一、先讲个有趣的快递驿站故事
假设你是一家「快递驿站老板」,核心业务是:用户寄件时填「包裹登记本」(对应JavaBean ),你把登记本信息抄到「快递单」(对应JSON 字符串 )存起来;用户取件时,你再根据快递单把信息填回登记本(对应JSON 反序列化)。
故事分 3 幕:
幕 1:无混淆(驿站初期)
登记本的列名是「收件人姓名」「收件人电话」(对应 JavaBean 的name、phone字段),快递单抄的也是这两个名字。员工取件时,快递单写「收件人姓名」→ 登记本找「收件人姓名」,100% 匹配,从没出错。
幕 2:旧版本混淆(驿站防泄密)
你怕竞争对手偷数据,把登记本列名改成「列 A」「列 B」(混淆把name→a、phone→b),并要求员工:快递单必须抄「列 A」「列 B」。此时用户寄件的快递单全是「列 A = 张三,列 B=138xxxx」,员工取件时按「列 A」找登记本的「列 A」,依然正常。
幕 3:版本升级 + 新混淆(驿站改规则)
你觉得「列 A/B」不够隐蔽,升级驿站系统(APP 升级),把登记本列名改成「列 C」「列 D」(新版本混淆把name→c、phone→d)。但!之前用户的快递单还写着「列 A = 张三,列 B=138xxxx」!
员工拿着旧快递单找新版登记本:只看到「列 C」「列 D」,找不到「列 A」「列 B」------ 要么填不上信息(字段为 null),要么直接喊 "没这列!"(Crash),这就是「反序列化失败」。
如果用户把旧快递单全扔了(清除本地数据),重新填新快递单(新版 APP 序列化出「列 C = 张三,列 D=138xxxx」),员工就能匹配上,自然恢复正常。
二、故事对应代码(从代码看原理)
用最常用的 Gson 举例,能直接跑的极简代码:
步骤 1:定义基础 JavaBean(对应「登记本」)
java
// 未混淆的UserBean(驿站初期)
public class UserBean {
// 收件人姓名
public String name;
// 收件人电话
public String phone;
public UserBean(String name, String phone) {
this.name = name;
this.phone = phone;
}
}步骤 2:无混淆场景(正常序列化 / 反序列化)
java
// 1. 序列化:把UserBean抄到JSON(填快递单)
Gson gson = new Gson();
UserBean oldUser = new UserBean("张三", "13800000000");
String json = gson.toJson(oldUser);
// 此时json内容:{"name":"张三","phone":"13800000000"}(快递单写真实列名)
// 2. 反序列化:按JSON填回UserBean(取件)
UserBean newUser = gson.fromJson(json, UserBean.class);
System.out.println(newUser.name); // 输出:张三(匹配成功)步骤 3:旧版本混淆(列名变 A/B)
