引言
你有没有遇到过这样的场景:应用在自己的手机上丝般顺滑,但换到某些设备上就卡得像PPT?或者复杂列表滑动时掉帧严重,但CPU和内存占用看起来都正常?
这通常不是代码逻辑的问题,而是渲染性能的瓶颈。在Android系统中,从应用UI绘制到屏幕显示,中间经历了一个复杂的渲染管线------涉及应用进程、SurfaceFlinger系统服务和GPU硬件。理解这条管线的工作原理,是优化渲染性能的关键。
我曾在一个车载项目中遇到过地图滑动时严重掉帧的问题。表面上看CPU占用只有40%,内存也充足,但就是卡。后来通过Systrace分析发现,问题出在过度绘制------地图底图、路网、POI标注层层叠加,GPU每帧要渲染7-8层,导致填充率爆表。最终通过合并图层、优化alpha混合,将帧率从20fps提升到58fps。
本文内容:
- Android渲染架构深入:VSYNC、BufferQueue、SurfaceFlinger工作流程
- GPU渲染管线与优化技巧
- 过度绘制分析与系统化优化方法
- 硬件加速原理与最佳实践
- 渲染性能分析工具全解(Profile GPU Rendering、GPU Profiler)
- 实战案例:复杂列表滑动优化
学习目标:
- 深入理解Android渲染机制的每个环节
- 掌握GPU渲染优化的实用技巧
- 学会使用工具定位渲染瓶颈
- 建立渲染优化的系统化思维
Android渲染机制深入
要优化渲染性能,首先要理解Android的渲染架构。这是一个分层设计的系统,应用、系统服务和硬件紧密协作。
渲染架构全景
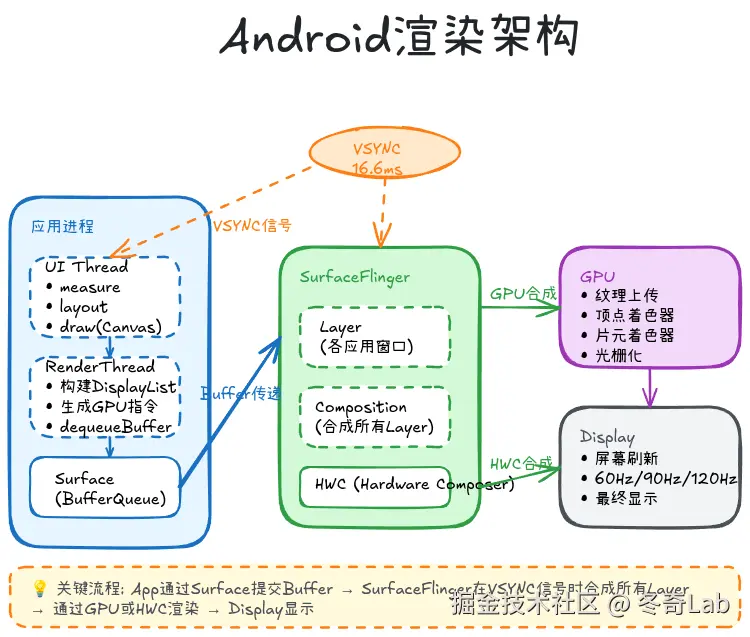
Android渲染架构可以分为以下几层:
1. 应用层 (App Process)
- UI Thread: 执行measure、layout、draw,生成DisplayList
- RenderThread: Android 5.0引入的独立渲染线程,负责将DisplayList转换为GPU指令
2. 系统服务层 (System Server)
- SurfaceFlinger: 系统合成器,负责将各个应用的Surface合成到屏幕
- WindowManager: 管理窗口层级和Surface分配
3. 硬件抽象层 (HAL)
- HWC (Hardware Composer): 硬件合成器,协调GPU和Display硬件
- Gralloc: 图形缓冲区分配器
4. 硬件层
- GPU: 图形处理单元,执行OpenGL ES/Vulkan指令
- Display: 显示设备,接收VSYNC信号
VSYNC信号与Choreographer
VSYNC (Vertical Synchronization) 是渲染系统的节拍器,它确保渲染与屏幕刷新同步,避免画面撕裂。
VSYNC信号流
css
Display发出VSYNC → SurfaceFlinger接收 → 分发给所有应用 → 触发绘制
↓
Choreographer回调Choreographer工作机制:
java
// Choreographer是应用端的VSYNC调度器
Choreographer.getInstance().postFrameCallback { frameTimeNanos ->
// 在下一个VSYNC信号到来时执行
// frameTimeNanos: VSYNC时间戳
doFrame(frameTimeNanos)
}关键时序:
yaml
VSYNC间隔 (60Hz) = 16.67ms
│
├── T0: VSYNC信号到达
│ └── App开始measure/layout/draw (UI Thread)
│
├── T1: DisplayList生成完成 (耗时: 2-5ms)
│ └── RenderThread开始处理
│
├── T2: GPU指令提交完成 (耗时: 3-8ms)
│ └── GPU开始渲染
│
├── T3: GPU渲染完成 (耗时: 5-10ms)
│ └── 写入Back Buffer
│
└── T4: 下一个VSYNC,交换Front/Back Buffer如果 T0 到 T4 的总时间超过16.67ms,就会发生掉帧 (Jank)。
AOSP源码位置:
- Choreographer实现:
frameworks/base/core/java/android/view/Choreographer.java - VSYNC分发:
frameworks/native/services/surfaceflinger/Scheduler/VSyncDispatch.cpp
VSYNC-app vs VSYNC-sf
Android中有两种VSYNC信号:
| 信号类型 | 接收者 | 作用 | 相位偏移 |
|---|---|---|---|
| VSYNC-app | 应用进程 | 触发绘制 | -5ms (提前触发) |
| VSYNC-sf | SurfaceFlinger | 触发合成 | 0ms (准时触发) |
为什么要提前触发应用?
