提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、sed基本定义
-
- [1.1 sed 工具的定义与核心作用](#1.1 sed 工具的定义与核心作用)
- [1.2 sed 工具的工作流程](#1.2 sed 工具的工作流程)
- [二、sed 命令的常见用法](#二、sed 命令的常见用法)
-
- [2.1 sed 命令的基本格式](#2.1 sed 命令的基本格式)
- [2.2 sed 命令的常用选项](#2.2 sed 命令的常用选项)
- [2.3 sed 命令的操作类型](#2.3 sed 命令的操作类型)
- [三、sed 工具的用法示例](#三、sed 工具的用法示例)
-
- [3.1 输出符合条件的文本(p 表示正常输出)](#3.1 输出符合条件的文本(p 表示正常输出))
- [.3.2 删除符合条件的文本(d)](#.3.2 删除符合条件的文本(d))
- [3.3 替换符合条件的文本](#3.3 替换符合条件的文本)
- [3.4 迁移符合条件的文本](#3.4 迁移符合条件的文本)
- 总结
前言
sed(Stream Editor,流编辑器)是类 Unix 系统中一款功能强大的文本处理工具,它以逐行处理的方式对文本流进行编辑操作,广泛应用于文本批量替换、内容筛选、格式转换等场景。与交互式编辑器(如 vim)不同,sed 更擅长自动化、脚本化的文本处理任务,常与管道(|)、其他命令(如 grep、awk)配合,构建高效的文本处理流水线。
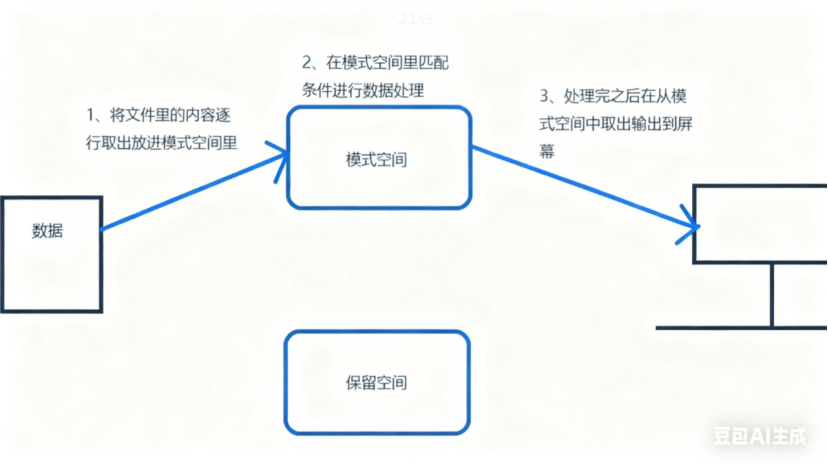
其核心工作机制围绕 "模式空间"(Pattern Space)和"保留空间"(Hold Space) 展开:文本行先被读入模式空间,sed 按照脚本指令(或命令行参数)对模式空间中的内容进行匹配、编辑,处理完成后将结果输出(或根据规则暂存至保留空间),整个过程是流式的,无需加载整个文件到内存,因此即使处理大文件也能保持高效。
一、sed基本定义
1.1 sed 工具的定义与核心作用
sed(Stream EDitor)是一款高效易用的文本处理工具。它以逐行方式读取文本,根据用户定义的规则执行查找替换、删除、插入等编辑操作,并输出处理结果。
1.2 sed 工具的工作流程
sed 的工作流程主要包括以下三个步骤:
读取 :从输入流(文件、管道或标准输入)中读取一行内容,存入临时的缓冲区中,又称之模式空间(pattern space)。
执行 :默认情况下,所有 sed 命令按顺序在模式空间中执行,除非指定了行地址。
**显示:**将处理后的内容发送到输出流,随后清空模式空间。
该过程会重复执行,直到所有内容处理完毕。
二、sed 命令的常见用法
2.1 sed 命令的基本格式
sed 命令有两种常用调用格式:
css
sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数其中,参数 表示目标文件,多个文件时用逗号分隔;scriptfile 是脚本文件,需使用 -f 选项指定。
当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
2.2 sed 命令的常用选项
e 或 --expression=:指定命令或脚本处理输入的文本文件
