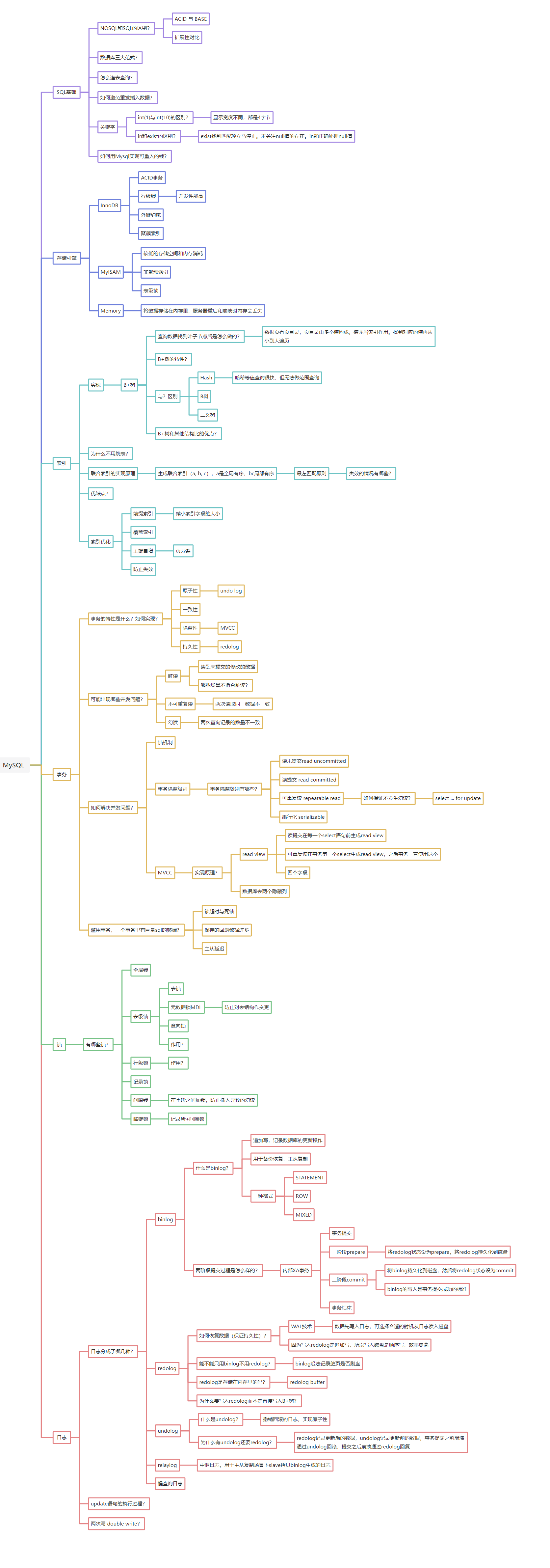
SQL 基础
- NOSQL 和 SQL 的区别 :从
ACID与BASE(SQL 侧重强一致性,NOSQL 侧重最终一致性)、扩展性对比(NOSQL 通常更易横向扩展)两个维度对比。 - 数据库三大范式:(需结合数据库设计知识,核心是减少冗余、保证数据完整性)。
- 连表查询:(如内连接、外连接等,用于多表关联取数)。
- 避免重复插入数据 :(可通过唯一索引、
INSERT IGNORE、ON DUPLICATE KEY UPDATE等方式实现)。 - 关键字 :
int(1)与int(10)的区别:显示宽度不同,但存储都是 4 字节(仅影响显示,不影响数值范围)。in和exist的区别:exist找到匹配项立即停止,且能正确处理null值;in不关注null逻辑,需全量匹配。
- MySQL 实现可重入的锁:(需结合锁机制,通过锁的粒度和逻辑设计实现可重入)。
存储引擎
- InnoDB :支持
ACID事务、行级锁(并发性能高)、外键约束、聚簇索引(数据和索引存储在一起)。 - MyISAM :特点是
较低的存储空间和内存消耗、非聚簇索引、支持表锁(并发性能弱于 InnoDB)。 - Memory:将数据存储在内存里,服务重启和崩溃时内存会丢失(适合临时、高频访问的小数据场景)。
索引
- 实现(B + 树) :
- 「查询数据找到叶子节点逻辑」:数据页有页目录,页目录由多个槽构成,槽充当索引,找到对应槽后从小到大连历。
- 「B + 树特性」:(如叶子节点链表相连、非叶子节点只存索引等,适合范围查询)。
- 「与 Hash、B 树、二叉树的区别」:
Hash等值查询快但无法范围查询;B+树叶子节点有序且链表连接,是 MySQL 索引的默认结构。 - 「B + 树和其他结构的优点」:(如磁盘 IO 次数少、范围查询高效等)。
- 为什么不用跳表:(跳表虽然也支持高效查询,但 MySQL 选择 B + 树是基于磁盘存储、索引维护成本等综合考量)。
- 联合索引的实现原理 :生成联合索引(如
(a, b, c))时,a全局有序,b、c局部有序,遵循最左匹配原则;需关注索引失效的情况(如字段类型不匹配、中间字段断连等)。 - 索引优缺点:(优点是提升查询效率,缺点是占用空间、写入时维护索引耗时)。
- 索引优化 :
前缀索引:减少索引字段的大小(适合长字符串字段)。覆盖索引:(查询字段都在索引中,无需回表,提升效率)。主键自增:避免页分裂(自增主键插入时索引结构更紧凑)。防止失效:(如避免函数操作索引字段、合理利用最左匹配等)。
事务
- 事务的特性(ACID)及实现 :
原子性:由undo log实现(回滚日志,用于事务回滚)。一致性:(由原子性、隔离性、持久性共同保障数据逻辑正确)。隔离性:由MVCC(多版本并发控制)实现。持久性:由redolog(重做日志,保证事务提交后数据不丢失)实现。
- 并发问题 :
脏读:读到未提交的修改数据;某些场景(如实时性要求极高的业务)不适合避免脏读。不可重复读:两次读取同一数据不一致。幻读:两次查询记录的数量不一致。