因为应用渲染需要时间,提前触发可以让应用在SurfaceFlinger合成之前完成渲染,确保新帧能被显示。
ini
Time: 0ms 5ms 10ms 16.67ms
│ │ │ │
VSYNC-app │────────> │ │ │ (提前5ms触发)
App Draw │ [绘制] │ │ │
│ │ │ │
VSYNC-sf │ │ │────────> │ (准时触发)
SF Composite │ │ [合成] │双缓冲与三缓冲
为了避免画面撕裂和提升流畅度,Android使用缓冲机制。
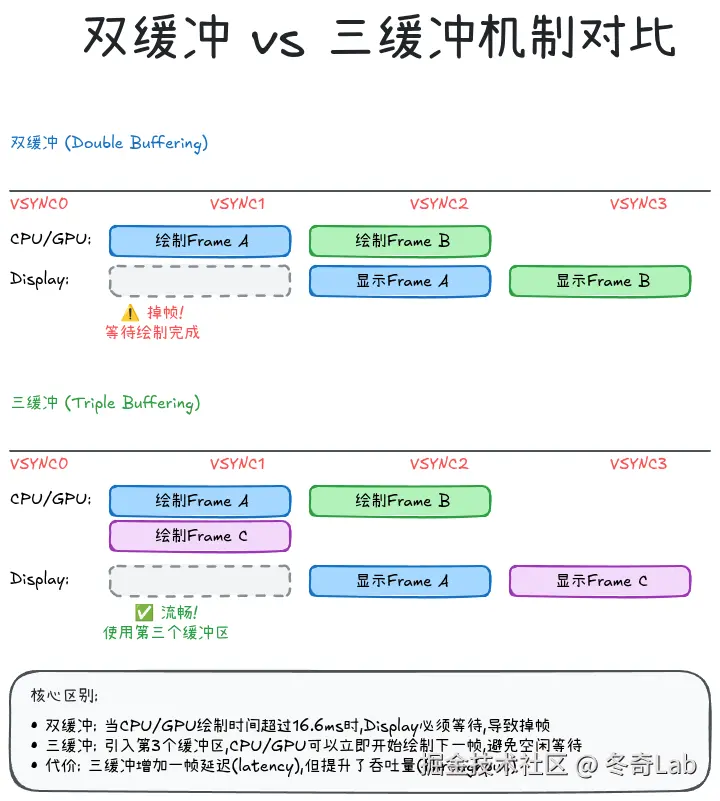
双缓冲 (Double Buffering)
yaml
Front Buffer: 正在被Display扫描显示
Back Buffer: 正在被GPU渲染工作流程:
- GPU渲染到Back Buffer
- VSYNC到来时,交换Front/Back Buffer (SwapBuffers)
- Display从新的Front Buffer读取数据显示
问题 : 如果GPU渲染未完成,VSYNC到来时无法交换,导致掉帧。
三缓冲 (Triple Buffering)
Android 4.1+ 引入三缓冲:
yaml
Front Buffer: 正在被Display扫描
Back Buffer: 正在被GPU渲染
Third Buffer: 等待GPU空闲时预先开始渲染优势: 当GPU繁忙时,CPU可以提前准备下一帧到Third Buffer,减少空闲等待。
代价: 额外的内存占用 + 1帧延迟 (Latency)。
查看当前配置:
bash
adb shell dumpsys SurfaceFlinger | grep -i buffer
# 输出示例:
# Triple Buffering: enabledSurfaceFlinger工作流程
SurfaceFlinger是Android渲染系统的核心,负责将多个应用的Surface合成到屏幕。
SurfaceFlinger架构
scss
┌─────────────────────────────────────────┐
│ SurfaceFlinger进程 │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Scheduler (VSYNC调度) │ │
│ │ - VSyncDispatch │ │
│ │ - EventThread │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Compositor (合成器) │ │
│ │ - Layer管理 │ │
│ │ - BufferQueue消费 │ │
│ │ - 合成策略选择 │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ HWC Abstraction │ │
│ │ - GPU合成 (Client Composition) │ │
│ │ - HWC合成 (Device Composition) │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────┘合成流程时序
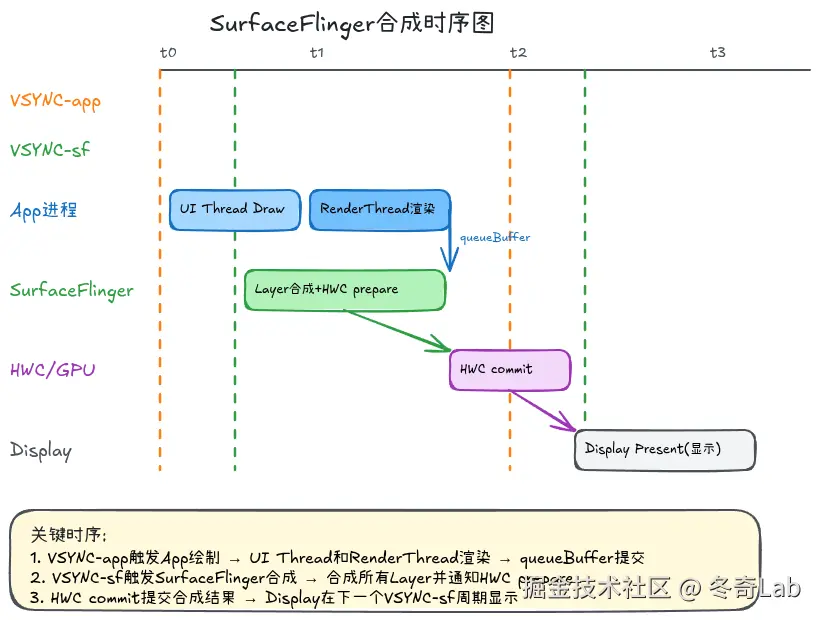
详细步骤:
cpp
// 1. 接收VSYNC-sf信号
void SurfaceFlinger::onMessageReceived(int32_t what) {
switch (what) {
case MessageQueue::INVALIDATE:
// 收集所有Layer的更新
handleMessageInvalidate();
break;
case MessageQueue::REFRESH:
// 执行合成
handleMessageRefresh();
break;
}
}
// 2. 遍历所有Layer,检查是否有新的Buffer
for (auto& layer : mDrawingState.layersSortedByZ) {
if (layer->hasReadyFrame()) {
// 从BufferQueue取出Buffer
layer->updateTexImage();
}
}
// 3. 决定合成策略
if (hwc->canHandleComposition()) {
// HWC合成 (硬件合成,更高效)
doCompositionByHWC();
} else {
// GPU合成 (Client Composition)
doCompositionByGPU();
}
// 4. 输出到Display
display->presentAndGetReleaseFences();合成策略对比:
| 合成方式 | 执行位置 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| Device Composition | HWC硬件 | 功耗低、无需GPU | 能力受限 | 简单场景(2-4个Layer) |
| Client Composition | GPU | 能力强、支持复杂特效 | 功耗高 | 复杂场景(alpha混合、旋转等) |
查看合成策略:
bash
adb shell dumpsys SurfaceFlinger | grep -A 5 "Composition"
# 输出示例:
# Layer[0]: Device Composition
# Layer[1]: Client Composition (alpha < 1.0)
# Layer[2]: Device CompositionBufferQueue机制
BufferQueue是应用与SurfaceFlinger之间的生产者-消费者模型。
BufferQueue架构
bash
┌────────────────┐ BufferQueue ┌──────────────────┐
│ 应用进程 │ ┌──────────┐ │ SurfaceFlinger │
│ │ │ Buffers │ │ │
│ ┌──────────┐ │ │ ┌──────┐ │ │ ┌────────────┐ │
│ │ Producer │──┼──────>│ │Buf#0 │ │<──────┼──│ Consumer │ │
│ │(App Draw)│ │ queue │ ├──────┤ │dequeue│ │(SF Compose)│ │
│ └──────────┘ │ │ │Buf#1 │ │ │ └────────────┘ │