混淆工具(R8/ProGuard)会把UserBean改成这样(模拟混淆后的代码):
java
// 旧版本混淆后的UserBean(列名A/B)
public class UserBean {
// 原name→a
public String a;
// 原phone→b
public String b;
public UserBean(String a, String b) {
this.a = a;
this.b = b;
}
}此时序列化的 JSON 变成:{"a":"张三","b":"13800000000"}(快递单写列 A/B),反序列化时按 A/B 找字段,依然正常。
步骤 4:新版本混淆(列名变 C/D)
APP 升级后,混淆规则变了,UserBean被改成:
java
// 新版本混淆后的UserBean(列名C/D)
public class UserBean {
// 原name→c
public String c;
// 原phone→d
public String d;
public UserBean(String c, String d) {
this.c = c;
this.d = d;
}
}此时用旧 JSON({"a":"张三","b":"13800000000"})反序列化:
java
// 旧JSON反序列化新版UserBean
String oldJson = "{"a":"张三","b":"13800000000"}";
UserBean newUser = gson.fromJson(oldJson, UserBean.class);
System.out.println(newUser.c); // 输出:null(找不到a,c字段为空)
System.out.println(newUser.d); // 输出:null(找不到b,d字段为空)
// 若业务依赖name/phone,直接空指针崩溃!清除数据后,新版 APP 序列化的 JSON 是{"c":"张三","d":"13800000000"},反序列化时 c/d 字段能正确赋值,自然正常。
三、时序图(直观看调用过程)
用 Mermaid 时序图展示「正常流程」和「升级失败流程」,小白能一眼看清差异。
时序图 1:正常流程(未混淆 / 清除数据后)
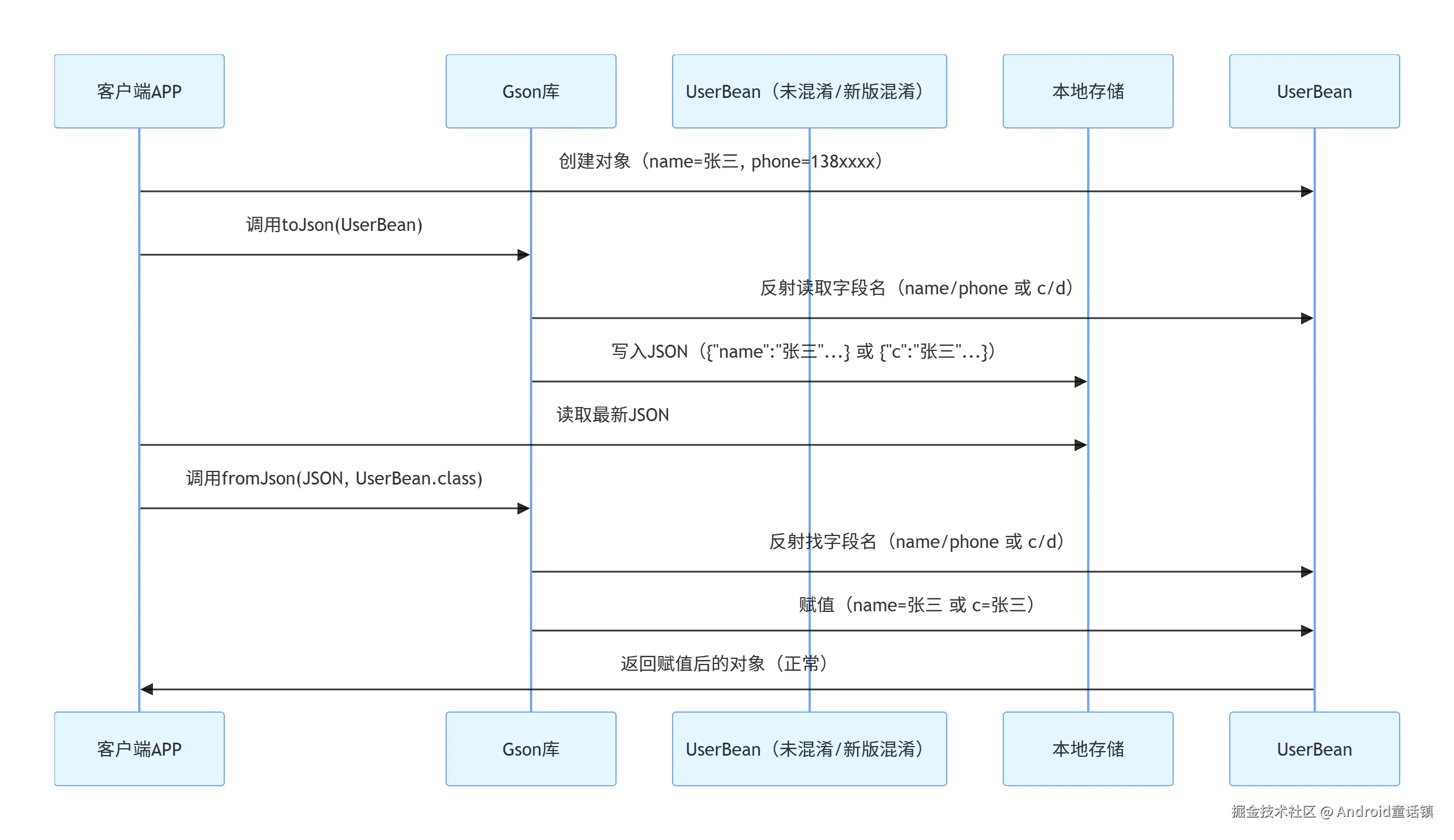
UserBean本地存储UserBean(未混淆/新版混淆)Gson库客户端APPUserBean本地存储UserBean(未混淆/新版混淆)Gson库客户端APP创建对象(name=张三, phone=138xxxx)调用toJson(UserBean)反射读取字段名(name/phone 或 c/d)写入JSON({"name":"张三"...} 或 {"c":"张三"...})读取最新JSON调用fromJson(JSON, UserBean.class)反射找字段名(name/phone 或 c/d)赋值(name=张三 或 c=张三)返回赋值后的对象(正常)
时序图 2:升级后失败流程(混淆名变更)

