模拟
1. 模拟
模拟,顾名思义,就是题目让你做什么你就做什么,考察的是将思路转化成代码的代码能力。 这类题一般较为简单,属于竞赛里面的签到题(但是,万事无绝对,也有可能会出现让人非常难受的 模拟题),我们在学习语法阶段接触的题,大多数都属于模拟题。
题一 : 多项式输出

思路:
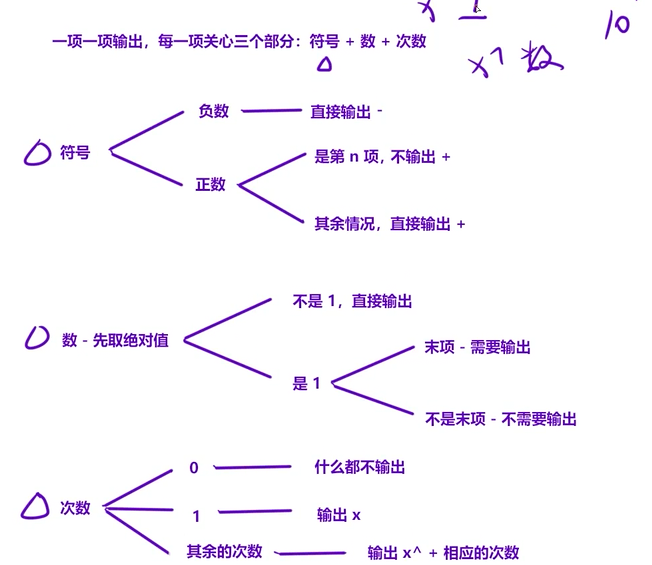
代码是逐项处理多项式的每一项,核心围绕"符号、数、次数"三个部分展开
- 遍历每一项(按次数从高到低)
- 通过 for (int i = n; i >= 0; i--) 遍历从最高次 n 到常数项 0 的所有项, i 就是当前项的次数, a 是当前项的系数。
- 处理"符号"(对应笔记的"符号"逻辑)
- 先跳过系数为 0 的项( if (a == 0) continue );
- 若系数为负:直接输出 - ;
- 若系数为正:
- 是最高次项( i == n ):不输出 + ;
- 不是最高次项:输出 + 。
- 处理"数"(对应笔记的"数-先取绝对值"逻辑)
先把系数取绝对值( a = abs(a) ),再分情况:
- 若系数≠1:直接输出系数;
- 若系数=1:
- 是常数项( i == 0 ):输出 1 ;
- 不是常数项:不输出。
- 处理"次数"(对应笔记的"次数"逻辑)
- 若次数=0(常数项):什么都不输出;
- 若次数=1:输出 x ;
- 若次数>1:输出 x^次数 。
代码:
cpp
#include<iostream>
#include<cmath>
using namespace std;
int main()
{
int n;
cin >> n;
for (int i = n;i >= 0;i--) //i == 5 4 3 2 1 0
{
int a;
cin >> a;
//符号
if (a == 0) continue;
if (a < 0)
cout << "-";
else
{
if (i!=n) cout << '+';
}
//数
a = abs(a);
if (a == 1)
{
if (i == 0) cout << a;
else ;
}
else cout << a;
//if (a != 1 || (a == 1 && i == 0))
// cout << a;
//次数
if (i == 0) continue;
else if (i == 1) cout << 'x';
else
cout << "x^" << i;
}
return 0;
}注意事项:
- 跳过系数为0的项:
题目要求"只包含系数不为0的项",所以必须用 if (a == 0) continue 跳过,否则会输出多余的项。
- 最高次项的符号:
最高次项系数为正时,开头不能有 + (比如样例1的 100x^5 开头没有 + ),代码中通过 if (i!=n) 控制了这一点。
- 系数为1的高次项:
比如 1x^3 要写成 x^3 ,代码中通过"系数=1且不是常数项时不输出"实现了这一点;但常数项 1 必须输出(比如样例2的末尾 +1 )。
- 次数的格式:
次数=1时输出 x (不是 x^1 ),次数>1时才输出 x^次数 ,别写混格式。
题目二 : 蛇形方阵
思路:
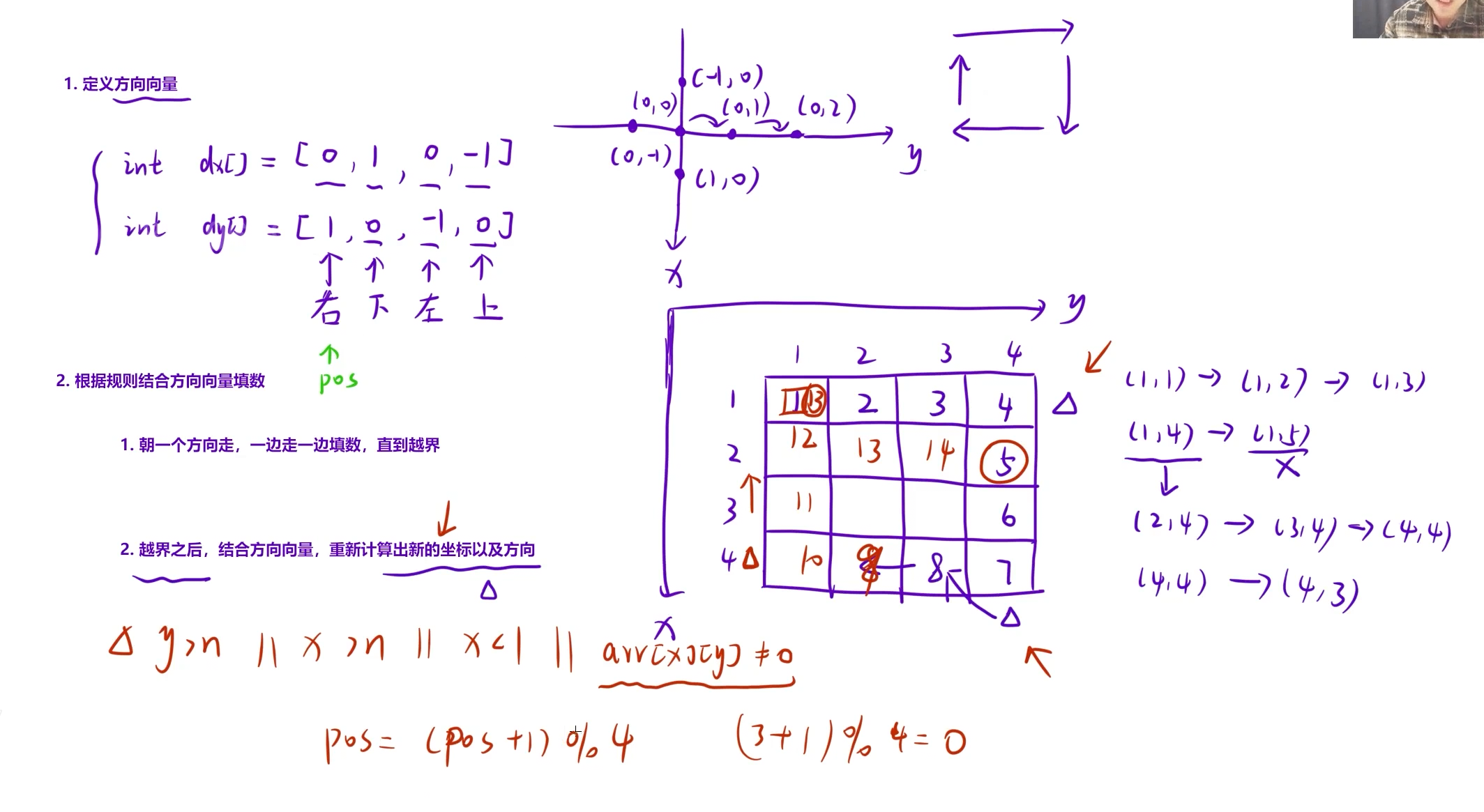
dx\[\] 和 dy\[\] :是方向向量数组,控制坐标的移动方向(对应"右、下、左、上"4个方向):
dxi :表示第 i 个方向下,行坐标(x)的变化量;
dyi :表示第 i 个方向下,列坐标(y)的变化量。
比如 dx0=0, dy0=1 对应"向右":行不变,列+1。
N :是矩阵的最大容量(设为15是因为题目中 n≤9 ,预留足够空间防止越界)。
arrNN :是存储蛇形矩阵的二维数组,初始值为0,填充完成后保存最终的矩阵数据。
n :是输入的正整数,表示要生成的蛇形矩阵的边长( n×n 矩阵)。
ret :是当前要填充的数字,初始值为1(从1开始填),每填充一个位置就自增1,直到 ret > n×n (填满所有位置)。
x, y :是当前填充位置的坐标(行号 x 、列号 y ),初始值为 (1,1) (矩阵的左上角)。
pos :是当前的移动方向索引,对应 dx\[\]/dy\[\] 的下标:
pos=0 → 右; pos=1 → 下; pos=2 → 左; pos=3 → 上。
初始值为0(从"右"方向开始),遇到边界时通过 pos=(pos+1)%4 切换方向。
a, b :是下一个位置的坐标(临时变量),由当前坐标 (x,y) 加上方向向量 (dxpos, dypos) 计算得到,用于判断下一个位置是否越界/已填充。
代码:
cpp
#include<iostream>
using namespace std;
//定义右下左上四个方向
int dx[] = { 0,1,0,-1 };
int dy[] = { 1,0,-1,0 };
const int N = 15;
int arr[N][N] = { 0 };
int main()
{
int n; cin >> n;
//模拟填数过程
int ret = 1; //当前位置要填的数
int x = 1, y = 1; //初始位置
int pos = 0; //当前方向
while (ret <= n * n)
{
arr[x][y] = ret;
//计算下一个位置
int a = x + dx[pos];
int b = y + dy[pos];
//判断是否越界
if (a <1 || a > n || b < 1 || b > n ||arr[a][b])
{
//更新出正确的该走的位置
pos = (pos + 1) % 4;
a = x + dx[pos], b = y + dy[pos];
}
x = a, y = b;
ret++;
}
//输出
for (int i = 1;i <= n;i++)
{
for (int j = 1;j <= n;j++)
{
printf("%3d", arr[i][j]);
}
printf("\n");
}
return 0;
}注意点:
1. 四个判断条件( a < 1 || a > n || b < 1 || b > n || arrab )
四个条件的核心作用:判断"下一个位置 (a,b) 是否能走",只要满足任意一个,就说明当前方向走不通,必须切换方向。
-
a < 1 :下一个位置的行号小于1(越上边界);
-
a > n :下一个位置的行号大于 n (越下边界);
-
b < 1 :下一个位置的列号小于1(越左边界);
-
b > n :下一个位置的列号大于 n (越右边界);
- arrab :下一个位置已经填过数字(因为初始为0,非0即已填充,可简化为 arrab ,等价于 arrab != 0 )。
- 顺序不影响结果:只要覆盖"越界"和"已填充"两种情况,四个边界条件的顺序可以随便换,但必须放在 arrab 前面(先判断是否在矩阵内,再判断是否已填充,逻辑更顺)。
2. pos 的取模( pos = (pos + 1) % 4 )
- 核心目的:实现"4个方向循环切换"(右→下→左→上→右...),避免方向索引超出 0-3 的范围。
- 因为方向只有4个( pos 取值0/1/2/3),当 pos=3 (上方向)再切换时, (3+1)%4=0 ,刚好回到 pos=0 (右方向),形成循环。
-
必须在"走不通"时切换:只有当下一个位置不合法(触发四个判断条件)时,才执行取模切换方向,不能随便切换------否则会乱改方向,导致填数顺序错误。
3. x、y 和 a、b 之间的关系 -
x、y 是"当前位置", a、b 是"候选下一个位置":
-
x、y 存储的是正在填数的位置(比如刚填完 ret 的坐标);
-
a、b 是通过 x + dxpos 、 y + dypos 计算出的"下一步想去的位置"(临时存储,用于判断)。
- 赋值逻辑:合法则替换,不合法则重算:
-
若 a、b 合法(不越界、未填充):就把 a、b 赋值给 x、y ( x=a; y=b ),让 x、y 移动到下一个位置;
-
若 a、b 不合法:不直接赋值,先切换 pos ,再重新计算 a、b (新方向的下一个位置),直到 a、b 合法,再赋值给 x、y 。
-
不能直接用 x、y 试错:如果不用 a、b ,直接修改 x、y 试方向,一旦不合法,还得把 x、y 回退( x -= dxpos; y -= dypos ),容易出错且逻辑绕。
-
最后的换行( printf("\n") )
-
核心作用:让矩阵按"行"显示,否则所有数字会挤在一行,和样例格式不一致。
- 外层循环 for (int i=1; i<=n; i++) 控制"行",每遍历完一行(内层循环结束),必须加一个换行,让下一行的数字从新的一行开始输出。
- 位置不能错:换行语句必须放在"内层循环结束后、外层循环结束前"------如果放在内层循环里,会每个数字换一行;如果漏写,所有数字连在一起,无法区分行。
3. 配合 printf("%3d") : %3d 保证每个数字占3个字符位,换行后每行的数字对齐,最终输出整齐的矩阵(和样例格式一致)。
题目三 : 字符串的展开