│ │ │ ├──────┤ │ │ │
│ │ │ │Buf#2 │ │ │ │
│ │ │ └──────┘ │ │ │
│ │ └──────────┘ │ │
└────────────────┘ └──────────────────┘工作流程:
java
// 应用端 (Producer)
// 1. 请求一个空闲Buffer
Surface surface = surfaceHolder.getSurface();
Canvas canvas = surface.lockCanvas(null); // dequeueBuffer
// 2. 绘制内容
canvas.drawRect(...);
canvas.drawText(...);
// 3. 提交Buffer
surface.unlockCanvasAndPost(canvas); // queueBuffer
// SurfaceFlinger端 (Consumer)
// 4. 获取最新的Buffer
acquireBuffer();
// 5. 合成到屏幕
composeBuffer();
// 6. 释放Buffer
releaseBuffer();Buffer状态机:
scss
FREE (空闲) ──dequeue──> DEQUEUED (应用持有)
│
queue
│
↓
ACQUIRED (SF持有) ←──acquire── QUEUED (等待合成)
│
release
│
↓
FREE常见参数:
bash
# 查看BufferQueue状态
adb shell dumpsys SurfaceFlinger | grep -A 10 "BufferQueue"
# 输出示例:
# BufferQueue: [com.example.app/com.example.MainActivity#0]
# + buffers: 3
# + queued: 1
# + dequeued: 1
# + free: 1
# + maxAcquired: 1AOSP源码位置:
- BufferQueue实现:
frameworks/native/libs/gui/BufferQueue.cpp - Surface (Producer):
frameworks/native/libs/gui/Surface.cpp - SurfaceFlinger (Consumer):
frameworks/native/services/surfaceflinger/
GPU渲染管线与优化
GPU是渲染的核心硬件,理解GPU渲染管线是优化的基础。
GPU渲染管线
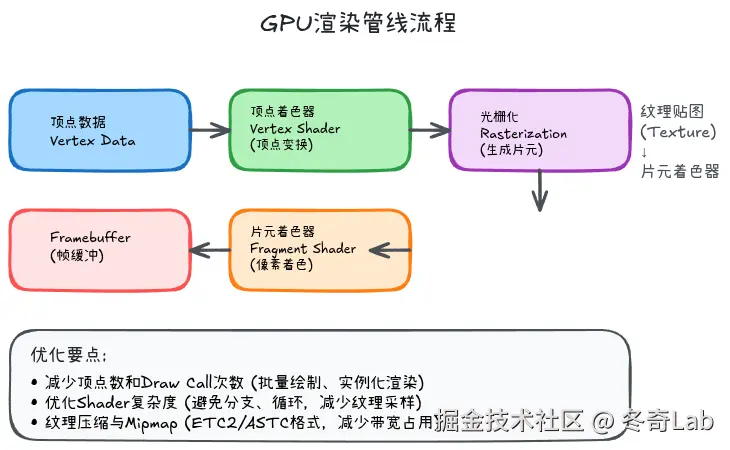
GPU渲染管线 (OpenGL ES):
markdown
1. 顶点着色器 (Vertex Shader)
输入: 顶点坐标、纹理坐标、颜色
输出: 变换后的顶点位置
作用: 顶点变换(MVP矩阵)、光照计算
2. 图元装配 (Primitive Assembly)
作用: 将顶点组装成三角形
3. 光栅化 (Rasterization)
作用: 将三角形转换为像素片段
4. 片段着色器 (Fragment Shader)
输入: 片段坐标、纹理坐标
输出: 片段颜色
作用: 纹理采样、颜色计算、特效
5. 测试与混合 (Tests & Blending)
作用: 深度测试、Alpha混合、模板测试
6. 帧缓冲 (Framebuffer)
作用: 最终输出到屏幕性能瓶颈点:
| 阶段 | 常见瓶颈 | 优化方向 |
|---|---|---|
| 顶点着色器 | 顶点数过多 | 减少顶点、LOD |
| 光栅化 | 大面积多边形 | 剔除、裁剪 |
| 片段着色器 | 复杂计算、纹理采样 | 简化Shader、优化纹理 |
| 测试与混合 | 过度绘制、Alpha混合 | 减少层级、z-order优化 |
OpenGL ES优化技巧
1. 减少Draw Calls
问题: 每次Draw Call都有CPU→GPU的开销。
❌ Bad: 每个UI元素一次Draw Call
kotlin
// 绘制100个按钮,100次Draw Call
for (i in 0..99) {
canvas.drawBitmap(buttonBitmap, x[i], y[i], paint)
}✅ Good: 批量绘制(Batch Drawing)
kotlin
// 使用Canvas.drawBitmapMesh 或者合并到一个纹理
val matrix = Matrix()
for (i in 0..99) {
matrix.setTranslate(x[i], y[i])
canvas.drawBitmap(buttonBitmap, matrix, paint)
}
// 或者更好:使用RecyclerView的ItemDecoration减少绘制Android中的自动批处理:
- RenderThread会尝试合并相同材质的Draw Calls
- 使用相同Paint和Bitmap有助于批处理
2. 纹理优化
纹理压缩:
kotlin
// 使用ETC2/ASTC压缩纹理,减少带宽占用
BitmapFactory.Options options = BitmapFactory.Options()
options.inPreferredConfig = Bitmap.Config.RGB_565 // 2字节/像素
// 比ARGB_8888 (4字节/像素) 节省50%内存和带宽Mipmap使用:
xml
<!-- res/drawable-nodpi/large_image.png -->
<!-- 为不同尺寸提供Mipmap,GPU自动选择合适的级别 -->
<bitmap xmlns:android="http://schemas.android.com/apk/res/android"
android:src="@drawable/large_image"
android:mipMap="true"/>纹理缓存:
java
// 复用Bitmap,避免频繁创建销毁
class BitmapPool {
private val pool = HashMap<Int, Queue<Bitmap>>()
fun acquire(width: Int, height: Int): Bitmap {
val key = width * 10000 + height
return pool[key]?.poll() ?: Bitmap.createBitmap(width, height, Config.ARGB_8888)
}
fun release(bitmap: Bitmap) {