本地存储(旧数据)UserBean(新版混淆:c/d)Gson库客户端APP(新版)本地存储(旧数据)UserBean(新版混淆:c/d)Gson库客户端APP(新版)读取旧JSON({"a":"张三","b":"138xxxx"})调用fromJson(旧JSON, UserBean.class)反射找字段名(a/b)无a/b字段(返回找不到)字段c/d赋值null返回空值对象业务逻辑崩溃(反序列化失败)
四、核心原理总结
大白话版
混淆会「随机改 JavaBean 的字段名 / 类名」,且新版本混淆的名字和旧版本不一样;JSON 反序列化是「按名字找字段」,旧 JSON 里的名字对应旧混淆名,新版 Bean 只有新混淆名,自然找不到,就失败了;清除数据后,新 JSON 用新混淆名,就能匹配上。
技术版
- 混淆核心:R8/ProGuard 对未保护的字段名 / 类名做无规律重命名,且不同版本的混淆映射表(mapping.txt)不一致;
- JSON 反序列化核心:Gson/FastJson 等库通过反射读取字段名,与 JSON 的 key 做精准字符串匹配;
- 失败本质:旧版本序列化的 JSON key 是「旧混淆名」,新版本 Bean 的字段名是「新混淆名」,反射匹配失败,字段赋值 null 或抛出 NoSuchFieldException;
- 清除数据正常的原因:旧 JSON 被删除,新版本重新序列化生成「新混淆名」的 JSON key,反射匹配成功。
五、小白也能懂的解决方案(对应故事)
回到快递驿站的故事,解决思路就是「让快递单的列名固定不变」,不管登记本怎么改名字:
java
// 给UserBean加注解,固定JSON的key为「name/phone」,不管混淆成啥
public class UserBean {
// 注解指定JSON的key永远是name,哪怕字段被混淆成a/c/x
@SerializedName("name")
public String name;
@SerializedName("phone")
public String phone;
public UserBean(String name, String phone) {
this.name = name;
this.phone = phone;
}
}加了@SerializedName注解后:
- 不管混淆把
name改成 a/c/x,序列化的 JSON 永远是{"name":"张三","phone":"138xxxx"}; - 新版本反序列化旧 JSON 时,按注解的「name/phone」找字段,哪怕字段名是 c/d,也能正确赋值,彻底解决问题。
再补一个兜底的混淆规则(防止字段被删除):
proguard
# 保护所有加了SerializedName注解的字段
-keepclassmembers class * {
@com.google.gson.annotations.SerializedName <fields>;
}
# 保护UserBean包下的类名和字段
-keep class com.你的包名.bean.** { <fields>; }