本文是基于自己项目进行的一次实践,欢迎大佬们提一下建议进行完善~~
一、整体技术栈全景
| 技术类别 | 具体技术/组件 | 在本系统中的角色 |
|---|---|---|
| 编程语言 | Java 25 | 提供虚拟线程、结构化并发等新特性 |
| 并发控制 | java.util.concurrent(JUC) • AtomicLong • ReentrantLock • AtomicBoolean |
实现线程安全的 ID 分配与段切换 |
| 异步执行 | 虚拟线程(Thread.ofVirtual().start()) |
轻量级异步预加载下一段 ID,避免阻塞主线程 |
| 分布式协调 | Redis + StringRedisTemplate |
全局分配连续 ID 段,保证跨节点唯一性 |
| Spring 集成 | Spring Boot + @Component / @Bean |
管理组件生命周期,依赖注入 |
| ID 编码设计 | 位运算(<<, ` |
`) |
- 拥抱 Project Loom:用虚拟线程简化异步编程,告别回调地狱;
- JUC 精准使用:无锁(Atomic)与有锁(Lock)结合,性能与正确性兼顾;
- Redis 用作协调器而非存储:只存序列号,不存完整 ID,高效且可靠;
- 工程化思维:通过 Spring 实现配置化、可插拔、易测试。
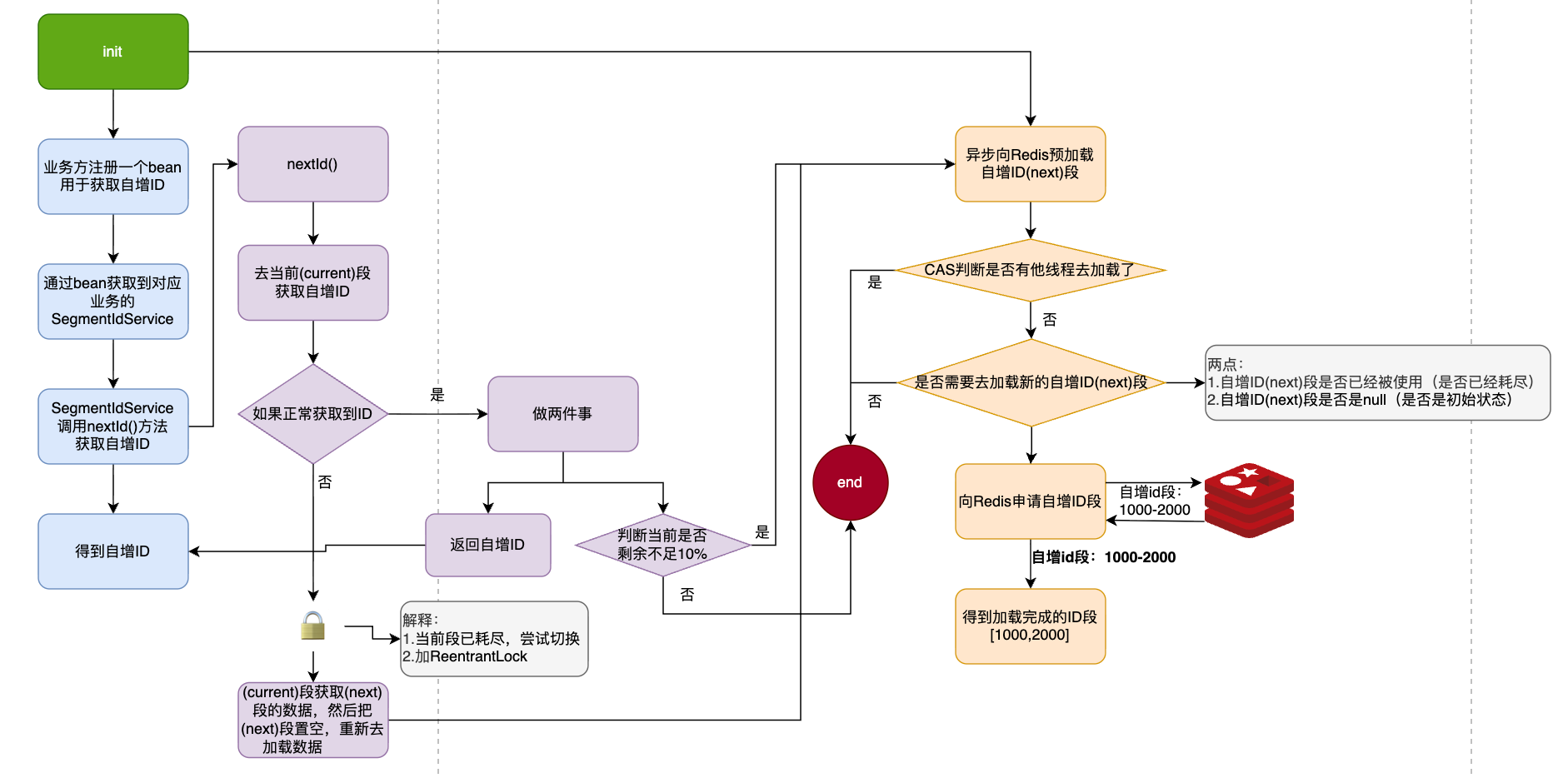
二、高性能分布式 ID 生成器实现
v2:
v2版本是本文的重点,基于v1版本进行的强化。
IdSegment:
java
import java.util.concurrent.atomic.AtomicLong;
/**
* 单个 ID 段(Segment)对象
* --------------------------
* 一个 Segment 代表一段连续的 ID 范围,例如 [1000, 1999]。
* Segment 内部使用 AtomicLong 进行线程安全的自增,保证高并发环境下正确分配。
* --------------------------
* 一个 Segment 的生命周期:
* 1. 被创建时即包含 start~end
* 2. 每次 getAndIncrement() 会返回一个 ID,并将游标递增
* 3. 当游标超过 end 时,是 耗尽
*/
public class IdSegment {
private final long start; // segment 范围:起始 ID(包含)
private final long end; // segment 范围:结束 ID(包含)
private final AtomicLong cursor; // 原子递增指针,指向"下一个要返回的 ID"
/**
* 构造函数
*
* @param start 当前 Segment 的开始 ID(包含)
* @param end 当前 Segment 的结束 ID(包含)
*/
public IdSegment(long start, long end) {
this.start = start;
this.end = end;
// cursor 初始指向 start
this.cursor = new AtomicLong(start);
}
/**
* 获取一个自增 ID。
* 若仍在范围内 [start, end],返回该值并自增。
* 若超出范围,返回 -1 表示耗尽。
*
* @return 下一个 ID;若已耗尽则返回 -1
*/
public long getAndIncrement() {
long v = cursor.getAndIncrement();
return v <= end ? v : -1L;
}
/**
* 获取当前剩余可分配数量
*
* @return 剩余 ID 数量,如果已耗尽返回 0
*/
public long remaining() {
long c = cursor.get();
// end - c + 1 表示还剩多少个(包含逻辑)
return Math.max(0, end - c + 1);
}
/**
* 表示 Segment 是否已经耗尽
*
* @return true:cursor 已经超过 end;false:还有剩余 ID
*/
public boolean isExhausted() {
return cursor.get() > end;
}
/**
* 调试信息
*/
public String toString() {