val key = bitmap.width * 10000 + bitmap.height
pool.getOrPut(key) { LinkedList() }.offer(bitmap)
}
}3. Shader优化
避免动态分支:
❌ Bad: 片段着色器中使用if
glsl
// fragment shader
void main() {
if (u_useTexture) {
gl_FragColor = texture2D(u_sampler, v_texCoord);
} else {
gl_FragColor = v_color;
}
}✅ Good: 使用Uniform控制混合
glsl
void main() {
vec4 texColor = texture2D(u_sampler, v_texCoord);
gl_FragColor = mix(v_color, texColor, u_textureFactor);
// u_textureFactor: 0.0(纯色) ~ 1.0(纯纹理)
}预计算常量:
glsl
// ❌ Bad: 每个片段都计算
void main() {
float normalizedX = v_position.x / 1920.0;
// ...
}
// ✅ Good: 在CPU端预计算,传入Uniform
uniform float u_invScreenWidth;
void main() {
float normalizedX = v_position.x * u_invScreenWidth;
// ...
}Vulkan渲染引擎
Vulkan是新一代图形API,比OpenGL ES更底层、更高效。
Vulkan vs OpenGL ES:
| 特性 | OpenGL ES | Vulkan |
|---|---|---|
| CPU开销 | 高 (Driver验证、状态管理) | 低 (显式控制) |
| 多线程 | 单线程 | 原生多线程支持 |
| 控制粒度 | 粗粒度 | 细粒度(内存、同步) |
| 学习曲线 | 平缓 | 陡峭 |
| 适用场景 | 通用应用 | 游戏、3D密集型 |
Vulkan优势示例:
cpp
// OpenGL ES: 串行提交
glDrawElements(...); // Wait for GPU
glDrawElements(...); // Wait for GPU
// Vulkan: 并行构建CommandBuffer
void thread1() {
vkBeginCommandBuffer(cmdBuffer1, ...);
vkCmdDrawIndexed(cmdBuffer1, ...);
vkEndCommandBuffer(cmdBuffer1);
}
void thread2() {
vkBeginCommandBuffer(cmdBuffer2, ...);
vkCmdDrawIndexed(cmdBuffer2, ...);
vkEndCommandBuffer(cmdBuffer2);
}
// 最后一次性提交
vkQueueSubmit(queue, 2, {cmdBuffer1, cmdBuffer2}, ...);Android中启用Vulkan:
kotlin
// 检查设备是否支持Vulkan
val pm = context.packageManager
val hasVulkan = pm.hasSystemFeature(PackageManager.FEATURE_VULKAN_HARDWARE_LEVEL, 1)
if (hasVulkan) {
// 使用Vulkan渲染
// 通常通过游戏引擎(Unity/Unreal)或NDK直接调用
}AOSP源码位置:
- Vulkan Loader:
frameworks/native/vulkan/ - Skia Vulkan Backend:
external/skia/src/gpu/vk/
过度绘制分析与优化
过度绘制 (Overdraw) 是指同一像素被绘制多次,浪费GPU填充带宽。
什么是过度绘制
makefile
屏幕上一个像素点:
┌─────────────────┐
│ 背景 (Layer 0) │ ← 第1次绘制
│ ┌──────────────┤
│ │ 父布局背景 │ ← 第2次绘制
│ │ ┌───────────┤
│ │ │ View背景 │ ← 第3次绘制
│ │ │ ┌────────┤
│ │ │ │ 文字 │ ← 第4次绘制
└──┴─┴─┴────────┘
最终可见: 只有文字
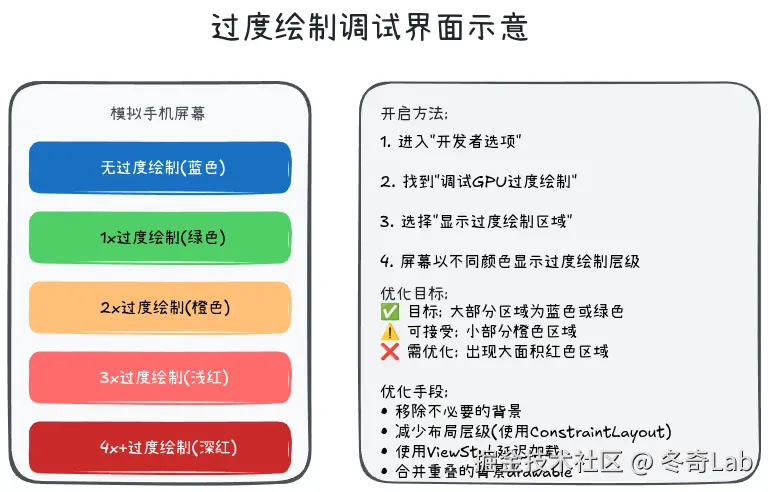
浪费: 前3次绘制都被覆盖过度绘制层级:
| 层级 | 颜色 | 说明 | 性能影响 |
|---|---|---|---|
| 0x | 无色 | 绘制1次 | 理想状态 |
| 1x | 蓝色 | 绘制2次 | 可接受 |
| 2x | 绿色 | 绘制3次 | 需优化 |
| 3x | 粉色 | 绘制4次 | 严重 |
| 4x+ | 红色 | 绘制5次+ | 非常严重 |
过度绘制分析工具
开发者选项
开启调试GPU过度绘制:
设置 → 开发者选项 → 调试GPU过度绘制 → 显示过度绘制区域设备屏幕会显示彩色叠加,颜色越深过度绘制越严重。
Systrace分析
bash
# 抓取Systrace,关注GPU相关的Slice
python systrace.py -t 10 gfx view sched freq -o trace.html
# 关键指标:
# - GPU completion: GPU渲染完成时间
# - eglSwapBuffers: Buffer交换耗时
# - RenderThread: 渲染线程工作时间Systrace中的过度绘制信号:
arduino
Slice名称: "DrawFrame"
├── "syncFrameState" (2ms) ← 同步状态
├── "prepareTree" (1ms) ← 准备DisplayList
├── "draw" (8ms) ← GPU绘制 ← 如果这里超过5ms,可能过度绘制
└── "eglSwapBuffers" (1ms) ← 交换Buffer系统化优化方法
1. 移除不必要的背景
❌ Bad: 层层叠加背景
xml
<!-- 根布局 -->
<LinearLayout
android:background="@color/white"> ← 背景1
<!-- 子布局 -->
<FrameLayout
android:background="@color/white"> ← 背景2 (重复!)
