一、作业描述 ⭐️
项目1 - PM2.5预测
题量: 1 满分: 100
作答时间:11-14 09:00 至 11-19 09:00
一. 编程题(共1题,100分)
- 1、(编程题)
一、作业目标
- 本作业旨在让学生掌握基于真实环境数据的多变量时间序列预测方法,理解从数据探索、特征工程到模型构建与评估的完整建模流程。学生将使用飞桨AI Studio提供的PM2.5数据集与项目资源,实现一个高精度的空气质量预测模型,提升在环境监测、智慧城市等领域的数据建模与工程实践能力。
二、任务描述
- 1、访问指定资源链接 :
- 数据集链接(李宏毅ML-PM2.5预测) :
- 🔗 https://aistudio.baidu.com/datasetdetail/71270
- 包含北京市多年PM2.5浓度及相关气象、污染因子数据(如PM10、SO₂、NO₂、CO、O₃、温度、湿度、风速等)。
- 参考项目链接 :
- 🔗 https://aistudio.baidu.com/projectdetail/8815797
- 提供基于飞桨(PaddlePaddle)或通用框架的PM2.5预测项目示例,包含数据处理与模型实现思路。
- 2、选择预测算法:
- 从以下算法中选择1--2种 进行独立实现:
- 传统机器学习模型 :
- 多元线性回归(MLR)
- 支持向量回归(SVR)
- 随机森林回归(Random Forest)
- 深度学习模型 (推荐):
- LSTM(长短期记忆网络)
- GRU(门控循环单元)
- BiLSTM(双向LSTM)
- CNN-LSTM 混合模型
- Transformer / Temporal Fusion Transformer(TFT)(进阶)
- ✅ 建议实现 LSTM 或 GRU,并可与传统模型对比性能。
- 3、独立实现与实验分析 :
- 使用 Python + PyTorch / TensorFlow / PaddlePaddle 框架复现模型,在给定数据集上完成训练、验证与测试,评估预测精度,并进行结果可视化与分析。
三、提交内容(打包为
.zip文件)
- 请在压缩包中包含以下三部分,目录结构清晰:
pm25_prediction_homework_zhangsan.zip
│
├── code/ # 所有源代码
│ ├── lstm_model.py # 模型定义
│ ├── train.py # 训练脚本
│ ├── predict.py # 预测脚本
│ ├── preprocess.py # 数据清洗与特征工程
│ └── requirements.txt # 依赖库(如 torch, pandas, scikit-learn, matplotlib)
│
├── data/ # 数据集(或下载说明)
│ ├── train.csv # 原始数据(可从AI Studio下载)
│ └── processed_data.pkl # 处理后数据(可选)
│
├── results/ # 保存预测结果
│ ├── predictions.csv # 预测值 vs 真实值
│ ├── plots/ # 可视化图像
│ │ ├── loss_curve.png
│ │ └── prediction_vs_true.png
│ └── metrics.txt # RMSE, MAE, R², MAPE等指标
│
├── report.pdf # 技术报告(PDF格式,不少于2000字)
│
└── README.md # 项目说明(运行方式、环境配置、结果截图)1. 源代码(
code/)
- 提供完整、可运行的Python脚本。
- 模型结构清晰,支持超参数配置(如序列长度、隐藏层维度、学习率)。
- 关键代码添加中文注释,说明数据流与模型逻辑。
- 鼓励使用模块化设计(数据加载、模型、训练、评估分离)。
2. 数据处理(
data/)
- 从 飞桨AI Studio 下载数据集:https://aistudio.baidu.com/datasetdetail/71270
- 预处理要求:
- 处理缺失值(如前向填充、插值)
- 特征归一化(Min-Max或StandardScaler)
- 构建滑动窗口(如输入序列长度=24小时,预测未来1小时PM2.5)
- 划分训练集、验证集、测试集(按时间顺序划分,避免未来信息泄露)
3. 技术报告(
report.pdf)
- 撰写一份结构完整的PDF报告,内容包括:
- | 章节 | 内容要求 |
- |------|--------|
- | 1. 引言 | PM2.5污染的危害及预测在环境治理、公众健康预警中的意义 |
- | 2. 数据集描述 | 来源、字段说明、数据规模、时间跨度、缺失值统计 |
- | 3. 数据探索与预处理 | 特征分布、相关性分析(热力图)、滑动窗口设计 |
- | 4. 模型原理 | 详细说明所选模型(如LSTM)的结构、数学机制及其适用性 |
- | 5. 实验设计 | 模型超参数、优化器(Adam)、损失函数(MSE)、评估指标(RMSE, MAE, R², MAPE) |
- | 6. 结果分析 | 展示训练损失曲线、预测效果图(真实 vs 预测)、误差分析 |
- | 7. 模型对比(如有) | 对比不同模型性能,分析优劣 |
- | 8. 挑战与改进 | 讨论长期预测误差、数据偏差、是否可引入外部因素(如节假日、天气预警) |
- | 9. 应用与伦理 | 预测系统如何服务城市治理?是否存在区域预测偏差? |
- | 10. 参考文献 | 列出至少5篇相关论文或技术文档(如LSTM论文、空气质量预测研究) |
四、评分标准(总分100分)
- | 项目 | 分值 | 说明 |
- |------|------|------|
- | 代码完整性与可运行性 | 50分 | 代码无错误,能成功训练并输出预测结果 |
- | 技术报告质量 | 50分 | 内容完整,逻辑清晰,图表规范 |
五、注意事项
- ⚠️ 严禁抄袭:所有代码和文档必须为独立完成。引用AI Studio项目或他人代码需在报告中明确标注(如"参考飞桨项目8815797的LSTM实现"),否则按学术不端处理。
- ⚠️ 框架建议:
- 可使用 PyTorch 、TensorFlow 或 PaddlePaddle(与AI Studio生态兼容)。
- 推荐使用
pandas、numpy、matplotlib、seaborn进行数据处理与可视化。- ⚠️ 环境建议:
- 使用虚拟环境(
conda或venv)管理依赖。- 可在本地运行,或使用飞桨AI Studio的免费GPU资源进行训练。
- ⚠️ 数据与伦理:
- 仅使用公开数据,不得伪造或篡改环境数据。
- 预测结果应客观呈现,避免误导性宣传。
六、参考资料
- 1、数据集:
- 2、参考项目:
- 3、深度学习框架:
- PyTorch: https://pytorch.org/
- TensorFlow: https://www.tensorflow.org/
- PaddlePaddle: https://www.paddlepaddle.org.cn/
- 4、经典论文:
- Hochreiter & Schmidhuber (1997). Long Short-Term Memory
- Vaswani et al. (2017). Attention Is All You Need
- 教师寄语:
- PM2.5预测是AI赋能可持续发展的重要实践。希望同学们在建模的同时,思考数据背后的环境责任,做有社会担当的数据科学家。
二、项目框架搭建及运行 ⭐️

(一)、下载数据 🍭
从 飞桨AI Studio 下载数据集:
train.csv,将其存放到目录结构data/下面。❀
(二)、搭建目录结构 🍭
python
pm25_prediction_homework_yanghui/
│
├── code/ # 所有源代码
│ ├── lstm_model.py # LSTM 模型定义
│ ├── train.py # LSTM 训练脚本
│ ├── predict.py # LSTM 预测脚本
│ ├── preprocess.py # 数据清洗与特征工程
│ ├── rf_baseline.py # RandomForest 基线模型
│ ├── dataset.py # 自定义 PyTorch Dataset
│ ├── utils.py # 辅助函数(绘图、评估等)
│ └── requirements.txt # 依赖库
│
├── data/ # 原始数据集
│ └── train.csv # 原始 PM2.5 数据
│
├── processed/ # 预处理后的数据(里面内容由代码运行生成)
│
├── results/ # 保存预测结果和模型(里面内容由代码运行生成)
│
├── report.pdf # 技术报告
│
└── README.md # 项目说明(三)、书写代码code/ 🍭

- 推荐书写顺序: 👇🏻
utils.py-- 工具函数preprocess.py-- 数据清洗和特征工程dataset.py-- 自定义 PyTorch Datasetlstm_model.py-- LSTM 模型定义train.py-- LSTM 训练脚本predict.py-- LSTM 预测脚本rf_baseline.py-- RandomForest 基线模型requirements.txt-- 依赖库整理
第一步、utils.py
原因 🍉: 项目中多个模块都需要使用工具函数(如指标计算 compute_metrics、绘图 plot_predictions、模型保存等),将它们单独封装可以提高复用性和维护性 。
依赖关系 🎃: 该模块不依赖其他自定义代码,因此先编写最基础的工具函数最为合理。
python
'''
utils.py - 工具函数
utils.py 提供训练与评估 LSTM 模型所需的通用工具函数,包括:
1. 模型保存(save_model)
- 保存 PyTorch 模型的参数字典,用于后续加载和推断。
2. 损失曲线绘制(plot_loss)
- 绘制并保存训练集与验证集的损失曲线,用于观察收敛情况。
3. 预测对比图绘制(plot_predictions)
- 绘制真实值与预测值的时间序列对比图,直观展示模型预测效果。
4. 指标计算(compute_metrics)
- 计算回归任务常用的 RMSE、MAE、R² 以及修正后的 MAPE。
- 返回指标字典,便于保存和记录。
该文件作为模型训练与评估的辅助模块,集中封装通用功能,使训练脚本更简洁、更易维护。
'''
import torch # 导入 PyTorch:用于保存模型权重(state_dict)等操作。
import numpy as np # 导入 NumPy:用于数值计算(例如计算 RMSE 时的平方根或数组运算)。
import matplotlib.pyplot as plt # 导入 matplotlib 的 pyplot 模块,用于绘图并保存图片文件。
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 从 scikit-learn 导入常用回归评估指标函数:
# - mean_squared_error: 均方误差 (MSE)
# - mean_absolute_error: 平均绝对误差 (MAE)
# - r2_score: 决定系数 R^2
# 这些函数接收真实值与预测值数组并返回标量指标。
def save_model(model, path):
"""保存模型状态字典"""
# 定义一个简单的保存模型函数,接受两个参数:
# - model: PyTorch 的 nn.Module 实例
# - path: 要保存的文件路径(可以是相对路径或绝对路径)
torch.save(model.state_dict(), path)
# 保存模型的 state_dict(推荐方式):只保存模型参数(权重和偏置),文件体积较小且跨设备加载更灵活。
# 如果以后需要恢复模型:model.load_state_dict(torch.load(path))
print(f"Model saved to {path}")
# 打印提示信息,方便在训练脚本中确认保存成功。
def plot_loss(train_losses, val_losses, path):
"""绘制并保存训练和验证损失曲线"""
# 参数:
# - train_losses: 训练集每个 epoch 的损失列表或数组
# - val_losses: 验证集每个 epoch 的损失列表或数组
# - path: 图像保存路径(例如 '../results/plots/loss_curve.png')
plt.figure(figsize=(10, 5))
# 新建一个图表,设置尺寸为 (10, 5) 英寸,便于保存为较高分辨率图片。
plt.plot(train_losses, label='Train Loss')
# 绘制训练损失曲线,x 轴为 epoch 索引(0,1,2,...),y 轴为损失值。
plt.plot(val_losses, label='Validation Loss')
# 绘制验证损失曲线,用不同标签区分。
plt.title('Training and Validation Loss Curve')
# 设置图表标题。
plt.xlabel('Epoch')
# x 轴标签:训练轮数(epoch)。
plt.ylabel('Loss (MSE)')
# y 轴标签:损失(脚本中使用 MSELoss,所以这里注明 MSE)。
plt.legend()
# 显示图例,区分训练/验证曲线。
plt.grid(True)
# 打开网格,便于观察曲线波动。
plt.savefig(path)
# 将当前图表保存到指定路径。若目录不存在会抛错,调用该函数前通常要确保目录已创建。
print(f"Loss curve saved to {path}")
# 打印提示信息,确认图像已保存。
plt.close()
# 关闭当前图表,释放内存与资源(特别是在循环或多次绘图时非常重要,否则会造成内存增长)。
def plot_predictions(y_true, y_pred, path, n_plot=None):
"""绘制并保存真实值与预测值对比图