return "IdSegment[" + start + "," + end + "] cursor=" + cursor.get();
}
}RangeAllocator:
java
public interface RangeAllocator {
/**
* 分配一个闭区间 [start, end],size 为区间大小
* 返回 long[]{start, end}
*/
long[] allocateRange(String typeName, int size) throws Exception;
}RedisSegmentIdAllocator:
java
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.TimeUnit;
@Component
public class RedisSegmentIdAllocator implements RangeAllocator {
@Value("${quick.redis-worker.begin-timestamp:1719312960}")
private long beginTimestamp;
@Value("${quick.redis-worker.count-bits:32}")
private int countBits;
private final StringRedisTemplate stringRedisTemplate;
public RedisSegmentIdAllocator(StringRedisTemplate redis) {
this.stringRedisTemplate = redis;
}
@Override
public long[] allocateRange(String type, int size) throws Exception {
// 1. 时间戳(与 RedisIdWorker 一致)
long nowSecond = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - beginTimestamp;
if (timestamp < 0) {
throw new RuntimeException("Clock moved backwards!");
}
// 2. 日期维度的 key(与 RedisIdWorker 一致)
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
String redisKey = "icr:" + type + ":" + date;
// 3. 批量递增序列号(Redis 保证原子)
Long endSeq = stringRedisTemplate.opsForValue().increment(redisKey, size);
if (endSeq == null) {
throw new IllegalStateException("Redis INCRBY failed.");
}
// 序列号区间
long startSeq = endSeq - size + 1;
// 设置过期
stringRedisTemplate.expire(redisKey, 2, TimeUnit.DAYS);
// 4. 拼成最终 ID(高位:时间戳,低位:序列号)
long startId = (timestamp << countBits) | startSeq;
long endId = (timestamp << countBits) | endSeq;
return new long[]{startId, endId};
}
}SegmentIdService:
java
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.locks.ReentrantLock;
/**
* 分段(Segment)ID 生成服务
* ---------------------------------------
* 核心思想:
* 1. 每次从 Redis 分配一段连续 ID(例如 0~999)。
* 2. 本地在内存中自增,性能极高。
* 3. 当前段快耗尽时,异步加载下一段,平滑切换(双 buffer 模式)。
* NOTE:
* 每个业务 type 对应一个 SegmentIdService 实例,互不影响。
*/
public class SegmentIdService {