<TextView
android:background="@drawable/text_bg"/> ← 背景3
</FrameLayout>
</LinearLayout>✅ Good: 只保留最上层背景
xml
<LinearLayout> ← 无背景
<FrameLayout> ← 无背景
<TextView
android:background="@drawable/text_bg"/> ← 只有这里有背景
</FrameLayout>
</LinearLayout>检测方法: 使用Layout Inspector查看每个View的background属性。
2. 优化布局层级
❌ Bad: 深层嵌套
xml
<LinearLayout> ← 层级1
<RelativeLayout> ← 层级2
<FrameLayout> ← 层级3
<LinearLayout> ← 层级4
<TextView/> ← 层级5
</LinearLayout>
</FrameLayout>
</RelativeLayout>
</LinearLayout>✅ Good: 使用ConstraintLayout扁平化
xml
<ConstraintLayout> ← 层级1
<TextView
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintStart_toStartOf="parent"/> ← 层级2
</ConstraintLayout>工具: Android Studio Layout Inspector可以可视化层级树。
3. clipRect优化
原理: 告诉GPU只绘制可见区域。
kotlin
class OptimizedView : View {
override fun onDraw(canvas: Canvas) {
// 获取可见区域
val clipBounds = canvas.clipBounds
// 只绘制可见部分
for (item in items) {
if (item.bounds.intersect(clipBounds)) {
canvas.drawBitmap(item.bitmap, item.x, item.y, paint)
}
}
}
}自动clipRect:
kotlin
// ViewGroup默认会clipChildren
<FrameLayout
android:clipChildren="true" ← 裁剪超出子View
android:clipToPadding="true"> ← 裁剪padding区域4. 自定义View优化
❌ Bad: 每次onDraw都创建对象
kotlin
override fun onDraw(canvas: Canvas) {
val paint = Paint() // ❌ 每帧创建,GC压力
paint.color = Color.RED
canvas.drawCircle(x, y, radius, paint)
}✅ Good: 复用Paint对象
kotlin
private val paint = Paint().apply {
color = Color.RED
style = Paint.Style.FILL
isAntiAlias = true
}
override fun onDraw(canvas: Canvas) {
canvas.drawCircle(x, y, radius, paint) // ✅ 复用
}onDraw优化清单:
- 不创建对象 (Paint、Rect等)
- 不执行耗时操作 (文件IO、网络请求)
- 缓存计算结果 (如三角函数)
- 使用Canvas.save/restore管理状态
硬件加速详解
硬件加速 (Hardware Acceleration) 是Android 3.0引入的特性,使用GPU加速2D渲染。
硬件加速层级
Android的硬件加速有4个层级:
| 层级 | 配置位置 | 作用域 | 说明 |
|---|---|---|---|
| Application | AndroidManifest.xml | 整个应用 | 默认开启 |
| Activity | AndroidManifest.xml | 单个Activity | 可选择性关闭 |
| Window | Java代码 | Window级别 | 动态控制 |
| View | Java代码 | 单个View | 精细控制 |
配置示例:
xml
<!-- AndroidManifest.xml -->
<application
android:hardwareAccelerated="true"> ← 应用级别开启
<activity
android:name=".MainActivity"
android:hardwareAccelerated="true"/> ← Activity级别
<activity
android:name=".LegacyActivity"
android:hardwareAccelerated="false"/> ← 特定Activity关闭
</application>
kotlin
// Java代码中控制
// Window级别
window.setFlags(
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,
WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED
)
// View级别
myView.setLayerType(View.LAYER_TYPE_HARDWARE, null) // 开启
myView.setLayerType(View.LAYER_TYPE_SOFTWARE, null) // 关闭,使用CPU渲染
myView.setLayerType(View.LAYER_TYPE_NONE, null) // 默认(继承父级)DisplayList机制
硬件加速的核心是DisplayList (显示列表)。
工作原理:
css
软件渲染: 硬件加速渲染:
onDraw() onDraw()
↓ ↓
直接绘制到Canvas 生成DisplayList (GPU指令序列)
↓ ↓
像素输出 GPU执行DisplayList
↓
像素输出
优势: DisplayList可以复用,避免重复执行onDrawDisplayList缓存:
kotlin
class CachedView : View {
override fun onDraw(canvas: Canvas) {
// 第一次调用: 生成DisplayList并缓存
// 后续调用: 直接重放DisplayList,不执行onDraw
canvas.drawCircle(x, y, radius, paint)
}
// 内容改变时,需要invalidate()触发重建DisplayList
fun updatePosition(newX: Float, newY: Float) {
x = newX
y = newY
invalidate() // 触发重建DisplayList
}
}查看DisplayList:
bash
adb shell setprop debug.hwui.capture_frame_as_bitmap true
# 启用后,DisplayList会被dump到/data/data/<package>/cache/AOSP源码位置:
- DisplayList实现:
frameworks/base/libs/hwui/DisplayList.cpp - RenderNode:
frameworks/base/libs/hwui/RenderNode.cpp
硬件图层 (Hardware Layer)
硬件图层是将View渲染到离屏纹理 (Offscreen Texture),适合静态内容 或复杂动画。
使用场景
1. 复杂View + 简单动画
kotlin