新增参数:
- n_plot: (可选)只绘制前 n_plot 个时间点,用于长序列的可视化精简
"""
# ------------------- 新增功能:限制绘图长度 -------------------
# 若 n_plot 不为 None,则只绘制前 n_plot 个点,避免图像过长
if n_plot is not None:
y_true = y_true[:n_plot]
y_pred = y_pred[:n_plot]
# -------------------------------------------------------------
plt.figure(figsize=(15, 6))
# 创建较宽的图表,方便对比时间序列(x 轴通常是时间步或索引)。
plt.plot(y_true, label='True Values', color='blue', alpha=0.7)
# 绘制真实值曲线:
# - label 用于图例说明
# - color 指定颜色(这里写了颜色,若你想保持默认色可去掉 color 参数)
# - alpha 指定透明度,0.7 能让两条线重叠时更易分辨
plt.plot(y_pred, label='Predicted Values', color='red', linestyle='--', alpha=0.7)
# 绘制预测值曲线,使用虚线更易区分。
plt.title('Prediction vs. True Values')
# 标题
plt.xlabel('Time Step')
# x 轴标签:时间步/样本索引
plt.ylabel('PM2.5 Concentration')
# y 轴标签:标签实际含义(示例:PM2.5)
plt.legend()
# 显示图例
plt.grid(True)
# 网格
plt.savefig(path)
# 保存图片到指定路径
print(f"Prediction plot saved to {path}")
# 打印提示信息
plt.close()
# 关闭图表,释放资源
def compute_metrics(y_true, y_pred):
"""计算并返回评估指标字典,使用 SMAPE 替代原来的 MAPE"""
# 接收真实值和预测值(建议为 numpy 数组)
# 返回一个字典,包含 RMSE、MAE、R2、SMAPE(%) 等指标。
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
# 计算 RMSE:先用 sklearn 的 MSE,再开方得到 RMSE。
mae = mean_absolute_error(y_true, y_pred)
# 计算 MAE:平均绝对误差。
r2 = r2_score(y_true, y_pred)
# 计算 R^2:决定系数,衡量模型解释方差的能力。
# --- SMAPE 替代 MAPE ---
# SMAPE 公式: mean( abs(y_true - y_pred) / ((|y_true| + |y_pred|)/2) ) * 100
denominator = (np.abs(y_true) + np.abs(y_pred)) / 2
# 防止分母为 0,给 0 值加上一个非常小的 epsilon
epsilon = 1e-10
smape = np.mean(np.abs(y_true - y_pred) / (denominator + epsilon)) * 100
# SMAPE 可以避免真实值或预测值为 0 时产生异常大数值
return {
'RMSE': rmse,
'MAE': mae,
'R2': r2,
'SMAPE(%)': smape # 使用 SMAPE 替代 MAPE
}第二步、preprocess.py
原因 🍉: 数据预处理是整个项目的起点,负责生成 processed_data.npz 和 scaler_y.pkl,为训练和预测提供标准化的数据输入。
依赖关系 🎃: 仅依赖 NumPy、Pandas 和 Scikit-learn,不依赖其他自定义模块,因此可以在工具函数之后编写。
python
# preprocess.py
"""
preprocess.py - 数据预处理
PM2.5 数据预处理脚本
功能:
1. 读取原始 CSV 数据
2. 格式转换与缺失值插值
3. 将时序切片为 LSTM 样本 (X, y)
4. 数据集划分 (train/val/test)
5. 数据归一化 (StandardScaler)
6. 保存处理后的数据 (.npz) 和归一化模型 (.pkl)
"""
import os # 操作系统相关功能,如路径操作
import argparse # 命令行参数解析模块
import pandas as pd # 数据处理与分析库
import numpy as np # 数值计算库
from sklearn.preprocessing import StandardScaler # 数据标准化工具
import joblib # 用于保存和加载 Python 对象(如 Scaler)
import chardet # 自动检测文件编码
# ----------------------------
# 函数定义
# ----------------------------
def load_raw(csv_path):
"""
函数作用:
自动检测 CSV 文件编码并加载为 pandas DataFrame。
参数:
csv_path (str): CSV 文件路径
返回:
df (pd.DataFrame): 加载的原始数据
"""
if not os.path.exists(csv_path): # 检查文件是否存在
raise FileNotFoundError(f"{csv_path} 不存在") # 文件不存在则抛出异常
# ---- ① 自动检测文件编码 ----
with open(csv_path, 'rb') as f: # rb="以二进制模式读取文件"【r=read:以"读取"方式打开文件;b=binary:以"二进制模式"打开文件】
raw_data = f.read(200000) # 读取前 200 KB 数据进行编码检测
detectedResults = chardet.detect(raw_data) # 使用 chardet 检测编码
encoding = detectedResults["encoding"] # 检测到的编码类型
confidence = detectedResults["confidence"] # 检测的置信度
print(f"🔍 检测到编码: {encoding} (置信度: {confidence:.2f})") # 输出检测结果
# ---- ② 按检测到的编码encoding 读取 CSV ----
df = pd.read_csv(csv_path, encoding=encoding) # 使用 pandas 读取 CSV
print("✅ 原始数据加载完成")
return df # 返回原始 DataFrame
def long_format(df):
"""
函数作用:
将宽表(每行 24 小时数据)转换为长表(每行 1 小时数据)。
参数:
df (pd.DataFrame): 原始宽表数据
返回:
df_long (pd.DataFrame): 转换后的长表数据,列包括 ['日期','測站','測項','hour','value','datetime']
"""
hour_cols = [str(i) for i in range(24)] # 小时列名列表:['0', '1', '2', '3', ..., '22', '23']
df['測項'] = df['測項'].str.strip() # 去掉列名中的空格
'''
df['測項'] = df['測項'].str.strip()的具体解释:
1. df['測項']
取出 DataFrame 的一列(Series 类型)。
2. .str
让你可以对 Series 中的每个元素使用字符串方法(类似 Python 原生的 str 类型方法)。
因为 Series 本身不是字符串对象,而是 pandas 对象,直接写 df['測項'].strip() 会报错:AttributeError: 'Series' object has no attribute 'strip'。
3. .strip()
去掉字符串开头和结尾的空格(或指定字符)。
因为用了 .str,strip() 会自动 作用于 Series 中的每个元素。
'''
# 使用 melt 将宽表转成长表,每小时一行:把"每行 24 小时"的宽表转换为长表(每行 1 小时一条记录),得到 df_long(列:'日期','測站','測項','hour','value')。
df_long = df.melt(
id_vars=["日期", "測站", "測項"], # 保留列
value_vars=hour_cols, # 需要转换的列
var_name="hour", # 新列名
value_name="value" # 对应值列名
)
# 替换 "NR" 为 NaN 并转换为数值
df_long["value"] = pd.to_numeric(df_long["value"].replace("NR", np.nan), errors='coerce')
'''
df_long["value"] = pd.to_numeric(df_long["value"].replace("NR", np.nan), errors='coerce')的具体解释:
1. df_long["value"].replace("NR", np.nan):
取出 DataFrame df_long 中名为 "value" 的列,用 replace 方法将 Series 中的 "NR" 替换为 NaN(缺失值)。
2. pd.to_numeric(..., errors='coerce'):
pd.to_numeric 用于把 Series 中的元素转换成数值类型(int 或 float),
参数 errors='coerce' 表示:无法转换的值会被强制转换为 NaN(缺失值)。
(1). errors='raise'(默认):
如果某个值无法转换,会直接报错。
(2). errors='ignore':
无法转换的值会保持原样(不会变成数字,也不会报错)。
(3). errors='coerce':
无法转换的值会被强制转换为 NaN(缺失值)。
'''
df_long["hour"] = df_long["hour"].astype(int) # hour 列转 int
# 新增 datetime 列 = 日期 + 小时
df_long["datetime"] = pd.to_datetime(df_long["日期"].astype(str), errors='coerce') + pd.to_timedelta(df_long["hour"], unit='h')
'''
df_long["datetime"] = pd.to_datetime(df_long["日期"].astype(str), errors='coerce') + pd.to_timedelta(df_long["hour"], unit='h')的具体解释:
1. df_long["日期"].astype(str):
将 "日期" 列的数据 全部转换为字符串类型。
2. pd.to_datetime(..., errors='coerce'):
将字符串转换为 pandas 的 datetime 类型,
参数 errors='coerce' 表示:如果某个值无法解析为日期,会被强制变成 NaT(缺失时间)。
3. pd.to_timedelta(df_long["hour"], unit='h'):
将 "hour" 列表示的 小时数 转换为 时间增量(Timedelta),
unit='h' 表示小时单位。
4. pd.to_datetime(...) + pd.to_timedelta(...) 相加操作:
pandas 支持 datetime + timedelta 的运算。
效果:得到 具体的时间点。
5. 最终结果赋值给 df_long["datetime"]
新增一列 datetime,是 日期 + 小时 的完整时间戳。
'''
# 如果这一行这两列'datetime', 'value'中任意一个是缺失值,就删除该行。inplace=True:修改操作直接作用于原 DataFrame,不生成新对象
df_long.dropna(subset=['datetime', 'value'], inplace=True)
'''
df_long.dropna(subset=['datetime', 'value'], inplace=True)的具体解释:
1. df_long.dropna():
dropna() 是 pandas DataFrame 的方法,用于删除包含缺失值 (NaN 或 NaT) 的行或列。
2. subset=['datetime', 'value']:
subset 参数指定 只关注哪些列 是否存在缺失值。
这里是:只检查 datetime 列和 value 列,如果这一行这两列中任意一个是缺失值,就删除该行。
3. inplace=True:
默认情况下,dropna() 会 返回一个新的 DataFrame,原 DataFrame 不会改变。
设置 inplace=True:
直接在原 DataFrame 上修改,不返回新的对象。
相当于 df_long = df_long.dropna(subset=['datetime', 'value']) 但不需要赋值。
'''
print("✅ 长格式数据转换完成")
return df_long # 返回长格式 DataFrame
def pivot_timeseries(df_long):
"""
函数作用:
将长表数据转换为时序表,索引为 datetime,列为各测项。
参数:
df_long (pd.DataFrame): 长表数据
返回:
df_ts (pd.DataFrame): 按小时重采样的时序表
"""
