
-
上下文库确认成功上传了 3 条蓝图向量;
-
知识库数据很小,被切成 2 个 chunk;
- 它们都落在了同一批(batch)100 条的范围内;
-
最终输出确认这 2 个向量也都成功写入:
-
vbnet
Processing and uploading Context Library to namespace: ContextLibrary
[Tqdm output for 3/3 iterations]
Successfully uploaded 3 context vectors.
Processing and uploading Knowledge Base to namespace: KnowledgeStore
Created 2 knowledge chunks.
[Tqdm output for 1/1 iterations]
Successfully uploaded 2 knowledge vectors.至此:
- 上下文库(ContextLibrary) 和
- 知识库(KnowledgeStore)
都已经成功写入向量存储。
接下来,我们就可以在运行时构建真正的上下文感知多智能体系统 (context-aware MAS),
让智能体一边查事实,一边查"写作蓝图",再把两者在生成阶段组合起来。
构建上下文感知系统
现在我们的数据已经 idx_4273754a 准备好并存入了 Pinecone,是时候把所有东西组合起来了。本节我们将实现图 3.3 展示的上下文感知系统(context-aware system) 。具体步骤在 Context_Aware_MAS.ipynb 笔记本中,对应的是整套架构的运行时执行阶段。我们会先定义负责核心任务的专业智能体,然后再看 Orchestrator 是如何协调整个流程的。
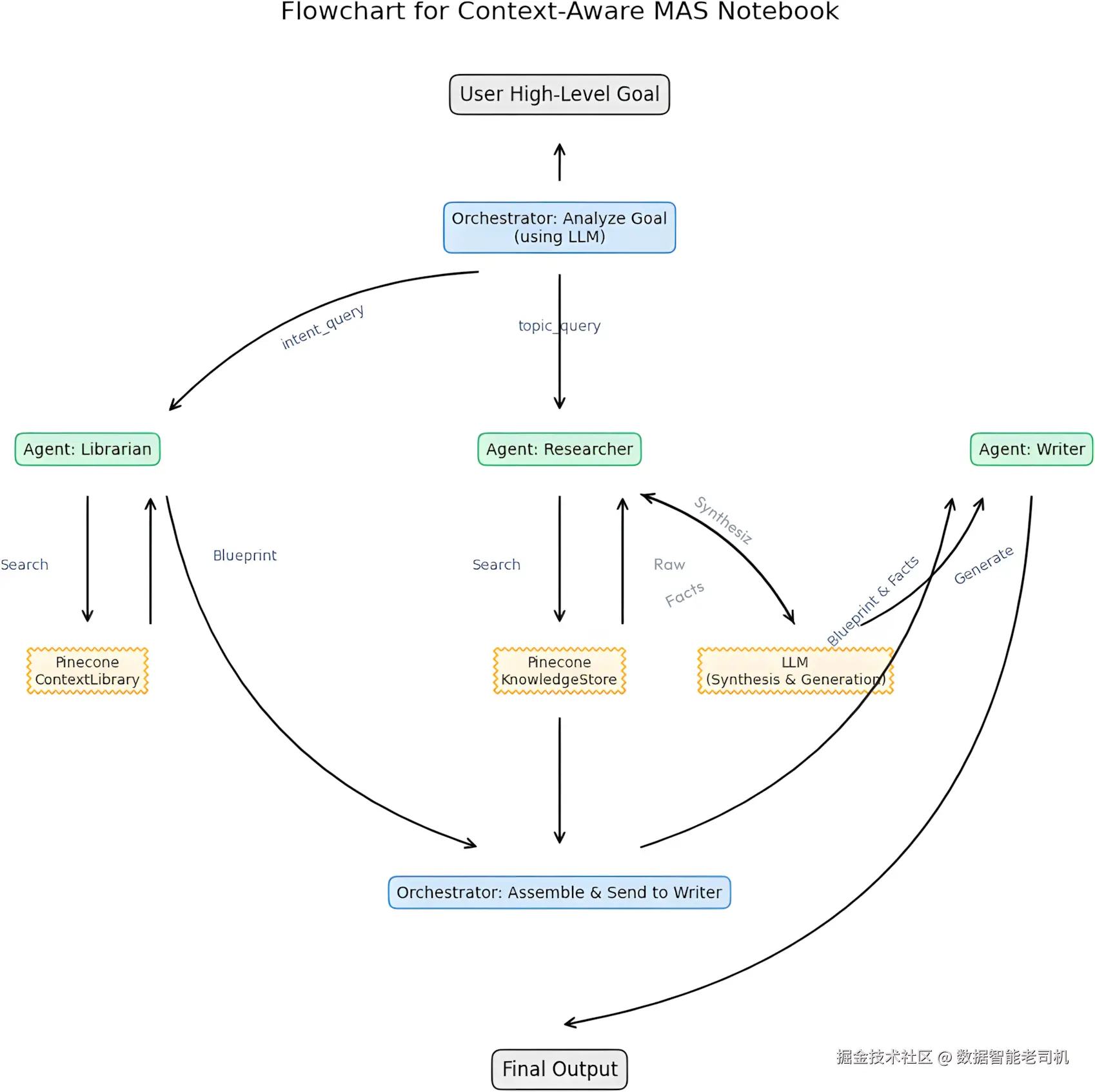
图 3.3:上下文感知 MAS 流程图
这张流程图展示了一个高层用户目标如何被转化为结构化的工作流。它很好地提醒我们:生成式 AI 并不是"开箱即用就 magically 工作"。谨慎的工程设计和上下文管理才是系统可靠运行的关键。
在图中,蓝色方块代表 Orchestrator(编排器),它作为中央协调者,把任务分派给若干专业智能体(绿色方块) :Librarian、Researcher 和 Writer。这些智能体会与外部服务(橙色方块)交互,例如 Pinecone(用于知识和蓝图检索)以及 LLM(用于向量化、分析与生成)。
有了这个全局图,我们就可以深入细节,从智能体本身开始。
定义智能体
整个 MAS 依赖三个 idx_82f9cb5d 专门的智能体,每个智能体都有明确的职责:
- Context Librarian(上下文馆员) :从上下文库中检索 idx_71e1c2b3 过程性 idx_0bbfccaf 指令
- Researcher(研究员) :从知识库中抽取 idx_4f52270a 并综合 idx_6e261e5c 事实数据
- Writer(写作者) :将 idx_3873fac6 过程性指令 idx_8039414a 与事实数据结合,生成最终输出
所有智能体都通过 MCP 进行通信。我们先从 Librarian 智能体开始。
Context Librarian 智能体
Context idx_975aad91 Librarian 的职责是从向量库中检索正确的语义蓝图(Semantic Blueprint) 。
这是一种更高级的 RAG 用法:检索的不是"事实",而是**"写作方式"** ------ 也就是过程性指令:
python
def agent_context_librarian(mcp_message):
"""
Retrieves the appropriate Semantic Blueprint from the Context Library.
"""
print("\n[Librarian] Activated. Analyzing intent...")
requested_intent = mcp_message['content']['intent_query']
results = query_pinecone(requested_intent, NAMESPACE_CONTEXT, top_k=1)
if results:
match = results[0]
print(f"[Librarian] Found blueprint '{match['id']}' (Score: {match['score']:.2f})")
blueprint_json = match['metadata']['blueprint_json']
content = {"blueprint": blueprint_json}
else:
print("[Librarian] No specific blueprint found. Returning default.")