-f 或 --file=:指定脚本文件处理文本
-h 或 --help:显示帮助信息
-n、--quiet 或 silent:仅显示处理后的结果,取消默认输出
-i.bak:直接编辑文件,并备份原文件
-r、-E:使用扩展正则表达式
-s:将多个文件视为独立文件,而非连续流
2.3 sed 命令的操作类型
"操作"用于指定对文件操作的动作行为,也就是 sed 的命令。操作符通常格式为 n1\[,n2]动作,其中 n1、n2 为可选行号。常见操作包括:
a:在当期行下方添加一行
c:替换选定行
d:删除选定行
i:在选定行上方插入一行
p:打印内容,常与 -n 联用
s:替换指定字符
y:字符转换
n:读取下一行到模式空间(跳过当前行)。
g:全局替换(每行所有匹配项)
三、sed 工具的用法示例
在本小节中依旧以 test.txt文件为例进行演示。
3.1 输出符合条件的文本(p 表示正常输出)
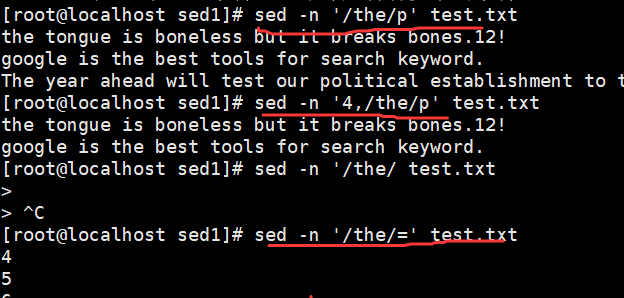
root@localhost \~# sed -n '/the/p' demo //输出包含the 的行
root@localhost \~# sed -n '4,/the/p' demo //输出从第 4 行至第一个包含 the 的行
root@localhost \~# sed -n '/the/=' demo
//输出包含the 的行所在的行号,等号(=)用来输出行号
4
5
6
root@localhost \~# sed -n '/^PI/p' demo //输出以PI 开头的行
PI=3.141592653589793238462643383249901429
root@localhost \~# sed -n '/0-9$/p' demo //输出以数字结尾的行
PI=3.141592653589793238462643383249901429

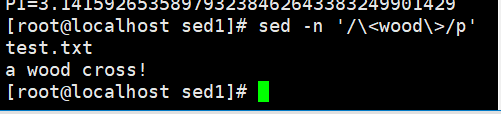
root@localhost \~# sed -n '/<wood>/p' demo //输出包含单词wood 的行,<、>代表单
词边界
.3.2 删除符合条件的文本(d)
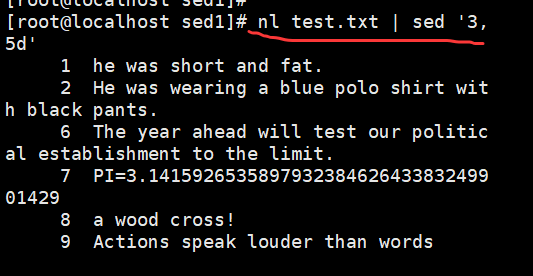
下面命令中 nl 命令用于计算文件的行数,结合该命令可以更加直观地查看到命令执行的结果
root@localhost \~# nl demo | sed '3,5d' //删除第 3~5 行
root@localhost \~# nl demo |sed '/cross/d' //删除匹配所有包含 cross 的行。

root@localhost \~# sed '/[1](#1)/d' demo //删除以小写字母开头的行

root@localhost \~# sed '/.$/d' demo //删除以"."结尾的行
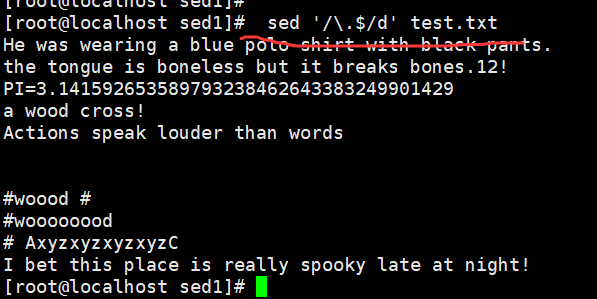
root@localhost \~# sed '/^$/d' demo //删除所有空行
注 意 : 若 是 删 除 重 复 的 空行 , 即 连 续 的 空 行 只 保 留 一 个 , "cat -s demo"。

.