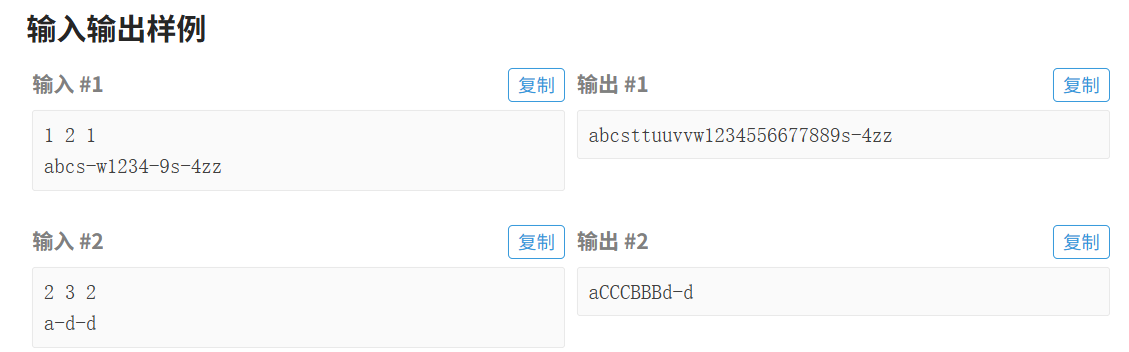
思路:
这段代码的核心思路是逐字符遍历输入字符串,识别需要展开的减号片段,按照题目给定的 p1/p2/p3 规则处理后,拼接成最终结果。以下是详细步骤:
一、准备工作:工具函数与全局变量
- 工具函数:
-
isdig(ch) :判断字符是否是数字( '0'~'9' );
-
islet(ch) :判断字符是否是小写字母( 'a'~'z' )。
- 全局变量:
-
p1/p2/p3 :存储题目要求的3个参数;
-
s :输入的原始字符串;
ret :存储最终展开后的结果字符串。
二、主函数:遍历字符串,识别可展开的减号
主函数的逻辑是逐个处理字符串的每个字符,核心是判断当前字符是否是"需要展开的减号":
- 遍历每个字符:
cpp
for (int i = 0;i < n;i++) {
char ch = s[i];- 跳过非减号/边界处的减号:
如果当前字符不是减号,或者减号在字符串开头/结尾(无法展开),直接将字符加入结果 ret :
cpp
if (s[i] != '-' || i == 0 || i == n - 1) ret += ch;- 判断减号是否满足展开条件:
若当前字符是减号,且不在边界,取出减号两侧的字符 left (左侧)、 right (右侧),判断是否满足"可展开"规则:
-
两侧同为数字 且 右侧>左侧;
-
或两侧同为小写字母 且 右侧>左侧。
满足则调用 add 函数处理中间字符,不满足则保留减号:
cpp
if (isdig(left) && isdig(right) && left < right
|| islet(left) && islet(right) && left < right) {
add(left, right); // 展开中间字符
} else {
ret += ch; // 保留减号
}三、 add 函数:按规则处理减号中间的字符
add 函数负责生成减号两侧字符之间的填充内容,并按照 p1/p2/p3 规则处理:
- 遍历中间字符:
从 left+1 到 right-1 ,逐个处理每个需要填充的字符:
cpp
for (char ch = left + 1;ch < right;ch++)- 处理 p1 :填充字符的类型:
-
若 p1=2 且当前字符是字母:将小写字母转为大写( tmp -= 32 ,因为 'a'-'A'=32 );
-
若 p1=3 :无论字母/数字,都替换为星号 * ;
-
若 p1=1 :保持原字符不变。
cpp
char tmp = ch;
if (p1 == 2 && islet(tmp)) tmp -= 32;
else if (p1 == 3) tmp = '*';- 处理 p2 :填充字符的重复次数:
将当前处理后的字符 tmp 重复 p2 次,加入临时字符串 t :
cpp
for (int i = 0;i < p2;i++) {
t += tmp;
}- 处理 p3 :填充内容的顺序:
若 p3=2 ,将临时字符串 t 逆序(改变填充顺序);最后将 t 加入结果 ret :
cpp
if (p3 == 2) reverse(t.begin(), t.end());
ret += t;四、输出结果
遍历完成后,输出最终拼接好的结果字符串 ret :
假设输入参数 p1=1, p2=1, p3=1 ,字符串包含 d-h :
-
主函数识别到 - ,两侧 left='d' 、 right='h' (同为字母且 h>d ),调用 add('d','h') ;
-
add 函数遍历 e/f/g :
-
p1=1 :保持 e/f/g ;
-
p2=1 :每个字符只加1次,临时串 t="efg" ;
-
p3=1 :不逆序;
- ret 拼接 t ,最终 d-h 展开为 defgh 。
代码:
cpp
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int p1, p2, p3, n;
string s;
string ret;
bool isdig(char ch)
{
return ch >= '0' && ch <= '9';
}
bool islet(char ch)
{
return ch >= 'a' && ch <= 'z';
}
void add(char left, char right)
{
string t;
//遍历中间的字符
for (char ch = left + 1;ch < right;ch++)
{
char tmp = ch;
//处理p1
if (p1 == 2 && islet(tmp)) tmp -= 32; //小写变大写
else if (p1 == 3) tmp = '*'; //变成*号
//处理p2
for (int i = 0;i < p2;i++)
{
t += tmp;
}
}
//处理p3
if (p3 == 2) reverse(t.begin(), t.end());
ret += t;
}
int main()
{
cin >> p1 >> p2 >> p3 >> s;
n = s.size();
for (int i = 0;i < n;i++)
{
char ch = s[i];
if (s[i] != '-' || i == 0 || i == n - 1) ret += ch;
else
{
char left = s[i - 1], right = s[i + 1];
//判断是否展开
if (isdig(left) && isdig(right) && left < right
|| islet(left) && islet(right) && left < right)
{
//展开
add(left, right);
}
else
{
ret += ch;
}
}
}
cout << ret << endl;
return 0;
}高精度