content = {"blueprint": json.dumps({"instruction": "Generate the content neutrally."})}
return create_mcp_message("Librarian", content)这里发生的事情是:
- Librarian 使用用户的意图
intent_query,在ContextLibrary命名空间里做语义检索; - 找到匹配的 blueprint 后,从 metadata 中取出 JSON 格式的指令;
- 再把这些指令封装到一个新的 MCP 消息中返回。
这样,Writer 智能体就能根据动态检索到的程序性指南来写作。
代码中还包含了一个重要的兜底机制 :
如果 Librarian 没找到任何匹配的语义蓝图,它就不会直接报错,而是返回一个默认蓝图:
{"instruction": "Generate the content neutrally."}
也就是说,如果用户的意图与现有蓝图都不匹配,系统不会停摆,而是退回到"中性生成"的简单策略。
这样 Writer 依然能拿到一套过程性指导,哪怕只是"中性写作",系统也能继续完成任务,而不是 idx_3aa5ac30 整个流程中断。
Researcher 智能体
Researcher 智能体 idx_5affbcf7 专注于从知识库中抽取 idx_2c1b5574 相关事实,并把这些信息综合成简明的摘要,方便 Writer 直接使用:
python
def agent_researcher(mcp_message):
"""
Retrieves and synthesizes factual information from the Knowledge Base.
"""
print("\n[Researcher] Activated. Investigating topic...")
topic = mcp_message['content']['topic_query']
results = query_pinecone(topic, NAMESPACE_KNOWLEDGE, top_k=3)
if not results:
print("[Researcher] No relevant information found.")
return create_mcp_message("Researcher", {"facts": "No data found."})
source_texts = [match['metadata']['text'] for match in results]
system_prompt = """You are an expert research synthesis AI. Synthesize the provided source texts into a concise, bullet-pointed summary relevant to the user's topic. Focus strictly on the facts provided in the sources. Do not add outside information."""
user_prompt = f"Topic: {topic}\n\nSources:\n" + "\n\n---\n\n".join(source_texts)
findings = call_llm(system_prompt, user_prompt)
return create_mcp_message("Researcher", {"facts": findings})在这里,Researcher 保持输出简洁且事实导向:
-
只关心从知识库中召回的文本;
-
系统提示(system_prompt)明确要求:
- 严格基于给定来源;
- 不得添加外部信息;
即使在更大的系统中,这种受控的"事实摘要"步骤也很关键,它可以避免 Writer 被一大堆原始文本淹没。
接下来,我们还需要一个 Writer 智能体来真正写出内容。
Writer 智能体
Writer 智能体是两个信息流的汇合点:
它把语义蓝图(过程性指令)和事实摘要结合起来,生成最终结构化的输出:
ini
def agent_writer(mcp_message):
"""
Combines factual research with the semantic blueprint to generate final output.
"""
print("\n[Writer] Activated. Applying blueprint to facts...")
facts = mcp_message['content']['facts']
blueprint_json_string = mcp_message['content']['blueprint']
# The Writer's System Prompt incorporates the dynamically retrieved blueprint
system_prompt = f"""You are an expert content generation AI.
Your task is to generate content based on the provided RESEARCH FINDINGS.
Crucially, you MUST structure, style, and constrain your output according to the rules defined in the SEMANTIC BLUEPRINT provided below.
--- SEMANTIC BLUEPRINT (JSON) ---
{blueprint_json_string}
--- END SEMANTIC BLUEPRINT ---
Adhere strictly to the blueprint's instructions, style guides, and goals. The blueprint defines HOW you write; the research defines WHAT you write about.
"""
user_prompt = f"--- RESEARCH FINDINGS ---\n{facts}\n--- END RESEARCH FINDINGS ---\nGenerate the content now."
final_output = call_llm(system_prompt, user_prompt)
return create_mcp_message("Writer", {"output": final_output})这个智能体的关键点在于,它通过 blueprint 对 LLM 进行动态"编程" :
- blueprint 规定"怎么写(HOW) ";
- facts 决定"写什么(WHAT) "。
系统提示里刻意画了一条清晰的界线:
"The blueprint defines HOW you write; the research defines WHAT you write about."