private final String type; // ID 类型,如 "log" / "sumit" / "test" Redis 会根据 type 区分不同的业务 ID 段。
private final RangeAllocator allocator; // 用于从 Redis 分配 ID 段的底层实现
private final int segmentSize; // 每个 segment 的大小,例如 1000 表示每次取 1000 个 id
private final int loadThreshold; // 当前段剩余数量小于该阈值时触发预加载下一段
private volatile IdSegment current; //当前正在使用的 ID 段
private volatile IdSegment next; // 预加载的下一段(异步填充)
private final ReentrantLock switchLock = new ReentrantLock(); // 切换 current/next 段的锁
private final AtomicBoolean loading = new AtomicBoolean(false); // 标记是否正在加载下一段(避免重复加载)
public SegmentIdService(String type, RangeAllocator allocator, int segmentSize) {
this.type = type;
this.allocator = allocator;
this.segmentSize = segmentSize;
// 预加载阈值为 10%(最小为 1)
this.loadThreshold = Math.max(1, segmentSize / 10);
init();
}
/**
* 初始化:
* 1. 加载 current 段
* 2. 异步预加载 next
*/
private void init() {
current = createNewSegment();
asyncLoadNext();
}
/**
* 向 Redis 请求一个新的 ID 段。
* 如果 Redis 挂了,则循环重试(阻塞等待恢复)。
*/
private IdSegment createNewSegment() {
while (true) {
try {
long[] r = allocator.allocateRange(type, segmentSize);
return new IdSegment(r[0], r[1]);
} catch (Exception e) {
// Redis 不可用则等待重试
try {
Thread.sleep(200);
} catch (InterruptedException ignored) {
// 若线程被中断,尝试退出循环
Thread.currentThread().interrupt();
break;
}
}
}
throw new IllegalStateException("Unable to allocate new segment");
}
/**
* 异步加载下一段(双 buffer 模式)
* - 使用虚拟线程,不会浪费 OS 线程
* - loading 确保只有一个线程执行加载
*/
private void asyncLoadNext() {
if (!loading.compareAndSet(false, true)) {
return; // 正在加载,不重复执行
}
Thread.ofVirtual().start(() -> {
try {
// 若 next 已存在且未耗尽,则无需重新加载
if (next != null && !next.isExhausted()) {
return;
}
// 加载新的 segment
next = createNewSegment();
} finally {
loading.set(false);
}
});
}
/**
* 获取下一个唯一 ID(高并发安全)
* 逻辑:
* 1. 从 current 段分配 ID
* 2. 触发下一段预加载
* 3. current 耗尽时与 next 平滑切换
*/
public long nextId() {
while (true) {
IdSegment seg = current;
long id = seg.getAndIncrement();
// 正常 ID
if (id > 0) {
// 剩余不足 10% 时预加载下一段
if (seg.remaining() <= loadThreshold) {
asyncLoadNext();
}
return id;
}
// -----------------------
// 当前段已耗尽,尝试切换
// -----------------------
switchLock.lock();
try {
// next 已准备好 → 切过去
if (current.isExhausted() && next != null) {
current = next;
next = null;
asyncLoadNext(); // 切换后继续预加载下一段
continue;
}
// next 尚未准备好 → 尝试启动 preload
if (next == null) {
asyncLoadNext();
}
} finally {
switchLock.unlock();
}
// 等待 next 被加载(避免自旋空转)
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IllegalStateException("Thread interrupted while allocating next ID", e);
}
}
}
}IdAllocatorConfig:
这个config把自增ID这个功能交给Spring进行管理,方便注入进行使用
java
import com.quick.utils.icrIdAllocator.v2.RedisSegmentIdAllocator;
import com.quick.utils.icrIdAllocator.v2.SegmentIdService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.core.StringRedisTemplate;
@Configuration
public class IdAllocatorConfig {
/**
* ID 段分配器:负责向 Redis 申请一段连续的 ID 区间
*
* 使用 @Primary 的原因:
* - 项目中如果有多个 IdAllocator 实现(例如 DBAllocator、RedisAllocator)
* - @Primary 可确保默认注入的是 RedisSegmentIdAllocator
*
* @param stringRedisTemplate Redis 客户端
*/
@Bean
@Primary
public RedisSegmentIdAllocator redisRangeAllocator(StringRedisTemplate stringRedisTemplate) {
return new RedisSegmentIdAllocator(stringRedisTemplate);
}
/**
* 基于 Segment(预分段)的 ID 生成服务
* --------------------------------------------------------------
* 说明:
* - type = "test_segment":同一个 type 会共享 Redis 中的全局自增序列
* - 每段大小 segmentSize = 3000 个 ID
* --------------------------------------------------------------
* 工作机制:
* 1. 启动时会从 Redis 获取一段连续 ID 作为 current segment
* 2. current 快耗尽时异步预加载 next segment,保证无阻塞切换
* 3. getId() 时只在本地 AtomicLong 自增,极高性能
* @param allocator Redis 段分配器
*/
@Bean
public SegmentIdService testSegmentIdService(RedisSegmentIdAllocator allocator) {
// 每段 3000 个 ID(可根据业务 QPS 调整)
return new SegmentIdService("test_segment", allocator, 3000);
}
}v1:
v1版本是之前基于雪花算法和redis自增做的一个简单的自增ID实现,其原理实际上就是基于 redis本身的指令操作的原子性达到自增ID这个目的。
RedisIdWorker:
java
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.TimeUnit;
/**
* 通过redis生成唯一id工具类
*/
@Component
public class RedisIdWorker {
/**
* 开始时间戳(配置化),用于计算ID的时间部分
*/
@Value("${quick.redis-worker.begin-timestamp:1719312960}")
private long beginTimestamp;
/**
* 序列号的位数(配置化),决定了每天生成的最大ID数量
*/
@Value("${quick.redis-worker.count-bits:32}")
private int countBits;
/**
* 序列号最大值,根据序列号位数计算得出
*/
private final long countMax = (1L << countBits) - 1;
// Redis操作模板类,用于与Redis交互
private final StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
/**
* 生成下一个全局唯一ID
*
* @param keyPrefix Redis键的前缀,用于区分不同的业务场景
* @return 返回生成的ID
*/
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - beginTimestamp;
// 检查时间戳是否有效
if (timestamp < 0) {
throw new RuntimeException(String.format("时钟回退。拒绝生成ID,当前时间戳为: %d", timestamp + beginTimestamp));
}
// 2. 生成序列号
// 2.1. 获取当前日期,精确到天
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
String redisKey = "icr:" + keyPrefix + ":" + date;
// 2.2. 自增长获取序列号
Long count = stringRedisTemplate.opsForValue().increment(redisKey);
if (count == null) {
count = 0L; // 如果 Redis 中没有这个键,初始化为 0
}
stringRedisTemplate.expire(redisKey,2, TimeUnit.DAYS);
// 3. 拼接时间戳和序列号,返回生成的ID
return (timestamp << countBits) | count;
}
}三、编写自测案例测试
java
import com.quick.result.Result;
import com.quick.utils.icrIdAllocator.v1.RedisIdWorker;
import com.quick.utils.icrIdAllocator.v2.SegmentIdService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.*;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/admin/test/icrId")
@RequiredArgsConstructor
@Tag(name = "管理端-自增ID生成测试接口")
public class TestIcrIdController {
private final SegmentIdService testSegmentIdService;
private final RedisIdWorker redisIdWorker;
private static final int SAMPLE_SIZE = 10;
@Operation(summary = "压测SegmentIdService")
@GetMapping("/benchmarkSegment")
public Result<IdBenchmarkResultVO> benchmarkSegment(
@RequestParam(defaultValue = "100000") int count) throws InterruptedException {
ExecutorService executor = Executors.newThreadPerTaskExecutor(Thread.ofVirtual().factory());