df_ts = df_long.pivot_table(index="datetime", columns="測項", values="value")
# 按小时重采样,并取平均值(合并多站数据):为了简化,这里我们对所有站点的同一时间点数据取平均,合并为一个总的时间序列。如果要为每个站点单独建模,则需按 '測站' 分组处理。
df_ts = df_ts.resample('h').mean()
print("✅ 时序格式数据转换完成")
return df_ts # 返回时序表 DataFrame
def basic_clean(df_ts):
"""
函数作用:
对时序表中的缺失值进行线性插值。
参数:
df_ts (pd.DataFrame): 时序表数据
返回:
df_ts (pd.DataFrame): 插值后的时序表
"""
df_ts.interpolate(method='linear', limit_direction='both', inplace=True) # 线性插值填充 NaN
'''
线性插值举例:
假设 df_ts 的某一列(索引为整点小时 0...4):
index: 0 1 2 3 4
value: 1.0 NaN NaN 4.0 NaN
在 index=0 值是 1.0,在 index=3 值是 4.0。这两个已知点之间有两个空位(index 1 和 2)。
线性插值会把 0→3 区间的增量(4.0−1.0=3.0)均匀分成 3 段,每段 +1.0:
index1 = 1.0 + 1.0 = 2.0
index2 = 1.0 + 2.0 = 3.0
index=4 是尾部的 NaN(在 3 之后没有已知点),线性插值无法外推,因此保持为 NaN。
插值后该列变为:
index: 0 1 2 3 4
value:1.0 2.0 3.0 4.0 NaN
'''
print("✅ 缺失值插值完成")
return df_ts # 返回插值后的 DataFrame
def create_sequences(df_ts, seq_len=24, pred_horizon=1, target_col='PM2.5'):
"""
函数作用:
使用滑动窗口生成 LSTM 输入序列 X 和预测目标 y。
参数:
df_ts (pd.DataFrame): 时序表
seq_len (int): 输入序列长度(小时数)
pred_horizon (int): 预测未来多少小时
target_col (str): LSTM 预测目标列名
返回:
X (np.ndarray): 输入序列,形状 (样本数, seq_len, 特征数)
y (np.ndarray): 目标值,形状 (样本数,)
"""
X_list, y_list = [], [] # 存放输入序列和目标
feature_cols = df_ts.columns.tolist() # 所有特征列
'''
feature_cols = df_ts.columns.tolist()的具体解释:
1. df_ts.columns:
获取 DataFrame 的列索引对象(Index 类型),包含所有列名。
2. .tolist():
将 Index 转换为普通 Python 列表
'''
data = df_ts[feature_cols].values # 转为 numpy 数组
if target_col not in feature_cols: # 检查目标列是否存在
raise ValueError(f"目标列 '{target_col}' 不在数据中!可用列: {feature_cols}")
target_idx = feature_cols.index(target_col) # 获取目标列索引
# 滑动窗口生成 X 和 y
for i in range(len(data) - seq_len - pred_horizon + 1):
X_seq = data[i:i + seq_len] # 输入序列
y_seq = data[i + seq_len + pred_horizon - 1, target_idx] # 预测目标
X_list.append(X_seq)
y_list.append(y_seq)
'''
(1) 循环范围
range(len(data) - seq_len - pred_horizon + 1)
len(data) → 数据总长度(时间步数)
seq_len → 输入序列长度
pred_horizon → 预测步长(从输入序列最后一步开始往后推)
+1 → 保证最后一个完整窗口也能使用
作用:遍历数据,生成所有可能的 (X_seq, y_seq) 对
(2) 输入序列
X_seq = data[i:i + seq_len]
data[i:i + seq_len] → 从 i 开始,取 seq_len 个连续时间步的子数组
形状:(seq_len, feature_dim)
作为 LSTM 的输入
(3) 输出预测
y_seq = data[i + seq_len + pred_horizon - 1, target_idx]
i + seq_len → 输入序列的最后一条时间步索引的下一步
+ pred_horizon - 1 → 往后推 pred_horizon-1 步,得到预测目标时间步
target_idx → 目标特征在列中的索引
结果:标量(单值预测)或者可以改为向量(多特征预测)
(4) 保存
X_list.append(X_seq)
y_list.append(y_seq)
每次循环生成一个 (X_seq, y_seq) 对,加入列表
最后转换为 NumPy 数组返回
具体例子:🥕
假设:
data = np.array([[1],[2],[3],[4],[5]]) # shape=(5,1)
seq_len = 2
pred_horizon = 1
target_idx = 0
解释:
每次输入序列长度 = 2
预测下一步
只有一列数据,预测目标是列 0
(1) 循环范围
len(data) - seq_len - pred_horizon + 1 = 5 - 2 - 1 + 1 = 3
i 取值:0, 1, 2
每次循环计算:
1. i = 0
X_seq = data[0:2] = [[1],[2]]
y_seq = data[0 + 2 + 1 - 1, 0] = data[2,0] = 3
2. i = 1
X_seq = data[1:3] = [[2],[3]]
y_seq = data[1 + 2 + 1 - 1, 0] = data[3,0] = 4
3. i = 2
X_seq = data[2:4] = [[3],[4]]
y_seq = data[2 + 2 + 1 - 1, 0] = data[4,0] = 5
最终结果:
X_list = [
[[1],[2]],
[[2],[3]],
[[3],[4]]
]
y_list = [3, 4, 5]
X = np.array(X_list) # shape = (3, 2, 1)
y = np.array(y_list) # shape = (3,)
🌈可视化理解:
data: [1, 2, 3, 4, 5]
窗口 1:
X = [1, 2] -> y = 3
窗口 2:
X = [2, 3] -> y = 4
窗口 3:
X = [3, 4] -> y = 5
每个窗口都是"滑动一次",覆盖整个时间序列。
✅ 总结
这是典型的 时间序列滑动窗口处理:
seq_len 决定输入长度
pred_horizon 决定预测步长
target_idx 指定预测目标
最终生成 (X, y),可以直接用于训练 LSTM/GRU 等模型。
'''
print("✅ 滑动窗口序列生成完成")
return np.array(X_list), np.array(y_list) # 返回 X, y
def split_data(X, y, train_ratio=0.7, val_ratio=0.15):
"""
函数作用:
按时间顺序划分训练集、验证集、测试集
参数:
X (np.ndarray): 输入序列
y (np.ndarray): 目标值
train_ratio (float): 训练集比例
val_ratio (float): 验证集比例
返回:
train_X, train_y, val_X, val_y, test_X, test_y
"""
n = len(X) # 总样本数
train_end = int(n * train_ratio) # 训练集截止索引
val_end = int(n * (train_ratio + val_ratio)) # 验证集截止索引
train_X, train_y = X[:train_end], y[:train_end] # 划分训练集
val_X, val_y = X[train_end:val_end], y[train_end:val_end] # 划分验证集
test_X, test_y = X[val_end:], y[val_end:] # 划分测试集
print("✅ 数据集划分完成")
return train_X, train_y, val_X, val_y, test_X, test_y
def normalize_data(train_X, val_X, test_X, train_y, val_y, test_y, out_dir):
"""
函数作用:
使用训练集数据对所有数据集进行标准化,并保存 StandardScaler。
参数:
train_X, val_X, test_X (np.ndarray): 输入序列
train_y, val_y, test_y (np.ndarray): 目标值
out_dir (str): 保存 scaler 的输出目录
返回:
train_X_scaled, train_y_scaled, val_X_scaled, val_y_scaled, test_X_scaled, test_y_scaled
"""
# --- 归一化特征 (X) ---
n_samples_train, seq_len, n_features = train_X.shape # 获取训练集形状
'''
n_samples_train, seq_len, n_features = train_X.shape的具体解释 ------ 获取训练集形状:
1. train_X 是 LSTM 输入的训练集,通常由滑动窗口生成。
形状:(样本数, 序列长度, 特征数) → (n_samples, seq_len, n_features)
2. train_X.shape 返回一个 元组 (tuple),表示数组的维度。
对应维度含义:
n_samples_train → 样本数量(滑动窗口数量)
seq_len → 每个序列的时间步长度(窗口长度)
n_features → 每个时间步的特征数
3. 举例:
假设经过滑动窗口处理后的 train_X:
train_X.shape = (3, 2, 1)
- 3 个样本
- 每个样本长度 2
- 每个时间步 1 个特征
则:
n_samples_train = 3
seq_len = 2
n_features = 1
'''
train_X_reshaped = train_X.reshape(-1, n_features) # 展平为 2D(这就是 3D → 2D reshape 的标准用法)
'''
.reshape(-1, n_features) 的作用:
1. 保留特征维度 n_features
每行仍然表示一个时间步的特征向量
对 LSTM/ML 处理、标准化等操作非常方便
2. 把前两维合并为一维 (样本 × 时间步)
原来是 (n_samples_train, seq_len, n_features)
reshape 后变成 (n_samples_train * seq_len, n_features)
方便按时间步操作或做批量标准化
3. -1 自动计算这一维长度
NumPy 会根据总元素数自动推算合适的行数
保证 reshape 前后的元素总数不变
'''
scaler_x = StandardScaler() # 初始化 StandardScaler
'''
StandardScaler 功能:
对每个特征计算 均值 (mean) 和 标准差 (std)
将数据标准化为均值 0、标准差 1:
𝑋_scaled=(𝑋−mean)/std
fit() → 计算训练集的均值和标准差
transform() → 用已计算的均值和标准差对数据进行缩放
'''
scaler_x.fit(train_X_reshaped) # 仅在训练集上 fit:避免数据泄露【训练时只能用 训练集信息,保证模型泛化能力】
# 对所有数据集进行归一化
train_X_scaled = scaler_x.transform(train_X_reshaped).reshape(train_X.shape)
val_X_scaled = scaler_x.transform(val_X.reshape(-1, n_features)).reshape(val_X.shape)
test_X_scaled = scaler_x.transform(test_X.reshape(-1, n_features)).reshape(test_X.shape)
# --- 归一化 目标 (y) ---
scaler_y = StandardScaler()
scaler_y.fit(train_y.reshape(-1, 1)) # reshape 为 (n_samples,1) 才能 fit
train_y_scaled = scaler_y.transform(train_y.reshape(-1, 1)).ravel() # 变回 1D
'''
train_y_scaled = scaler_y.transform(train_y.reshape(-1, 1)).ravel()的具体解释:
1. train_y.reshape(-1, 1)
把 train_y 变成二维数组(N × 1),因为 scaler 要求输入是二维矩阵。
其中:
-1 表示 自动计算行数,1 表示 只有 1 列。
2. scaler_y.transform(...)