正是这种"职责分离" idx_3b44a307 让整个系统具有很强的可适配性和可扩展性 idx_ab0e706d ------
你可以更新知识库而不改写作风格蓝图,也可以新增蓝图而不动事实存储。
接下来,我们要构建把这一切串起来的 Orchestrator。
构建 Orchestrator(编排器)
Orchestrator(编排器)是整个系统的"指挥家"。它的职责是:接收一个高层目标,把它拆解成可执行的查询,然后协调各个智能体,最终生成结果。你可以把它想象成一个项目经理:自己不干具体活儿,但要确保每个人都在正确的节奏上协同工作。
目标分析(Goal analysis)
Orchestrator 首先会把用户的高层目标拆解成两个部分:
- intent_query:想要的风格、语气或格式(例如"悬疑叙事蓝图""客观技术解释结构")
- topic_query:要处理的事实主题(例如"朱诺号任务目标与供电方式""阿波罗 11 号登月细节")
代码大致如下:
python
def orchestrator(high_level_goal):
"""
Manages the workflow of the Context-Aware MAS.
"""
print(f"=== [Orchestrator] Starting New Task ===")
print(f"Goal: {high_level_goal}")
# Step 0: Analyze Goal (Determine Intent and Topic)
# We use the LLM to separate the desired style (intent) from the subject matter (topic).
print("\n[Orchestrator] Analyzing Goal...")
analysis_system_prompt = """You are an expert goal analyst. Analyze the user's high-level goal and extract two components:
1. 'intent_query': A descriptive phrase summarizing the desired style, tone, or format, optimized for searching a context library (e.g., "suspenseful narrative blueprint", "objective technical explanation structure").
2. 'topic_query': A concise phrase summarizing the factual subject matter required (e.g., "Juno mission objectives and power", "Apollo 11 landing details").
Respond ONLY with a JSON object containing these two keys."""
# We request JSON mode for reliable parsing
analysis_result = call_llm(
analysis_system_prompt, high_level_goal, json_mode=True)
)
try:
analysis = json.loads(analysis_result)
intent_query = analysis['intent_query']
topic_query = analysis['topic_query']
except (json.JSONDecodeError, KeyError):
return在这里,Orchestrator 自己会调用一次 LLM,把这个高层目标解析成结构化 JSON。
如果解析失败,函数就直接 return,从而避免后面整条链路因为脏数据而崩掉。
这个 try...except 块实际上就是一个回退机制 :
如果 LLM 返回的 JSON 无法解析或字段缺失,Orchestrator 会优雅终止 ,而不是把错误数据继续往下传。在生产环境中,你还可以用更严格的结构化提示或者模式校验(schema validation)来强化这一步,但对当前原型来说,这种轻量做法已经兼顾了韧性 和可读性。
智能体协调(Agent coordination)
一旦目标被拆解完成,Orchestrator 就开始协调各个智能体之间的信息流:
- 把 intent_query 发给 Librarian(上下文馆员),用于检索语义蓝图;
- 把 topic_query 发给 Researcher(研究员),用于检索事实信息;
- 然后把两者结果一起交给 Writer(写作者)。
1. 向 Librarian 请求上下文蓝图(Procedural RAG)
ini
# Step 1: Get the Context Blueprint (Procedural RAG)
mcp_to_librarian = create_mcp_message(
sender="Orchestrator",
content={"intent_query": intent_query}
)
# display_mcp(mcp_to_librarian, "Orchestrator -> Librarian")
mcp_from_librarian = agent_context_librarian(mcp_to_librarian)