CountDownLatch latch = new CountDownLatch(count);
ConcurrentLinkedQueue<Long> idSamples = new ConcurrentLinkedQueue<>();
long start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
executor.submit(() -> {
try {
long id = testSegmentIdService.nextId();
// 随机采样少量 ID,避免内存膨胀
if (idSamples.size() < SAMPLE_SIZE * 5 && ThreadLocalRandom.current().nextInt(10) == 0) {
idSamples.add(id);
}
} finally {
latch.countDown();
}
});
}
latch.await();
executor.shutdown();
long end = System.currentTimeMillis();
// 最终取 SAMPLE_SIZE 个随机结果
List<Long> sample = idSamples.stream()
.limit(SAMPLE_SIZE)
.collect(Collectors.toList());
Collections.sort(sample);
return Result.success(
new IdBenchmarkResultVO(
"SegmentIdService 虚拟线程压测完成",
count,
end - start,
sample
)
);
}
@Operation(summary = "压测RedisIdWorker")
@GetMapping("/benchmarkRedisWorker")
public Result<IdBenchmarkResultVO> benchmarkRedisWorker(
@RequestParam(defaultValue = "100000") int count,
@RequestParam(defaultValue = "test_redis_worker") String keyPrefix) throws InterruptedException {
ExecutorService executor = Executors.newThreadPerTaskExecutor(Thread.ofVirtual().factory());
CountDownLatch latch = new CountDownLatch(count);
ConcurrentLinkedQueue<Long> idSamples = new ConcurrentLinkedQueue<>();
long start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
executor.submit(() -> {
try {
long id = redisIdWorker.nextId(keyPrefix);
if (idSamples.size() < SAMPLE_SIZE * 5 && ThreadLocalRandom.current().nextInt(10) == 0) {
idSamples.add(id);
}
} finally {
latch.countDown();
}
});
}
latch.await();
executor.shutdown();
long end = System.currentTimeMillis();
List<Long> sample = idSamples.stream()
.limit(SAMPLE_SIZE)
.collect(Collectors.toList());
Collections.sort(sample);
return Result.success(
new IdBenchmarkResultVO(
"RedisIdWorker 虚拟线程压测完成",
count,
end - start,
sample
)
);
}
@Data
@AllArgsConstructor
public class IdBenchmarkResultVO {
private String msg;
private long total;
private long costMs;
private List<Long> sampleIds;
}
}10万并发测试:
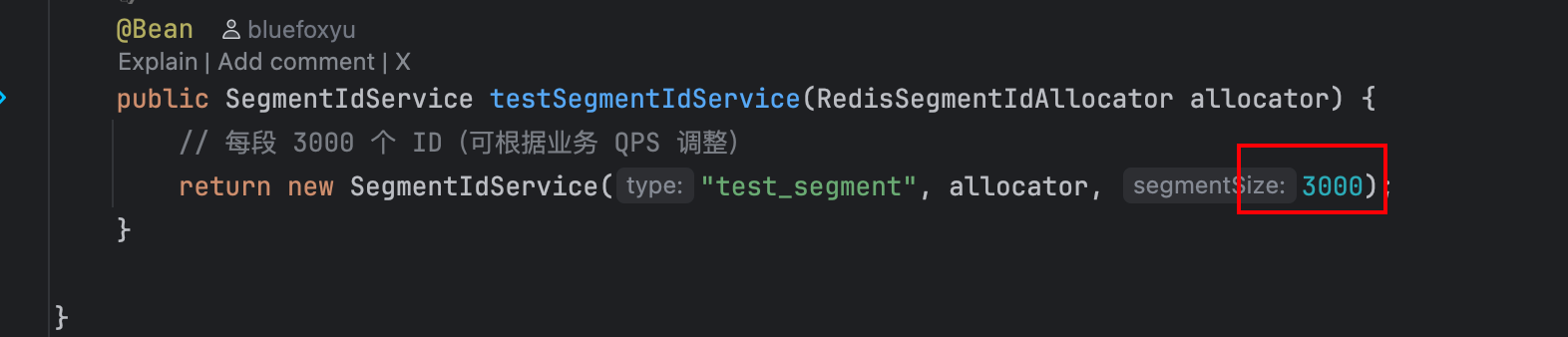
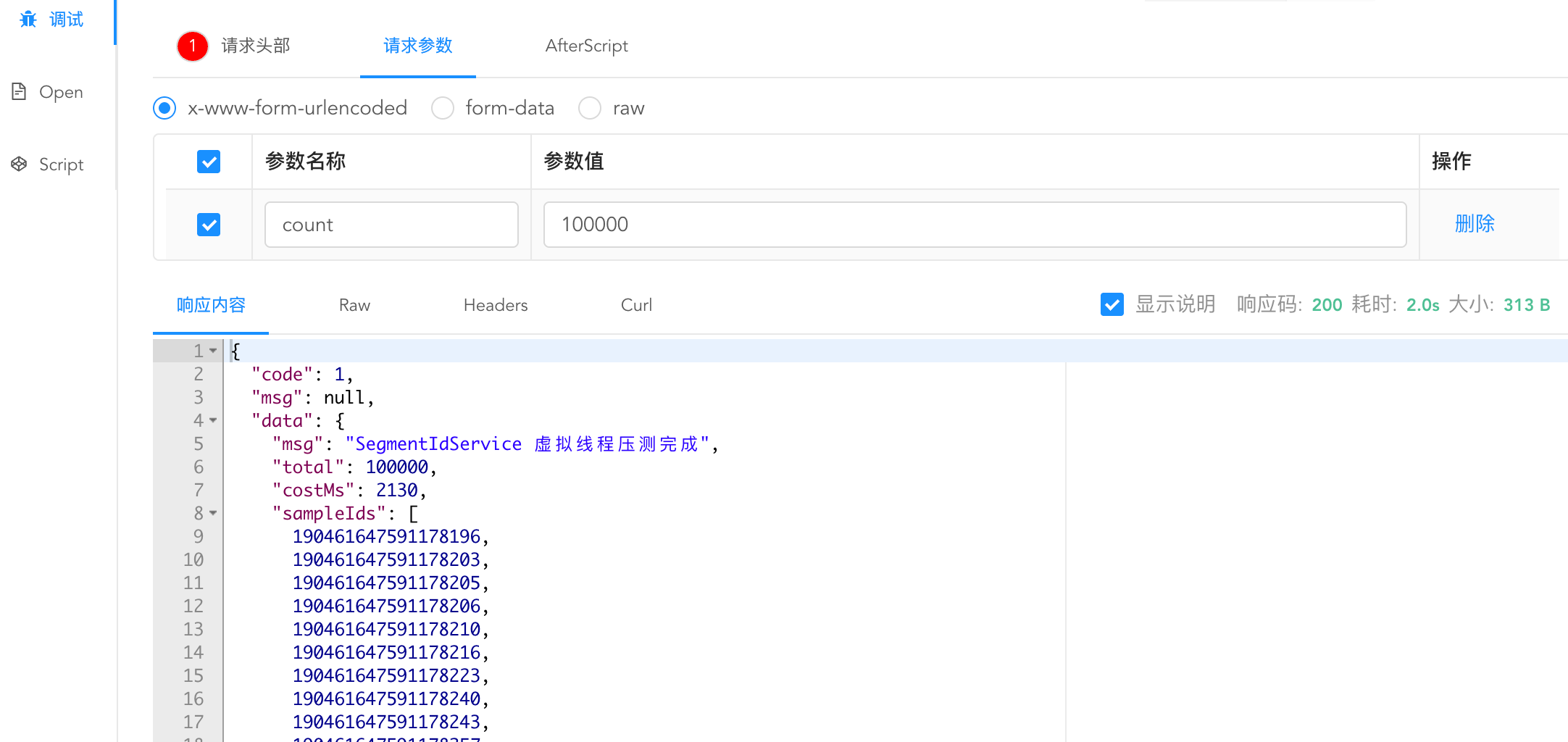
这里我们配置了segmentSize = 3000,由于10w并发超过了很多,也会多次去向redis申请自增ID段,自测也得花上2s左右,不过实际业务场景中,一般的业务不需要预留太多,3000足够了,如果有10w并发的场景,我们可以配置segmentSize = 10000
v2:
segmentSize = 3000:
segmentSize = 10000:
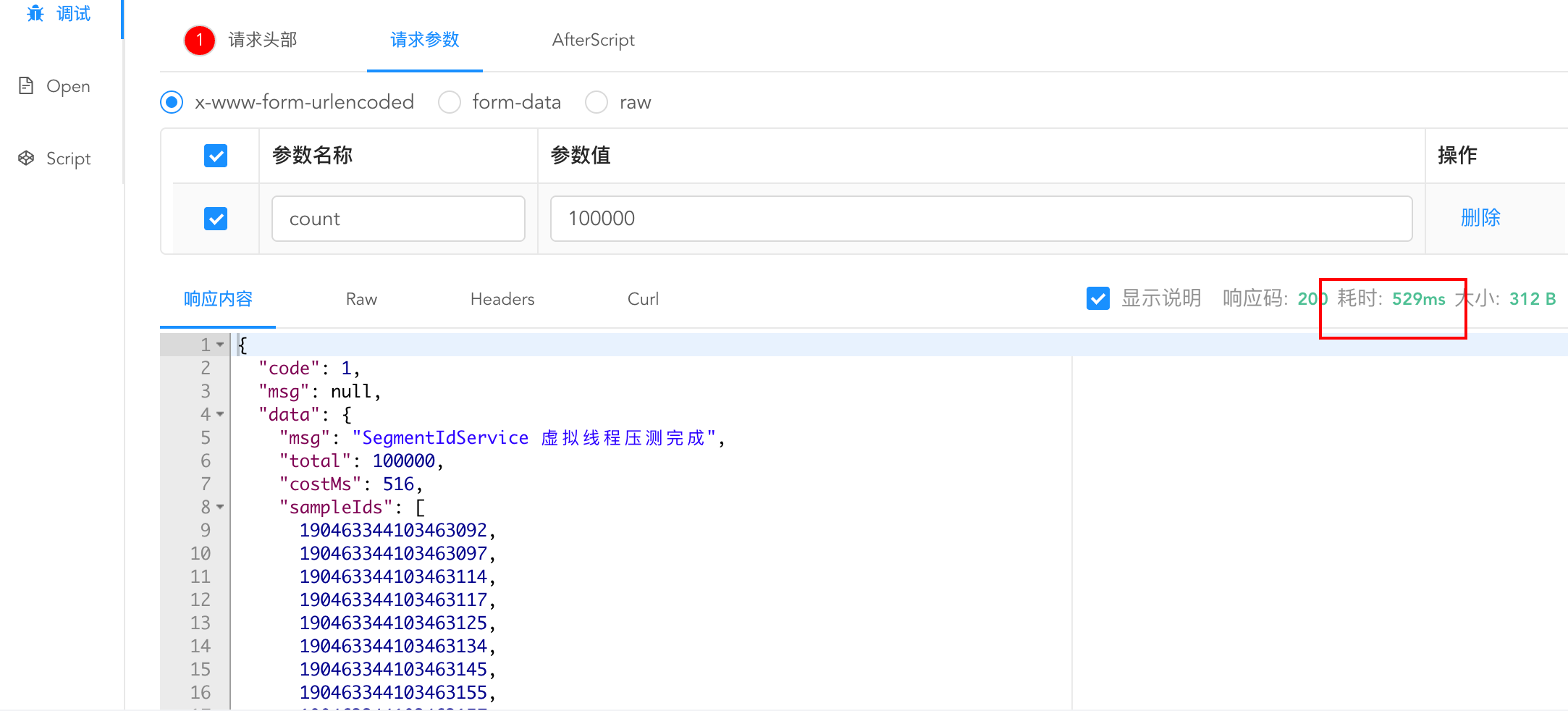
可见10w并发也能保证在500ms左右,这个性能是十分优秀的。a
v1:
10w并发下v1方案压测直接就导致redis连接池被打满。
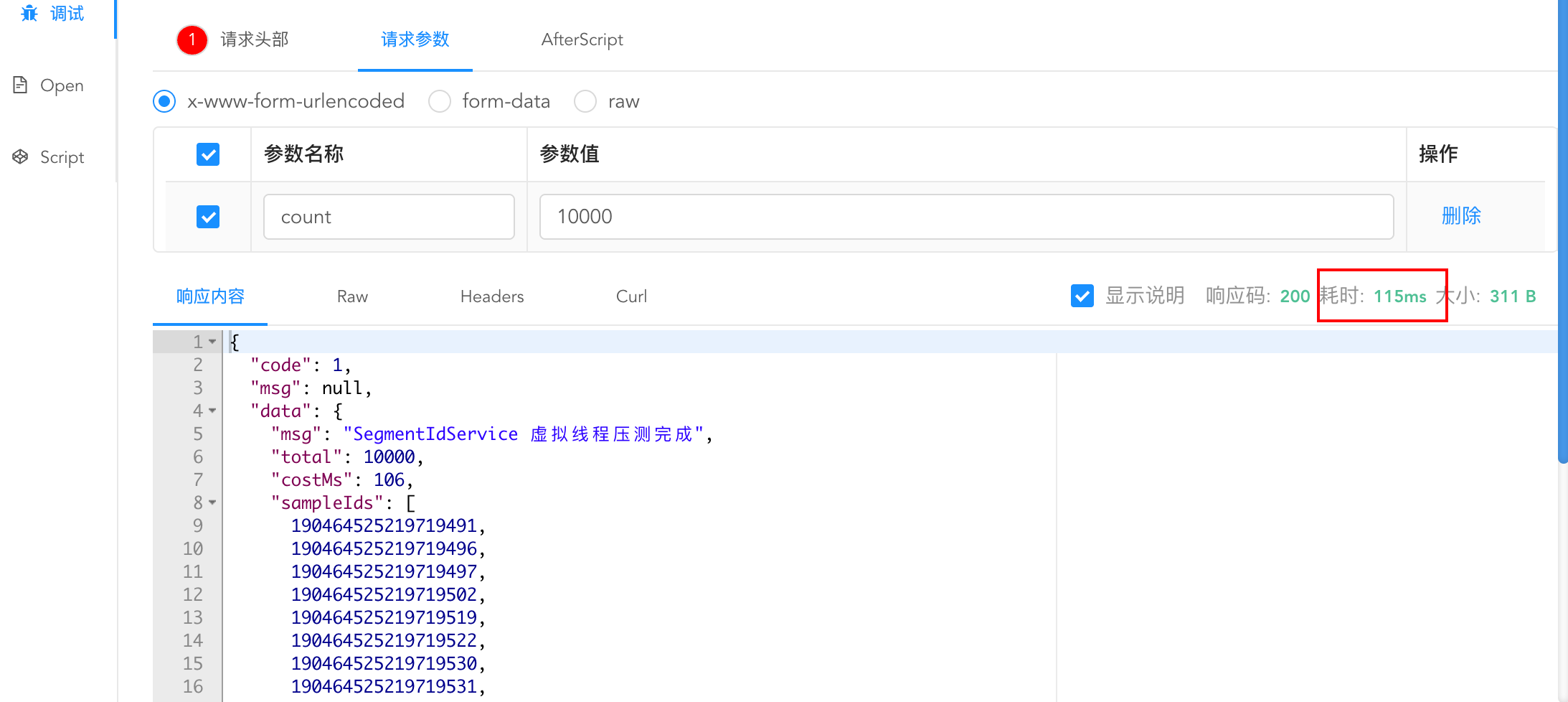
1万并发测试:
v2:
在配置segmentSize = 3000的情况下,耗时只有100ms左右:

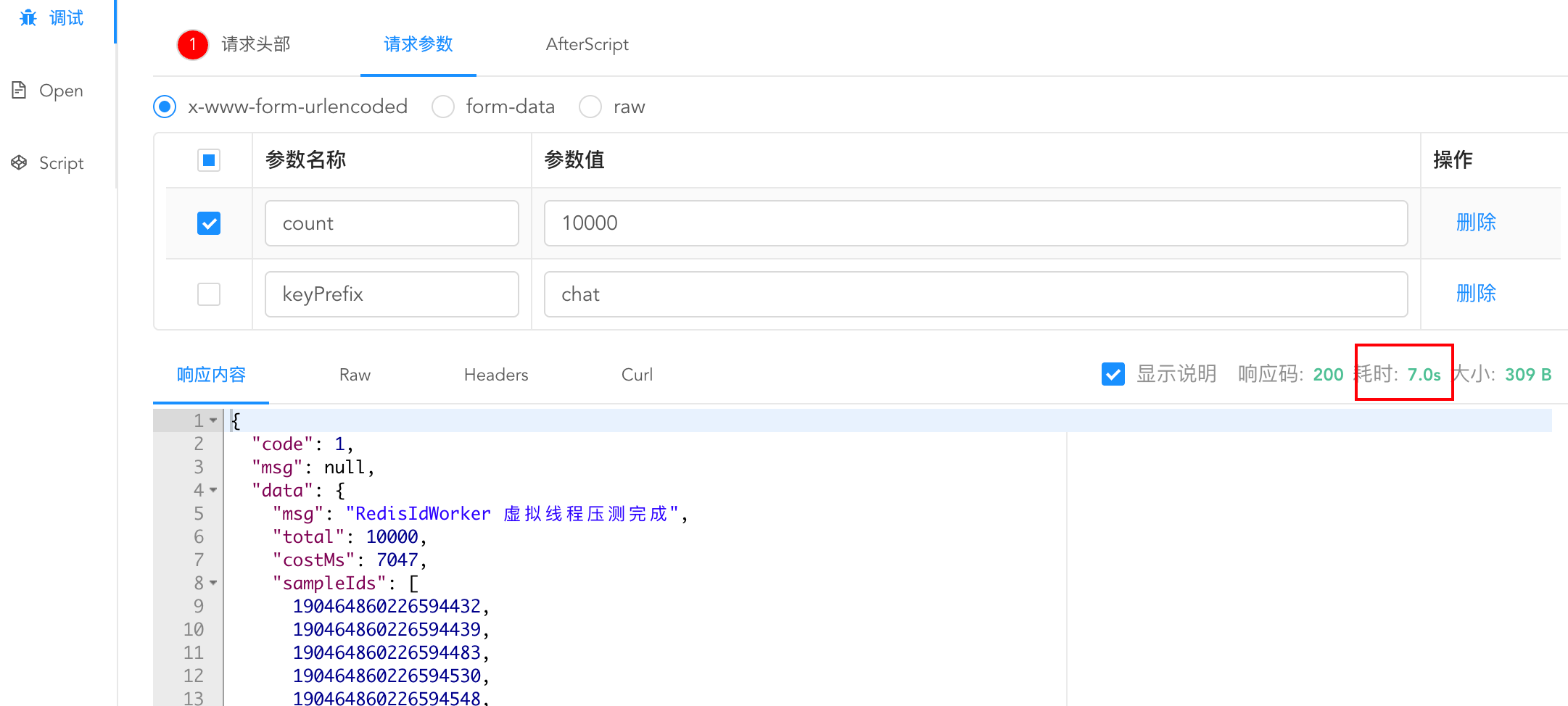
v1:
而v1版本却还要7s
总结:
| 维度 | v1(直连 Redis) | v2(Segment 预分配) |
|---|---|---|
| 架构定位 | Redis 是"生产者" | Redis 是"协调者" |
| 扩展性 | 无法横向扩展(Redis 单点瓶颈) | 可无限水平扩展(每个实例本地分配) |
| 容错性 | Redis 不可用 = 服务瘫痪 | Redis 短时不可用 = 继续分配已有段 |
| 资源消耗 | 高连接、高网络、高 Redis 负载 | 极低资源消耗 |
| 适用场景 | 仅适合 < 1000 QPS 的玩具项目 | 适合生产环境高并发系统 |
四、各技术栈的作用
1. Java 并发工具包(JUC)
✅ AtomicLong
- 用途 :在
IdSegment中作为游标(cursor),实现无锁自增。 - 优势 :
- 基于 CAS(Compare-And-Swap)硬件指令,无锁、高性能;
- 避免
synchronized带来的上下文切换开销; - 完美适配高并发场景下的 ID 自增需求。
java
private final AtomicLong cursor = new AtomicLong(start);
long v = cursor.getAndIncrement(); // 线程安全自增✅ ReentrantLock
- 用途 :在
SegmentIdService中保护current和next段的切换逻辑。 - 为什么不用 synchronized?
- 更灵活:支持公平锁、可中断、超时等;
- 明确临界区:只在"段耗尽需切换"时加锁,降低锁竞争频率。
java
switchLock.lock();
try {
if (current.isExhausted() && next != null) {
current = next;
next = null;
}
} finally {
switchLock.unlock();
}✅ AtomicBoolean
- 用途 :标记是否正在异步加载
next段,防止重复加载。 - 典型模式:"状态标志 + CAS" 实现轻量级互斥。
java
if (!loading.compareAndSet(false, true)) {
return; // 已有线程在加载,直接返回
}💡 这些 JUC 组件共同构建了一个 无锁为主、细粒度锁为辅 的高性能并发模型。
2. 虚拟线程(Virtual Threads)
📌 背景
- 传统线程(Platform Threads)由操作系统管理,创建成本高(MB 级栈内存,上下文切换慢);
- 高并发场景下,大量线程会导致资源耗尽("C10K 问题")。
✅ 在本系统中的应用
关于虚拟线程的学习可以移步到我这篇博客去简单了解一下使用:
java
Thread.ofVirtual().start(() -> {
next = createNewSegment();
loading.set(false);
});🌟 优势
| 对比项 | 传统线程 | 虚拟线程(Java 21+) |
|---|---|---|
| 创建成本 | 高(OS 级) | 极低(JVM 托管,KB 级) |
| 并发能力 | 几千级 | 百万级 |
| 阻塞影响 | 阻塞 OS 线程 | 仅挂起虚拟线程,底层载体线程可复用 |
| 适用场景 | CPU 密集型 | I/O 密集型(如网络请求、DB 查询) |
💡 为什么适合这里?
createNewSegment()本质是 Redis 网络调用(I/O 密集);- 使用虚拟线程后,即使同时有 100 个 ID 类型在预加载,也不会耗尽线程池;
- 代码保持同步风格 ,无需回调或 CompletableFuture,开发体验极佳。
⚠️ 注意:虚拟线程不是"更快",而是"更轻"。它让异步任务像写同步代码一样简单,同时具备高并发能力。
3. Redis ------ 分布式唯一性的保障
🔑 核心操作
java
Long endSeq = stringRedisTemplate.opsForValue().increment(redisKey, size);- 利用 Redis 的 INCRBY 原子性,确保多个服务实例分配的 ID 段不重叠;
- Key 设计:
icr:{type}:{yyyy:MM:dd},按业务类型 + 日期隔离,避免冲突; - 设置 2 天过期:防止历史数据无限增长。
🧠 ID 编码设计(雪花算法变种)
java
long startId = (timestamp << countBits) | startSeq;timestamp:相对时间戳(秒级),节省高位;startSeq:当日序列号(32 位),保证每秒最多 232 个 ID;- 最终 ID 全局唯一、大致有序、可解析。
✅ 对比标准 Snowflake:
- 不依赖机器 ID(避免配置管理);
- 序列号由 Redis 全局分配,彻底解决时钟回拨问题。
4. Spring Boot ------ 工程化集成
@Component+@Bean:自动注册RedisSegmentIdAllocator和SegmentIdService;@Primary:解决多实现注入冲突;StringRedisTemplate:Spring Data Redis 提供的字符串操作模板,线程安全。
5. 技术协同:如何形成合力?
| 场景 | 技术组合 | 效果 |
|---|---|---|
| 正常分配 ID | AtomicLong + 本地内存 |
纳秒级响应,零网络开销 |
| 预加载下一段 | 虚拟线程 + Redis INCRBY | 异步、轻量、不阻塞业务线程 |
| 段切换 | ReentrantLock + volatile |
线程安全切换,避免竞态条件 |
| 防重复加载 | AtomicBoolean + CAS |
保证只有一个加载任务运行 |
| 全局唯一 | Redis 原子递增 + 位拼接 | 跨 JVM、跨机器唯一 |
- 拥抱 Project Loom:用虚拟线程简化异步编程,告别回调地狱;
- JUC 精准使用:无锁(Atomic)与有锁(Lock)结合,性能与正确性兼顾;
- Redis 用作协调器而非存储:只存序列号,不存完整 ID,高效且可靠;
- 工程化思维:通过 Spring 实现配置化、可插拔、易测试。
五、核心优势分析
- 高性能:本地原子自增,避免每次请求 Redis
- 每次调用
nextId()本质是AtomicLong.getAndIncrement(),纯内存操作,纳秒级响应。 - 只有在段快耗尽时才异步预加载下一段,对主流程几乎无影响。
- 高可用:Redis 故障自动重试 + 虚拟线程轻量恢复
- 若 Redis 暂时不可用,
createNewSegment()会循环重试(带 sleep),不会导致服务崩溃。 - 使用 Java 21+ 的 虚拟线程(Virtual Thread) 异步加载,资源开销极小,适合大量 ID 类型并存。
- 平滑切换:双缓冲(Double Buffering)机制
current和next两个 Segment 实现无缝切换:- 当前段快用完 → 后台加载下一段;
- 耗尽时加锁切换,避免空转或重复加载;
- 切换后立即预加载再下一段,形成流水线。
- 全局唯一 & 时间有序
- ID 结构为:
[时间戳][序列号](高位时间戳,低位序列号)。- 全局唯一(依赖 Redis INCR 原子性);
- 大致按时间递增(便于数据库索引优化);
- 支持每秒生成 232 个 ID(由
countBits=32决定)。
- 灵活扩展:按业务类型隔离
- 每个
type(如 "order", "user")对应独立的 Redis key 和 Segment 服务,互不干扰。 - 通过 Spring Bean 配置即可新增类型,无需修改核心逻辑。
- 资源友好:自动过期 + 精确控制段大小
- Redis key 设置 2 天过期,防止历史数据堆积;
- 段大小(如 3000)可根据 QPS 调整:QPS 高 → 段更大,减少 Redis 请求频率。
| 维度 | 传统方案(如 DB 自增 / Snowflake) | 本 Segment 方案 | 业务价值 |
|---|---|---|---|
| 性能 | 中~低(依赖外部) | 极高(本地自增) | 支撑更高并发,用户体验更好 |
| 稳定性 | 弱(强依赖外部服务) | 强(具备缓冲与重试) | 减少故障,保障核心链路可用 |
| 成本 | 高(频繁访问 DB/Redis) | 低(批量预取) | 节省服务器与云资源开支 |
| 数据质量 | Snowflake 无序,DB 自增单点 | 全局唯一 + 时间有序 | 便于存储优化与问题排查 |
| 扩展性 | 差(Snowflake 机器位有限) | 极佳(type 隔离,无限扩展) | 快速支持多业务线并行发展 |