输出仍然是二维数组(N × 1)。
3. .ravel()
把输出再压回一维:(N,)
方便后续 PyTorch 或 numpy 处理。
举个例子:🥕
import numpy as np
a = np.array([[1], [2], [3]])
print(a.shape) # (3, 1)
b = a.ravel()
print(b) # [1 2 3]
print(b.shape) # (3,)
'''
val_y_scaled = scaler_y.transform(val_y.reshape(-1, 1)).ravel()
test_y_scaled = scaler_y.transform(test_y.reshape(-1, 1)).ravel()
# --- 保存 Scalers ---
joblib.dump(scaler_x, os.path.join(out_dir, 'scaler_x.pkl')) # 保存特征 scaler
joblib.dump(scaler_y, os.path.join(out_dir, 'scaler_y.pkl')) # 保存目标 scaler
print("✅ 数据归一化完成,并已保存 scaler_x.pkl 和 scaler_y.pkl")
return train_X_scaled, train_y_scaled, val_X_scaled, val_y_scaled, test_X_scaled, test_y_scaled
def main(args):
"""
函数作用:
数据处理主流程:
1. 加载 CSV
2. 宽表 -> 长表 -> 时序表
3. 插值缺失值
4. 构建 LSTM 输入序列
5. 划分数据集
6. 数据归一化
7. 保存归一化后的数据和 scalers
参数:
args: 命令行参数对象,包括:
args.csv (str): CSV 文件路径
args.out_dir (str): 输出目录
args.seq_len (int): 输入序列长度
args.pred_horizon (int): 预测未来多少小时
"""
# 确保输出目录存在
os.makedirs(args.out_dir, exist_ok=True)
df = load_raw(args.csv) # 加载原始 CSV
df_long = long_format(df) # 宽表 -> 长表
df_ts = pivot_timeseries(df_long) # 长表 -> 时序表
df_ts = basic_clean(df_ts) # 插值缺失值
# 生成序列
X, y = create_sequences(df_ts, seq_len=args.seq_len, pred_horizon=args.pred_horizon)
# 划分数据集
train_X, train_y, val_X, val_y, test_X, test_y = split_data(X, y)
# 数据归一化并保存 scalers
train_X, train_y, val_X, val_y, test_X, test_y = normalize_data(
train_X, val_X, test_X, train_y, val_y, test_y, args.out_dir
)
# 保存处理好的(已归一化的)数据
out_file = os.path.join(args.out_dir, "processed_data.npz")
np.savez(
out_file,
train_X=train_X, train_y=train_y,
val_X=val_X, val_y=val_y,
test_X=test_X, test_y=test_y
)
print(f"✅ 处理完成,归一化后的数据已保存至 {out_file}")
print(f"train_X shape: {train_X.shape}, train_y shape: {train_y.shape}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PM2.5 Data Preprocessing and Normalization Script") # 创建一个命令行参数解析器 parser【description = "脚本整体功能描述"】
'''
description = "脚本整体功能描述"
显示在用户执行 --help 时(eg. 运行 python preprocess.py --help)
让别人一眼就知道这个 Python 文件是做什么的
'''
parser.add_argument("--csv", type=str, default='../data/train.csv', help="原始 CSV 文件路径") # 添加一个命令行参数 --csv
parser.add_argument("--out_dir", type=str, default='../processed', help="处理后数据和 scaler 的输出目录")
parser.add_argument("--seq_len", type=int, default=24, help="LSTM输入序列长度 (小时)") # 默认值:24 → 表示用过去 24 小时的数据预测未来
parser.add_argument("--pred_horizon", type=int, default=1, help="预测未来多少小时")
args = parser.parse_args() # 解析命令行参数
main(args) # 执行主流程第三步、dataset.py
原因 🍉: 自定义 PyTorch Dataset 类,便于训练和预测阶段使用 DataLoader 批量加载数据,提高训练效率和代码可读性。
依赖关系 🎃: 依赖 NumPy 和 PyTorch,但不依赖模型定义或训练脚本,可在数据预处理之后编写。
python
'''
dataset.py - 数据加载器
自定义PyTorch Dataset类,用于加载时间序列数据
将numpy数组转换为PyTorch张量,支持DataLoader批量加载
'''
import numpy as np # 导入 NumPy,用于数组处理
import torch # 导入 PyTorch,用于张量计算
from torch.utils.data import Dataset # 导入 Dataset 类,用于自定义数据集
class TimeSeriesDataset(Dataset):
"""
自定义 PyTorch 时间序列数据集,用于 LSTM 或其他序列模型训练。
参数:
X (np.ndarray): 输入特征,形状 (N, seq_len, feat)
y (np.ndarray): 目标值,形状 (N,) 或 (N,1)
功能:
- 将 NumPy 数组转换为 PyTorch 张量
- 自动扩展 y 为 (N,1)
- 提供 __len__ 和 __getitem__ 接口,支持 DataLoader 批量加载
"""
def __init__(self, X: np.ndarray, y: np.ndarray):
# 将输入特征 X 转换为 float32 类型的 PyTorch 张量
self.X = torch.tensor(X, dtype=torch.float32)
# 将目标 y 转换为 float32 类型的张量,并增加最后一维,形状 (N,) -> (N,1)
self.y = torch.tensor(y, dtype=torch.float32).unsqueeze(-1)
def __len__(self):
"""
返回数据集样本数量
DataLoader 会使用该方法决定迭代次数
"""
return self.X.shape[0]
def __getitem__(self, idx):
"""
根据索引 idx 返回单个样本
输出:
tuple: (X[idx], y[idx])
DataLoader 会使用该方法按批次获取数据
"""
return self.X[idx], self.y[idx]第四步、lstm_model.py
原因 🍉: 定义 LSTM 模型类,是训练脚本 train.py 和预测脚本 predict.py 的核心组件。
依赖关系 🎃: 仅依赖 PyTorch,可在 Dataset 编写完成后进行编写。
python
'''
lstm_model.py - 模型定义
定义LSTM回归模型架构
包含LSTM层和全连接层,支持双向LSTM和dropout
'''
import torch # 导入 PyTorch 主包(张量处理、自动求导)
import torch.nn as nn # 导入 PyTorch 神经网络模块(包含 LSTM / Linear / ReLU 等)
# 定义一个用于回归任务的 LSTM 模型
'''
创建一个类 LSTMRegressor,继承 nn.Module(所有神经网络需继承它)。
这是一个 LSTM 时间序列回归模型(输入序列 → 预测一个数值)。
'''
class LSTMRegressor(nn.Module):
def __init__(self, input_dim, hidden_dim=64, num_layers=2, dropout=0.2, bidirectional=False):
'''
input_dim: 每个时间步的特征维度(例如 PM2.5 = 1)
hidden_dim: LSTM 隐藏单元数量(特征提取能力)
num_layers: 堆叠 LSTM 层数(深度)
dropout: LSTM 层与层之间的 dropout(防过拟合)
bidirectional: 是否使用双向 LSTM(前后两个方向)
'''
super().__init__() # 调用父类 nn.Module 的初始化,PyTorch 要求固定写法。
# 保存模型参数(不是必须,但方便调试或扩展示例)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.bidirectional = bidirectional
# 定义 LSTM 网络层
# input_size = 输入的特征维度(例如每小时1个 PM2.5,则=1)
# hidden_size = LSTM 隐藏层维度
# num_layers = 堆叠的 LSTM 层数(深度)
# batch_first = True,让输入输出维度变成 (batch, seq_len, feature)
# dropout = 每层之间的 dropout(LSTM 内部不使用 dropout)
# bidirectional = 是否使用双向 LSTM(会将 forward 和 backward 拼接)
self.lstm = nn.LSTM(input_size=input_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
dropout=dropout if num_layers > 1 else 0.0, # 多层才启用 dropout
bidirectional=bidirectional)
# 如果是双向 LSTM,则输出特征维度翻倍,即需要 ×2
direction = 2 if bidirectional else 1
'''
普通 LSTM:输出维度 = hidden_dim
双向 LSTM:输出维度 = hidden_dim * 2
'''
# 定义全连接层,用于把 LSTM 最后时刻的隐藏状态映射到最终预测值
self.fc = nn.Sequential(
nn.Linear(hidden_dim * direction, hidden_dim // 2), # 全连接层1:降维
nn.ReLU(), # 激活函数,增加非线性
nn.Linear(hidden_dim // 2, 1) # 全连接层2:输出1个数
)
'''
解释:
LSTM 输出最后一个时间步的向量 (batch, hidden_dim * direction)
首先压缩到 hidden_dim//2 → 避免过大维度
ReLU() 非线性激活
最后 Linear(..., 1) 输出一个标量(PM2.5 预测值)
'''
# 定义前向传播
def forward(self, x):
"""
x 的形状:(batch_size, seq_len, input_dim)
"""
# out: LSTM 在每个时间步的输出 (batch, seq_len, hidden_dim*direction)
# h_n: 每层每个方向的最后隐藏状态
# c_n: 每层每个方向的最后记忆单元状态(常用于需要长时记忆的任务)
out, (h_n, c_n) = self.lstm(x)