3.3 替换符合条件的文本
s(字符串替换)、c(整行/整块替换)、y(字符转换)
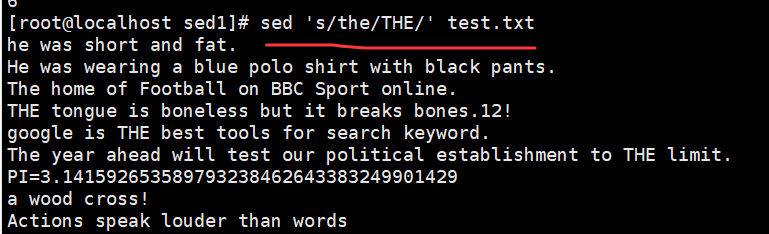
sed 's/the/THE/' demo //将每行中的第一个the 替换为 THE
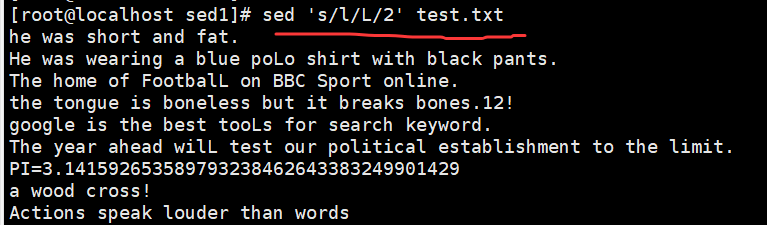
sed 's/l/L/2' demo //将每行中的第 2 个 l 替换为 L
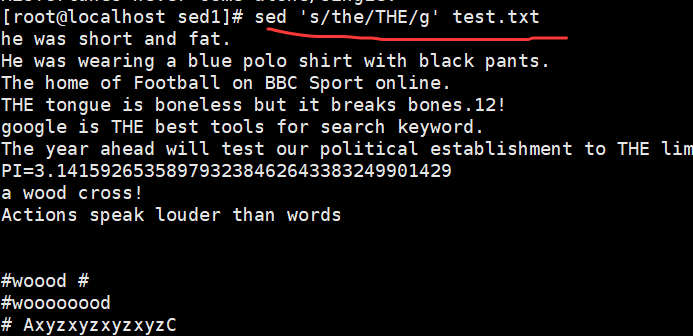
sed 's/the/THE/g' demo //将文件中的所有the 替换为 THE
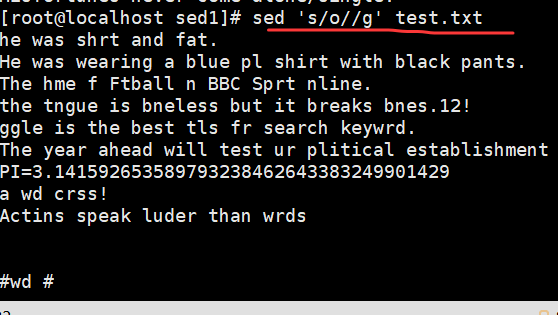
sed 's/o//g' demo //将文件中的所有o 删除(替换为空串)
sed 's/^/#/' demo //在每行行首插入#号
sed '/the/s/^/#/' demo //在包含the 的每行行首插入#号

sed 's/$/EOF/' demo //在每行行尾插入字符串EOF
sed '3,5s/the/THE/g' demo //将第 3~5 行中的所有 the 替换为 THE
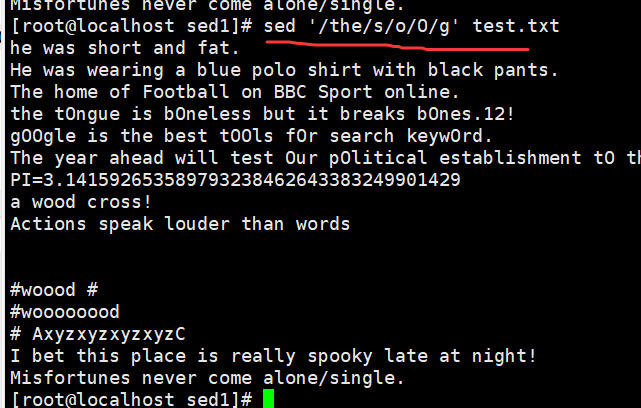
sed '/the/s/o/O/g' demo //将包含the 的所有行中的 o 都替换为 O


3.4 迁移符合条件的文本
H:复制到剪贴板;