题一 : A+B Problem
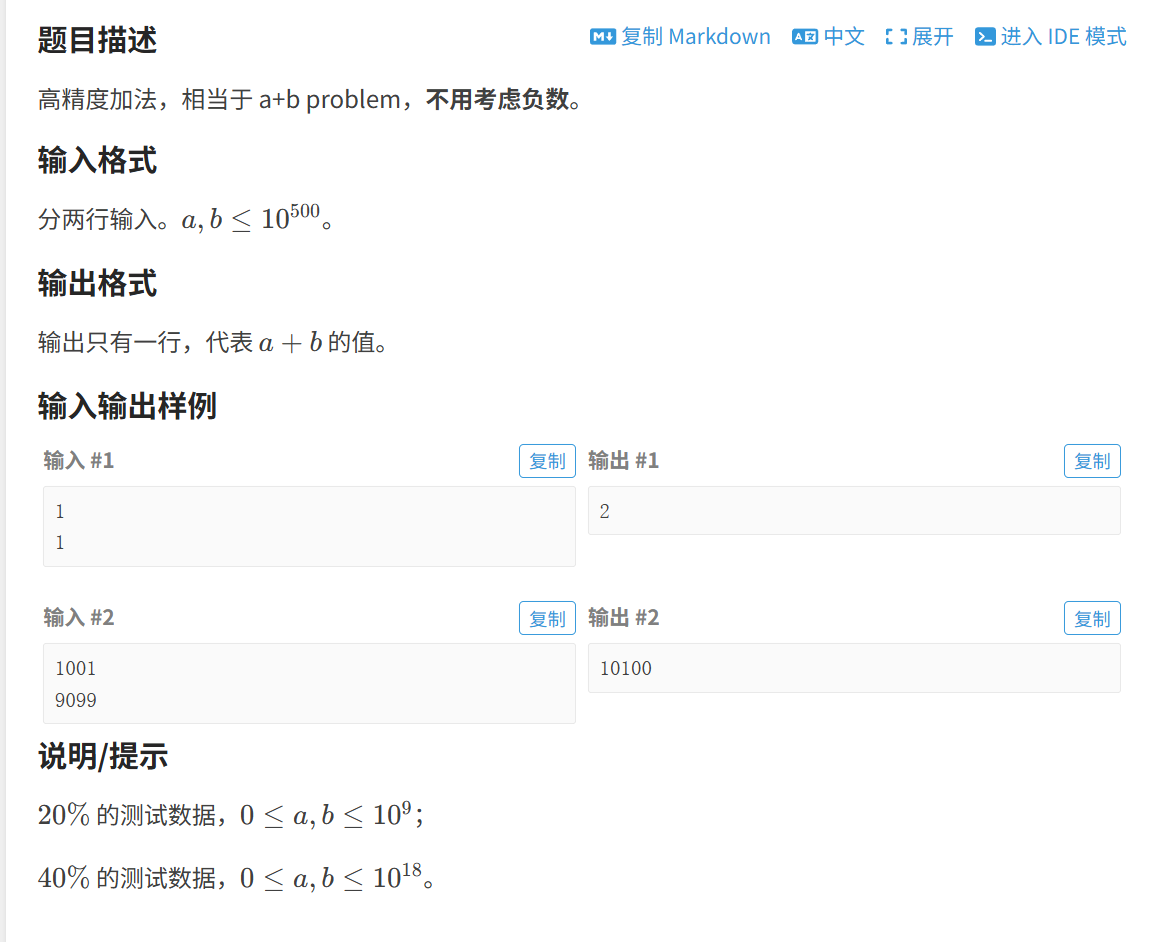
思路:
- ⽤字符串读入数据;
- 将字符串的每⼀位拆分,逆序放在数组中;
- 模拟列竖式计算的过程:
a. 对应位累加;
b. 处理进位;
c. 处理余数。- 处理结果的位数
代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int a[N], b[N], c[N];
int la, lb, lc;
void Add(int a[], int b[], int c[])
{
for (int i = 0;i < lc;i++)
{
c[i] += a[i] + b[i]; // 对应位相加,再加上进位
c[i + 1] += c[i] / 10; // 处理进位
c[i] %= 10; // 处理余数
}
if (c[lc]) lc++;
}
int main()
{
string s1, s2;
cin >> s1 >> s2;
la = s1.size(), lb = s2.size();lc = max(la, lb);
// 1. 拆分每⼀位,逆序放在数组中
for (int i = 0;i < la; i++)
{
a[la - 1 - i] = s1[i] - '0';
}
for (int i = 0;i < lb; i++)
{
b[lb - 1 - i] = s2[i] - '0';
}
//模拟加法过程
Add(a, b, c);
for (int i = lc - 1;i >= 0;i--)
cout << c[i];
return 0;
}- const int N = 1e6 + 10 :定义数组的最大长度,这里设得比500大很多,是为了给大整数的存储和进位预留足够空间,避免数组不够用。
- int aN, bN :两个数组分别存要相加的两个大整数,并且是逆序存储的------比如输入"1001",会存在a0=1(个位)、a1=0(十位)、a2=0(百位)、a3=1(千位),这样能方便从个位开始逐位计算,不用倒着找个位。
- int cN :用来存加法的最终结果,和a、b一样是逆序存储,比如计算结果是1001,c数组就是c0=1、c1=0、c2=0、c3=1。
- la, lb :分别表示两个大整数的位数,其实就是输入的两个字符串s1、s2的长度------比如s1是"123",la就是3;s2是"45",lb就是2。
- lc :表示结果数组c的有效长度,一开始设为la和lb里的较大值(因为两个数相加,结果最少和位数多的那个数一样长),后面如果最高位有进位,lc会再加1。
- string s1, s2 :用字符串来接收输入的大整数,因为如果直接用数字类型接收,500位的数根本存不下,字符串能原样保存每一位数字。
1. 输入与数组初始化
-
先通过cin输入两个字符串s1、s2,然后用s1.size()、s2.size()分别得到两个数的位数la、lb。
-
接着把字符串里的数字逆序存到数组a、b里:
比如s1是"1001"(长度la=4),循环 for (int i=0; i<la; i++) 里, ala-1-i = s1i-'0' 的意思是:把s10(字符'1')转成数字1,存到a3(千位);s11('0')转成0存到a2(百位);s12('0')存到a1(十位);s13('1')存到a0(个位)------最后a数组就是1,0,0,1,刚好对应1001的逆序。b数组的存储逻辑和a完全一样。
2. Add函数:模拟逐位加法
这个函数是核心,专门负责算a和b的和,存到c里:
-
第一步先设lc为max(la, lb),确定结果的初始长度。
-
然后循环 for (int i=0; i<lc; i++) ,从个位(i=0)开始,逐位算到初始lc的最高位(i=lc-1):
-
ci += ai + bi :当前位的和 = a的第i位数字 + b的第i位数字 + 上一步留下来的进位(ci一开始是0,第一次加的就是ai\[ib\[i)。
-
ci+1 += ci / 10 :算进位------用当前位的和除以10,商就是要进到下一位的数,加到ci+1里(比如和是12,进位就是1,加到下一位)。
-
ci %= 10 :当前位只留个位数字------用和除以10的余数作为当前位的结果(比如和是12,余数2就是当前位的数)。
-
循环结束后,判断 clc 是不是0:如果不是0,说明最高位相加后产生了进位(比如999+1,最高位加完进位1),这时候就把lc加1,让结果长度包含这个进位位。
3. 输出结果
因为c数组是逆序存的(个位在c0,最高位在clc-1),所以输出时要从lc-1(最高位)循环到0(个位),依次输出每一位数字,拼起来就是正确的结果。
注意点:
1. 为什么要写 s1i - '0' ?------ 字符转数字的关键
因为 s1、s2 是字符串类型,里面存的每一个"数字"本质是字符(比如字符 '1'、'9'),而不是真正的整数 1、9。
计算机中,字符是用 ASCII 码存储的:字符 '0' 的 ASCII 码是 48,'1' 是 49,'2' 是 50...... 直到 '9' 是 57。
所以 s1i - '0' 的本质是:用字符的 ASCII 码减去 '0' 的 ASCII 码,把字符转成对应的整数------比如 '5' - '0' = 53 - 48 = 5,刚好得到数字 5。
如果不写 - '0' ,直接用 s1i 赋值给数组,存的会是 ASCII 码(比如 '1' 存成 49),后续加法就完全错了。
2. 加法函数中, += 和 %= 能不能换成 + 和 % ?------ 必须用复合赋值,否则漏进位
不能直接换,核心是要保留"上一轮的进位":
- 先看 ci += ai + bi :这里的 += 不是简单的"加",而是"当前位的和 + 上一轮存到 ci 的进位"。
比如上一轮计算时, ci 可能已经存了前一位传来的进位(比如 i=1 时,c1 可能被 i=0 的进位 c1 += 1 赋值过)。如果换成 ci = ai + bi ,就会把之前的进位覆盖掉,导致进位丢失。
- 再看 ci %= 10 : %= 是"先取余,再把结果存回 ci"。
如果换成 ci = ci % 10 ,功能上完全一样(只是写法不同);但如果直接写 ci % 10 而不加赋值,取余后的结果没存回 ci,ci 还是原来的"和+进位"的数值(比如 12),后续输出就会错。
3. 为什么要 lc++ ?------ 给最高位的进位"腾位置"
lc 是结果数组 c 的有效长度(即最终输出的位数),初始 lc = max(la, lb) (比如 999+2,初始 lc=3)。
但两个数相加可能产生"最高位进位"(比如 999+2=1001,原来 3 位,加完变成 4 位,多了最高位的 1)。
循环结束后, clc 存的就是最高位的进位(比如 999+2 中,c3 = 1)。
所以 if (clc) lc++ 的作用是:如果最高位有进位(clc≠0),就把结果长度加 1,让这个进位成为"新的最高位"------否则输出时会漏掉这个进位(比如 1001 只输出 001)。
如果不写 lc++ ,最高位的进位就不会被输出,结果必然少一位,完全错误。
题二 : A-B Problem
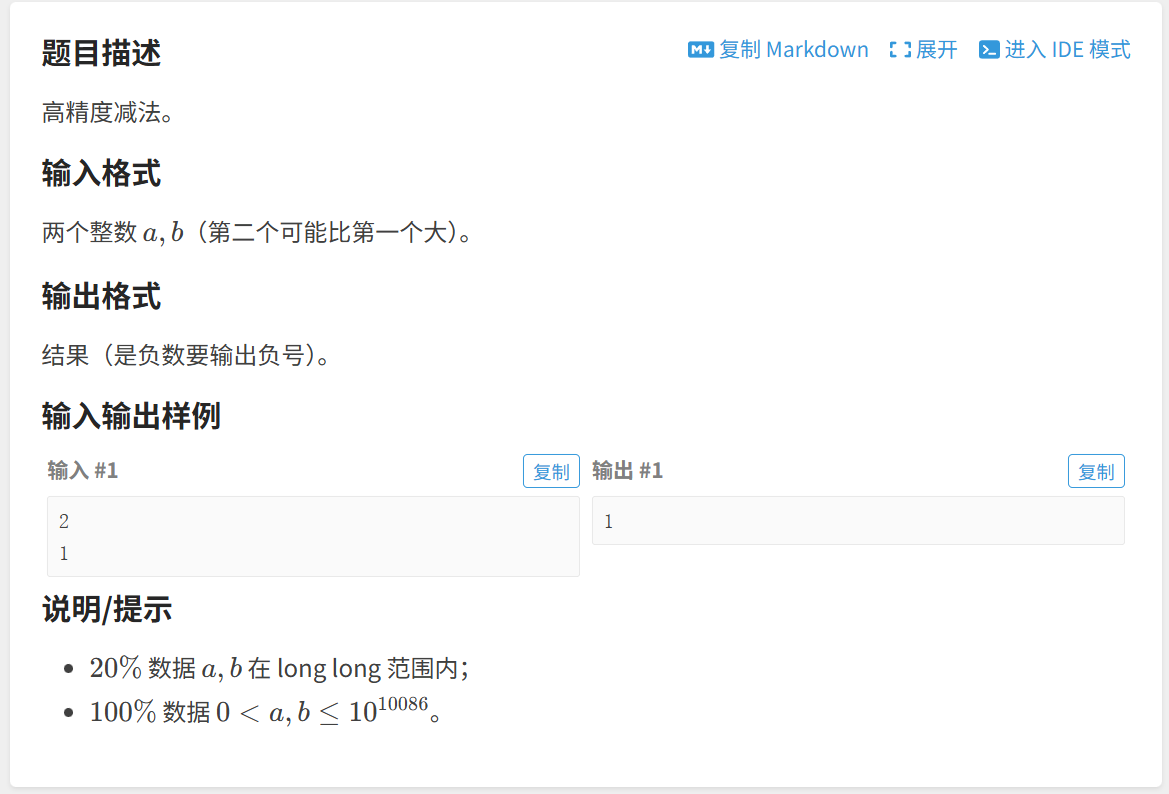
思路:

代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int la, lb, lc;
int a[N], b[N], c[N];
bool cmp(string& s1, string& s2)
{
//先比较长短
if (s1.size() != s2.size())
return s1.size() < s2.size();
//再按照 字典序 的方式进行比较
return s1 < s2;
}
void sub(int a[], int b[], int c[])
{
for (int i = 0;i < lc;i++)
{
c[i] += a[i] - b[i];
if (c[i] < 0)
{
c[i + 1] -= 1;
c[i] += 10;
}
}
//处理前导零
while (lc > 1 && c[lc - 1] == 0) lc--;
}
int main()
{
string s1, s2;
cin >> s1 >> s2;
//先比大小
if(cmp(s1,s2))
{
swap(s1, s2);
cout << '-';
}
//拆分每一位,逆序放入数组中
la = s1.size(), lb = s2.size(), lc = max(la, lb);
for (int i = 0;i < la;i++)
{
a[la - 1 - i] = s1[i] - '0';
}
for (int i = 0;i < lb;i++)
{
b[lb - 1 - i] = s2[i] - '0';
}
//模拟减法
sub(a, b, c);
for (int i = lc - 1;i >= 0;i--)
cout << c[i];
return 0;
}我们用 8-12 这个例子,走一遍代码的执行流程:
步骤1:读入字符串
输入 s1="8" , s2="12" 。
步骤2:比较大小(确定被减数/减数)
调用 cmp(s1, s2) :
-
s1长度=1 , s2长度=2 → s1.size() < s2.size() ,所以 cmp返回true 。
-
执行 swap(s1, s2) → 此时 s1="12" , s2="8" ;同时输出负号 - 。
步骤3:字符串逆序存入数组
-
la = s1.size()=2 , lb = s2.size()=1 , lc = max(2,1)=2 。
-
处理 s1="12" :
a2-1-0 = a1 = '1'-'0'=1 ;
a2-1-1 = a0 = '2'-'0'=2 ;
所以 a数组 : a0=2, a1=1 。
- 处理 s2="8" :
b1-1-0 = b0 = '8'-'0'=8 ;( b1 默认为0)
所以 b数组 : b0=8, b1=0 。
步骤4:模拟减法(sub函数)
遍历 i=0 到 i=1 :
- i=0 :
c0 += a0-b0 = 2-8 = -6 ;
因为 -6 < 0 ,所以 c1 -=1 ( c1 变为 -1 ), c0 +=10 → c0=4 。
- i=1 :
c1 += a1-b1 = (-1) + 1-0 = 0 ;
无需借位。
处理前导零: lc=2 , c1=0 → 执行 lc-- → lc=1 。
步骤5:输出结果
逆序输出 c数组 (从 lc-1=0 到 0 ):输出 c0=4 。
最终整体输出: -4 (对应 8-12=-4 )。
注意点:
注意点1:提前输出负号
- 为什么要提前输出?
因为我们会把"小数减大数"转换成"大数减小数"来计算(避免中间出现负数),所以只有在交换了被减数和减数时(即原数是小数减大数),才需要在开头输出负号。
- 易错点:不要在计算完结果后再补负号(容易忘记或逻辑混乱),而是在确定需要交换两个数的同时就输出负号。
注意点2:先比字符串长度,再比字典序
-
长度优先的原因:数字的位数越多,数值一定越大(比如"123"是3位,"45"是2位,123>45)。
-
字典序的适用场景:只有当两个数的位数相同时,字符串的字典序才等价于数字的大小(比如"123"和"124",字典序"123"<"124",对应数字123<124)。
-
易错点:不能直接对任意长度的字符串用字典序比较(比如"9"和"10",字典序"9">"10",但实际数字9<10)。
注意点3:前导零的处理
-
处理时机:要在减法计算完成后再处理前导零(计算过程中高位的0是必要的,不能提前删)。
-
处理规则:从结果数组的最高位(数组末尾)开始检查,若为0则缩短结果长度,直到遇到非0数字;但要保证至少保留1位(比如结果是0时,不能删成空)。
-
易错点:如果不处理前导零,会输出"00901"这类不合法的数字;如果处理过度,可能把"0"删成空字符串。
题三 : A*B Problem
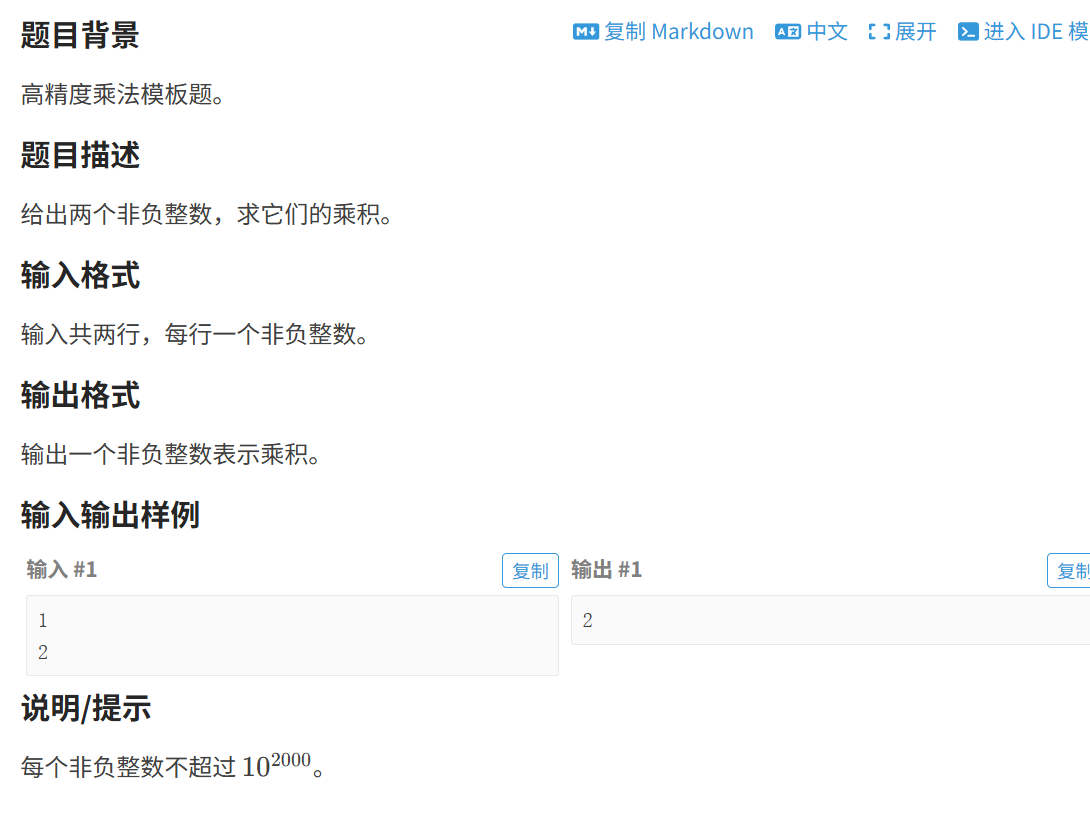
思路:



代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int a[N], b[N], c[N];
int la, lb, lc;
void mul(int a[], int b[], int c[])
{
//无进位相乘 , 然后相加
for (int i = 0;i < la;i++)
{
for (int j = 0;j < lb;j++)
{
c[i + j] += a[i] * b[j];
}
}
//处理进位
for (int i = 0;i < lc;i++)
{
c[i + 1] += c[i] / 10;
c[i] %= 10;
}
//处理值为零时
while (lc > 1 && c[lc - 1] == 0) lc--;
}
int main()
{
string s1, s2;
cin >> s1 >> s2;
la = s1.size(), lb = s2.size(), lc = la + lb;
for (int i = 0;i < la;i++)
{
a[la-1-i] = s1[i]-'0';
}
for (int i = 0;i < lb;i++)
{
b[lb - 1 - i] = s2[i] - '0';
}
mul(a, b, c);
for (int i = lc - 1;i >= 0;i--)
{
cout << c[i];
}
return 0;
}普通数据类型存不下2000位的大整数,所以用数组逆序存储大整数的每一位,然后像列竖式乘法一样:
-
把其中一个数的每一位,分别和另一个数的每一位相乘;
-
把乘积"错位"累加到结果数组的对应位置;
-
最后统一处理所有位置的进位,得到最终结果。
mul 函数:模拟竖式乘法
(1)逐位相乘 + 错位累加
循环 for (int i=0; i<la; i++) (遍历 a 的每一位),嵌套 for (int j=0; j<lb; j++) (遍历 b 的每一位):
-
ai 是 a 的第 i 位(对应原数的"第i位",比如 i=0 是个位);
-
bj 是 b 的第 j 位;
-
它们的乘积要存到 ci+j 中(错位累加):比如 a的个位(i=0)×b的个位(j=0) ,结果存到 c0 ; a的个位×b的十位(j=1) ,结果存到 c1 ; a的十位(i=1)×b的个位 ,结果也存到 c1 ------这和竖式乘法中"相同数位对齐"的逻辑一致。
-
用 += 而不是 = :因为多个乘积会加到同一个 ci+j 位置(比如 a0×b1 和 a1×b0 都要加到 c1 ),如果用 = 会覆盖之前的结果。
(2)统一处理进位
循环 for (int i=0; i<lc; i++) ,从个位到最高位处理每一位的进位:
-
ci+1 += ci / 10 :把当前位的"十位及以上部分"(即 ci/10 )作为进位,加到下一位;
-
ci %= 10 :当前位只保留"个位部分"(即 ci%10 )。
这样一次循环就能把所有位置的进位处理完。
(3)去掉结果的前导零
用 while (lc>1 && clc-1==0) :
- 如果结果的"最高位"是0(比如 100×100=10000 ,初始 lc=6 ,但 c5=0 ),就把 lc 减1,直到最高位不是0或只剩1位(避免输出 0000 这种无效结果)。
注意点:
1. 数组存储的"逆序"必须严格对应"数位"
-
逆序的核心是把"个位存在数组下标0的位置"(比如输入 123 , a0=3 是个位, a1=2 是十位, a2=1 是百位)。
-
如果顺序存反(比如把高位存在下标0),后续的 i+j 错位累加逻辑会完全混乱,导致数位对齐错误。
2. 相乘阶段必须用 += 而不是 = -
错误写法: ci+j = ai * bj (会覆盖之前的乘积);
-
正确写法: ci+j += ai * bj (累加所有错位的乘积)。
比如 a0×b1 和 a1×b0 都要加到 c1 ,如果用 = 会只保留最后一次乘积,结果必然错误。
3. lc 的初始值必须是 la + lb
两个数相乘,结果的最大位数是"位数之和"(比如3位×2位最多5位)。如果 lc 设得更小,会导致高位的乘积或进位被截断,结果丢失;设得更大则会多一些前导零,但后续的去零逻辑可以处理。
4. 进位循环的范围必须覆盖 lc
-
进位循环要写 for (int i=0; i<lc; i++) (而不是 i<=lc 或更小的范围),因为 lc 是结果的最大位数,所有可能的进位都在这个范围内。
-
如果循环范围不够,高位的进位会被遗漏,导致结果错误(比如999×999的进位会传到很高位)。
5. 去前导零的逻辑不能省略,且要在"进位之后"执行 -
必须等所有进位处理完,再去前导零(否则会把合法的高位0误删)。
-
条件 lc>1 是为了避免"结果本身是0"时被误删(比如输入 0 和 123 ,结果是 0 ,不能把唯一的 0 删掉)。
题四 : A/B Problem
思路:

代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int a[N], b, c[N];
int la, lc;
void sub(int a[], int b, int c[])
{
//标记每次除完之后的余数
long long t = 0;
for (int i = la - 1;i >= 0;i--)
{
//计算当前的被除数
t = t * 10 + a[i];
c[i] = t / b;
t %= b;
}
//处理前导零
while (lc > 1 && c[lc - 1] == 0) lc--;
}
int main()
{
string s1;
cin >> s1 >> b;
la = s1.size();
for (int i = 0;i < la;i++)
{
a[la - 1 - i] = s1[i] - '0';
}
lc = la;
sub(a, b, c);
for (int i = lc - 1;i >= 0;i--)
cout << c[i];
return 0;
}比如 100÷5 的流程:
步骤1:读入与数组存储
输入 s1="100" , b=5 。
la = s1.size()=3 ,逆序存入数组 a :
-
a3-1-0 = a2 = '1'-'0' = 1
-
a3-1-1 = a1 = '0'-'0' = 0
-
a3-1-2 = a0 = '0'-'0' = 0
此时 a数组 : a0=0, a1=0, a2=1 (逆序后的 100 )。
步骤2:调用 sub 函数
lc=3 ,初始化余数 t=0 ,从 i=la-1=2 (数组 a 的高位)遍历到 i=0 :
- i=2:
t = t*10 + a2 = 0*10 + 1 = 1
c2 = t / b = 1 / 5 = 0
t = t % b = 1 % 5 = 1
- i=1:
t = 1*10 + a1 = 10 + 0 = 10
c1 = 10 / 5 = 2
t = 10 % 5 = 0
- i=0:
t = 0*10 + a0 = 0 + 0 = 0
c0 = 0 / 5 = 0
t = 0 % 5 = 0
此时 c数组 : c0=0, c1=2, c2=0 。
步骤3:处理前导零
lc=3 ,检查 clc-1=c2=0 ,执行 lc-- ( lc=2 );
再检查 c1=2≠0 ,停止处理。
步骤4:输出(修正循环条件为 i >= 0 )
从 i=lc-1=1 遍历到 i=0 ,输出 c1=2 、 c0=0 ,最终结果为 20 (即 100÷5=20 )。
注意点:
注意点1:为什么b用整形变量,用数组?
因为你的代码实现的是 "高精度除以低精度"(即:大数÷小数),不是"高精度除以高精度"。
-
b 是"小数":题目中 b 的范围没超过整形( int )的存储上限(比如 b≤1e9 ),直接用 int 存就行;
-
若 b 也是大数(比如 b=1234567890123 ),就不能用 int 了,必须也用数组存,那就是"高精度÷高精度",逻辑会更复杂(需要用减法模拟除法)。
注意点2:为什么除法函数里面的for循环i从大到小?
因为除法要 从原数的高位开始算(和竖式除法一致)。
-
数组 a 是逆序存的(比如 100 存成 0,0,1 ),原数的高位对应数组的"大下标"( a2 是百位1);
-
所以 i从la-1(大下标)到0(小下标) ,就是从原数的高位→低位遍历,正好匹配竖式除法的计算顺序(先算百位,再算十位,最后算个位)。
注意3:为什么用long long?int可以吗?
不可以,会溢出!
t 的逻辑是"之前的余数×10 + 当前位",假设 a 的当前位是9,之前的余数是 1e9 ( int 最大值约2e9):
-
若用 int : t = 1e9 *10 +9 = 10000000009 ,远超 int 的存储上限(2147483647),会溢出出错;
-
用 long long :存储上限是 9e18 ,足够容纳"余数×10+当前位"的结果(就算余数是 1e9 ,×10+9也才 1e10 ,远小于 9e18 )。
注意点4:t的逻辑(核心!)
t 是 "当前正在计算的被除数",本质是模拟竖式除法中"余数+落位"的过程,一步一步拆:
-
初始化 t=0 :刚开始没有余数;
-
每一步 t = t*10 + ai :把"上一步的余数"×10(相当于竖式里"把下一位落下来",比如余数1→10,再加上当前位0→10);
-
计算 ci = t / b :当前位的商(比如10÷5=2);
-
更新 t = t % b :当前步的余数(比如10%5=0,作为下一步的初始余数)。
举个例子( 100÷5 ):
-
第一步(百位1):t=0×10+1=1 → 商0 → 余数1;
-
第二步(十位0):t=1×10+0=10 → 商2 → 余数0;
-
第三步(个位0):t=0×10+0=0 → 商0 → 余数0;
枚举
题一 : 铺地毯