# 取序列的最后一个时间步作为整体序列的特征表示
last = out[:, -1, :] # 形状 (batch_size, hidden_dim*direction)
'''
解释:
如输入 24 小时序列,取第 24 小时 LSTM 输出的特征作为最终语义。
比如要预测下一小时 PM2.5,不需要所有步的输出,只需要最后一个。
'''
# 将最后一个时间步的特征输入全连接网络,得到最终预测结果
'''
解释:
全连接层输出一个标量(如预测未来 1 小时 PM2.5)
支持批量预测(可以一次预测多个 batch)
'''
return self.fc(last) # 输出形状: (batch_size, 1)第五步、train.py
原因 🍉: 训练脚本,整合 preprocess.py 生成的数据、dataset.py 封装的数据集、lstm_model.py 的模型,以及 utils.py 的工具函数,实现完整训练流程并保存模型、损失曲线和指标。
依赖关系 🎃: 依赖 dataset.py、lstm_model.py、utils.py 和 preprocess.py,需在这些模块完成后编写。
python
# train.py
"""
train.py - 模型训练
训练脚本:训练 LSTM,并保存模型、loss 曲线、验证指标
适配 processed_data.npz
"""
import os # Python 内置的操作系统库,用于创建文件夹、拼接路径、检查目录等。
import argparse # 用于解析命令行参数,例如:python train.py --epoch 50。
import numpy as np # 数值计算库,用来加载 npz 文件、拼接预测结果等。
import pandas as pd # 用于把预测结果保存成 CSV 文件。
import torch # PyTorch 主库:张量计算、模型训练、GPU 加速。
from torch import nn, optim # nn:神经网络模块(LSTM、Linear、Loss) optim:优化器(Adam、SGD)。
from torch.utils.data import DataLoader, Dataset # Dataset 封装数据,DataLoader 负责批量加载。
import joblib # sklearn 推荐的序列化库,用于加载 scaler_y.pkl。
from dataset import TimeSeriesDataset # 导入自定义 Dataset
from lstm_model import LSTMRegressor # 导入你自己写的 LSTM 模型。
from utils import save_model, plot_loss, compute_metrics, plot_predictions # 导入自定义的工具函数
"""
工具函数导入说明:
save_model:保存模型 .pth
plot_loss:绘制训练/验证损失曲线 PNG
compute_metrics:计算 RMSE/MAE/R²/MAPE
plot_predictions:绘制预测 vs 真实值图像
"""
# ----------------------
# 训练循环(train mode)
# ----------------------
def train_loop(model, device, loader, criterion, optimizer):
model.train() # 设置模型为训练模式(启用 dropout、BN)
running_loss = 0.0 # 累积总损失
for X, y in loader: # 从 DataLoader 取一批数据
X, y = X.to(device), y.to(device) # 放到 GPU 或 CPU
optimizer.zero_grad() # 梯度清零
out = model(X) # 前向传播
loss = criterion(out, y) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item() * X.size(0) # 批大小乘 loss
return running_loss / len(loader.dataset) # 返回平均 loss
# ----------------------
# 验证 / 测试循环(eval mode)
# ----------------------
def eval_loop(model, device, loader, criterion):
model.eval() # 设置为评估模式
running_loss = 0.0
preds, trues = [], [] # 用来存所有预测和真实值
with torch.no_grad(): # 禁止梯度,节省显存和运算
for X, y in loader:
X, y = X.to(device), y.to(device)
out = model(X) # 推断
loss = criterion(out, y)
running_loss += loss.item() * X.size(0)
preds.append(out.cpu().numpy()) # 收集预测(转 numpy)
trues.append(y.cpu().numpy()) # 收集真实值
preds = np.concatenate(preds, axis=0) # 合并所有批次预测
trues = np.concatenate(trues, axis=0) # 合并所有真实值
return running_loss / len(loader.dataset), preds, trues
# ----------------------
# 主函数 main()
# ----------------------
def main(args):
# 自动选择 GPU,除非 --no_cuda 强制关闭
device = torch.device('cuda' if torch.cuda.is_available() and not args.no_cuda else 'cpu')
# ----------------------
# 读取 preprocess.py 生成的 processed_data.npz
# ----------------------
data = np.load(args.processed)
train_X, train_y = data['train_X'], data['train_y']
val_X, val_y = data['val_X'], data['val_y']
test_X, test_y = data['test_X'], data['test_y']
feat_dim = train_X.shape[-1] # 输入特征维度(例如 24 或更多)
print(f"train_X shape: {train_X.shape}, train_y shape: {train_y.shape}")
# ----------------------
# 读取 scaler_y.pkl(用于反归一化)
# ----------------------
try:
scaler_y = joblib.load(args.scaler_y_path)
print(f"Scaler '{args.scaler_y_path}' loaded successfully.")
except FileNotFoundError:
print(f"Error: Scaler file not found at '{args.scaler_y_path}'.")
print("Please run preprocess.py first to generate the scaler file.")
return # 结束程序
# ----------------------
# 创建 Dataset & DataLoader
# ----------------------
train_ds = TimeSeriesDataset(train_X, train_y)
val_ds = TimeSeriesDataset(val_X, val_y)
test_ds = TimeSeriesDataset(test_X, test_y)
train_loader = DataLoader(train_ds, batch_size=args.batch_size, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=args.batch_size, shuffle=False)
test_loader = DataLoader(test_ds, batch_size=args.batch_size, shuffle=False)
# ----------------------
# 创建 LSTM 模型实例
# ----------------------
model = LSTMRegressor(
input_dim=feat_dim,
hidden_dim=args.hidden,
num_layers=args.layers,
dropout=args.dropout,
bidirectional=args.bidirectional
).to(device)
criterion = nn.MSELoss() # 预测回归任务使用 MSELoss
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# ----------------------
# 训练过程
# ----------------------
best_val_loss = float('inf') # 用来保存最小验证损失
train_losses, val_losses = [], []
# -------- 早停机制参数 --------
patience = args.patience # 容忍多少个 epoch 验证集 loss 未下降
'''
patience 是允许"连续多少个 epoch 验证 loss 没有下降"的容忍次数
举个例子:
如果 patience = 5,则允许验证 loss 连续 5 个 epoch 不下降;
第 6 个 epoch 仍然没有下降,就会触发早停,训练提前结束。
这个机制可以避免因为验证 loss 的短期波动而过早停止训练,同时防止过拟合。
'''
counter = 0 # 计数器,用于记录连续未下降次数:验证loss 下降 → counter=0;验证loss 未下降 → counter += 1;counter >= patience → 停止训练
# ----------------------------
for epoch in range(1, args.epochs + 1):
train_loss = train_loop(model, device, train_loader, criterion, optimizer)
val_loss, _, _ = eval_loop(model, device, val_loader, criterion)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Epoch {epoch}/{args.epochs} - train_loss: {train_loss:.6f} val_loss: {val_loss:.6f}")
# ----------------------
# 早停逻辑
# ----------------------
if val_loss < best_val_loss:
best_val_loss = val_loss
counter = 0 # 验证 loss 下降,重置计数器
save_model(model, args.save_model)
else:
counter += 1 # 验证 loss 未下降,计数器加 1
if counter >= patience:
print(f"Early stopping triggered at epoch {epoch}")
break # 停止训练
# ----------------------
# 创建保存损失曲线的目录
os.makedirs(os.path.dirname(args.plot_loss), exist_ok=True)
plot_loss(train_losses, val_losses, args.plot_loss)
# ----------------------
# 测试集评估
# ----------------------
print("\nStarting evaluation on the test set...")