g、G:将剪贴板中的数据覆盖/追加至指定行;
w:保存为文件;
r:读取指定文件;
a:追加指定内容。具体操作方法如下所示。
I,i 忽略大小
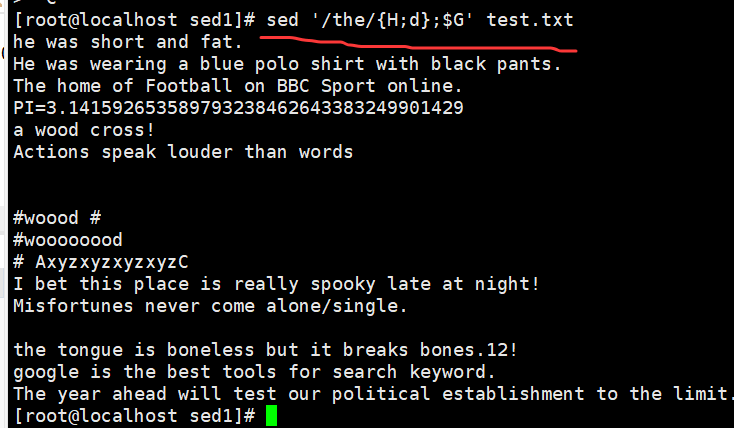
sed '/the/{H;d};$G' demo //将包含the 的行迁移至文件末尾,{;}用于多个操作
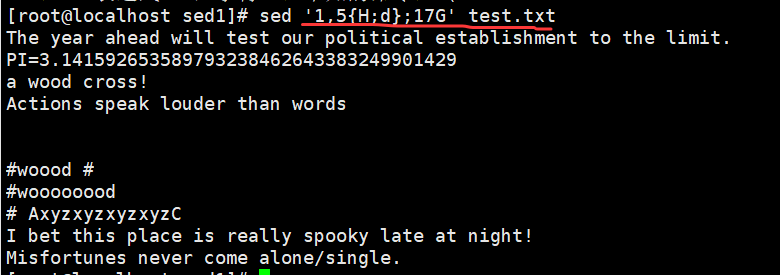
sed '1,5{H;d};17G' demo //将第 1~5 行内容转移至第 17 行后
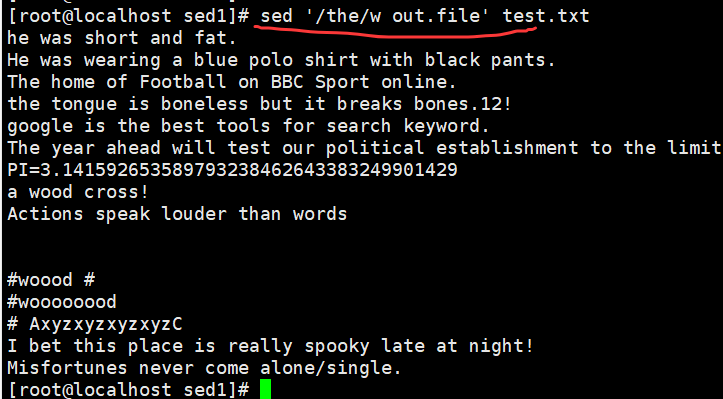
sed '/the/w out.file' demo //将包含the 的行另存为文件 out.file
sed '/the/r /etc/hostname' demo //将文件/etc/hostname 的内容添加到包含 the 的每行以后
sed '3aNew' demo //在第 3 行后插入一个新行,内容为New
sed '/the/aNew' demo //在包含the 的每行后插入一个新行,内容为 New
sed '3aNew1\nNew2' demo //在第 3 行后插入多行内容,中间的\n 表示换行
总结
掌握 sed 需重点理解其逐行处理的流程和两个空间的协作逻辑,通过实践不同场景的脚本编写(如正则匹配优化、多命令组合),可充分发挥其在文本自动化处理中的价值。
- a-z ↩︎