// 场景: 复杂的自定义View需要执行平移/缩放/旋转动画
complexView.setLayerType(View.LAYER_TYPE_HARDWARE, null)
// 执行动画
complexView.animate()
.translationX(100f)
.alpha(0.5f)
.setDuration(300)
.withEndAction {
// 动画结束后释放硬件图层
complexView.setLayerType(View.LAYER_TYPE_NONE, null)
}原理: View被渲染到纹理后,动画只需要操作纹理的变换矩阵,不需要重绘内容。
2. 模糊效果
kotlin
val blurPaint = Paint().apply {
maskFilter = BlurMaskFilter(10f, BlurMaskFilter.Blur.NORMAL)
}
// 使用硬件图层应用模糊
blurView.setLayerType(View.LAYER_TYPE_HARDWARE, blurPaint)内存开销
硬件图层会占用额外的GPU内存:
ini
内存占用 = 宽度 × 高度 × 4字节 (ARGB_8888)
示例:
1920×1080的全屏View
= 1920 × 1080 × 4
= 8.29 MB
如果有10个硬件图层 = 82.9 MB GPU内存!最佳实践:
- 仅在动画期间启用硬件图层
- 动画结束后立即释放 (
setLayerType(NONE)) - 避免对大尺寸View使用硬件图层
何时关闭硬件加速
某些操作在硬件加速下不支持 或性能差:
不支持的操作:
kotlin
// 以下Canvas方法在硬件加速下不可用:
canvas.drawPicture() // 不支持
canvas.drawPosText() // 不支持
canvas.drawTextOnPath() // 支持,但慢
canvas.drawVertices() // 不支持
// 解决方案: 关闭单个View的硬件加速
myView.setLayerType(View.LAYER_TYPE_SOFTWARE, null)性能差的场景:
- 频繁invalidate的View: 硬件加速需要重建DisplayList,反而比软件渲染慢
- 大量小图形绘制: DrawCall开销大
- Canvas.saveLayer: 需要离屏渲染,开销大
kotlin
// 频繁更新的View,使用软件渲染可能更快
class HighFrequencyUpdateView : View {
init {
setLayerType(LAYER_TYPE_SOFTWARE, null)
}
// 每秒更新60次
fun startUpdate() {
handler.postDelayed(object : Runnable {
override fun run() {
invalidate() // 触发重绘
handler.postDelayed(this, 16)
}
}, 16)
}
}渲染性能分析工具
工具是优化的眼睛,没有度量就没有优化。
Profile GPU Rendering
开启方法:
设置 → 开发者选项 → Profile GPU Rendering → 在屏幕上显示为条形图图表解读:
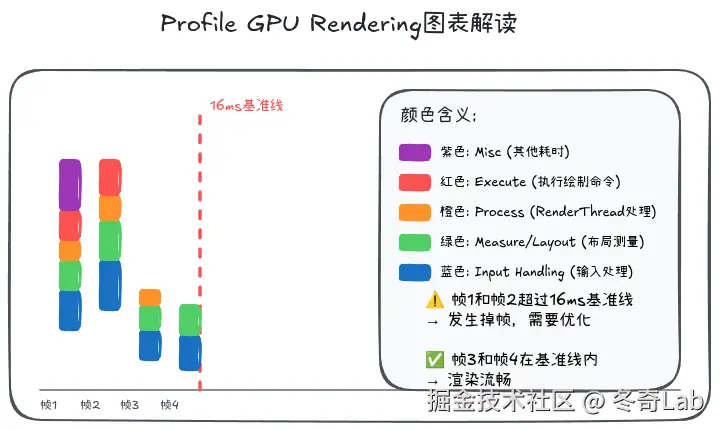
各阶段含义:
| 颜色 | 阶段 | 说明 | 优化方向 |
|---|---|---|---|
| 绿色横线 | 16ms基准 | 超过此线会掉帧 | - |
| 蓝色 | Draw | measure/layout/draw | 简化布局层级 |
| 红色 | Execute | RenderThread执行 | 减少Draw Calls |
| 橙色 | Process | GPU处理 | 优化Shader、纹理 |
| 黄色 | Swap | eglSwapBuffers | 减少过度绘制 |
示例分析:
makefile
场景1: 蓝色柱子很高 (Draw阶段慢)
原因: 布局层级深、measure/layout耗时
优化: 使用ConstraintLayout、减少嵌套
场景2: 橙色柱子很高 (GPU处理慢)
原因: 过度绘制、复杂Shader
优化: 移除不必要背景、简化特效
场景3: 黄色柱子很高 (Swap慢)
原因: BufferQueue阻塞、填充率过高
优化: 减少过度绘制、降低分辨率GPU Profiler (Android Studio)
使用步骤:
markdown
1. Android Studio → View → Tool Windows → Profiler
2. 点击 "+" 按钮,选择应用进程
3. 点击 "GPU" 行展开
4. 进行操作,观察GPU活动可分析的指标:
diff
- Draw Calls: 绘制调用次数
- Primitives: 渲染的三角形数量
- Texture Memory: 纹理内存占用
- Frame Time: 每帧渲染时间识别问题:
kotlin
// 示例: 发现某个场景DrawCall过高
// Before: 1000+ Draw Calls
fun drawManyItems(canvas: Canvas) {
items.forEach { item ->
canvas.drawBitmap(item.bitmap, item.x, item.y, paint)
}
}
// After: 合并为1个Draw Call
fun drawManyItemsOptimized(canvas: Canvas) {
// 将所有item合并到一个大纹理
val mergedBitmap = mergeBitmaps(items)
canvas.drawBitmap(mergedBitmap, 0f, 0f, paint)
}Systrace渲染分析
抓取渲染Trace:
bash
python systrace.py -t 10 -o render.html \
gfx view sched freq idle load workq
# 关键Tag:
# - gfx: SurfaceFlinger、HWC
# - view: View绘制
# - sched: CPU调度分析重点Slice:
makefile
线程: RenderThread
├── syncFrameState (2ms) ← 同步UI Thread状态
├── prepareTree (1ms) ← 准备渲染树
├── draw (5ms) ← 执行绘制
│ ├── drawDisplayList (3ms) ← 重放DisplayList
│ └── flush (2ms) ← 提交GPU指令
└── eglSwapBuffers (1ms) ← 交换Buffer
线程: SurfaceFlinger
├── onMessageInvalidate (1ms) ← 收集Layer更新
└── onMessageRefresh (3ms) ← 合成
├── updateTexImage (1ms) ← 更新纹理
├── doComposition (1ms) ← 执行合成
└── postComposition (1ms) ← 提交Display掉帧定位:
arduino
如果RenderThread的"draw"阶段超过10ms:
→ 检查过度绘制、Draw Calls数量
如果SurfaceFlinger的"doComposition"超过5ms:
→ 检查Layer数量、合成策略
如果GPU Completion延迟大:
→ 检查GPU负载、Shader复杂度自定义渲染监控
实现FrameMetrics监听器:
kotlin
class RenderMonitor(private val activity: Activity) {
fun start() {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) {
val listener = Window.OnFrameMetricsAvailableListener { _, metrics, _ ->
analyzeFrame(metrics)
}
activity.window.addOnFrameMetricsAvailableListener(
listener,
Handler(Looper.getMainLooper())
)
}
}
private fun analyzeFrame(metrics: FrameMetrics) {
// 各阶段耗时 (纳秒)
val inputTime = metrics.getMetric(FrameMetrics.INPUT_HANDLING_DURATION)
val animationTime = metrics.getMetric(FrameMetrics.ANIMATION_DURATION)
val layoutTime = metrics.getMetric(FrameMetrics.LAYOUT_MEASURE_DURATION)
val drawTime = metrics.getMetric(FrameMetrics.DRAW_DURATION)
val syncTime = metrics.getMetric(FrameMetrics.SYNC_DURATION)
val commandTime = metrics.getMetric(FrameMetrics.COMMAND_ISSUE_DURATION)
val swapTime = metrics.getMetric(FrameMetrics.SWAP_BUFFERS_DURATION)
val totalTime = metrics.getMetric(FrameMetrics.TOTAL_DURATION)
// 转换为毫秒
val totalMs = totalTime / 1_000_000.0
if (totalMs > 16.67) {
Log.w("RenderMonitor", "Dropped frame! Total: ${totalMs}ms")
Log.w("RenderMonitor", " Layout: ${layoutTime/1_000_000.0}ms")
Log.w("RenderMonitor", " Draw: ${drawTime/1_000_000.0}ms")
Log.w("RenderMonitor", " Command: ${commandTime/1_000_000.0}ms")
Log.w("RenderMonitor", " Swap: ${swapTime/1_000_000.0}ms")
// 上报到监控平台
reportToMonitoring(metrics)
}
}
private fun reportToMonitoring(metrics: FrameMetrics) {
// 上报到Bugly/Firebase等平台
}
}使用:
kotlin
class MainActivity : AppCompatActivity() {
private val renderMonitor = RenderMonitor(this)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
renderMonitor.start()
}
}实战案例:复杂列表滑动优化
让我用一个真实案例演示渲染优化的完整流程。
问题描述
场景: 车载应用中的音乐列表,每个Item包含:
- 专辑封面图 (300x300px)
- 歌曲名、歌手名、时长
- 播放按钮、收藏按钮
- 渐变背景
现象:
- 快速滑动时掉帧,FPS只有35左右
- Profile GPU Rendering显示橙色柱子很高 (GPU处理慢)
- 调试GPU过度绘制显示大量红色区域 (4x+)
优化前分析
使用工具:
bash
# 1. Profile GPU Rendering: 橙色(Process)和黄色(Swap)很高
# 2. 调试GPU过度绘制: 整个列表都是红色
# 3. Systrace分析:
python systrace.py -t 10 -o music_list.html gfx view sched
# 发现:
# - RenderThread的draw阶段耗时12ms
# - 大量"drawBitmap"调用
# - SurfaceFlinger合成耗时5ms过度绘制分析:
markdown
每个Item的绘制层级:
1. RecyclerView背景 (白色)
2. ItemView背景 (渐变)
3. ImageView背景 (占位图)
4. 专辑封面Bitmap
5. TextView背景 (半透明黑色)
6. 文字
总计: 6层! (4x过度绘制)优化措施
1. 移除不必要背景
❌ Before:
xml
<RecyclerView
android:background="@color/white"> ← 层级1
<FrameLayout (ItemView)
android:background="@drawable/gradient_bg"> ← 层级2
<ImageView
android:src="@drawable/placeholder" ← 层级3
android:background="@drawable/image_border"/> ← 层级4
<TextView
android:background="#80000000"/> ← 层级5 (半透明)
</FrameLayout>
</RecyclerView>✅ After:
xml
<RecyclerView> ← 无背景 (Activity设置window背景)
<FrameLayout (ItemView)
android:background="@drawable/gradient_bg"> ← 层级1
<ImageView
android:src="@drawable/placeholder"/> ← 层级2 (移除border)
<TextView
android:textColor="@color/white"/> ← 移除半透明背景
</FrameLayout>
</RecyclerView>效果: 过度绘制从4x降低到1x。
2. 图片优化
❌ Before: 300x300的ARGB_8888图片
kotlin
Glide.with(context)
.load(song.coverUrl)
.into(imageView)
// 内存占用: 300×300×4 = 360KB/张✅ After: 压缩 + 缓存
kotlin
Glide.with(context)
.load(song.coverUrl)
.override(150, 150) // ← 缩小到实际显示尺寸
.format(DecodeFormat.PREFER_RGB_565) // ← 使用RGB_565 (2字节)
.diskCacheStrategy(DiskCacheStrategy.ALL)
.into(imageView)
// 内存占用: 150×150×2 = 45KB/张 (减少88%!)3. ViewHolder优化
❌ Before: 每次bind都设置所有属性
kotlin
override fun onBindViewHolder(holder: ViewHolder, position: Int) {
val song = songs[position]
// 即使没变化也重新设置
holder.coverImage.load(song.coverUrl)
holder.titleText.text = song.title
holder.artistText.text = song.artist
holder.durationText.text = song.duration
// 重新设置背景 (触发重绘!)
holder.itemView.setBackgroundResource(R.drawable.gradient_bg)
}✅ After: 差量更新
kotlin
override fun onBindViewHolder(holder: ViewHolder, position: Int) {
val song = songs[position]
// 只在内容变化时更新
if (holder.currentSongId != song.id) {
holder.coverImage.load(song.coverUrl)
holder.titleText.text = song.title
holder.artistText.text = song.artist
holder.durationText.text = song.duration
holder.currentSongId = song.id
}
// 背景只设置一次 (在onCreateViewHolder中)
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): ViewHolder {
val view = LayoutInflater.from(parent.context)
.inflate(R.layout.item_song, parent, false)
// 背景只设置一次
view.setBackgroundResource(R.drawable.gradient_bg)
return ViewHolder(view)
}4. RecyclerView优化
kotlin
recyclerView.apply {
// 1. 设置固定大小 (避免重新measure)
setHasFixedSize(true)
// 2. 增加缓存池大小
recycledViewPool.setMaxRecycledViews(VIEW_TYPE_SONG, 20)
// 3. 设置预取策略
layoutManager = LinearLayoutManager(context).apply {
isItemPrefetchEnabled = true // Android 7.0+
initialPrefetchItemCount = 4 // 预取4个Item
}
// 4. 减少不必要的动画
(itemAnimator as? SimpleItemAnimator)?.supportsChangeAnimations = false
}5. 使用DiffUtil
kotlin
class SongDiffCallback(
private val oldList: List<Song>,
private val newList: List<Song>
) : DiffUtil.Callback() {
override fun getOldListSize() = oldList.size
override fun getNewListSize() = newList.size
override fun areItemsTheSame(oldPos: Int, newPos: Int): Boolean {
return oldList[oldPos].id == newList[newPos].id
}
override fun areContentsTheSame(oldPos: Int, newPos: Int): Boolean {
return oldList[oldPos] == newList[newPos]
}
// 返回变化的部分,实现精准更新
override fun getChangePayload(oldPos: Int, newPos: Int): Any? {
val oldSong = oldList[oldPos]
val newSong = newList[newPos]
val changes = Bundle()
if (oldSong.title != newSong.title) {
changes.putString("title", newSong.title)
}
if (oldSong.isFavorite != newSong.isFavorite) {
changes.putBoolean("favorite", newSong.isFavorite)
}
return if (changes.isEmpty) null else changes
}
}
// 使用
fun updateSongs(newSongs: List<Song>) {
val diffResult = DiffUtil.calculateDiff(
SongDiffCallback(songs, newSongs)
)
songs = newSongs
diffResult.dispatchUpdatesTo(adapter)
}优化效果对比
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| FPS | 35fps | 57fps | +63% |
| 过度绘制 | 4x (红色) | 1x (蓝色) | -75% |
| 内存占用 | 12MB (图片) | 2MB (图片) | -83% |
| GPU Process时间 | 8ms | 3ms | -63% |
| 用户感知 | 明显卡顿 | 流畅 | ✅ |
验证方法:
bash
# 1. Profile GPU Rendering: 橙色柱子明显降低
# 2. 调试GPU过度绘制: 大部分变成蓝色
# 3. Systrace: draw阶段从12ms降低到4ms
# 4. 用户反馈: 滑动流畅度明显提升最佳实践与总结
渲染优化Checklist
布局优化:
- 使用ConstraintLayout减少层级
- 移除不必要的背景
- 避免过深的View嵌套 (≤5层)
- 使用ViewStub延迟加载
- 使用merge标签减少层级
过度绘制优化:
- 开启"调试GPU过度绘制"检查
- 目标: 大部分区域蓝色 (1x)
- 移除窗口默认背景 (如果Activity有自定义背景)
- 使用clipRect裁剪不可见区域
- 优化自定义View的onDraw
GPU优化:
- 减少Draw Calls (批量绘制、合并纹理)
- 压缩纹理 (ETC2/ASTC)
- 使用Mipmap
- 简化Shader逻辑
- 避免动态分支
硬件加速:
- 默认开启应用级硬件加速
- 动画时启用硬件图层
- 动画结束释放硬件图层
- 避免对大View使用硬件图层
RecyclerView:
- setHasFixedSize(true)
- 增加RecycledViewPool大小
- 使用DiffUtil精准更新
- 启用预取 (Prefetch)
- 减少onBind操作
监控:
- 集成FrameMetrics监听
- 定期Systrace分析
- 监控掉帧率
- 上报到APM平台
常见坑点
1. 过度使用硬件图层
❌ 错误做法:
kotlin
// 给所有View都设置硬件图层
listView.children.forEach {
it.setLayerType(View.LAYER_TYPE_HARDWARE, null)
}
// 结果: GPU内存爆炸,反而卡顿✅ 正确做法: 只在动画期间使用。
2. 忽略clipRect
❌ 错误做法:
kotlin
override fun onDraw(canvas: Canvas) {
// 绘制所有100个Item,即使只有10个可见
for (i in 0..99) {
drawItem(canvas, items[i])
}
}✅ 正确做法: 只绘制可见区域。
3. 频繁创建对象
❌ 错误做法:
kotlin
override fun onDraw(canvas: Canvas) {
val rect = Rect() // 每帧创建
val paint = Paint() // 每帧创建
}✅ 正确做法: 复用对象。
总结
渲染优化是一个系统工程,需要从架构、代码和工具三个层面综合施策:
核心原则:
- 减少工作量: 更少的绘制、更少的Draw Calls、更少的像素填充
- 提高效率: 使用GPU、批量处理、缓存复用
- 度量驱动: 工具分析、数据说话、持续监控
优化路径:
markdown
1. 使用工具定位瓶颈 (Profile GPU Rendering、GPU Profiler、Systrace)
↓
2. 针对性优化 (过度绘制、布局层级、GPU负载)
↓
3. 验证效果 (FPS、工具指标、用户反馈)
↓
4. 持续监控 (FrameMetrics、APM平台)记住:优化是一个持续迭代的过程,没有银弹,只有合适的方案。理解渲染机制、善用工具、注重实测,才能打造丝般顺滑的用户体验。
系列文章:
作者简介: 多年Android系统开发经验,专注于系统稳定性与性能优化领域。欢迎关注本系列,一起深入Android系统的精彩世界!