# 根据 PyTorch 新版本推荐,使用 weights_only=True 加载更安全
model.load_state_dict(torch.load(args.save_model, map_location=device, weights_only=True))
model.eval()
test_loss_scaled, preds_scaled, trues_scaled = eval_loop(model, device, test_loader, criterion)
# ----------------------
# 使用 scaler_y 进行反归一化
# ----------------------
preds_original = scaler_y.inverse_transform(preds_scaled)
trues_original = scaler_y.inverse_transform(trues_scaled)
# ----------------------
# 在原始 PM2.5 尺度上计算指标
# ----------------------
metrics = compute_metrics(trues_original.ravel(), preds_original.ravel())
print(f"\nTest loss (on scaled data): {test_loss_scaled:.6f}")
print("Metrics (on original PM2.5 scale):")
print(metrics)
# ----------------------
# 保存预测 CSV
# ----------------------
os.makedirs(os.path.dirname(args.pred_csv), exist_ok=True)
pd.DataFrame({
'y_true': trues_original.ravel(),
'y_pred': preds_original.ravel()
}).to_csv(args.pred_csv, index=False)
# ----------------------
# 保存指标到文本文件
# ----------------------
with open(args.metrics_txt, 'w') as f: # 'w' 模式会 清空原文件内容 并写入新内容,也就是自动覆盖。如果想 追加 内容而不是覆盖,需要使用 'a' 模式。
f.write(f"Test_Loss_Scaled: {test_loss_scaled}\n\n")
f.write("Metrics on Original Scale:\n")
for k, v in metrics.items():
f.write(f"{k}: {v}\n")
# ----------------------
# 绘制预测 vs 真实曲线(取前 500 个点)
# train.py 的预测曲线,只适用于"测试集",即 模型在测试集上的表现;
# predict.py 的预测曲线才是"真正对新数据的预测",即 模型对新数据的最终预测结果;
# 所以,最终"预测 vs 真实"曲线,以 predict.py 运行出来的为准。
# 【train.py → 测试集(test)预测】
# ----------------------
plot_pred_path = os.path.join(os.path.dirname(args.plot_loss), 'prediction_vs_true_test.png')
plot_predictions(trues_original.ravel()[:500], preds_original.ravel()[:500], plot_pred_path)
# ----------------------
# argparse:命令行参数配置
# ----------------------
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--processed', type=str, default='../processed/processed_data.npz',
help="Path to processed data file")
parser.add_argument('--scaler_y_path', type=str, default='../processed/scaler_y.pkl',
help="Path to the saved target scaler") # 用于反归一化
parser.add_argument('--epochs', type=int, default=50)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--hidden', type=int, default=128)
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.2)
parser.add_argument('--bidirectional', action='store_true')
parser.add_argument('--save_model', type=str, default='../results/model_best.pth',
help="Path to save the best model")
parser.add_argument('--plot_loss', type=str, default='../results/plots/loss_curve.png',
help="Path to save loss curve plot")
# 【train.py → 测试集(test)预测】
parser.add_argument('--pred_csv', type=str, default='../results/predictions/predictions_test.csv',
help="Path to save prediction results")
parser.add_argument('--metrics_txt', type=str, default='../results/metrics.txt',
help="Path to save evaluation metrics")
# ----------------------
# 早停参数:patience,指定连续多少个 epoch 验证 loss 未下降就提前停止训练。
# ----------------------
parser.add_argument('--patience', type=int, default=10,
help="Number of epochs to wait for improvement before stopping early")
parser.add_argument('--no_cuda', action='store_true')
args = parser.parse_args()
main(args)第六步、predict.py
原因 🍉: 预测脚本,用于加载训练好的模型权重和数据进行批量预测,并保存预测结果与对比图,验证模型在测试集或新数据上的性能。
依赖关系 🎃: 依赖 dataset.py、lstm_model.py、utils.py,并要求 train.py 已生成模型权重,因此应在训练脚本之后编写。
python
"""
predict.py - 模型预测
使用保存的 LSTM 模型和 scaler 对测试集或任意新数据进行预测,并保存结果
功能:
1. 加载测试数据
2. 加载训练好的模型
3. 批量预测
4. 计算回归指标(RMSE, MAE, R², MAPE)
5. 保存预测结果 CSV
6. 绘制预测 vs 真实值对比图
"""
import numpy as np # 数组处理
import torch # PyTorch 主库
import argparse # 命令行参数解析
import pandas as pd # 保存预测结果为 CSV
from torch.utils.data import DataLoader # DataLoader 用于批量加载数据
from lstm_model import LSTMRegressor # 导入自定义 LSTM 模型类
from dataset import TimeSeriesDataset # 导入自定义 Dataset
from utils import compute_metrics, plot_predictions # 导入自定义的工具函数:计算指标、绘图
def main(args):
# 1️⃣ 加载处理好的数据 npz 文件
data = np.load(args.processed)
test_X = data['test_X'] # 测试集输入特征
test_y = data['test_y'] # 测试集真实目标值
feat_dim = test_X.shape[-1] # 输入特征维度
# 设备选择:有 GPU 且未禁用则使用 CUDA,否则使用 CPU
device = torch.device('cuda' if torch.cuda.is_available() and not args.no_cuda else 'cpu')
# 2️⃣ 构建模型
model = LSTMRegressor(
input_dim=feat_dim,
hidden_dim=args.hidden,
num_layers=args.layers,
dropout=args.dropout,
bidirectional=args.bidirectional
)
# 加载训练好的模型权重
model.load_state_dict(torch.load(args.model_path, map_location=device))
model.to(device)
model.eval() # 切换模型为评估模式,关闭 dropout 等
# 3️⃣ 构建 DataLoader 批量加载测试数据
loader = DataLoader(
TimeSeriesDataset(test_X, test_y), # 使用自定义 Dataset 封装
batch_size=args.batch_size,
shuffle=False
)
preds = [] # 存放预测值
trues = [] # 存放真实值
with torch.no_grad(): # 预测阶段不需要计算梯度
for X, y in loader:
X = X.to(device) # 输入移动到设备
out = model(X).cpu().numpy() # 模型预测,转换回 NumPy
preds.append(out) # 保存预测结果
trues.append(y.numpy()) # 保存真实值
# 4️⃣ 将批次结果合并为完整向量
preds = np.vstack(preds).ravel() # (N,1) -> (N,)
trues = np.vstack(trues).ravel() # (N,1) -> (N,)
# 5️⃣ 计算回归指标
metrics = compute_metrics(trues, preds)
print(metrics)
# 6️⃣ 保存预测结果 CSV
pd.DataFrame({'y_true': trues, 'y_pred': preds}).to_csv(args.out_csv, index=False)
# 7️⃣ 绘制预测 vs 真实值对比图
plot_predictions(trues, preds, args.plot_path, n_plot=args.n_plot)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# 数据文件路径
parser.add_argument('--processed', type=str, default='../processed/processed_data.npz')
# 模型路径
parser.add_argument('--model_path', type=str, default='../results/model_best.pth')
# 输出预测 CSV 路径【predict.py → 新数据(newData)预测】
parser.add_argument('--out_csv', type=str, default='../results/predictions/predictions_newData.csv')
# 绘图保存路径【predict.py → 新数据(newData)预测】
parser.add_argument('--plot_path', type=str, default='../results/plots/prediction_vs_true_newData.png')
# 批次大小
parser.add_argument('--batch_size', type=int, default=64)
# 模型超参数
parser.add_argument('--hidden', type=int, default=128)
parser.add_argument('--layers', type=int, default=2)
parser.add_argument('--dropout', type=float, default=0.2)
parser.add_argument('--bidirectional', action='store_true')
# 绘图时显示多少个时间步
parser.add_argument('--n_plot', type=int, default=500)
# 是否禁用 GPU
parser.add_argument('--no_cuda', action='store_true')
args = parser.parse_args()
main(args)第七步、rf_baseline.py
原因 🍉: RandomForest 基线模型,用于对比 LSTM 的性能,验证深度学习模型的优势。
依赖关系 🎃: 依赖 utils.py 和 preprocess.py 提供的数据,但不依赖 PyTorch,可在 LSTM 主流程完成后编写,作为对照实验。
python
"""
rf_baseline.py - 基线模型(RandomForest: 是另一个传统机器学习模型。)
功能:
1. 加载处理好的训练、验证、测试数据
2. 将时间序列 X 展平为普通特征向量
3. 训练 RandomForestRegressor 基线模型
4. 对验证集、测试集进行预测
5. 将预测值与真实值 inverse_transform(反归一化)
6. 计算回归指标(RMSE, MAE, R², SMAPE)
7. 保存模型与预测结果 CSV
rf_baseline.py 就是我的 baseline 对照实验,用来对比 LSTM 性能是否真的提升:
从最终结果来看,LSTM 明显优于 RandomForest → 模型设计成功 ✔
"""
import numpy as np # 数组处理
from sklearn.ensemble import RandomForestRegressor # 随机森林回归模型
from sklearn.preprocessing import StandardScaler # 加载 scaler_y 需要使用
import joblib # 模型保存/加载
import argparse # 命令行参数解析
import pandas as pd # 保存预测结果为 CSV
from utils import compute_metrics # 计算 RMSE / MAE / R² / SMAPE
def flatten_X(X):
"""
将时间序列 X 展平为普通特征向量
参数:
X: np.ndarray, shape (N, seq_len, feat)
返回:
X_flat: np.ndarray, shape (N, seq_len*feat)
"""
return X.reshape(X.shape[0], -1)
def main(args):
# 1️⃣ 加载处理好的数据 npz 文件
data = np.load(args.processed)
train_X, train_y = data['train_X'], data['train_y']
val_X, val_y = data['val_X'], data['val_y']
test_X, test_y = data['test_X'], data['test_y']
# 2️⃣ 展平时间序列特征 -> 普通机器学习可用的 (N, seq_len*feat)
X_train = flatten_X(train_X)
X_val = flatten_X(val_X)
X_test = flatten_X(test_X)
# 3️⃣ 加载 y 的 scaler(用于 inverse_transform)
scaler_y = joblib.load('../processed/scaler_y.pkl')
# 4️⃣ 初始化 RandomForest 回归器
rf = RandomForestRegressor(
n_estimators=args.n_estimators, # 树的数量
max_depth=args.max_depth, # 树的深度
n_jobs=-1, # 使用所有 CPU
random_state=42 # 固定随机种子保证结果可复现
)
# 5️⃣ 训练模型
rf.fit(X_train, train_y)
# 6️⃣ 验证集 & 测试集预测(仍是缩放后的数值)
val_pred_scaled = rf.predict(X_val)
test_pred_scaled = rf.predict(X_test)
# 7️⃣ 将 y_true 与 y_pred 全部还原到 PM2.5 原始尺度
val_pred = scaler_y.inverse_transform(val_pred_scaled.reshape(-1, 1)).ravel()
test_pred = scaler_y.inverse_transform(test_pred_scaled.reshape(-1, 1)).ravel()
val_y_orig = scaler_y.inverse_transform(val_y.reshape(-1, 1)).ravel()
test_y_orig = scaler_y.inverse_transform(test_y.reshape(-1, 1)).ravel()
# 8️⃣ 计算并打印指标(全部基于原始 PM2.5)
print("val metrics:", compute_metrics(val_y_orig, val_pred))
print("test metrics:", compute_metrics(test_y_orig, test_pred))
# 9️⃣ 保存训练好的 RandomForest 模型
joblib.dump(rf, args.save_path)
# 🔟 保存测试集预测结果 CSV(包含原始尺度 y_true/y_pred)
pd.DataFrame({
'y_true': test_y_orig,
'y_pred': test_pred
}).to_csv(args.pred_csv, index=False)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# 数据路径
parser.add_argument('--processed', type=str, default='../processed/processed_data.npz')
# RandomForest 超参数
parser.add_argument('--n_estimators', type=int, default=200)
parser.add_argument('--max_depth', type=int, default=15)
# 模型保存路径
parser.add_argument('--save_path', type=str, default='../results/rf_model.joblib')
# 预测 CSV 路径
parser.add_argument('--pred_csv', type=str, default='../results/predictions/predictions_rf.csv')
args = parser.parse_args()
main(args)第八步、requirements.txt
原因 🍉: 列出项目依赖的第三方库,保证环境可复现。
依赖关系 🎃: 可以在任何阶段完成,但通常在主要功能实现后整理更准确。
python
# requirements.txt - 环境依赖
# 列出项目所需的Python包
numpy # 数值计算库,用于高效数组操作、线性代数和数学运算
pandas # 数据处理库,用于读取 CSV、处理 DataFrame、数据清洗和分析
scikit-learn # 机器学习库,提供数据预处理、模型训练、评估和常用算法
matplotlib # 绘图库,用于绘制折线图、散点图、柱状图等可视化图表
seaborn # 基于 matplotlib 的高级绘图库,用于统计图表和美观可视化
torch # PyTorch 深度学习库,用于构建、训练神经网络
tqdm # 进度条库,用于显示循环或训练进度条
joblib # 序列化库,用于保存/加载模型或数据预处理器
opencv-python-headless # OpenCV 图像处理库(无 GUI),用于图像读取、处理和计算机视觉任务
chardet # 字符编码检测库,用于自动检测文件编码(UTF-8、GBK 等)(四)、跑代码 🍭

第一步、环境准备 🍉
(1)、创建虚拟环境(可选,但推荐)🍍
方法一、

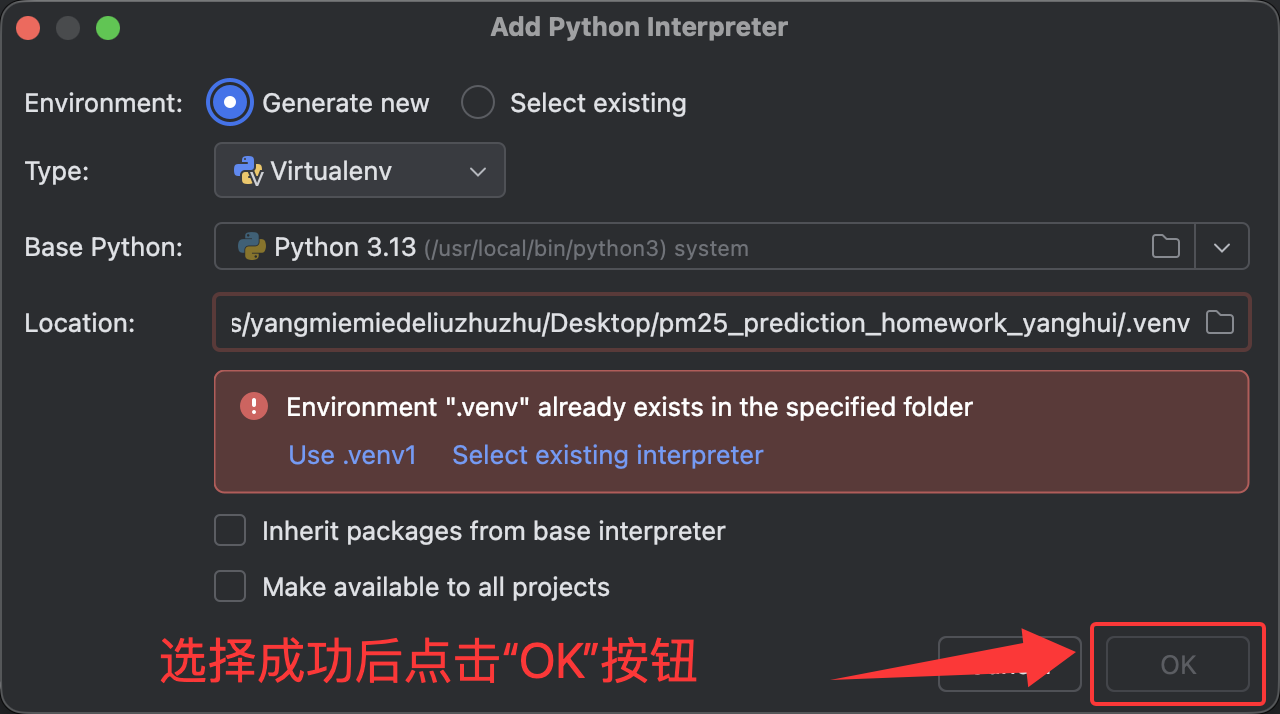
方法二、直接点击右下角,进行虚拟环境创建

检查是否成功 🐰
打开终端,若最前面出现创建好的自定义的虚拟环境名,则表示创建成功。❀
【如果在终端中没有看到上述输出,可以先关闭
PyCharm,然后重新启动一次,再重新打开终端即可。】

(2)、安装依赖库 requirements.txt 🍍
python
# requirements.txt - 环境依赖
# 列出项目所需的Python包
numpy # 数值计算库,用于高效数组操作、线性代数和数学运算
pandas # 数据处理库,用于读取 CSV、处理 DataFrame、数据清洗和分析
scikit-learn # 机器学习库,提供数据预处理、模型训练、评估和常用算法
matplotlib # 绘图库,用于绘制折线图、散点图、柱状图等可视化图表
seaborn # 基于 matplotlib 的高级绘图库,用于统计图表和美观可视化
torch # PyTorch 深度学习库,用于构建、训练神经网络
tqdm # 进度条库,用于显示循环或训练进度条
joblib # 序列化库,用于保存/加载模型或数据预处理器
opencv-python-headless # OpenCV 图像处理库(无 GUI),用于图像读取、处理和计算机视觉任务
chardet # 字符编码检测库,用于自动检测文件编码(UTF-8、GBK 等)终端输入
pip install -r requirements.txt。
- 【注意 📢】目前我是处于
code目录下,若是处于pm25_prediction_homework_yanghui目录下,则是pip install -r code/requirements.txt。

第二步、数据预处理 🍉
运行
preprocess.py【这一部是基础数据准备,不影响后续模型的独立性】
- 生成
processed_data.npz- 包含
train_X,train_y,val_X,val_y,test_X,test_y- 并保存
scaler_X.pkl、scaler_y.pkl
第三步、训练LSTM模型 🍉
运行
train.py
- 训练
LSTM- 保存
LSTM模型到model_best.pth- 保存
loss曲线、metrics等- 👉 不会改变
processed_data.npz- 👉 不会修改
scaler_y- 👉 不会影响
RF baseline数据
第四步、模型预测 🍉
运行
predict.py
- 使用
LSTM推断- 仅生成
prediction_vs_true_test.png- 👉 只是读取模型和
scaler,不会修改.npz- 👉 不影响
RF baseline
第五步、运行基线模型(可选) 🍉
运行
rf_baseline.py
- 再次加载
processed_data.npz- 完全独立于
LSTM训练结果- 👉 也不会使用
LSTM模型和predict.py的输出- 👉 完全不会被前面的步骤"干扰"
(五)、最终目录 🍭

python
pm25_prediction_homework_yanghui/
│
├── code/ # 所有源代码
│ ├── lstm_model.py # LSTM 模型定义
│ ├── train.py # LSTM 训练脚本
│ ├── predict.py # LSTM 预测脚本
│ ├── preprocess.py # 数据清洗与特征工程
│ ├── rf_baseline.py # RandomForest 基线模型
│ ├── dataset.py # 自定义 PyTorch Dataset
│ ├── utils.py # 辅助函数(绘图、评估等)
│ └── requirements.txt # 依赖库
│
├── data/ # 原始数据集
│ └── train.csv # 原始 PM2.5 数据
│
├── processed/ # 预处理后的数据
│ ├── processed_data.npz # NumPy 格式的数据
│ ├── scaler_x.pkl # 特征归一化模型
│ └── scaler_y.pkl # 目标值归一化模型
│
├── results/ # 保存预测结果和模型
│ ├── model_best.pth # LSTM 最佳模型权重
│ ├── rf_model.joblib # RandomForest 模型
│ ├── metrics.txt # LSTM 测试集指标
│ ├── predictions/ # 预测结果 CSV
│ │ ├── predictions_test.csv # train.py 测试集预测
│ │ ├── predictions_newData.csv # predict.py 新数据预测
│ │ └── predictions_rf.csv # rf_baseline.py 测试集预测
│ └── plots/ # 可视化图像
│ ├── loss_curve.png # train.py 训练/验证损失曲线
│ ├── prediction_vs_true_test.png # train.py 测试集预测图
│ └── prediction_vs_true_newData.png # predict.py 新数据预测图
│
├── report.pdf # 技术报告
│
└── README.md # 项目说明三、知识点 ⭐️

(一)、rf_baseline.py在该项目里的作用 🍓
- 具体分析:👇🏻
- 1、独立性
rf_baseline.py是一个独立的对比实验脚本;- 它不依赖于其他文件的训练结果;
- 其他文件也不依赖它的输出。
- 2、用途和价值
- 作为性能基准:随机森林模型通常作为机器学习项目的基线模型;
- 模型对比:可以与
LSTM模型的性能进行对比,判断深度学习的必要性;- 快速验证:随机森林训练速度快,可以快速验证特征的有效性。
- 3、使用方式
- 需要手动单独运行:
python rf_baseline.py。
(二)、train.py和predict.py绘制的"预测 vs 真实曲线" 🍓
问题1、二者都绘制了"预测 vs 真实曲线",其用途是否相同呢❓
- 答:用途不同:
train.py里绘制的是:
- ✔ 测试集 的预测 vs 真实(并且只取前500个点)
- 位置在:
- plot_predictions(trues_original.ravel():500, preds_original.ravel():500, plot_pred_path)
- 作用:
- 用于快速看一下模型的预测效果
- 通常是在训练完成后的"简单可视化"
predict.py里绘制的是:
- ✔ 任意你想预测的数据集(通常不是 test测试 集,而是你手动输入的真实新数据)
predict.py的定位是 真正用模型去预测外部数据并可视化结果 ,所以绘的是"你要预测的数据 vs 模型结果"。
问题2、既然二者都绘制了"预测 vs 真实曲线",那么 predict.py 是否多余❓
- 答:完全不是多余的,它非常重要。 原因如下(非常关键):
train.py的作用:训练 + 在测试集上验证模型性能
train.py并不是为了让你给"真实业务数据"做预测的。- 它的任务是:
- 训练模型
- 记录训练与验证损失
- 测试集上计算指标
- 保存模型与输出曲线
- 它不支持对"任意新数据"进行预测,也不应该支持。
predict.py的作用:真正使用模型进行预测(inference推断)
predict.py才承担这些任务:
- 读取你提供的新数据
processed_data.npz(可能是别的数据)- 加载
scaler- 加载训练好的模型
- 用模型预测真实新数据
- 保存预测结果
CSV- 绘制预测 vs 真实曲线(完整的,而不是只取前500个)
predict.py是生产阶段 / 部署阶段必需脚本。
问题3、为什么运行完 train.py 之后,还要运行 predict.py 呢❓
- 答:因为:训练 = 学习能力,预测 = 使用能力,它们属于两件事。
- 运行
train.py后可以得到:
- 训练好的
models- 训练曲线
loss- 测试集指标
- 但是:
- 🔹
train.py无法对你自己的实际业务数据预测- 🔹 你不能每天重新训练再预测,太慢也没必要
- 🔹 真正上线预测时,永远只需要
predict.py,不需要train.py- 通俗解释:
train.py= 学生上课 + 模拟考试
- 学习知识(训练)
- 在模拟题测试表现(test set)
- 保存学到的知识(模型)
predict.py= 学生参加真正的考试
- 使用学到的知识(加载模型)
- 做真正的题目(新数据)
- 输出答案(预测结果)
总结 ✍🏻
train.py→ 用训练后模型做"测试集预测"
predict.py→ 用训练后模型做"新数据预测"train.py→ 用于评估模型在"测试集"上的表现(模型质量评估 )
predict.py→ 用于对"新数据"做预测(实际部署输出)
| 脚本 | 是否绘制预测曲线 | 用途 |
|---|---|---|
| train.py | ✔ 是(但只用于测试集) | 训练模型 + 验证性能 |
| predict.py | ✔ 是(用于真实预测任务) | 加载模型,对新数据做预测 |
问题4、那我最后得到的"预测 vs 真实曲线" 以哪个跑的为准呢❓
- 答:✅ 最终应该看的是
predict.py生成的预测 vs 真实曲线。原因如下:👇🏻
- 1、
train.py的预测曲线,只适用于"测试集"。
train.py里画的虽然是真实值 vs 预测值,但是:
- 数据是测试集
test_X→test_y- 数据来自同一个
processed_data.npz- 是模型在训练阶段使用的固定数据
- 不能代表实际想预测的真实业务数据
- 它只是模型好坏的参考指标,不是最终预测结果。
- 2、
predict.py的预测曲线才是"真正对新数据的预测"。
predict.py才是真正用来:
- 输入新的数据
- 加载训练好的模型
- 预测想要的 PM2.5 值
- 画出真实 vs 预测曲线
- 这个结果才是真正"模型输出结果",也是实际要看的。
- 3、
train.py的预测可视化只是辅助,不作最终判断。
train.py的预测图:
- 只是模型自测
- 数据固定
- 不会变化
- 用处是检查模型有没有过拟合、欠拟合
predict.py的曲线:
- 输入真实你要预测的数据
- 体现模型的真实表现
- 才是最终你要输出的曲线
- 举个例子:
train.py= 模拟考试成绩
- 只能证明学得还行,但不算最终成绩。
predict.py= 正式考试成绩
- 这个才是拿出去用的结果。
- ✔ 所以最终看
predict.py的图。
(三)、loss_curve.png 为什么由train.py生成呢?这个图片的作用是什么呢?🍓
1、为什么 loss_curve.png 要由 train.py 生成❓
- 因为:
- ✔
train.py才包含训练循环(train loop)
- 它在 每个
epoch都计算:
train_lossval_loss- 并记录成曲线,所以 只有
train.py能得到完整的训练历史。- ✔
predict.py不做训练,也不会有loss曲线
predict.py只是用训练好的模型对新数据推理(inference),完全不涉及训练,所以它不可能生成loss曲线。
2、📈 loss_curve.png 的作用是什么❓
- 🟣 1、判断模型是否收敛了(有没有学到东西)
- 一个正常的 loss 曲线应该是这样:(理想情况) 🦋
- train_loss:不断下降
- val_loss:也一起下降,最后稳定(也下降到某个低点后保持平稳或小幅波动)
- 如果 loss 不降,说明:👇🏻
- 学习率不合适
- 模型太小
- 数据问题
- 🔵 2、判断是否出现过拟合(模型记住训练集,无法泛化)
- 典型过拟合: 🦋
- train_loss: 继续下降
- val_loss: 先下降,随后开始上升
- 如果你看到这种典型过拟合曲线,应当:👇🏻
- 增大 dropout
- 减少 LSTM 层数
- 使用更少神经元
- 提早停止(early stopping)
- 🟢 3、判断训练是否异常中断
- 例如训练中途学习率太大,loss 抖动成炸裂的锯齿形。
- 🟡 4、用于实验记录(机器学习实验必须保存)
- 实际项目中,每次训练都要保存 loss 曲线,否则以后无法复现模型质量。
3、总结对比 ✍🏻
| 脚本 | 输出内容 | 作用 |
|---|---|---|
train.py |
loss_curve.png、prediction_vs_true_test.png |
用于模型训练质量评估 |
predict.py |
prediction_vs_true_newData.png |
用于部署和对新数据预测 |
loss_curve.png是训练监控指标,必须由train.py生成,predict.py不会也不应该生成它。
(四)、loss曲线的理想情况以及为什么这样是理想情况呢?🍓
1、loss曲线的理想情况
loss曲线的理想情况是:👇🏻
Train Loss下降Val Loss也下降到某个低点后保持平稳或小幅波动
2、为什么这样是理想情况呢❓
Train Loss下降
- 模型在训练集上越来越好,能拟合训练数据。
Val Loss下降到某个低点后保持平稳或小幅波动
- 模型在验证集上表现稳定,说明它没有记住训练集的噪声,而是学到了泛化能力。
- 换句话说:
- 训练集
loss下降 → 模型在学习- 验证集
loss下降并稳定 → 模型可以泛化到新数据- 这就是理想的训练过程。
- 举个例子:🌰
- 假设学英语单词:
- 场景 A:理想训练 😎
- 每天背单词(
Train Loss) → 每天记住的单词越来越多,忘记的少 →loss下降- 每周小测(
Val Loss) → 测试真正记住的单词,最开始成绩慢慢提高,然后稳定在 90%-95% →loss降低并平稳- 解释:不仅记住了训练的单词,也能正确应用到测验题上 → 模型泛化能力好
- 场景 B:过拟合 😱
- 每天背单词(
Train Loss) → 每天记住很多单词,Train Loss下降得很快- 每周小测(
Val Loss) → 测试结果不升反降,甚至波动很大- 解释:你只记住了训练中出现的单词组合,但测验题出现新单词或顺序不同,你就做错了 → 模型只记住训练集,不会泛化
- 场景 C:欠拟合 😱
- 每天背单词(
Train Loss) → 无论怎么背,Train Loss都不降(你总是记不住)- 每周小测(
Val Loss) → 验证结果很差,也不下降- 解释:模型容量太小或者数据量太大,学不到规律 → 欠拟合
3、总结对比 ✍🏻
Loss 曲线 |
含义 | 是否理想 |
|---|---|---|
| Train ↓ , Val ↓ 并稳定 | 模型学到规律且能泛化 | ✅ 理想 |
| Train ↓ , Val ↑ 或震荡 | 模型记住训练集噪声,泛化差 | ❌ 过拟合 |
| Train 停滞 , Val 高 | 模型能力不足或训练不足 | ❌ 欠拟合 |
(五)、训练集(train set)、验证集(validation set)、测试集(test set)在机器学习/深度学习训练中的作用 🍓
1、训练集(Train Set)
- 作用: 🦋
- 用于模型的 参数学习。
- 模型通过训练集计算损失并更新权重(梯度下降)。
- 模型只"看到"训练集数据,学习输入 X 与目标 y 的映射关系。
项目里的例子(train.py):
python
train_ds = TimeSeriesDataset(train_X, train_y)
train_loader = DataLoader(train_ds, batch_size=args.batch_size, shuffle=True)
train_loss = train_loop(model, device, train_loader, criterion, optimizer)
- 这里
train_X,train_y是训练集。train_loop里模型不断前向传播 + 反向传播 + 参数更新。- 损失函数(
MSE)是用训练集计算的。- 如果只有训练集,没有验证集,早停、超参数调优就无法判断模型好坏。
2、验证集(Validation Set)
- 作用: 🦋
- 用于 模型选择与调参,不参与梯度更新。
- 监控验证集损失来判断是否过拟合。
- 可以实现 早停(Early Stopping):如果验证集损失连续多轮不下降,就停止训练。
项目里的例子(train.py):
python
val_ds = TimeSeriesDataset(val_X, val_y)
val_loader = DataLoader(val_ds, batch_size=args.batch_size, shuffle=False)
val_loss, _, _ = eval_loop(model, device, val_loader, criterion)
- 这里
val_X,val_y是验证集。eval_loop在验证集上计算损失 但不更新模型参数。- 训练过程中:👇🏻
python
if val_loss < best_val_loss:
best_val_loss = val_loss
save_model(model, args.save_model)
else:
counter += 1
if counter >= patience:
print(f"Early stopping triggered at epoch {epoch}")
break
- 当验证损失不再下降时,触发早停,防止过拟合。
3、测试集(Test Set)
- 作用: 🦋
- 用于 最终评估模型性能,不参与训练和调参。
- 模拟真实场景预测:你已经训练好模型,拿到未知数据,看看效果。
- 计算指标(
RMSE、MAE、R²、SMAPE)来评估模型。
项目里的例子(train.py & predict.py):
python
test_ds = TimeSeriesDataset(test_X, test_y)
test_loader = DataLoader(test_ds, batch_size=args.batch_size, shuffle=False)
test_loss_scaled, preds_scaled, trues_scaled = eval_loop(model, device, test_loader, criterion)
metrics = compute_metrics(trues_original.ravel(), preds_original.ravel())
test_X,test_y是测试集。- 模型在测试集上进行推理(
eval_loop),计算预测值,但不更新权重。- 得到最终指标:👇🏻
python
print("Metrics (on original PM2.5 scale):")
print(metrics)
- 这是最终报告里
LSTM或RandomForest的性能值。
总结对比 ✍🏻
| 数据集 | 作用 | 是否参与参数更新 | 代码示例 |
|---|---|---|---|
训练集 train |
学习模型参数 | ✅ 是 | train_loop(model, train_loader) |
验证集 val |
调参、早停 | ❌ 否 | eval_loop(model, val_loader) |
测试集 test |
模型最终评估 | ❌ 否 | eval_loop(model, test_loader) + compute_metrics |
