在现代高并发的分布式系统中,缓存是提高性能的关键技术之一。对于一个具有高访问量、频繁查询数据库的应用程序,缓存可以有效减轻数据库的压力,降低响应延迟。本文将深入探讨 多级缓存 的概念、实现与优化策略,基于 Spring Boot 和 Redis ,实现本地缓存与分布式缓存的结合,解决 缓存一致性问题 、缓存回填 和 负载均衡优化。
目录
- 引言:为什么需要缓存?
- [缓存类型:本地缓存 vs 分布式缓存](#缓存类型:本地缓存 vs 分布式缓存)
- 多级缓存概述
- [实现多级缓存:Spring Boot + Caffeine + Redis](#实现多级缓存:Spring Boot + Caffeine + Redis)
- 缓存常见问题与解决方案
- 多级缓存优化策略
- [实践项目:Spring Boot 多级缓存实现](#实践项目:Spring Boot 多级缓存实现)
- 总结
1. 引言:为什么需要缓存?
在高并发、低延迟的应用中,缓存扮演着至关重要的角色。缓存的作用是将常用数据存储在内存中,减少对数据库或其他远程服务的访问,从而提高数据读取的速度。缓存系统不仅能提高响应速度,还能降低数据库的负载,尤其在面对大量并发请求时,缓存能够有效缓解系统的瓶颈。
然而,随着系统的扩展,单一的缓存模式已无法满足高并发的需求,因此 多级缓存 系统应运而生,它结合了 本地缓存 和 分布式缓存 的优势,能够提供更高的性能和可扩展性。
2. 缓存类型:本地缓存 vs 分布式缓存
2.1 本地缓存
本地缓存存储在应用进程的内存中,如 Java 中的 ConcurrentHashMap,常用的缓存库包括 Caffeine 和 Guava 。它的主要优势是 访问速度极快,因为数据直接存储在内存中。
优点:
- 极快的访问速度:无需网络延迟。
- 实现简单,适用于单机系统。
缺点:
- 数据只能在单机有效,无法共享。
- 内存受限,重启后缓存数据丢失。
2.2 分布式缓存
分布式缓存将数据存储在集中的缓存系统中,如 Redis 或 Memcached。它允许多个应用实例共享缓存数据,适用于高并发分布式系统。
优点:
- 数据一致性好,可以跨多个应用共享缓存。
- 扩展性强,支持大规模的数据存储。
缺点:
- 访问速度受到网络延迟的影响。
- 需要额外的运维和配置,尤其是 Redis 集群模式。
3. 多级缓存概述
多级缓存 是将 本地缓存 和 分布式缓存 结合使用的一种缓存策略。多级缓存的基本思想是,首先查询本地缓存,如果本地缓存未命中,再查询 Redis 等分布式缓存。如果 Redis 也未命中,则访问数据库,并将查询结果回填到本地缓存和 Redis 中。
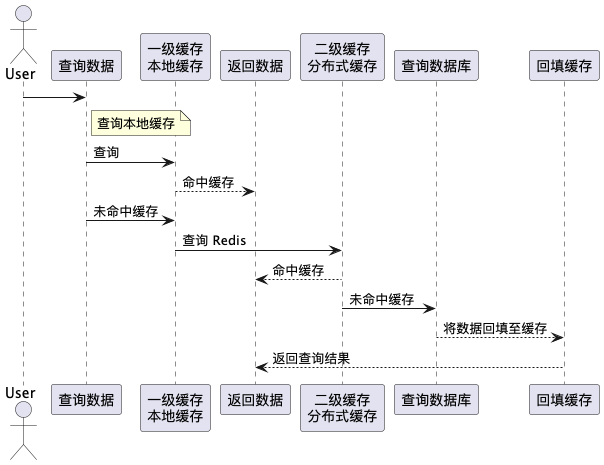
多级缓存的优点:
- 提高查询速度:本地缓存提供快速的数据访问,而 Redis 提供了更大规模的数据存储和跨实例共享。
- 减轻数据库压力:多级缓存减少了数据库的访问频率,避免数据库成为系统瓶颈。
4. 实现多级缓存:Spring Boot + Caffeine + Redis
4.1 配置 Caffeine 本地缓存
我们首先在 Spring Boot 项目中集成 Caffeine 本地缓存,并配置缓存的最大容量和过期时间。
xml
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.0.5</version>
</dependency>然后,在 application.properties 中配置缓存的默认设置:
properties
spring.cache.caffeine.spec=maximumSize=100,expireAfterWrite=60m接着,在 CacheConfig.java 中配置 Caffeine 缓存管理器:
java