思路:

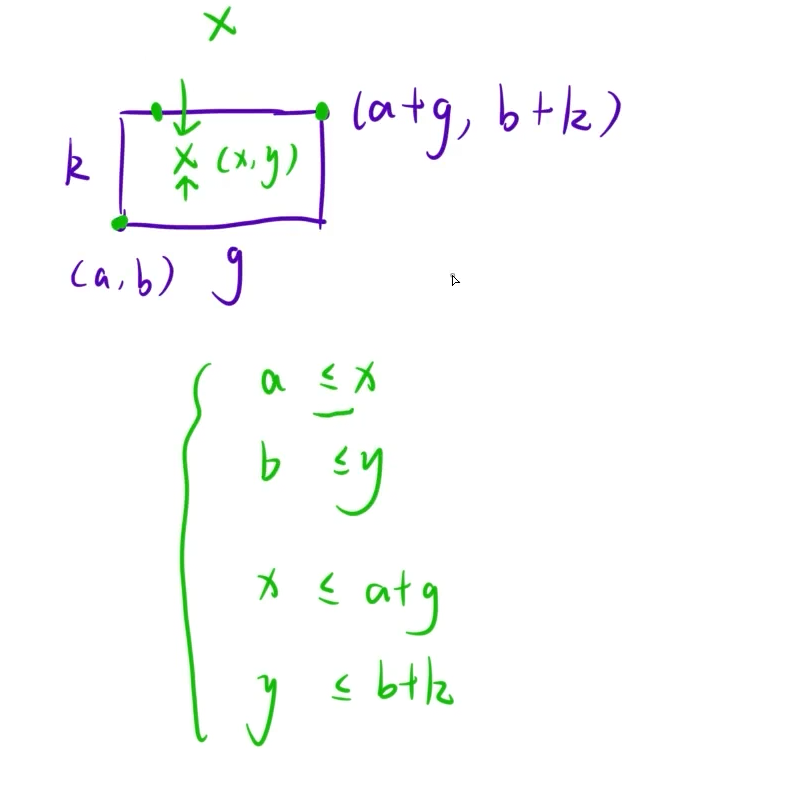
代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e4 + 10;
int a[N], b[N], g[N], k[N];
int x, y;
int n; //表示有几张地毯
int find()
{
//从后往前枚举
for (int i = n;i >= 1;i--)
{
//判断是否覆盖
if (a[i] <= x && b[i] <= y && a[i] + g[i] >= x && b[i] + k[i] >= y)
{
return i;
}
}
return -1;
}
int main()
{
cin >> n;
for (int i = 1;i <= n;i++)
cin >> a[i] >> b[i] >> g[i] >> k[i];
cin >> x >> y;
cout << find() << endl;
return 0;
}注意点:
- 全局变量的含义
代码里定义的全局数组:
-
aN :存储第 i 张地毯左下角的x坐标(对应题目里的 a );
-
bN :存储第 i 张地毯左下角的y坐标(对应题目里的 b );
-
gN :存储第 i 张地毯在x轴方向的长度(对应题目里的 g );
-
kN :存储第 i 张地毯在y轴方向的长度(对应题目里的 k );
-
全局变量 x,y :存储待查询点的坐标;
-
全局变量 n :存储地毯的总数。
- find函数中if语句的逻辑
if (ai <= x && bi <= y && ai + gi >= x && bi + ki >= y) 是用来判断第i张地毯是否覆盖了点(x,y),逻辑是:
-
地毯的x范围是 a\[i, ai\[ig\[i] (左下角x到x+长度),所以点的x要满足 ai ≤ x ≤ ai\[ig\[i ;
-
地毯的y范围是 b\[i, bi\[ik\[i] (左下角y到y+长度),所以点的y要满足 bi ≤ y ≤ bi\[ik\[i ;
-
同时满足这四个条件,说明点在第i张地毯的范围内。
- 变量与题目如何串联
题目是"按编号从小到大铺地毯,后铺的覆盖先铺的,求点上方最上面的地毯编号",代码的串联逻辑:
-
输入时,把每张地毯的 a,b,g,k 存在对应的全局数组里( ai 对应第i张的左下角x,依此类推);
-
输入查询点的 x,y ,存在全局变量里;
-
find 函数从后往前枚举地毯(因为后铺的在上面,找到第一个覆盖点的就是最上面的 );
-
用if语句判断当前地毯是否覆盖点,找到则返回编号,全枚举完没找到就返回-1。
题二 : 回文日期

思路1:

代码:
cpp
#include<iostream>
using namespace std;
int x, y;
int day[] = { 0,31,29,31,30,31,30,31,31,30,31,30,31 };
int main()
{
cin >> x >> y;
int ret = 0;
//枚举日月的组合
for (int i = 1;i <= 12;i++)
{
for (int j = 1;j <= day[i];j++)
{
int k = j % 10 * 1000 + j / 10 * 100 + i % 10 * 10 + i / 10;
int num = k * 10000 + i * 100 + j;
if (x <= num && num <= y)
ret++;
}
}
cout << ret << endl;
return 0;
}该思路本质是利用回文日期的结构特性,先构造"合法的回文日期",再验证是否在目标范围内,具体逻辑可以拆解为:
因为8位回文日期的格式是 YYYYMMDD ,且必须满足"回文",所以:
YYYY 是 DDMM 的反转(比如月日是 0102 ,则年份必须是 2010 ,这样整体是 20100102 ,满足回文)。
所以思路是:
-
枚举所有合法的月日组合(比如1月1日、1月2日...12月31日,只枚举真实存在的月日);
-
根据月日构造对应的回文年份(把月日的字符串反转,得到年份);
-
拼接成完整的8位回文日期(年份+月日);
-
验证这个日期是否在输入的 x-y 范围内,若是则计数。
为什么这个思路可行?
-
回文日期的结构决定了:只要月日合法,且对应的年份构造正确,得到的日期一定是回文的(不需要额外判断回文);
-
只枚举"合法的月日",避免了构造无效的回文日期(比如月日是 1301 这种不存在的月份);
-
最后只需要验证日期是否在目标区间,逻辑简洁且效率高。
注意点:
为什么数组中对应的二月份是29天而不是28天?
因为每个月日组合对应的回文日期是唯一的(因为年份由月日的各位数字反向映射决定),不存在"一个月日对应多个年份"的情况。
所以当月日是 0229 时,只能构造出 92200229 ,然后只需要判断 9220 是否是闰年即可(又因为9220是闰年,所以这个日期合法)。
这个思路的优势是避免了遍历大量无效日期,只枚举合法的月日组合,再反向构造年份,效率很高。
思路2:

代码:
cpp
#include <iostream>
#include <string>
using namespace std;
// 判断是否为闰年
bool isLeap(int year) {
if (year % 400 == 0) return true;
if (year % 100 == 0) return false;
if (year % 4 == 0) return true;
return false;
}
// 判断日期是否合法
bool isValidDate(int year, int month, int day) {
// 月份范围1-12
if (month < 1 || month > 12) return false;
// 各月份的天数(先按平年处理2月)
int daysInMonth[] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
// 闰年2月调整为29天
if (month == 2 && isLeap(year)) {
daysInMonth[2] = 29;
}
// 日期范围1-当月最大天数
return (day >= 1 && day <= daysInMonth[month]);
}
// 判断数字是否为回文(8位)
bool isPalindrome(int num) {
string s = to_string(num);
// 8位数字才需要判断(题目中输入是8位,枚举的也是8位)
for (int i = 0; i < 4; i++) {
if (s[i] != s[7 - i]) {
return false;
}
}
return true;
}
int main() {
int x, y;
cin >> x >> y;
int count = 0;
// 枚举x到y之间的所有数字
for (int num = x; num <= y; num++) {
// 第一步:判断是否是回文
if (!isPalindrome(num)) {
continue;
}
// 第二步:拆分为年、月、日
int year = num / 10000; // 前4位是年
int month = (num / 100) % 100; // 中间2位是月
int day = num % 100; // 最后2位是日
// 第三步:验证日期是否合法
if (isValidDate(year, month, day)) {
count++;
}
}
cout << count << endl;
return 0;
}思路3:

代码:
cpp
#include <iostream>
#include <string>
using namespace std;
// 判断是否为闰年
bool isLeap(int year) {
if (year % 400 == 0) return true;
if (year % 100 == 0) return false;
if (year % 4 == 0) return true;
return false;
}
// 判断日期是否合法
bool isValidDate(int year, int month, int day) {
// 月份范围1-12
if (month < 1 || month > 12) return false;
// 各月份的天数(先按平年处理2月)
int daysInMonth[] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
// 闰年2月调整为29天
if (month == 2 && isLeap(year)) {
daysInMonth[2] = 29;
}
// 日期范围1-当月最大天数
return (day >= 1 && day <= daysInMonth[month]);
}
// 判断数字是否为回文(8位)
bool isPalindrome(int num) {
string s = to_string(num);
// 8位数字才需要判断(题目中输入是8位,枚举的也是8位)
for (int i = 0; i < 4; i++) {
if (s[i] != s[7 - i]) {
return false;
}
}
return true;
}
int main() {
int x, y;
cin >> x >> y;
int count = 0;
// 枚举x到y之间的所有数字
for (int num = x; num <= y; num++) {
// 第一步:判断是否是回文
if (!isPalindrome(num)) {
continue;
}
// 第二步:拆分为年、月、日
int year = num / 10000; // 前4位是年
int month = (num / 100) % 100; // 中间2位是月
int day = num % 100; // 最后2位是日
// 第三步:验证日期是否合法
if (isValidDate(year, month, day)) {
count++;
}
}
cout << count << endl;
return 0;
}题三 : 扫雷

思路:

代码:
cpp
#include<iostream>
using namespace std;
const int N = 1e4 + 10;
int n;
int a[N], b[N];
int check1()
{
a[1] = 0;
for (int i = 2;i <= n + 1;i++)
{
a[i] = b[i - 1] - a[i - 1] - a[i - 2];
if (a[i] < 0 || a[i]>1) return 0;
}
if (a[n + 1] == 0) return 1;
else return 0;
}
int check2()
{
a[1] = 1;
for (int i = 2;i <= n + 1;i++)
{
a[i] = b[i - 1] - a[i - 1] - a[i - 2];
if (a[i] < 0 || a[i]>1) return 0;
}
if (a[n + 1] == 0) return 1;
else return 0;
}
int main()
{
cin >> n;
for (int i = 1;i <= n;i++) cin >> b[i];
int ret = 0;
ret += check1();
ret += check2();
cout << ret << endl;
return 0;
}- ai :第一列第 i 个格子的状态(0=非雷,1=雷);
- bi :第二列第 i 个格子的值(即周围雷的数量);
- check1() / check2() :分别枚举第一列第1个格子是0(非雷)/1(雷)的情况。
注意点:
- 原代码中 for 循环到 n+1 的原因
- 你的思路是:把第一列的"虚拟第 n+1 个格子"也纳入计算------因为第二列第 i 个值对应第一列 i-1、i、i+1 三个格子的雷数(8连通)。
- 比如第二列第 n 个值,对应的是第一列 n-1、n、n+1 三个格子的雷数。但第一列实际只有 n 个格子,所以你想通过" an+1 必须是0(无雷)"来约束最后一个位置的合法性。
- 原代码中 if (an+1 == 0) 的意义
- 这里的 an+1 是虚拟的"第n+1个格子",你认为"第一列没有第n+1个格子,所以它必须是0",以此验证第二列第n个值的约束是否成立。
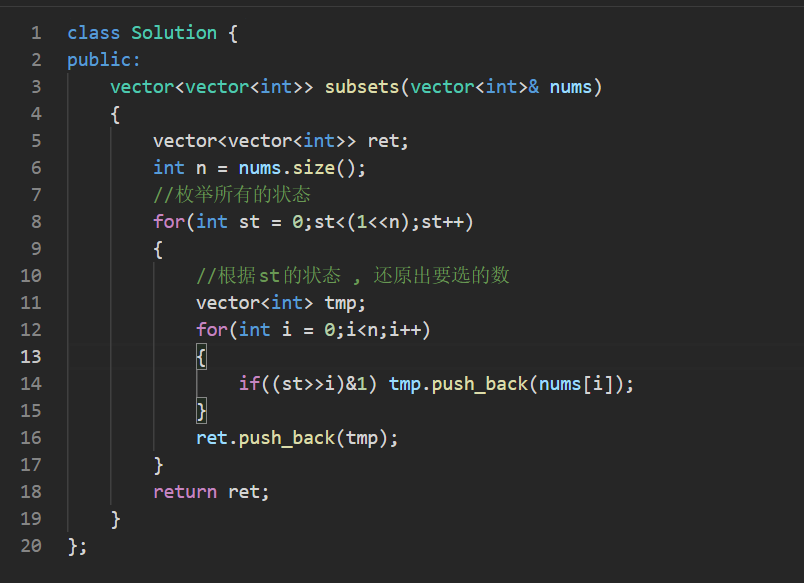
题四 : 子集 (二进制枚举)

思路:
用二进制枚举法解决"子集"问题,核心是用整数的二进制位表示元素的选择状态。
对于长度为 n 的数组,每个元素有"选"或"不选"两种状态,正好可以用 n位二进制数 表示一种选择方案:
- 二进制数的每一位对应数组的一个元素;
- 某一位是 1 表示"选这个元素",是 0 表示"不选"。
例如数组 1,2,3 ( n=3 ):
- 二进制 000 → 所有位是0 → 空集;
- 二进制 001 → 第0位是1 → 选第0个元素 → {1};
- 二进制 010 → 第1位是1 → 选第1个元素 → {2};
- 二进制 011 → 第0、1位是1 → 选第0、1个元素 → {1,2};
- ...以此类推,直到二进制 111 → 选所有元素 → {1,2,3}。
- for(int st = 0; st < (1 << n); st++) :
- 1 << n 等价于 2^n(左移n位),所以循环会从 0 遍历到 2^n - 1,覆盖所有 n位二进制数 的可能(正好对应所有子集的选择状态)。
- (st >> i) & 1 :
- st >> i :将整数 st 右移 i 位,把第 i 位移动到最低位;
- & 1 :和1做与运算,取出最低位的值(0或1);
- 整体作用:判断 st 的第 i 位是0还是1,从而决定是否选择 numsi 。
示例验证(以 nums = 1,2,3 为例)
-
当 st = 0 (二进制 000 ):所有位都是0 → tmp 为空集 → 加入结果;
-
当 st = 1 (二进制 001 ):第0位是1 → tmp = 1 → 加入结果;
-
当 st = 2 (二进制 010 ):第1位是1 → tmp = 2 → 加入结果;
-
当 st = 3 (二进制 011 ):第0、1位是1 → tmp = 1,2 → 加入结果;
-
...直到 st = 7 (二进制 111 ):所有位是1 → tmp = 1,2,3 → 加入结果。
代码: