深夜,Meta 又一次给 AI 视觉领域丢下重磅炸弹------SAM 3(Segment Anything Model 3)与 SAM 3D 全面发布!
不仅模型开放权重,连推理代码、数据集、体验平台都一次性放出,可谓"真·全家桶"。


这意味着什么?
如果说早期的 SAM 1、SAM 2 让我们看到了"分割一切"的可能性,那么现在,Meta 想让机器做到更多:
不仅要分割一切,还要从一张图片里重建整个 3D 世界。
SAM 3
和 SAM 3D 关注 3D 不同,SAM 3 是新一代通用分割大模型,能力全面提升。
之前我们介绍过 SAM3 ICLR 2026 惊现 SAM 3,匿名提交,实现"概念分割",CV领域再迎颠覆性突破?通过引入可提示概念分割(promptable concept segmentation) 模型能够根据文本提示或示例图像提示,找到并分割某个概念的所有实例。
这次发布让我们看到,它不仅可以分割,还可以
检测 + 分割 + 跟踪
覆盖 图像 & 视频
并且支持 多种提示方式:
✔ 文本提示(Text Prompt)
✔ 示例提示(Exemplar Prompt)
✔ 视觉提示(Visual Prompt)
"Promptable Concept Segmentation"------概念级分割,这让 SAM 3 能识别大量新概念,并支持开放词汇。
为了评估模型在大词汇量情况下的检测与分割能力,Meta 还构建了 SA-Co(Segment Anything with Concepts)基准。与以往基准相比,SA-Co 涵盖了规模更大的概念词汇,挑战性显著提高。
在 Meta 发布的新 benchmark SA-Co 上,SAM 3 相比现有模型做到:
图像 + 视频概念分割性能提升一倍以上
用户偏好测试中,SAM 3 的结果是 OWLv2 的 3 倍
单图像推理 30ms 内完成 100+ 对象检测与分割
简而言之,速度快、效果强、能力广。
对于开发者和研究者而言,像Coovally 这样的AI平台已经集成了1000+预训练模型,您可以直接调用使用,极大简化了开发流程。
不仅如此,您也可以直接在Coovally平台上上传自己的模型和数据进行训练,享受一站式的AI开发体验。
!!点击下方链接,立即体验Coovally!!
平台链接: www.coovally.com
SAM 3D
SAM 3D 是 SAM 家族最新成员,一个真正将2D 分割能力延伸到 3D 理解的里程碑模型。
如果说 SAM 是"让所有人都能对图像进行分割"的起点,那么 SAM 3D 则是在此基础上迈向"人人皆可 3D"时代的重要一步:它不仅能识别物体、人体、场景,还能把普通 2D 图片"长成"完整的 3D 结构。
它包含两个子模型:
- SAM 3D Objects
SAM 3D Objects 专注于通用物体与场景的3D重建,能从一个静止图像中还原物体的详细形状、纹理和空间布局。
数据引擎革命: 创建3D真值通常需要3D艺术家手动制作,费时费力。SAM 3D的创新在于,它构建了一个高效的"人机循环"数据标注引擎:
利用一系列模型自动为海量图片生成多个3D网格候选。让标注者(而非创建者)对AI生成的选项进行评分和排序,这是一个门槛更低、效率更高的任务。将最棘手的案例路由给专业的3D艺术家处理,以填补数据盲区。
通过这一引擎,Meta以前所未有的规模为近100万张真实世界图像标注了3D信息,生成了约314万个模型参与生成的网格。
训练范式创新: 借鉴大语言模型的成功经验,SAM 3D采用了"预训练-后训练" 的全新食谱。
在大量合成的3D资产上学习基础3D先验。利用上述数据引擎产出的真实世界数据,对模型进行"对齐"训练,从而跨越从合成数据到真实数据的鸿沟。
模型与数据引擎相互促进,形成一个不断自我改进的正向飞轮。


这些只需几年之前还属于研究级能力,如今被 Meta 做成开源工具。
- SAM 3D Body
- 海量高质量数据: 基于从数十亿图像中通过自动化引擎挖掘出的约800万张高质量图片进行训练,这些图片涵盖了罕见姿势和复杂拍摄条件,使模型对遮挡、奇异姿态和多样着装具有惊人的鲁棒性。
- 可提示的交互设计: 模型支持通过分割掩码、2D关键点等交互输入来引导预测,让用户拥有更大的控制权。
- 全新的参数化人体模型MHR: 本次开源还包括MHR模型,它将人体的骨骼结构与软组织形状分离,提供了更强的可解释性,并已应用于Meta的Codec Avatars等核心技术。
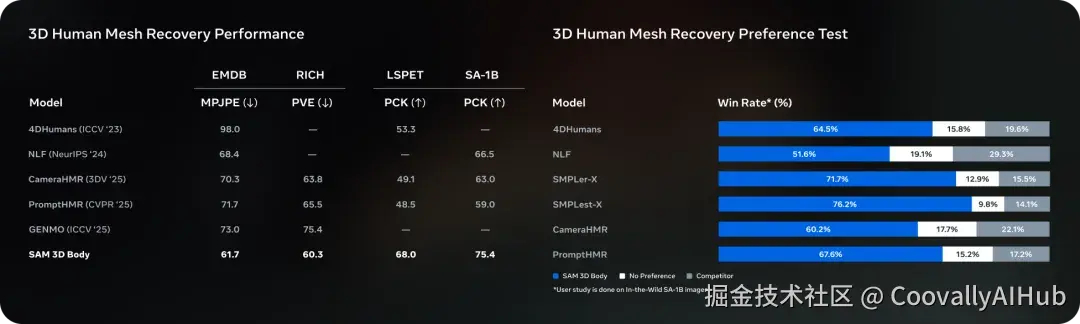
Meta 强调,这两个模型在各类 3D benchmark 上都达到了 SOTA(业界领先)性能。
一句话总结 SAM 3D:
把普通人拍的 2D 照片,变成可用于 AR/VR、影视、游戏、机器人和科学研究的 3D 数据。
Meta 还构建了一个包含约 800 万张图像的高质量训练数据集,使其能够应对遮挡、罕见姿态和各种服装,并在多个 3D 基准测试中均超越了以往的模型。
这次为什么这么重要?
从 SAM(2D 分割)到 SAM 3(通用检测/分割/跟踪)到 SAM 3D(3D 重建平台)
Meta 正在构建一个覆盖:
「2D 识别 → 3D 理解 → 视频跟踪 → 多模态推理」的完整视觉 AI 基础设施。
对于整个 AI 视觉生态的意义包括:未来的 AI 应用不再需要从零训练检测/分割模型
3D 生成、AR/VR、机器人将获得标准化 3D 感知能力视频编辑、特效制作将彻底简化。学术界获得了统一的开放数据与 benchmark工业检测、农业、安防、自动驾驶、小样本学习等领域都能直接接入。
一句话,这是视觉 AI 的一次"地基级"升级。
总结
当我们还在讨论"能不能分割一切"时,Meta 已经把问题升级为------"能不能从一张图片里重建世界?"
SAM 3D 与 SAM 3 的同步发布,让这个问题第一次变得现实和可实验。
未来一两年,围绕它们会诞生非常多的产业级创新。我相信这将是视觉 AI 赛道的一个重要里程碑。