package com.wilson.weatherquery.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CaffeineCacheManager caffeineCacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.maximumSize(100) // 最大缓存条目数
.expireAfterWrite(60, TimeUnit.MINUTES)); // 缓存过期时间
return cacheManager;
}
}4.2 配置 Redis 缓存
在 application.properties 中配置 Redis 连接:
properties
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=
spring.redis.jedis.pool.max-active=10
spring.redis.jedis.pool.max-idle=5
spring.redis.jedis.pool.min-idle=1
spring.redis.timeout=2000然后,在 RedisConfig.java 中配置 RedisTemplate,用于操作 Redis 缓存:
java
package com.wilson.weatherquery.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
return template;
}
}5. 缓存常见问题与解决方案
5.1 缓存击穿
缓存击穿 是指缓存中某个热点数据失效后,多个请求同时查询该数据,导致大量请求直接访问数据库,造成数据库压力急剧增加。
解决方案: 分布式锁
使用 分布式锁 来确保只有一个请求能去查询数据库,其他请求可以等待。
5.2 缓存雪崩
缓存雪崩 是指缓存中大量的数据同时失效,导致大量请求同时访问数据库,造成数据库瞬时压力增大。
解决方案: 加随机过期时间
通过给缓存设置 随机过期时间,避免大量数据同时过期,减轻数据库压力。
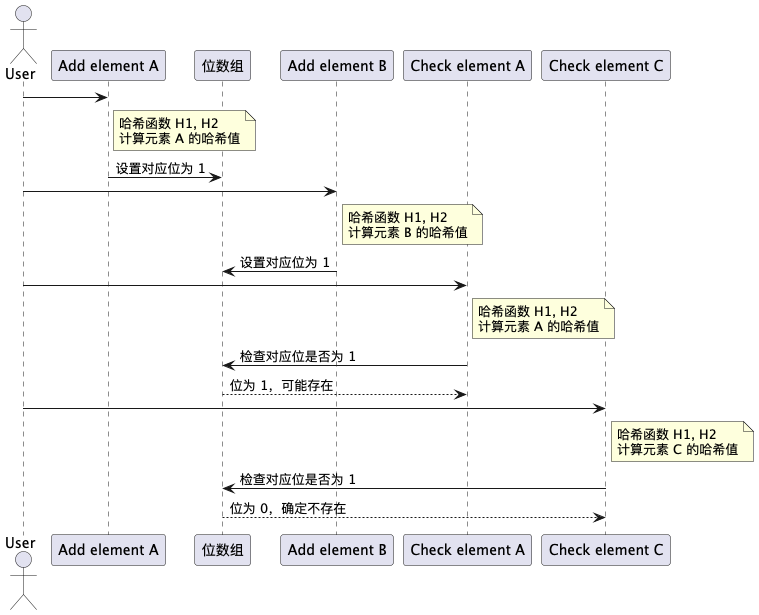
5.3 缓存穿透
缓存穿透 是指请求的数据既不在缓存中,也不在数据库中,导致缓存直接穿透查询数据库,给数据库带来不必要的压力。
解决方案: 布隆过滤器
使用 布隆过滤器 来过滤掉不存在的数据,避免无效请求穿透缓存。
6. 多级缓存优化策略
6.1 缓存一致性
使用 分布式锁 和 消息队列 来确保不同层级的缓存保持一致。
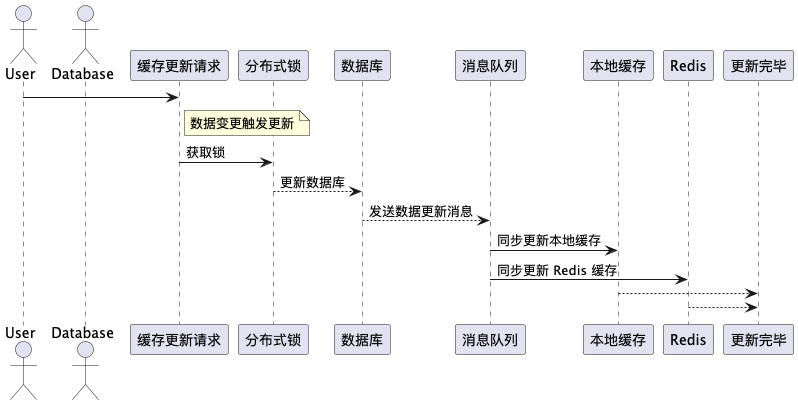
6.2 缓存回填
通过 异步回填 和 缓存预热,优化缓存的回填过程,减少响应延迟。
6.3 数据分级存储
根据数据的访问频率,选择合适的缓存层级。例如,热点数据优先放入本地缓存,冷数据放入 Redis。
6.4 负载均衡优化
通过 Redis 集群模式 和 高可用配置,确保 Redis 的负载均衡和高可用性。
7. 实践项目:Spring Boot 多级缓存实现
在项目中,我们结合 Caffeine 本地缓存和 Redis 分布式缓存,实施了多级缓存策略。通过合理的缓存过期策略、缓存一致性处理和优化方案,显著提升了系统的响应速度和稳定性。
bash
# 克隆项目代码
git clone https://github.com/Wilsoncyf/weather-query.git可以访问我们的 GitHub 仓库,查看完整的实现和代码:weather-query GitHub
8. 总结
本文深入探讨了 多级缓存 的实现与优化,结合 Spring Boot 和 Redis 实现了本地缓存与分布式缓存的结合。通过缓存一致性、缓存回填和数据分级存储的优化,我们能够有效提升系统的性能和可扩展性。在实践中,合理设计缓存策略和优化方案对于确保高并发环境下系统的稳定性至关重要。
希望本文对你有所帮助!如果你有任何问题或改进意见,欢迎在 GitHub 或 CSDN 上留言,我们将共同讨论和完善。