- 解决并发问题的机制 :
锁机制:(通过锁控制数据访问权限)。事务隔离级别:包含读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read,MySQL默认级别)、串行化(serializable);其中可重复读下防止幻读可通过select ... for update加锁实现。MVCC实现原理:基于read view(读视图)和数据库表两个隐藏列(如事务 ID、回滚指针);读提交在每个select前生成read view,可重复读在事务第一个select生成read view并复用。
- 事务适用场景的问题 :一个事务里有大量 SQL 时,可能导致
锁超时与死锁、保存的回滚数据过多、主从延迟(若涉及主从复制)。
锁
- 锁的类型 :
全局锁:(锁定整个数据库,一般用于备份)。表级锁:包含表锁、元数据锁(MDL,防止对表结构变更)、意向锁等,需理解各类锁的作用(如表锁控制整张表的读写权限)。行级锁:(锁定单行数据,并发粒度细,InnoDB 支持),需理解其作用(提升并发写入效率)。记录锁:(锁定单行记录)。间隙锁:在字段之间加锁,防止插入导致的幻读。临键锁:记录锁+间隙锁(InnoDB 默认的行锁算法,兼顾记录和区间锁定)。
日志
- binlog(二进制日志) :
- 定义:
追加写,记录数据库的更新操作,用于备份恢复、主从复制。 - 格式:包含
STATEMENT(记录 SQL 语句)、ROW(记录行变更)、MIXED(混合模式)。 - 两阶段提交过程:内部 XA 事务分为
一阶段prepare(将redolog设为 prepare 并持久化)、二阶段commit(将binlog持久化,再将redolog设为 commit;binlog写入是事务提交成功的标准)。
- 定义:
- redolog(重做日志) :
- 恢复数据(保证持久性):基于
WAL技术(先写日志再写磁盘),数据先写入日志,再择机从日志读入磁盘;redolog是追加写,写入磁盘是顺序 IO,效率更高。 - 不能只用
binlog不用redolog:因为binlog没法记录脏页是否刷盘(redolog是磁盘持久化的直接保障)。 - 存储:
redolog buffer(内存缓冲区,再刷入磁盘)。 - 写入原因:直接写 B + 树会导致随机 IO,而
redolog顺序写效率更高。
- 恢复数据(保证持久性):基于
- undolog(回滚日志) :
- 定义:撤销回滚的日志,实现
原子性。 - 与
redolog的关系:redolog记录更新后的数据,undolog记录更新前的数据;事务提交前崩溃通过undolog回滚,提交后崩溃通过redolog恢复。
- 定义:撤销回滚的日志,实现
- 其他日志 :
relaylog(中继日志,主从复制场景下 slave 端用于同步 binlog)、慢查询日志(记录执行慢的 SQL)。 - update 语句执行过程:(需结合存储引擎、日志、索引等流程,如解析 SQL、加锁、更新内存 / 磁盘、写日志等)。
- 两次写(double write):(InnoDB 用于防止部分写失效,保证数据页的完整性)。