display_mcp(mcp_from_librarian, "Librarian -> Orchestrator")
context_blueprint = mcp_from_librarian['content'].get('blueprint')
if not context_blueprint: return这里 Orchestrator 通过 MCP 消息,把 intent_query 发送给 Librarian;
返回后,从消息内容里拿到 blueprint(蓝图)。如果没拿到,就直接返回。
2. 向 Researcher 请求事实知识(Factual RAG)
ini
# Step 2: Get the Factual Knowledge (Factual RAG)
mcp_to_researcher = create_mcp_message(
sender="Orchestrator",
content={"topic_query": topic_query}
)
# display_mcp(mcp_to_researcher, "Orchestrator -> Researcher")
mcp_from_researcher = agent_researcher(mcp_to_researcher)
display_mcp(mcp_from_researcher, "Researcher -> Orchestrator")
research_findings = mcp_from_researcher['content'].get('facts')
if not research_findings: return这一步 Orchestrator 让 Researcher 从知识库中检索与 topic_query 相关的事实,并综合成一个简明摘要 facts。如果没有结果,同样直接退出。
3. 交给 Writer 生成最终内容
ini
# Step 3: Generate the Final Output
# Combine the outputs for the Writer Agent
writer_task = {
"blueprint": context_blueprint,
"facts": research_findings
}
mcp_to_writer = create_mcp_message(
sender="Orchestrator",
content=writer_task
)
# display_mcp(mcp_to_writer, "Orchestrator -> Writer")
mcp_from_writer = agent_writer(mcp_to_writer)
display_mcp(mcp_from_writer, "Writer -> Orchestrator")
final_result = mcp_from_writer['content'].get('output')
print("\n=== [Orchestrator] Task Complete ===")
return final_result这一模式让各自的职责极其清晰:
- Librarian 只负责取"怎么写"的过程指导(程序性上下文);
- Researcher 只负责取"写什么"的事实内容;
- Writer 把"怎么写"和"写什么"组合起来,生成最终文本。
同时,这个架构之所以稳健,是因为它既模块化 又可扩展:
- 每个智能体只做一件事(Single Responsibility);
- 系统严格按照你提供的过程性指令(语义蓝图)来执行;
- Orchestrator 像一个优秀的项目经理:只管拆任务和派任务,而不参与具体实现,把细节交给各个专家智能体。
真正的杀手锏在于------把 "what(内容)" 和 "how(表现形式)" 彻底分离:
- 事实检索(知识库)与风格/过程指令(上下文库)完全独立;
- 这样你可以只更新知识库,而不用动任何风格规则;
- 或者只新增/调整蓝图,而不用动事实数据。
这让迭代速度非常快,也让系统变得极灵活:
只要更换语义蓝图,就能在同一批事实的基础上,瞬间换一种风格、结构或语气来生成内容。
最终,这不仅仅是一个"教学示例",而是一套可落地的工程蓝图,用于构建真正能处理复杂、上下文敏感任务的多智能体系统(MAS)。
小结(Summary)
本章我们从第 2 章的 MAS 继续演化,核心升级是引入了双重 RAG 架构(dual RAG) 。
-
在同一个 Pinecone 索引中,我们创建了两个完全独立的数据库:
- Knowledge Base(知识库) :为 Researcher 智能体存储事实信息;
- Context Library(上下文库) :为新引入的 Context Librarian 智能体存储过程性语义蓝图。
这种分离让系统可以独立管理"知道什么"和"如何行动" 。
实现上分为两大部分:
-
数据准备阶段(第一个 notebook)
- 预处理并上传数据到两个 Pinecone 命名空间;
- 一个用于知识向量(知识库),一个用于蓝图向量(上下文库)。
-
运行时执行阶段(第二个 notebook)
-
定义多智能体工作流:
- Orchestrator 分析用户目标;
- 把"事实查询"交给 Researcher;
- 把"风格/结构检索"交给 Librarian;
- Writer 同时接收事实和语义蓝图,按蓝图约束来生成最终输出。
-
现在,这个系统已经可以动态控制生成过程 :
既保证内容来自检索到的事实,又保证表达形式严格遵从语义蓝图。
接下来,我们将基于本章构建的能力,设计一个真正意义上的上下文引擎(context engine) ,把这一 MAS 提升到新的层级。